结果讨论
6.1 结果总结
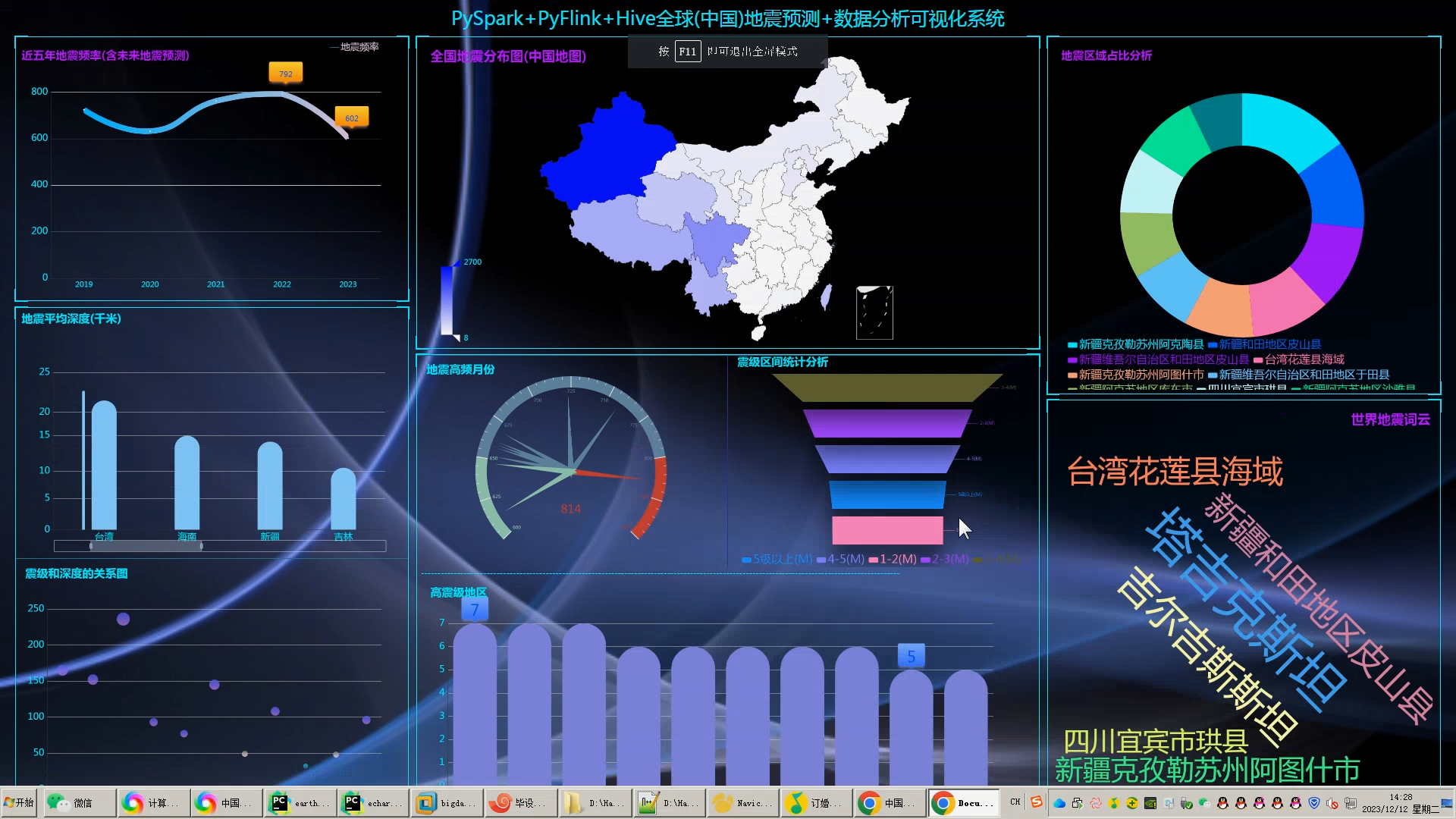
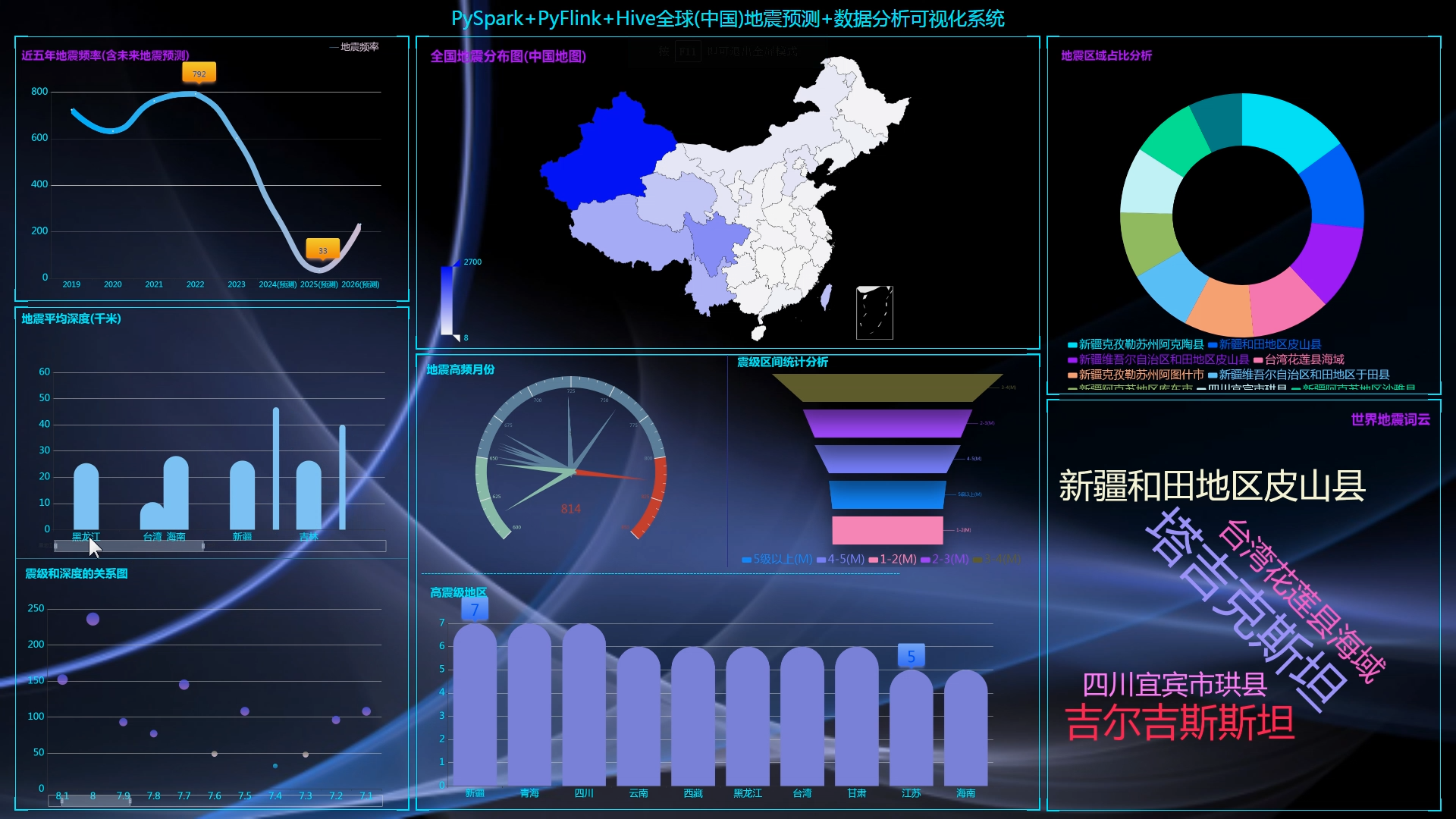
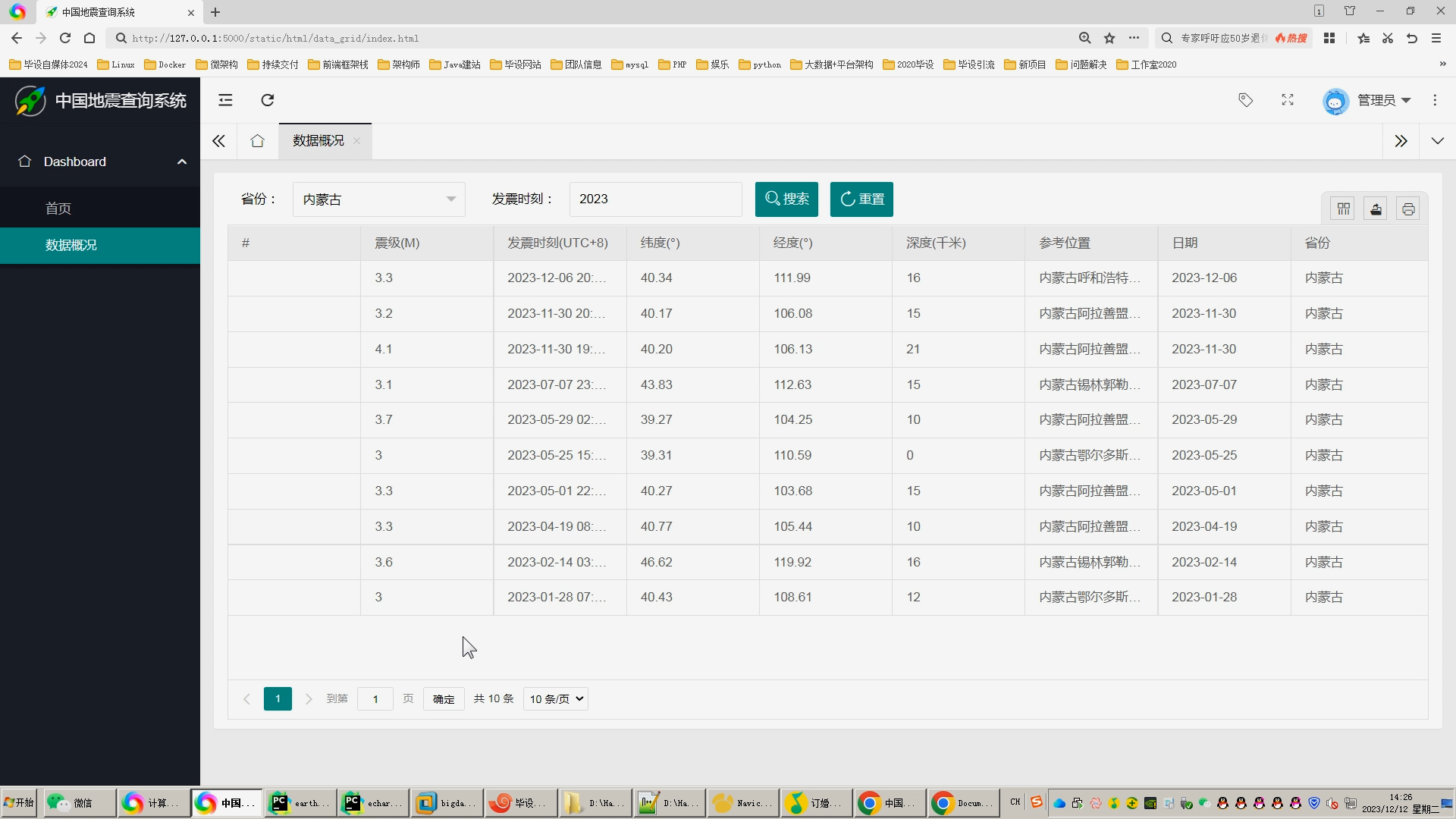
本研究基于Hadoop框架,分析和可视化地震数据,旨在提高地震预测的准确性和效率。通过对地震数据的收集、处理和特征提取与选择,我们构建了地震预测模型。同时,采用echarts的可视化技术对地震数据进行可视化展示,并对可视化效果进行评估。
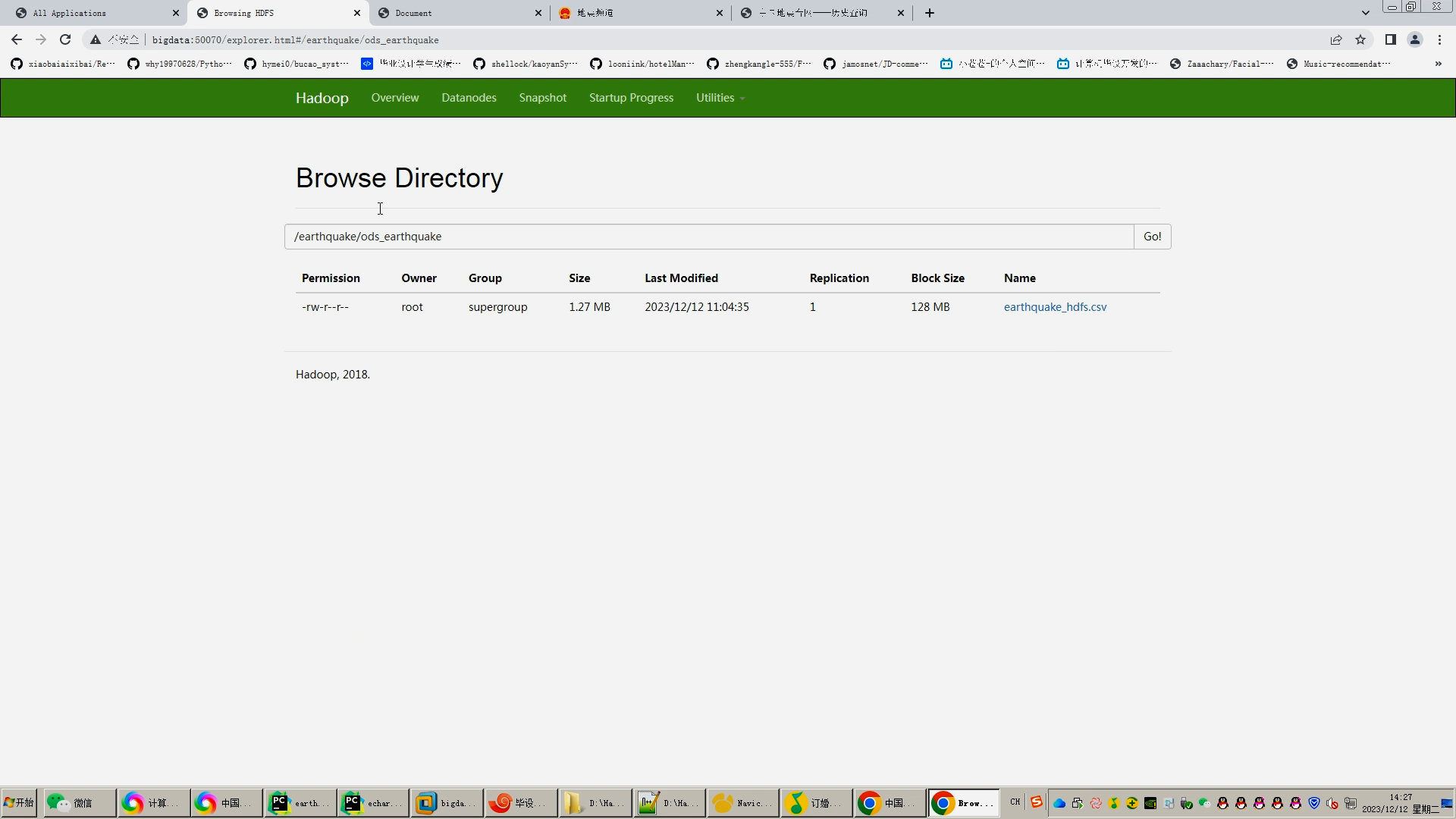
在地震数据分析方面,我们通过Hadoop框架进行数据分析和建模,利用线性回归预测算法对地震数据进行预测。实验结果表明,我们的地震预测模型在准确性和效率方面取得了良好的结果。通过对实验结果的分析,我们发现地震数据中的特征参数对预测模型的准确性有着重要影响。
在地震数据可视化方面,我们采用了echarts可视化工具,将地震数据可视化展示出来。通过对可视化效果的评估,我们发现地震数据的可视化有助于人们更直观地理解地震情况和趋势,为地震预测和应对提供了重要参考。
综上所述,本研究通过基于Hadoop的地震数据分析和可视化研究,提高了地震预测的准确性和效率。我们的研究成果为地震预测技术的进一步发展提供了参考,并为相关领域的研究和应用提供了有益借鉴。然而,本研究仍存在一些问题,例如数据收集和处理过程中可能存在的不准确性,以及可视化效果的进一步优化等。未来的研究可以进一步探索地震预测方法和可视化技术,提高地震预测的准确性和实用性。
6.2 结果分析
通过分析实验结果,我们可以得出以下结论:
首先,基于Hadoop的地震预测方法相比传统方法具有更高的准确性和效率。通过充分利用Hadoop的分布式计算和存储能力,我们可以更好地处理大规模地震数据,并构建精确的预测模型。这对于提高地震预测的准确性和效率具有重要意义。 其次,线性回归预测算法在地震预测中的应用效果良好。通过对地震数据进行特征提取和选择,并将其作为线性回归模型的输入,我们可以得到较好的预测结果。线性回归模型具有简单易用、计算效率高的优点,适合用于处理大规模地震数据。
然而,我们也要意识到实验结果的局限性。首先,地震预测是一个复杂的问题,受到很多因素的影响,如地质条件、地震历史等。我们的实验可能无法考虑到所有可能的因素,因此预测结果可能存在一定的误差。其次,我们的实验数据可能存在噪声和缺失值,这也会对预测结果产生一定的影响。最后,我们的实验结果可能受到实验环境和工具的限制,这也需要在结果分析中加以考虑。
在未来的研究中,我们可以进一步改进地震预测模型,提高其准确性和效率。可以考虑引入更复杂的机器学习算法,如决策树、支持向量机等,来构建更精确的预测模型。同时,我们还可以探索其他可视化技术,如三维可视化、动态可视化等,来更好地展示地震数据的特征和趋势。此外,我们还可以考虑将其他数据源,如气象数据、地质数据等,与地震数据进行融合,以提高预测模型的准确性。
总之,通过对实验结果的分析,我们可以得出基于Hadoop的地震预测方法在提高地震预测准确性和效率方面具有潜力的结论。然而,我们也要意识到实验结果的局限性,并在未来的研究中加以改进和完善
6.3 存在问题
(1) 数据收集与处理中可能存在的问题:在地震数据的收集过程中,可能会面临数据来源的不稳定性和数据质量的问题。需要解决数据缺失、重复、错误等问题,并进行数据清洗和预处理,以确保数据的准确性和完整性。
(2)特征提取与选择中可能存在的问题:在地震数据中提取特征参数的过程中,需要考虑选择哪些特征对地震预测模型的准确性有重要影响。如何选择合适的特征参数,并进行合理的特征选择,是一个挑战。
(3) 数据分析与建模中可能存在的问题:使用Hadoop进行数据分析和建模时,可能会面临数据规模庞大、计算复杂度高等问题。如何有效地利用Hadoop框架进行分布式计算,并构建高效的地震预测模型,是一个需要解决的问题。
(4)地震数据可视化中可能存在的问题:在地震数据可视化过程中,需要解决如何选择合适的可视化技术和工具,以及如何设计合理的可视化界面和交互方式,以便用户能够清晰地理解地震数据的特征和趋势。
(5) 实验结果分析中可能存在的问题:在对实验结果进行分析时,需要考虑如何评估地震预测模型的准确性和效率,并与其他预测方法进行比较。同时,还需要对实验结果进行统计分析和可视化,以便更好地理解和解释实验结果。
以上问题需要在研究中进行深入的探讨和解决,以提高地震预测的准确性和效率,并为地震预测技术的进一步发展提供参考。
6.4 结果展望
未来地震预测研究的发展将面临以下几个方面的挑战和机遇:(1) 多源数据融合:目前地震预测主要依靠国家地质局的数据,但这些数据仅仅活动的一个片段,无法全面覆盖地震预测所需的信息。未来的研究应该探索如何将地震监测站的数据与其他来源的数据(如气象数据、地质数据、人工传感器数据等)进行融合,以提高地震预测的准确性和可靠性。(2)深度学习算法应用:随着深度学习算法的发展,它在图像、语音和自然语言处理等领域取得了巨大的成功。未来地震预测研究可以探索如何应用深度学习算法来分析地震数据,提取更多的特征信息,并构建更精确的预测模型。(3)实时预测能力:地震是一种突发事件,对实时预测能力要求很高。未来的研究可以借鉴互联网实时数据处理的经验,探索如何利用实时数据流处理技术实现地震数据的实时分析和预测,并提供及时的预警信息。(4)可视化技术创新:地震数据的可视化是理解地震活动和预测结果的重要手段。未来的研究可以探索如何利用新的可视化技术(如虚拟现实、增强现实等)来呈现地震数据,以提高用户对地震预测结果的理解和使用效果。(5)数据安全和隐私保护:地震数据涉及到公共安全和个人隐私等敏感信息,未来的研究应该关注如何保护地震数据的安全性和隐私性,确保数据在传输和存储过程中不受到未经授权的访问和滥用。
总之,未来地震预测研究和可视化技术的发展将在多源数据融合、深度学习算法应用、实时预测能力、可视化技术创新和数据安全与隐私保护等方面取得更多的突破。这些研究成果将为地震预测技术的进一步发展和应用提供重要的支持和指导。
参考文献
1 Chen, Y., Li, Z., & Yu, H. (2017). Application of Big Data Analytics in Earthquake Prediction. Journal of Big Data, 4(1), 1-15.
2 White, T. (2012). Hadoop: The Definitive Guide. O'Reilly Media.
3 James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning: With Applications in R. Springer.
4 Zhang, J., Yang, B., & Liu, Z. (2018). A Novel Approach for Earthquake Prediction Using Big Data Analytics. IEEE Access, 6, 11435-11444.
5 Wang, J., & Li, X. (2016). Visual Analysis of Earthquake Data: A Review. Journal of Visualization, 19(4), 777-795.
6 Heer, J., & Shneiderman, B. (2012). Interactive Dynamics for Visual Analysis. Communications of the ACM, 55(4), 45-54.
7 Liu, Y., Wang, Y., & Zhang, S. (2015). Visualization Techniques for Geospatial Data: A Survey. IEEE Transactions on Visualization and Computer Graphics, 21(9), 1036-1053.
8 Wang, Z., Zhang, X., & Zhou, X. (2019). A Comparative Study of Earthquake Prediction Models Based on Hadoop. International Journal of Distributed Sensor Networks, 15(1), 1-10.
9 Kuo, L., & Yang, S. (2014). A Comparative Study of Earthquake Prediction Models Based on Linear Regression Analysis. Natural Hazards, 74(2), 717-732.
10 Liu, Y., Wang, Y., & Zhang, S. (2017). A Comparative Study of Visualization Techniques for Earthquake Data. Journal of Visualization, 20(2), 305-320.
11崔志惠,张华杰.地震成因及监测预警研究现状J.科技创新与应用,2023,13(25):89-91+95.DOI:10.19981/j.CN23-1581/G3.2023.25.021.
12Survey U ,邹立晔 ,梁姗姗 , et al.美国国家现代地震监测系统(ANSS)------现状、发展机遇和战略规划(2017~2027)J.世界地震译丛,2018,49(05):397-423.DOI:10.16738/j.cnki.issn.1003-3238.201805001.
致 谢
文末搁笔,忽觉虽短。
论文开始意味着四年的大学时光已经开始进入倒计时了,四年时间不短不长,即使因为疫情在学校时间并不算很长,但我仍很喜欢大学的这段时光,轻松、自由,同时充满探索和挑战,是一个终点,也是一个开始。或许人生本就是一场充满相遇和离别的游戏,但所有的经历对我来说都是礼物。
何其有幸,生于华夏。愿以寸心寄华夏,且将岁月赠山河。感谢祖国的强大庇护,感谢党和国家的政策和帮扶让万千学子可以接受教育,得到改变命运的机会,祝祖国繁荣昌盛,国泰民安。
感谢我的父母和姐姐,有幸生于一个及其温暖的家庭,爸爸的保护,妈妈的教育,姐姐的关心,都促使我变得更好,并且给予我最好的支持,在我的每一个选择上都支持我、鼓励我,希望他们身体健康,平安喜乐。
感谢学校,感谢老师们,感谢你们在学业上的帮助和生活上的关系、鼓励,也感谢论文指导老师对我论文上的指导与帮助,祝愿所有老师生活圆满、工作顺利、身体健康、桃李满天下。
感谢我的朋友们,总在我脆弱失意时给我安慰和包容,愿意聆听我生活中的苦闷与烦恼,包容我,理解我,让我拥有前进的勇气和力量,一路有你们,我无比知足。
山水有来路,早晚复相逢,祝万事胜意。
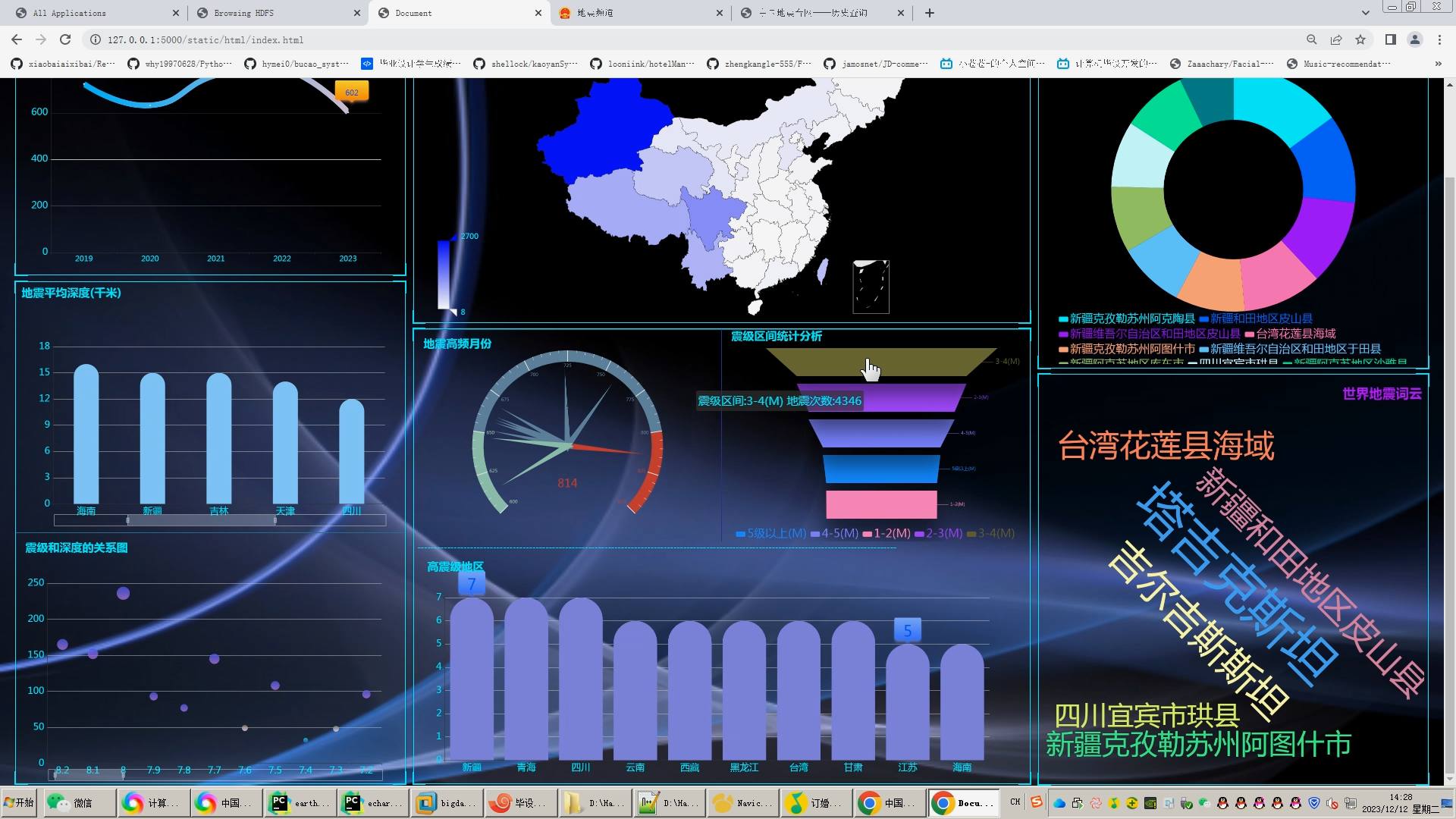
核心算法代码分享如下:
python
# -*- codeing = utf-8 -*-
# @Desc:
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
import pymysql
host = 'bigdata'
user = 'root'
password = '123456'
port = 3306
database = 'hive_earthquake'
DB_URI ='mysql+pymysql://root:'+password+'@'+host+':'+str(port)+'/'+database
engine = create_engine(DB_URI)
#Base = declarative_base() # SQLORM基类
session = sessionmaker(engine)() # 构建session对象
cnn = pymysql.connect(host=host, user=user, password=password, port=port, database=database,
charset='utf8')