ViM: Out-Of-Distribution with Virtual-logit Matching(CVPR2022)
文章目录
- [ViM: Out-Of-Distribution with Virtual-logit Matching(CVPR2022)](#ViM: Out-Of-Distribution with Virtual-logit Matching(CVPR2022))
-
- Abstract
- 1.Introduction
- [2.Related Work](#2.Related Work)
- [3.Motivation: The Missing Info in Logits](#3.Motivation: The Missing Info in Logits)
- [4.Virtual-logit Matching](#4.Virtual-logit Matching)
- [5.OpenImage-O Datase](#5.OpenImage-O Datase)
- 6.Experiment
- 7.Conclusion
实验部分详见原文,文章为原文翻译,如有错误请参照原文
Abstract
-
背景:大多数现有的out - distribution (OOD)检测算法依赖于单一输入源:feature、logit或softmax概率
-
挑战:
- 然而,OOD示例的巨大多样性使得这些方法很脆弱
- 有些OOD样本在特征空间中很容易识别,而在logit空间中很难区分,反之亦然
-
方法:
- 基于这一观察结果,我们提出了一种新的OOD评分方法,称为虚拟逻辑匹配(Virtual-logit Matching, ViM),该方法结合了来自特征空间的类不可知class-agnostic分数和分布内(In-Distribution, ID)类依赖逻辑class-dependent分数(# 1."class-agnostic"和"class-dependent")
- 具体来说,从特征对主空间的残差中生成一个代表虚拟OOD类的附加logit,然后通过常数缩放与原始logit匹配
- 这个虚拟logit在softmax之后出现的概率是OOD-ness的指标
-
贡献:
- 为了方便学术界对大规模OOD检测的评估,我们为ImageNet1K创建了一个新的OOD数据集,该数据集是人工注释的,是现有数据集的8.8倍
- 我们进行了大量的实验,包括cnn和视觉transformer,以证明所提出的ViM评分的有效性
- 特别地,使用BiT-S模型,我们的方法得到了一个平均AUROC在4个困难的OOD基准上达到90.91%,比最佳基准高出4%
- code、dataset:https://github.com/haoqiwang/vim
1.Introduction

Figure 1. The AUROC (in percentage) of nine OOD detection algorithms applied to a BiT model trained on ImageNet-1K. The OOD datasets are ImageNet-O (x-axis) and OpenImage-O (yaxis). Methods marked with box use the feature space; methods with triangle 4 use the logit; and methods with diamond ♦ use the softmax probability. The proposed method ViM (marked with *) uses information from both features and logits.
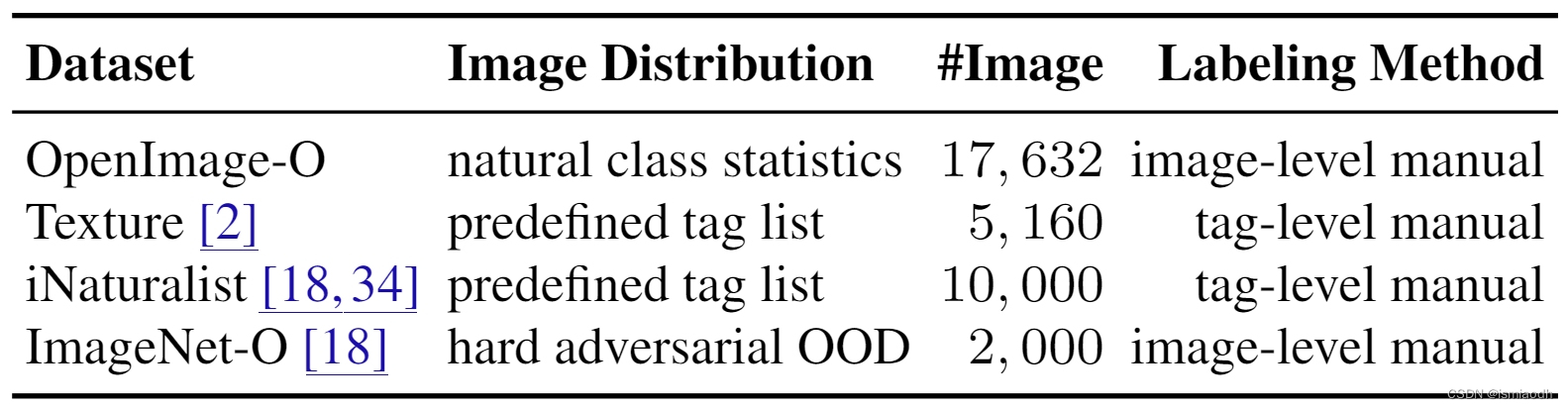
Table 1. OpenImage-O follows natural class statistics, while ImageNet-O is adversarially built to be hard. Both datasets have image-level OOD annotation. Texture and iNaturalist are selected by tags, and their OOD labels are annotated in tag-level.
++1st Para:++
- 考虑到大多数深度图像分类模型都是在封闭世界环境下训练的,当模型被部署到生产环境中,面对来自开放世界的输入时,(OOD)问题就会出现并恶化客户体验
- 例如,一个模型可能错误地但自信地将螃蟹的图像分类为鼓掌类,即使训练集中没有出现与螃蟹相关的概念
- OOD检测是判断输入是否属于训练分布
- OOD检测填补了分类,在自动驾驶、医学分析、工业检测等领域得到应用
- 文献38全面回顾了OOD及其相关主题,包括开放集识别、新颖性检测和异常检测
++2st Para:++
- OOD检测器的核心是一个评分函数 ϕ \phi ϕ,它将输入特征 x x x 映射到 R \mathbb{R} R 中的标量,表明样本在多大程度上可能是OOD
- 在测试中,阈值 τ \tau τ,确保验证集至少保持给定的真阳性率(TPR),例如典型值0.95。如果 ϕ ( x ) > τ \phi(x)>\tau ϕ(x)>τ,则认为输入示例为OOD,否则为ID
- 在方便用分数表示ID的情况下,我们默认将OOD分数的负值作为ID分数
++3st Para:++
- 研究人员通过寻找ID样例自然拥有而OOD样例容易违反的属性(反之亦然),设计了不少评分函数
- score主要来源于三个来源:(1)概率,如softmax的最大概率13、softmax与平均类别分布之间的最小kl -散度12;(2) logit,如最大logit 12, logits上的logsumexp函数;(3)特征,如特征与其低维嵌入的预像之间的残差的范数27,特征与类质心之间的最小马氏距离(# 2.马氏距离)23等
- 在这些方法中,OOD分数可以直接从现有模型中计算出来,而无需重新训练,使得部署变得轻松
- 然而,如图1所示,它们的性能受到其信息源的单一性的限制:单独使用特征忽略了具有类相关信息的分类权重;使用logit或softmax只会忽略零空间中的特征变化3,其中包含与类无关的信息;softmax进一步抛弃了logits范数(# 4.logits norm)(范数(Norm)是数学中用于量化向量大小或长度的概念)
- 为了应对OOD样本中表现出的巨大多样性,我们提出了一个问题,设计一个使用多种来源的OOD分数是否有帮助?
++4st Para:++
- 在现有技术成功的基础上,我们设计了一种新的评分函数,称为虚拟logit匹配(ViM)分数,它是构建虚拟的softmax分数OOD类,其logit由特征和现有logit共同决定
- 具体来说,评分函数首先提取特征对主子空间的残差,然后通过在训练样本上的均值与平均最大logits匹配,将其转换为有效logit
- 最后,所设计的OOD类的softmax概率就是OOD分数
- 从ViM的构造中,我们可以直观地看到,原始logits越小,残差越大,它越有可能是OOD
++5st Para:++
- 与上述方法不同的是,另一项研究通过施加专门的正则化损失5,16,18,40或通过暴露生成的或真实收集的OOD样本22,37,对网络学习到的特征进行调整,以更好地识别ID和OOD
- 由于它们都需要对网络进行再训练,我们在这里简单地提到它们,而不深入研究细节
++6st Para:++
- 近年来,大规模语义空间中的OOD检测受到越来越多的关注12,15,18,29,将OOD检测方法推向了现实应用
- 然而,目前缺乏用于大规模ID数据集的干净、真实的OOD数据集成为该领域的一个障碍
- 以前的OOD数据集是从公共数据集中收集的,这些数据集是用预定义的标签列表收集的,如iNaturalist、Texture和ImageNet-21k(表1)
- 这可能会导致偏倚的性能比较,具体来说,就是在第5节描述的覆盖率较小的可操纵性(# 5.the hackability of small coverage)
- 为了避免这种风险,我们从OpenImage数据集21中为ImageNet-1K4模型构建了一个新的OOD基准,OpenImage- o,具有自然的类分布
- 它包含17,632张手动过滤的图像,比最近的ImageNet-O15数据集大7.8倍
++7st Para:++
- 我们在使用ImageNet-1K作为ID数据集的各种模型上广泛评估了我们的方法
- 模型架构范围从经典的ResNet-5011,到BiT20,到最新的ViT-B16 8, RepVGG 7,DeiT33和Swin Transformer26
- 从OpenImage-O、ImageNet-O,Texture和iNaturalist四个OOD数据集的结果来看,我们发现模型选择影响了许多基线方法的性能,而我们的方法表现稳定
- 特别地,我们的方法在BiT模型下的平均AUROC达到了90.91%,大大超过了最佳基线的平均AUROC为86.62%
++8st Para:++
- 我们的贡献有三个方面:(1) 我们提出了一种新的 OOD(Out-Of-Distribution,分布外)检测方法 ViM,该方法由于有效地融合了特征和 logits 的信息,能够在广泛的模型和数据集上表现良好
- 该方法轻量级且快速,既不需要额外的OOD数据,也不需要重新训练
- (2) 我们在 ImageNet-1K 数据集上进行了全面的实验和消融研究,包括卷积神经网络(CNNs)和视觉(vision transformers)
- 我们策划了一个新的ImageNet-1K的OOD数据集称为OpenImage-O,它非常多样化,包含复杂的场景
- 我们相信这将促进大规模OOD检测的研究
2.Related Work
++1st Para: OOD/ID Score Design++
- Hendrycks等人13提出了一种使用最大预测softmax概率(MSP)作为ID评分的基线方法
- ODIN24通过扰动输入和重新调整对数增强MSP
- Hendrycks等人12也在ImageNet数据集上实验了MaxLogit和KL匹配方法
- 能量分数25计算logits上的logsumexp,ReAct32通过特征裁剪来增强能量评分
- 在27中,使用特征与其低维流形嵌入的预图像之间的差的范数
- Lee等人23计算特征和类智质心之间的最小马氏距离
- NuSA3使用特征向量在分类权重矩阵(这是分类层---通常是最后一层全连接层 的权重矩阵,每一列对应一个类别的权重)列空间上的投影范数与原始特征向量范数的比值作为 ID(分布内)评分
- 在17中,梯度也被用作ID和OOD区分的证据
- 对于使用logits/概率的方法,权重矩阵零空间上的特征变化完全被忽略;而对于对特征空间进行操作的方法,则丢弃了权重矩阵上的类相关信息
- 我们的方法通过虚拟logit的新机制将基于特征的评分和基于逻辑的评分的优点结合起来,并得到了实质性的改进
++2st Para: Network/Loss Design++
-
许多工作通过重新设计训练损失函数使其能够感知分布外数据(OOD-aware),或添加正则项来区分部分分布内(ID)和分布外(OOD)的特征
-
DeVries 等人 5 增加了一个置信度估计分支,将分类错误的分布内样本作为分布外样本的代理
-
MOS 18 修改了损失函数,利用预定义的组结构,使得组内最小的"其他"类概率可以指示分布外数据的可能性
-
Zaeemzadeh 等人 40 在训练过程中强制分布内样本嵌入到多个一维子空间的并集中,并计算特征到各类别子空间的最小角距离
-
Generalized ODIN 16 使用分子/分母结构来编码分解类别概率置信度的先验知识
-
与这些方法不同的是,我们的方法不需要模型再训练,因此不仅更容易应用,而且还保留了ID分类的准确性
++3st Para: OOD Data Exposure++
- Outlier Exposure14利用辅助OOD数据集来改进OOD检测
- Dhamija 等人 6 对来自额外背景类别的样本进行正则化,使其 logits 分布均匀,并且特征范数较小
- Lee等人22利用GAN生成靠近ID样本的OOD样本,并将OOD样本的预测推向均匀分布
- 有几种方法,包括MCD39、NGC36和UDG37可以利用外部未标记的噪声数据来增强OOD检测性能
- 与这些方法不同的是,我们的方法不需要额外的OOD数据,从而避免了对引入的OOD样本的偏差31
3.Motivation: The Missing Info in Logits
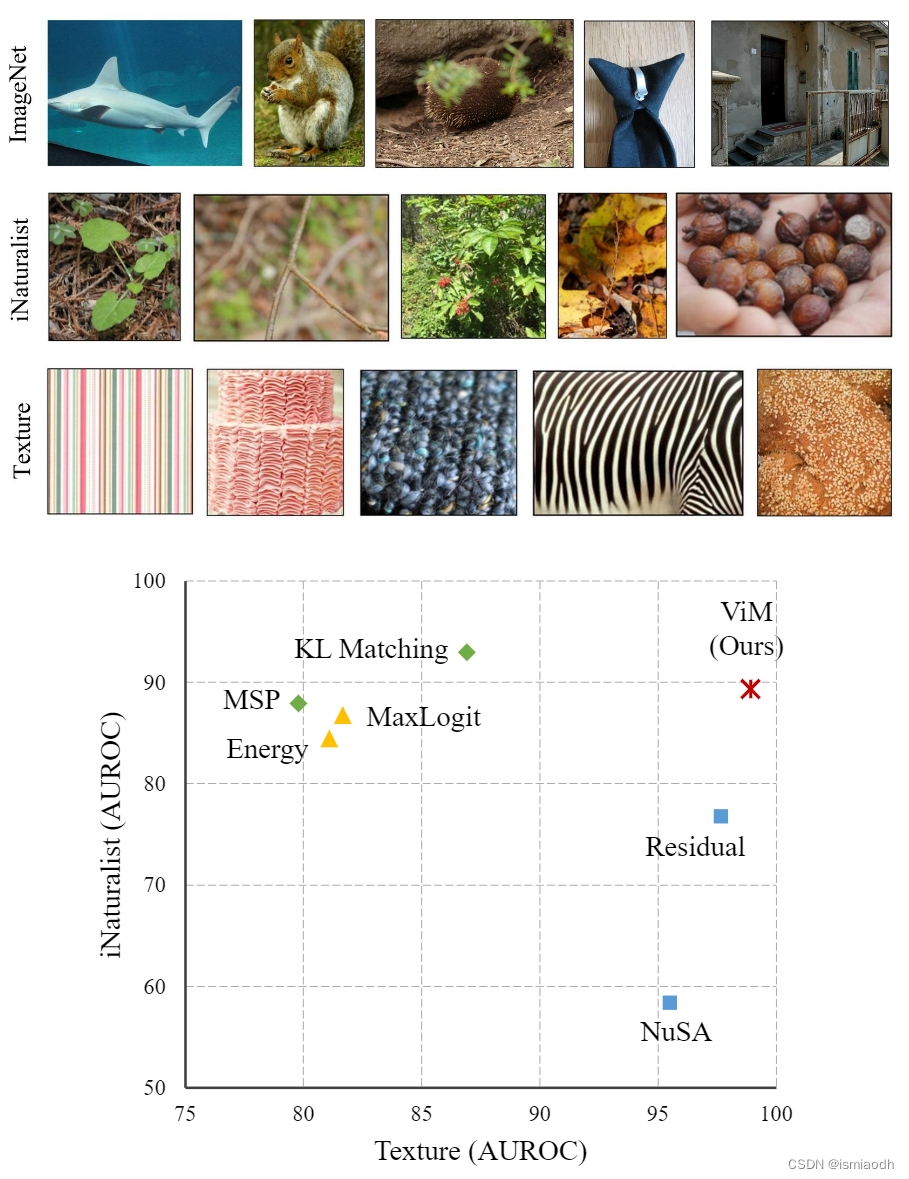
Figure 2. Comparison of AUROC for OOD detection algorithms that are based on probability (marked with diamond ♦), logit (), and feature () of 9 OOD detection algorithms applied to a BiT model trained on ImageNet-1K. The OOD datasets are Texture (xaxis) and iNaturalist (y-axis). Example images for the ID dataset ImageNet-1K and the two OOD datasets are illustrated at the top.
++1st Para:++
- 对于一系列基于logits或softmax概率的OOD检测方法,我们发现它们的性能是有限的
- 在图1中,基于特征的 OOD 评分(例如 Mahalanobis 和 Residual)在检测 ImageNet-O 数据集的 OOD 数据时表现良好,而所有基于 logits/概率的方法则表现较差
- 这并非偶然,如图2所示。最先进的基于概率的方法 KL Matching 的 AUROC 仍然低于在 Texture 数据集上直接设计的特征空间中的 OOD 评分
- 这促使我们研究从特征到logits的丢失信息的影响
++2st Para:++
-
考虑 C C C 分类的模型的logit l ∈ R C l\in\mathbb{R}^C l∈RC 由特征 x ∈ R N x\in \mathbb{R}^N x∈RN 通过FC层的 W ∈ R N × C , b ∈ R C W\in \mathbb{R}^{N\times C},b\in\mathbb{R}^C W∈RN×C,b∈RC 转变,例 l = W T x + b l=W^Tx+b l=WTx+b
-
预测概率 p ( x ) = softmax ( l ) p(x)=\text{softmax}(l) p(x)=softmax(l)
-
为方便起见,我们设点 o : = − ( W T ) + b o:=-(W^T)^+b o:=−(WT)+b , ( ⋅ ) + (\cdot)^+ (⋅)+ 是Moore-Penrose inverse(# 5.Moore-Penrose inverse),作为特征空间新坐标系的原点
l = W T x ′ = W T ( x − o ) , ∀ x . l=W^Tx'=W^T(x-o),\quad\forall x. l=WTx′=WT(x−o),∀x. -
从几何学的角度来看,每个 logit l_i 是特征向量 \\mathbf{x} 和类别向量 w_i (即矩阵 W 的第 i 列)之间的内积
-
在将 logits 泛化为虚拟 logits 时,我们将用子空间替代 w_i ,并用投影替代内积
-
在新的坐标系中,偏置项被省略了
-
在本文的剩余部分,我们假设特征空间使用新的坐标系统
++3st Para:++
- Logits 包含类别相关的信息,但特征空间中有一些无法从 logits 恢复的类别无关信息
- 我们研究了两种情况(零空间和主空间(# 11.零空间和主空间)),并分别讨论了依赖它们的两种 OOD 评分方法(NuSA 和 Residual)
++4st Para: OOD Score Based on Null Space++
- 一个特征 x 可以分解为 x = x^{W^\\perp} + x\^W ,其中 W 是矩阵 W 的列空间, x^{W^\\perp} 和 x\^W 分别是 x 到 W\^\\perp 和 W 的投影
- 其中, W\^\\perp 是矩阵 W\^T 的零空间, W\^{T} x^{W^\\perp}=0
- x W ⊥ x^{W^\perp} xW⊥ 不会影响分类,但是会影响OOD检测
- 在3中已经证明,可以对图像进行强烈扰动,同时限制在 W\^\\perp 中的特征之间的差异
- 得到的离群图像不像任何ID图像,但在分类中保留了很高的置信度
- 利用这一点,他们将ID分数NuSA(零空间分析)定义为(# 12.OOD样本在零空间的比例更大)
N u S A ( x ) = ∥ x ∥ 2 − ∥ x W ⊥ ∥ 2 ∥ x ∥ . \mathrm{NuSA}(x)=\frac{\sqrt{\|x\|^2-\|x^{W^\perp}\|^2}}{\|x\|}. NuSA(x)=∥x∥∥x∥2−∥xW⊥∥2 .
- 直观地说,NuSA 使用特征 $ x $ 和 $ W $ 之间的角度(即 $ \\text{arccos}(\\text{NuSA}(x)) $)来表示其分布外(OOD)的程度(# 9.NuSA角距离)
- 从图2中我们可以看到,简单的角度信息清晰地区分了在纹理数据集中的分布外示例,其 AUROC 为95.50%,超过了基于 logits 和基于 softmax 概率的竞争方法 KL Matching
++5st Para: OOD Score Based on Principal Space++
-
通常假设特征位于低维流形\](# 6.流形)中 \[27, 40
- 为了简化,我们使用通过原点 o 的线性子空间(在新的坐标系中)作为模型
- 我们将主空间定义为由矩阵 X\^T X 的最大 $ D $ 个特征值对应的特征向量所张成的 $ D $ 维子空间 $ P $(# 8.子空间),其中 X 是 ID 数据矩阵
- 偏离主空间的特征可能是OOD
- 我们可以定义:
R e s i d u a l ( x ) = ∥ x P ⊥ ∥ , \mathrm{Residual}(x)=\|x^{P^\perp}\|, Residual(x)=∥xP⊥∥,
- 捕捉特征与主空间的偏差
- 这里 x = x\^P + x^{P^\\perp} ,其中 x^{P^\\perp} 是 x 在 P\^\\perp 上的投影
- 残差分数与27中的重构误差相似,不同之处在于它们采用了非线性流形学习(# 7.非线性流形学习)进行降维
- 请注意,在投影到 logits 上之后,这种偏差会受到损害,因为矩阵 W\^T 投影到的空间维度低于特征空间的维度
- 图2显示,残差分数在两个数据集上的表现都优于NuSA分数,使得基于特征的方法与基于logit概率的方法之间的性能对比更加显著
++6st Para: Fusing Class-dependent and Class-agnostic Information++
- 与logit概率方法相反,NuSA和残差都不考虑特定于单个ID类的信息,即它们是类无关的
- 因此,这些分数忽略了与每个ID类的特征相似性,并且忽略了输入与哪个类最相似
- 这就解释了为什么它们在iNaturalist OOD基准测试中表现较差,因为iNaturalist样本需要区分细粒度类之间的细微差异
- 我们假设统一特征空间和逻辑信息可以提高在更广泛类型的OOD上的检测性能
- 这样的解决方案将在第4节中使用虚拟逻辑的概念提出
4.Virtual-logit Matching
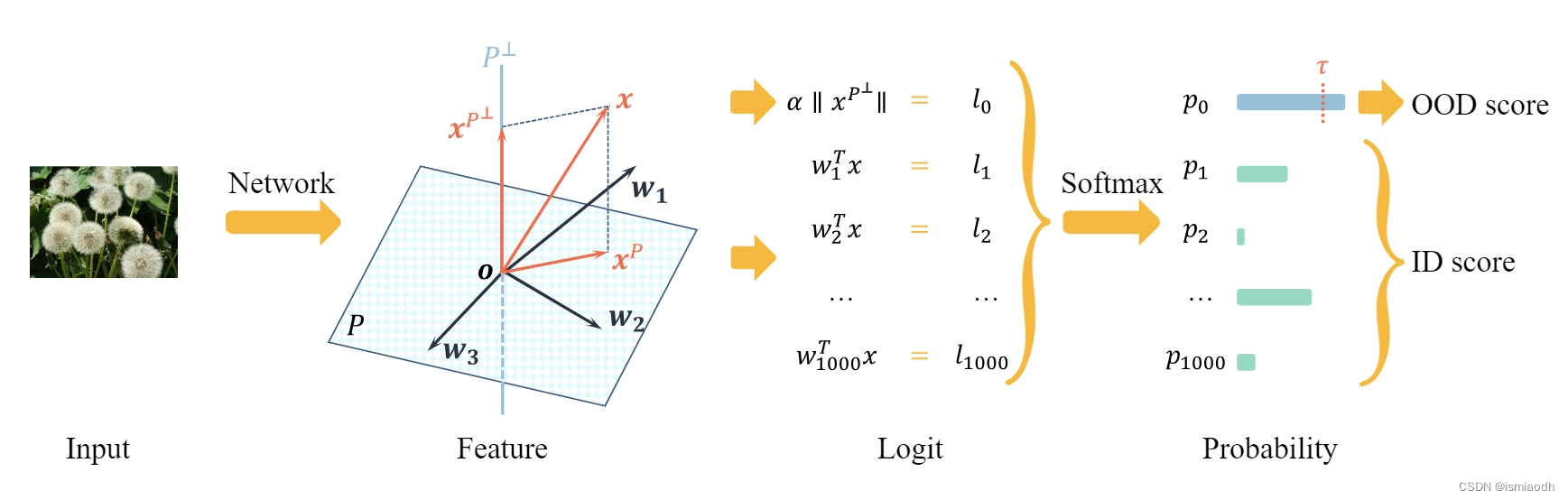
Figure 3. The pipeline of ViM. The principal space P P P and the matching constant α \alpha α are determined by the training set beforehand using Eq. (4) and Eq. (6). In inference, feature x x x is computed by the network, and the virtual logit α ∣ ∣ x P ⊥ ∣ ∣ \alpha||x^{P^\perp}|| α∣∣xP⊥∣∣ is computed by projection and scaling. After softmax, the probability corresponding to the virtual logit is the OOD score. It is OOD if the score is larger than threshold τ \tau τ .
++1st Para:++
- 为统一类别无关和类别相关信息用于分布外(OOD)检测,我们提出了一种通过虚拟对数匹配(Virtual-logit Matching,简称ViM)计算OOD得分的方法
- 该流程如图3所示,其中有三个步骤,分别对特征、对数和概率进行操作
- 具体来说,对于特征 x ,(1)提取 x 相对于主空间 P 的残差 x^{P^\\perp} ;(2)通过重新缩放将范数 \|x^{P^\\perp}\| 转换为虚拟对数;(3)输出虚拟对数的softmax概率作为ViM得分
- 下面我们给出更多细节
- 回顾一下符号定义: C 是类别数, N 是特征维度, W 和 b 分别是分类权重和偏置
++2st Para: Principal Subspace and Residual++
- 首先,我们通过一个向量 o = -(W^T)^+ + b 来偏移特征空间,使其在计算对数值时不受偏置的影响,如Eq.(1)所示
- 主子空间 P 是由训练集 X 定义的,其中行是新坐标系中以 o 为原点的特征
- 对矩阵 X\^T X 进行了特征分解
X T X = Q Λ Q − 1 , X^TX=Q\Lambda Q^{-1}, XTX=QΛQ−1,
- 特征值按降序排列在矩阵 \\Lambda 中,那么前 D 列的张成空间是 D 维的主子空间 P
- 残差 x^{P^\\perp} 是 x 在 P\^\\perp 上的投影,在公式(4)中,将第 (D+1) 列到最后一列的 Q 定义为新矩阵 R \\in \\mathbb{R}\^{N \\times (N-D)} ,那么 x^{P^\\perp} = R R\^T x (可能是: x^{P^\\perp} = R\^T x )
- 残差 x^{P^\\perp} 被送往下一步骤继续处理
++3st Para: Virtual-logit Matching++
- 虚拟对数值是通过每个模型的常数 \\alpha 重新调整残差范数后的值
l 0 : = α ∥ x P ⊥ ∥ = α x T R R T x l_0:=\alpha\|x^{P^\perp}\|=\alpha\sqrt{x^TRR^Tx} l0:=α∥xP⊥∥=αxTRRTx
- 残差范数 \|x^{P^\\perp}\| 不能直接用作新的对数值,因为后续的 softmax 操作会在对数值的指数上进行归一化,这对对数值的尺度非常敏感(# 10.常数调整)
- 如果残差相对于最大的对数值非常小,那么在进行 softmax 操作后,残差的影响会被对数值的噪声所掩盖
- 为了匹配虚拟对数值的尺度,我们计算训练集上虚拟对数值的平均范数以及训练集上最大对数值的均值
α : = ∑ i = 1 K max j = 1 , ... , C { l j i } ∑ i = 1 K ∥ x i P ⊥ ∥ , \alpha:=\frac{\sum_{i=1}^K\max_{j=1,\dots,C}\{l_j^i\}}{\sum_{i=1}^K\|x_i^{P^\perp}\|}, α:=∑i=1K∥xiP⊥∥∑i=1Kmaxj=1,...,C{lji},
- 其中 x_1, x_2, \\ldots, x_K 是均匀采样的 K 个训练样本,且 l_{i}\^j 是 x_i 的第 j 个对数值
- 通过这种方式,虚拟对数值的平均尺度与原始对数值中的最大值相同
++4st Para: The ViM Score++
- 我们将虚拟对数值追加到原始的对数值中,然后计算 softmax
- 将虚拟逻辑所对应的概率定义为ViM
- 数学上,假设 x 的第 i 个对数值是 l_i ,那么得分(score)是
V i M ( x ) = e α x T R R T x ∑ i = 1 C e l i + e α x T R R T x . \mathrm{ViM}(\boldsymbol{x})=\frac{e^{\alpha\sqrt{\boldsymbol{x}^T\boldsymbol{R}\boldsymbol{R}^T\boldsymbol{x}}}}{\sum_{i=1}^Ce^{l_i}+e^{\alpha\sqrt{\boldsymbol{x}^T\boldsymbol{R}\boldsymbol{R}^T\boldsymbol{x}}}}. ViM(x)=∑i=1Celi+eαxTRRTx eαxTRRTx .
- 这个方程显示了影响 ViM 分数的两个因素:如果原始的对数值较大,那么它更不可能是 OOD(Out-of-Distribution)例子;而如果残差的范数较大,则更有可能是 OOD
- 计算开销与分类网络中的最后一个全连接层(从特征到对数值的映射)相比是可接受的,非常小
++5st Para: Connection to Existing Methods++
- 注意,对分数应用严格的递增函数不会影响OOD评估
- 应用函数 t(x) = -\\ln \\left( \\frac{1}{x} - 1 \\right) 到 ViM 分数上,然后我们得到一个等价的表达式
α ∥ x P ⊥ ∥ − ln ∑ i = 1 C e l i . \alpha\|x^{P^\perp}\|-\ln\sum_{i=1}^Ce^{l_i}. α∥xP⊥∥−lni=1∑Celi.
- 第一项为Eq. (5)中的虚拟对数,第二项为能量分数25
- ViM通过提供来自特征的额外残差信息来完善能量方法
- 其性能远远优于能量方法和残差方法
5.OpenImage-O Datase
6.Experiment
7.Conclusion
- 在本文中,我们提出了一种新颖的OOD检测方法:虚拟对数值匹配(ViM)分数
- 该方法结合了特征空间和对数值中的信息,分别提供了与类别无关的信息和与类别相关的信息
- 大量的大规模OOD基准测试显示了该方法的有效性和鲁棒性
- 特别是,我们在基于CNN的模型和基于Transformer的模型上测试了ViM,展示了其在不同模型架构上的鲁棒性
- 为了促进大规模OOD检测的评估,我们为ImageNet-1K创建了高质量和大规模的OpenImage-O数据集