论文阅读笔记:Cross-Image Relational Knowledge Distillation for Semantic Segmentation
- [1 背景](#1 背景)
- [2 创新点](#2 创新点)
- [3 方法](#3 方法)
- [4 模块](#4 模块)
-
- [4.1 预备知识](#4.1 预备知识)
- [4.2 跨图像关系知识蒸馏](#4.2 跨图像关系知识蒸馏)
- [4.3 Memory-based像素到像素蒸馏](#4.3 Memory-based像素到像素蒸馏)
- [4.4 Memory-based像素到区域蒸馏](#4.4 Memory-based像素到区域蒸馏)
- [4.5 整体框架](#4.5 整体框架)
- [5 效果](#5 效果)
论文:https://arxiv.org/pdf/2204.06986
代码:https://github.com/winycg/CIRKD
1 背景
本文在面向语义分割的高容量教师网络的指导下,研究KD以提高学生网络的性能。广泛的KD方法已经得到很好的研究,但主要用于图像分类任务。与图像级别的识别不同,分割任务针对的事更稠密的像素预测,更具挑战性。之前的研究发现,直接使用基于分类的KD方法来处理稠密预测,可能达不到理想的性能。
这是因为严格对齐教师和学生网络之间的粗略特征图可能会导致负约束,并忽略像素之间的结构化上下文。
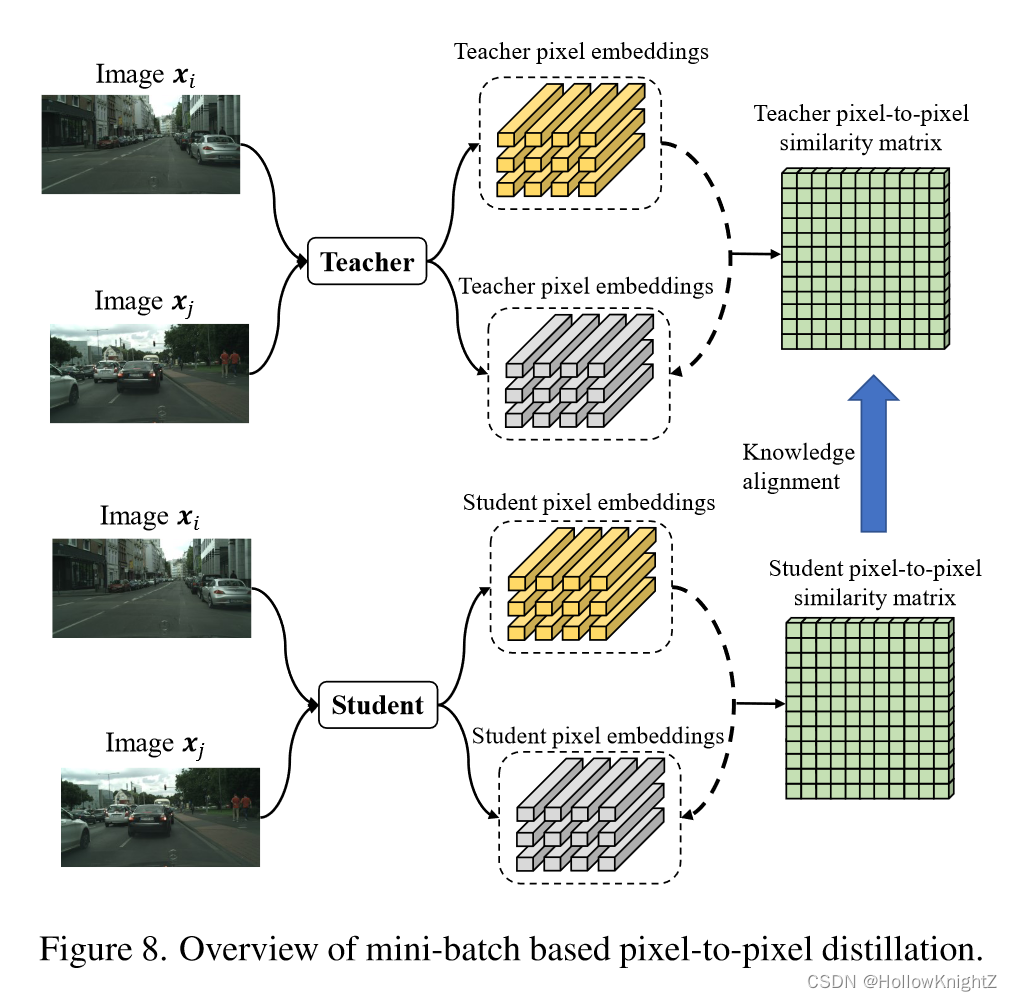
最近提出用于语义分割的KD方法中,大部分都关注挖掘空间像素位置之间的相关性和依赖性,因为分割需要结构化的输出。这类方法在捕捉结构化的空间知识方面往往比传统的点对齐方式表现的更好。然而,以往的分割KD方法往往引导学生模仿教师从个体数据中产生的结构化信息,它忽略了利用像素之间的跨图像语义关系来传递知识,如图8所示。
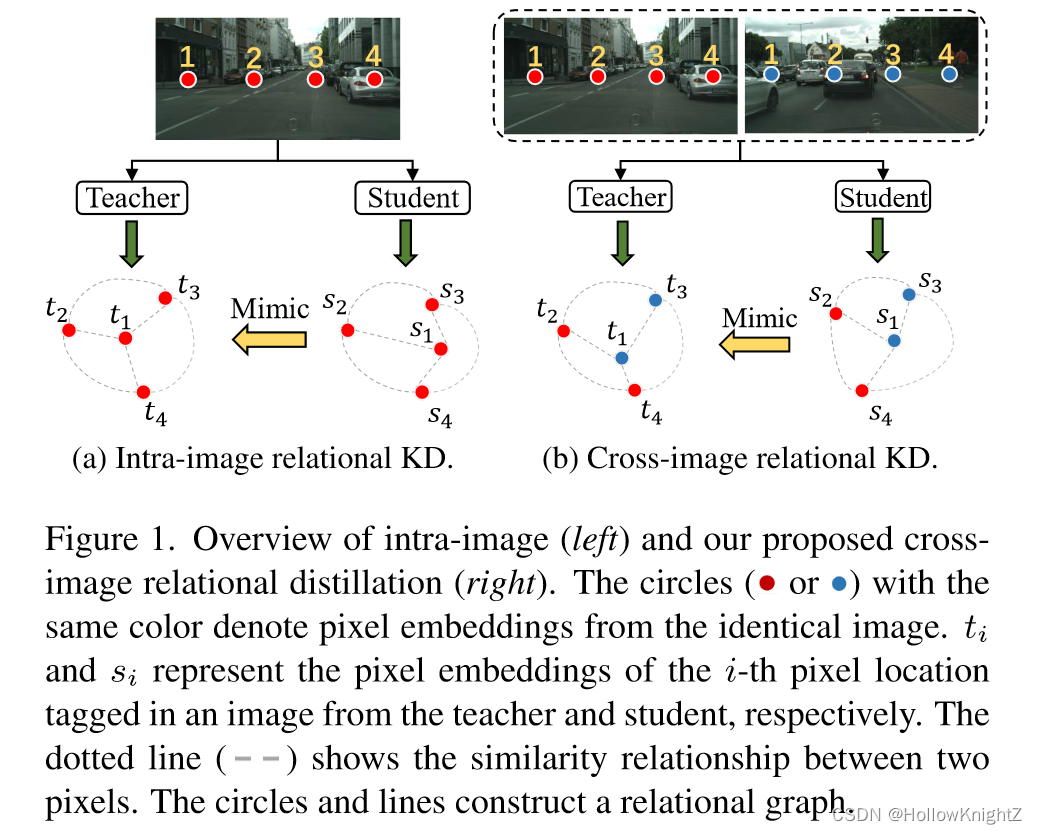
基于这一动机,本文提出了跨图像关系知识蒸馏(Cross-Imge Relational Knowledge distillation,CIRKD)。其核心思想是构建跨整个训练图像的全局像素作为有意义的知识。一个好的预训练教师网络往往可以生成一个良好的像素嵌入空间,并捕获比学生网络更好的像素相关性。基于这个性质,作者将这种像素关系从教师转移到学生。具体来说,就是提出了像素到像素蒸馏和像素到区域蒸馏,以充分利用各种图像之间的结构化关系,前者旨在传递图像嵌入之间的相似性分布,后者侧重于转移与前者互补的像素到区域的相似性分布。区域嵌入通过平均池化来自同一类别的像素嵌入生成,并代表该类别的特征中心。像素到区域的关系表明像素和原类型之间的相对相似性。
如图1,具有相同颜色的圆表示来自同一图像的像素嵌入。 t i t_i ti 和 s i s_i si 分别表示教师和学生图像中标记的第 i i i 个像素位置的像素嵌入。虚线表示两个像素之间的相似性关系。
2 创新点
(1)提出了跨图像关系知识蒸馏来传递全局像素关系。
(2)提出了像素到像素和像素到区域蒸馏的内存库机制,以充分探索用于传输的结构化关系。
(3)CIRKD在公共分割数据集上取得了最先进方法中最好的蒸馏性能。
3 方法
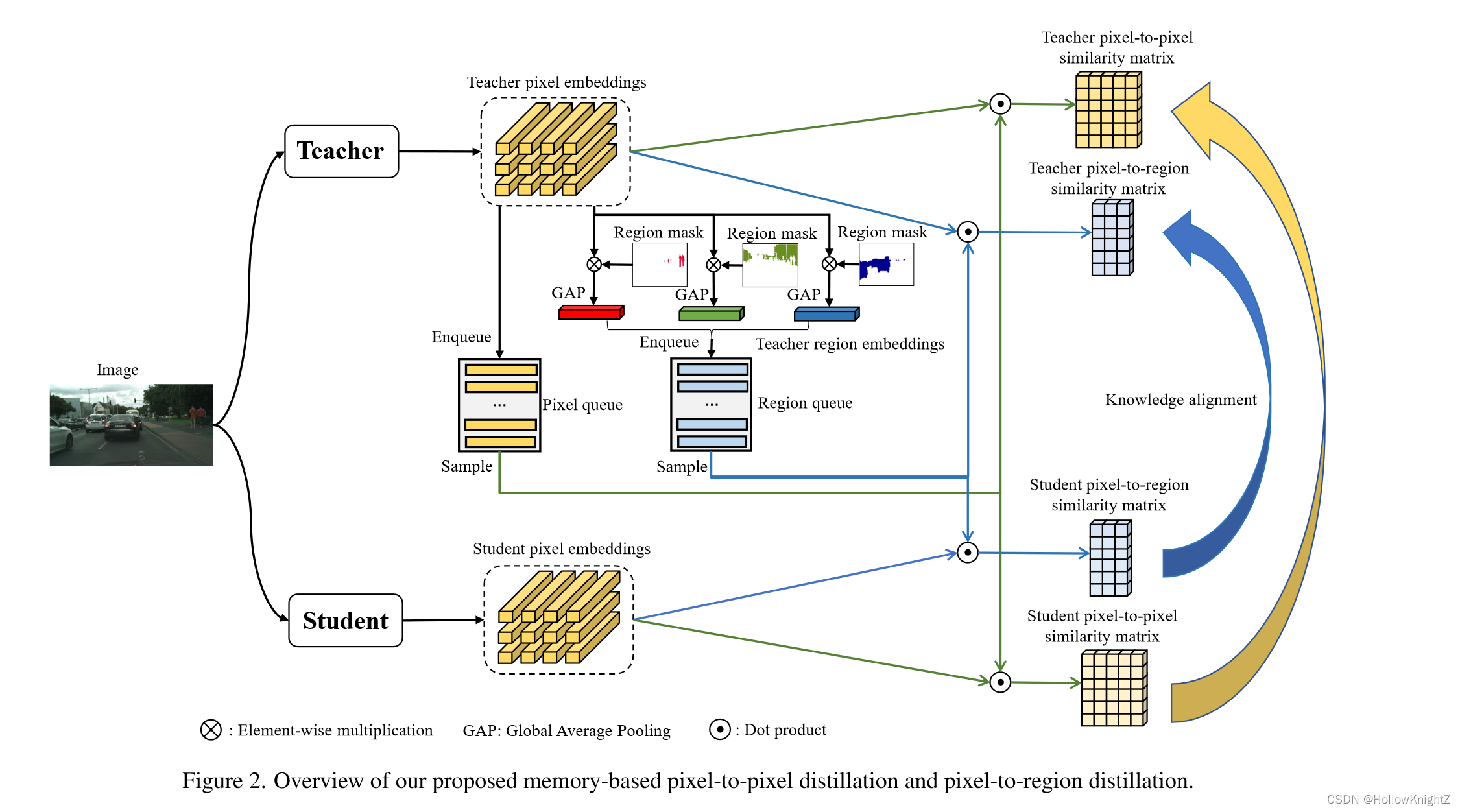
输入网络将教师网络的像素嵌入经过不同处理分别存储到在线像素队列和在线区域队列。同时,计算当前图像经过teacher和student的图像嵌入,和像素嵌入队列中采样的像素嵌入分别计算像素到像素的相似度矩阵,和在线区域队列采样的区域嵌入计算像素到区域的相似度矩阵,并进行对齐。
4 模块
4.1 预备知识
一个分割网络需要将图像中的每个像素从 C C C 类中分类到一个单独的类别标签。该网络可以分解为一个特征提取器和一个分类器。前者生成稠密特征图 F ∈ R H × W × d F∈R^{H × W × d} F∈RH×W×d,其中 H H H, W W W 和 d d d 分别表示通道的高度,宽度和数量。可以推理出沿空间维度的 H × W H × W H×W 像素嵌入。后者进一步将 F F F 转化为分类logit映射 Z ∈ R H × W × C Z∈R^{H × W × C} Z∈RH×W×C。传统的分割任务损失是使用交叉熵对每个像素及其真实标签进行训练:
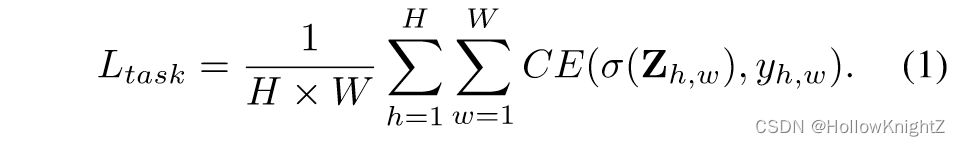
其中 CE 表示交叉熵损失, σ \sigma σ 表示softmax函数, y h , w y_{h,w} yh,w 表示第(h,w)个像素。
一种直接的像素级分类概率蒸馏方法是将每个像素的类别概率分布从学生到对齐到教师,公式表示为:
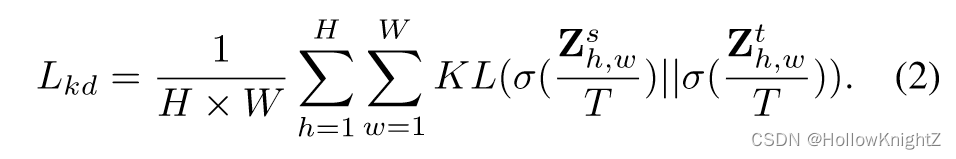
这里 σ ( Z h , w s / T ) \sigma(Z_{h,w}^s/T) σ(Zh,ws/T) 和 σ ( Z h , w t / T ) \sigma(Z_{h,w}^t/T) σ(Zh,wt/T) 表示学生和教师产生的第(h,w)个像素的软类别概率。 K L KL KL 表示KL散度, T T T 是温度,在之前的工作中 T = 1 T=1 T=1 是足够好的。
4.2 跨图像关系知识蒸馏
虽然式(1)(2)的训练目标被广泛应用于语义分割,但他们只独立处理像素级的预测,而忽略了像素之间的语义关系。一些分割KD方法试图通过像素亲和度建模来捕获空间关系知识。然而,这些KD方法只构建了单幅图像中像素之间的语义依赖关系。本文论证了跨图像关系知识对于基于师生模型的知识蒸馏也是有帮助的。
给定一个 mini-batch { x n } n = 1 N \{x_n\}^N_{n=1} {xn}n=1N,分割网络从 N N N 幅输入图像中提取N个结构化特征图 { F n ∈ R H × W × d } n = 1 N \{F_n∈R^{H×W×d}\}^N_{n=1} {Fn∈RH×W×d}n=1N。通过 l2 归一化对 F n F_n Fn 中的每个像素嵌入进行预处理。为了便于记号,将 { F n ∈ R H × W × d } n = 1 N \{F_n∈R^{H×W×d}\}^N_{n=1} {Fn∈RH×W×d}n=1N的空间维数重新定义为 { F n ∈ R A × d } n = 1 N \{F_n∈R^{A×d}\}^N_{n=1} {Fn∈RA×d}n=1N,其中 A = H × W A = H × W A=H×W。对于第 i i i 幅图像 x i x_i xi 和第 j j j 幅图像 x j x_j xj, i , j ∈ { 1 , 2 , ⋅ ⋅ ⋅ , N } i,j∈\{ 1,2,· · ·,N \} i,j∈{1,2,⋅⋅⋅,N},可以计算跨图像两两相似度矩阵 S i j = F i F j T > j ∈ R A × A S_{ij} = F_iF_j^T > j∈R^{A × A} Sij=FiFjT>j∈RA×A。关系矩阵 S i j S_{ij} Sij 捕捉了像素间的跨图像成对相关性。
引导学生产生的成对相似性矩阵 S i j s S_{ij}^s Sijs 与教师产生的成对相似度矩阵 S i j t S_{ij}^t Sijt 对齐。蒸馏过程表述为:

其中, S i j ∣ a , : S_{ij|a,:} Sij∣a,: 表示 S i j S_{ij} Sij 的第 a a a 行。通过softmax函数 σ \sigma σ 将 S i j S_{ij} Sij 的每行相似度分布归一化为一个与温度 τ \tau τ 相关的概率分布。由于softmax归一化,学生网络和教师网络之间的数量级差异将被消除。 K L KL KL 散度用于对齐每一行的概率分布。对 N N N 幅图像中的每两幅图像进行像素到像素的蒸馏:
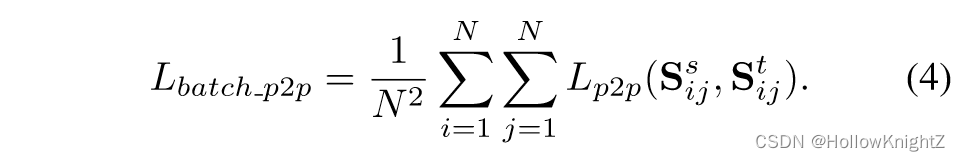
4.3 Memory-based像素到像素蒸馏
虽然mini-batch的蒸馏可以在一定程度上捕获跨图像关系,但由于分割任务的每个GPU的batch大小通常较小,例如1或2,因此很难从全局图像中建模依赖关系。为了解决这个问题,作者引入了一个在线像素队列,该队列可以在过去的mini-batch生成的存储库中存储大量的像素嵌入。这样就可以高效的检索到丰富的嵌入。
在密集分割任务重,每幅图像都会包含大量的像素样本,而同一目标区域的大多数像素往往是同质的。因此,存储所有像素可能会学习到冗余的关系知识,并减慢蒸馏过程。此外,将最后几个batch保存到队列中也可能会破坏像素嵌入的多样性。因此,作者使用了一个对类别敏感的像素嵌入队列 Q p ∈ R C × N p × d Q_p ∈ R^{C×N_p×d} Qp∈RC×Np×d,其中 N p N_p Np 是每个类的像素嵌入个数, d d d 是嵌入大小。对于小批次图像中的每一幅图像,只随机采样一小部分 V V V,即 V < < N p V <<N_p V<<Np,将来自同一类别的像素嵌入推送到像素队列 Q p Q_p Qp 中,随着蒸馏的进行,队列在先进先出策略下逐步更新。
受论文《Seed: Self-supervised distillation for visual representation》在学生和教师网络之间采用一个共享的像素队列,并存储教师在蒸馏过程中产生的像素嵌入。给定图像 x n x_n xn ,学生网络和教师网络生成的像素嵌入分别为 F n s ∈ R A × d F_n^s∈R^{A×d} Fns∈RA×d 和 F n t ∈ R A × d F_n^t∈R^{A×d} Fnt∈RA×d。对 F n s F_n^s Fns 和 F n t F_n^t Fnt 的每个像素嵌入进行 L2归一化处理。将 F n s F_n^s Fns 和 F n t F_n^t Fnt 作为锚点,从像素队列 Q p Q_p Qp 中随机采样 K p K_p Kp 个对比嵌入 { v k ∈ R d } k = 1 K p \{v_k∈R^d\}{k=1}^{K_p} {vk∈Rd}k=1Kp,这里采用类别平衡采样,因为来自不同类别的像素数通常符合长尾分布。为了方便表述,令 V p = v 1 , v 2 , ... , v K p ∈ R K p × d V_p=v_1,v_2,...,v_{K_p}∈R^{K_p×d} Vp=v1,v2,...,vKp∈RKp×d 是 { v k ∈ R d } k = 1 K p \{v_k∈R^d\}{k=1}^{K_p} {vk∈Rd}k=1Kp 沿着行维度拼接。然后,将学生和教师的锚点和对比嵌入之间的像素相似度矩阵建模为 P s P^s Ps 和 P t P^t Pt:
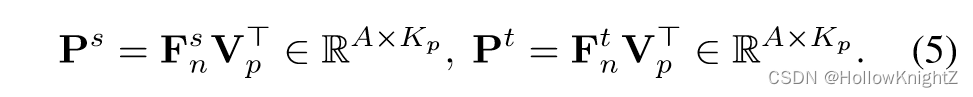
教师网络的像素相似度矩阵往往表现比学生网络更好。强迫学生的 P s P^s Ps 模仿教师的 P t P^t Pt 来惩罚差异。类似的,对 P s P^s Ps 和 P t P^t Pt 每一行分布进行softmax归一化,并通过KL散度损失进行像素到像素的蒸馏。公式如下:
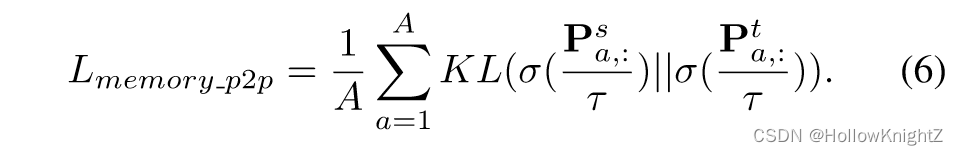
每次迭代后,将每类的 V 个教师像素嵌入推进像素队列 Q p Q_p Qp 中。
4.4 Memory-based像素到区域蒸馏
离散的像素嵌入可能无法完全捕捉图像内容。因此,作者又引入了一个在线区域队列,可以在内存库中存储大量更具代表性的区域嵌入。除了像素到像素的蒸馏,进一步构建像素到区域的蒸馏来建模全局图像中像素和类别区域嵌入之间的关系。每个区域嵌入表示图像中一个语义类的特征中心。通过平均池化单幅图像中属于 c c c 类的所有像素嵌入来构造 c c c 类的区域嵌入。
在蒸馏过程汇中保持一个区域队列 Q r ∈ R C × N r × d Q_r∈R^{C×N_r×d} Qr∈RC×Nr×d,其中 N r N_r Nr 是每个类的区域嵌入个数, d d d 是嵌入大小,对于每一次迭代,从 Q r Q_r Qr 中进行类平衡采样 K r K_r Kr 个对比区域嵌入 { r k ∈ R d } k = 1 K r \{r_k∈R^d\}{k=1}^{K_r} {rk∈Rd}k=1Kr,为了方便表述,令 V r = r 1 , r 2 , ... , r K r ∈ R K r × d V_r=r_1,r_2,...,r_{K_r}∈R^{K_r×d} Vr=r1,r2,...,rKr∈RKr×d 是 { r k ∈ R d } k = 1 K r \{r_k∈R^d\}{k=1}^{K_r} {rk∈Rd}k=1Kr 沿着行维度拼接。给定输入图像 x n x_n xn,将从像素嵌入 F n s ∈ R A × d F^s_n∈R^{A × d} Fns∈RA×d 和 F n t ∈ R A × d F^t_n∈R^{A × d} Fnt∈RA×d 到区域嵌入 V r V_r Vr 建模为像素到区域的相似度矩阵 R s R^s Rs 和 R t R^t Rt :
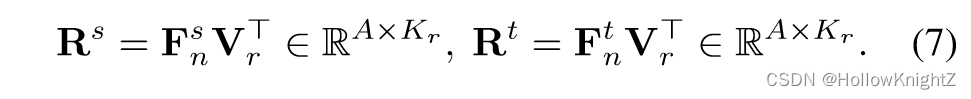
与式(6)相似,通过KL -散度损失提取学生和教师网络之间的归一化像素-区域相似性矩阵:
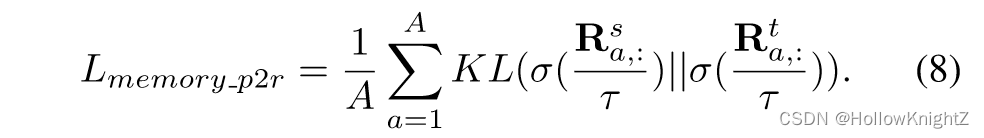
对于每个小批次,将所有教师区域嵌入推入区域队列 Q r Q_r Qr 。
4.5 整体框架
整体框架如图2。损失函数上,采用传统的逐像素交叉熵损失 L t a s k L_{task} Ltask 和 类概率蒸馏损失 L k d L_{kd} Lkd 作为基础损失,总损失为:
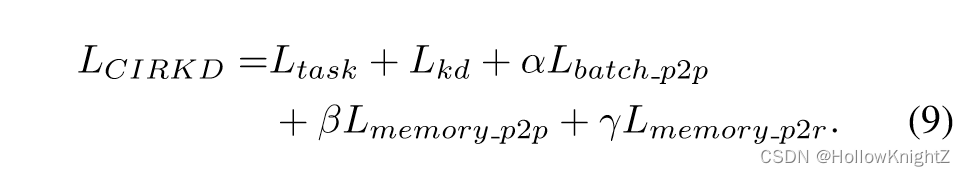
其中, α , β , γ \alpha,\beta,\gamma α,β,γ 是权重系数。实验中设置 α = 1 , β = 0.1 , γ = 0.1 \alpha=1,\beta=0.1,\gamma=0.1 α=1,β=0.1,γ=0.1。当学生网络和教师网络的嵌入大小不匹配时,可以在学生网络上加入一个投影头,由两个 1×1 卷积层, ReLU 和 BN层组成,在推理时丢弃,不会引入额外推理成本。
CIRKD的整体训练pipeline如算法1。

5 效果
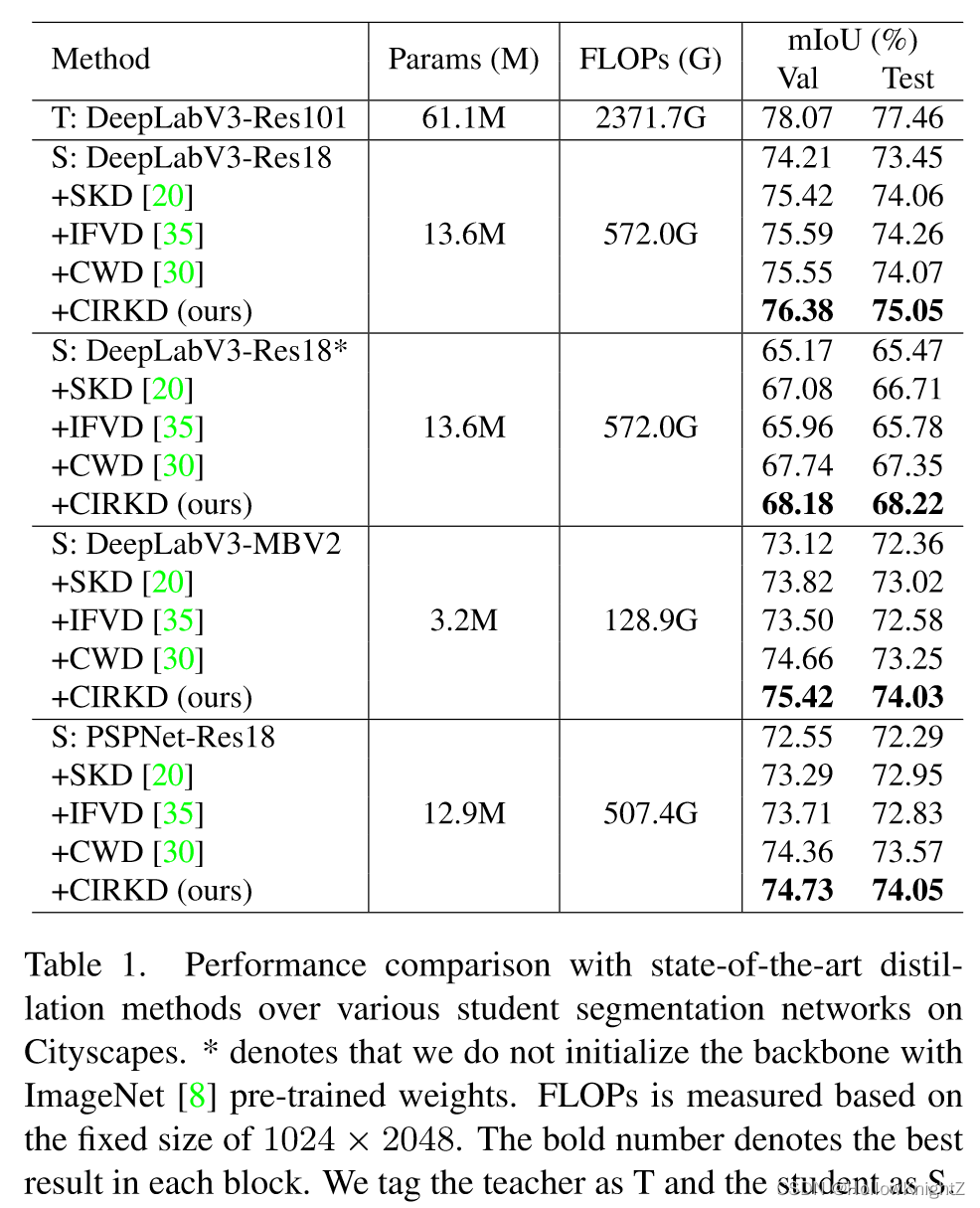
在CityScapes上的效果对比如表1。
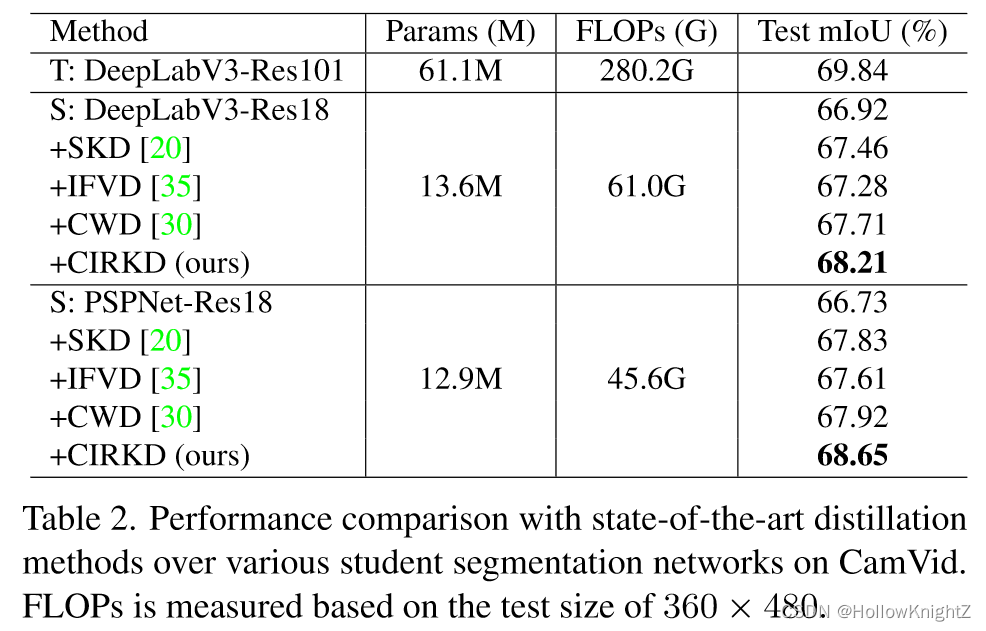
在CamVid上的效果对比如表2。
在VOC上的效果对比如表3。
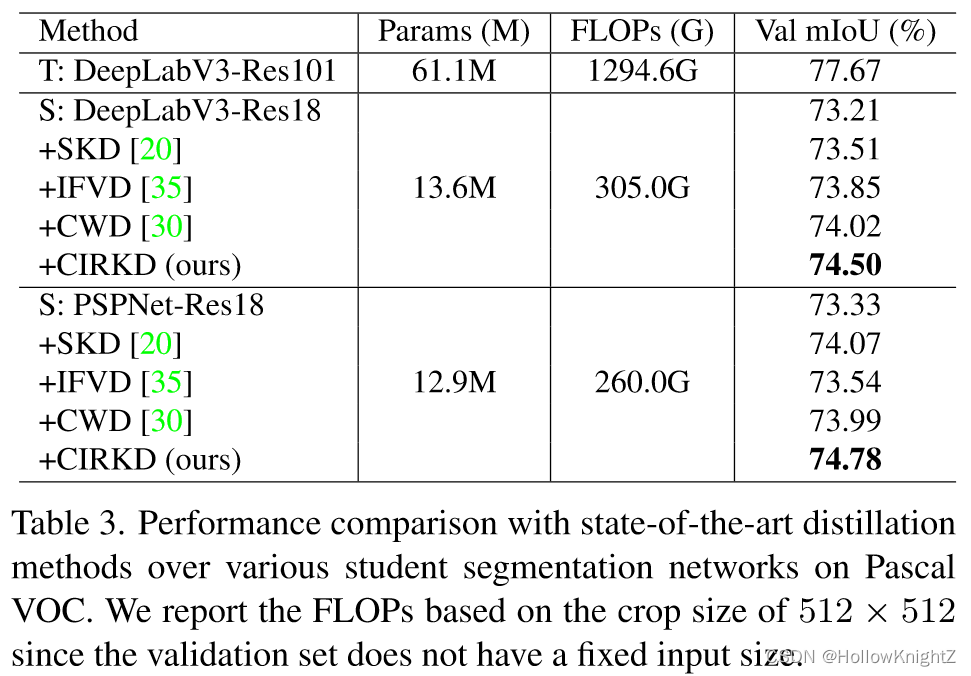
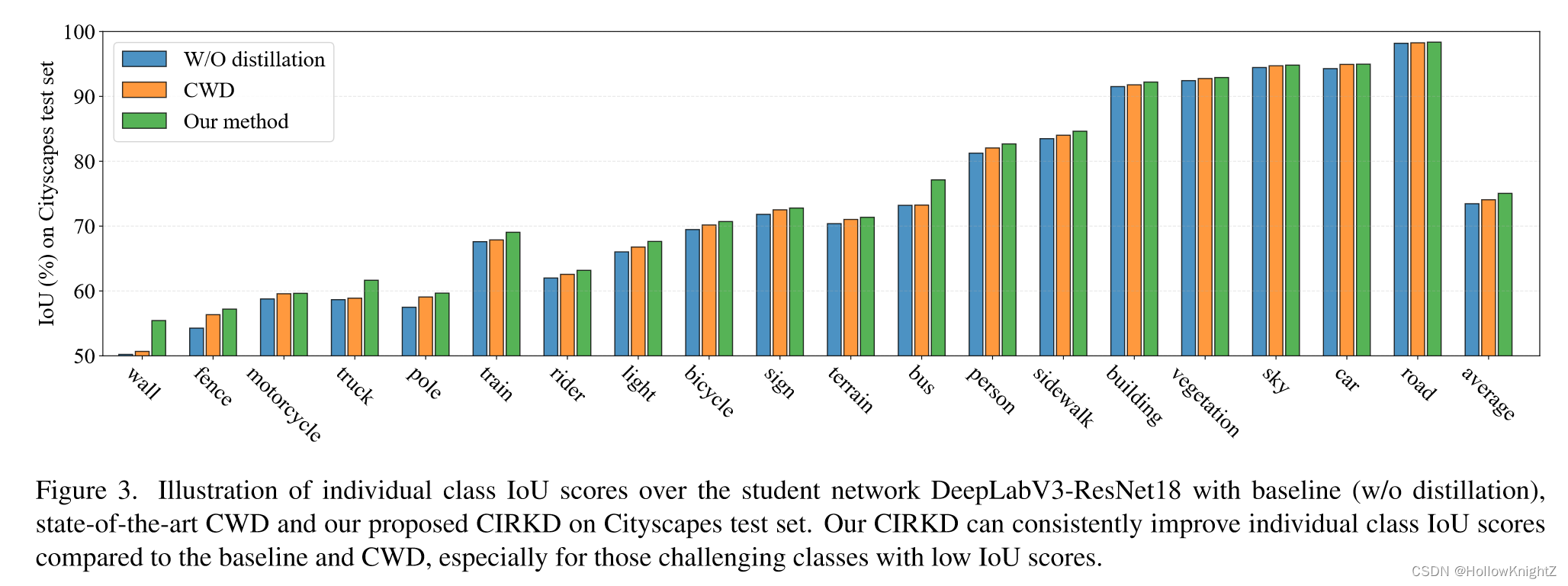
图3展示了单个类别IoU分数在学生网络上的表现。可以观察到,CIRKD比基线(w/o蒸馏)和CWD获得了更好的IoU得分,特别是那些IoU得分较低的类别。例如,在Wall上比baseline和CWD分别相对提升了10.4 %和9.4 %。
进一步的,图4可视化得展示了分割结果。

图5将CWD和CIRKD在学生网络上学习到的特征嵌入进行T-SNE可视化。与CWD相比,CIRKD训练的网络表现出结构良好的像素级语义特征空间。

表4为Loss项的消融实验。
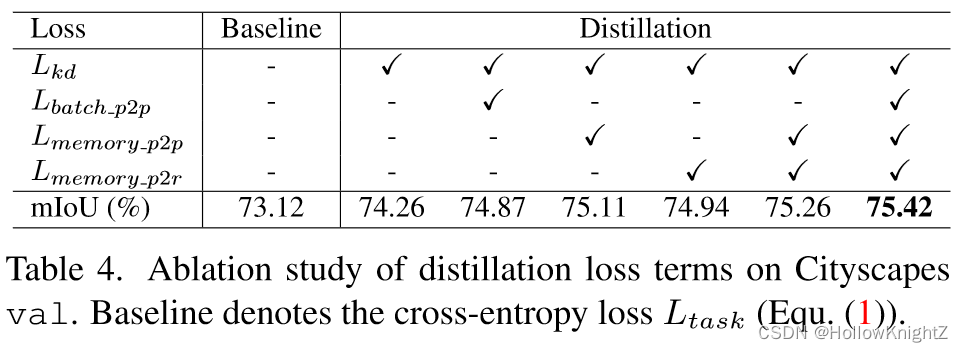
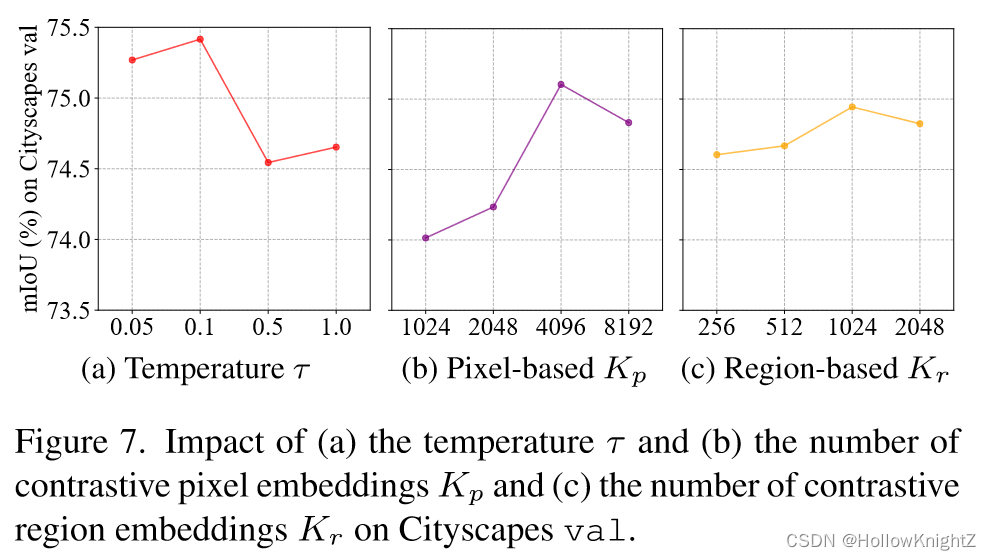
表6为缓存队列大小的消融实验。
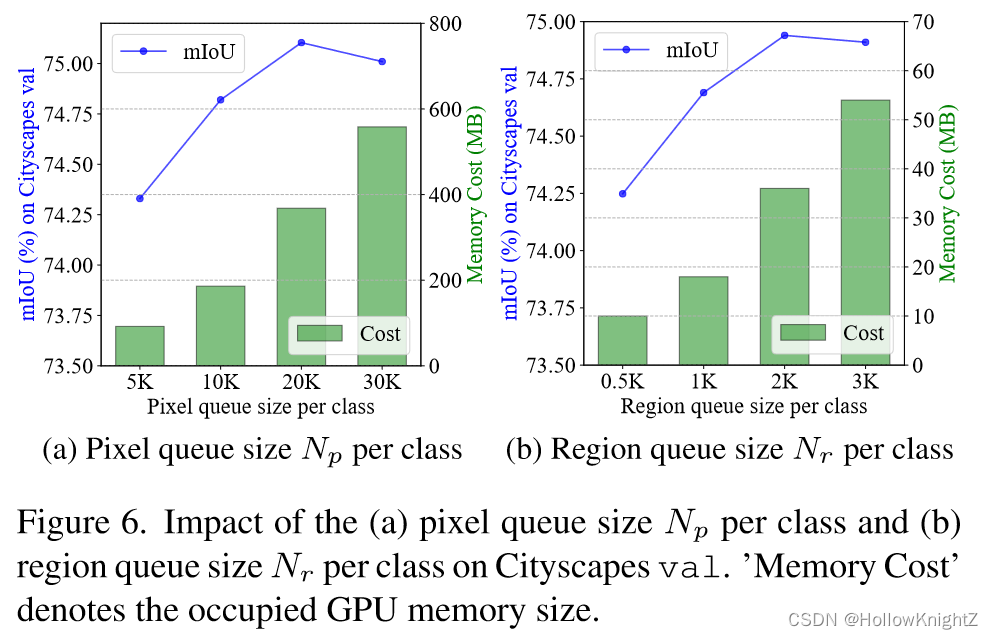
表7为超参 τ \tau τ ,像素嵌入和区域嵌入采样个数 K p , K r K_p, K_r Kp,Kr 的消融实验。