节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:

论文:GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
代码:https://link.zhihu.com/?target=https%3A//github.com/openai/glide-text2im
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群 , 想要大模型技术交流、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
想加入星球也可以如下方式:
方式①、微信搜索公众号:机器学习社区,后台回复:交流
方式②、添加微信号:mlc2040,备注:交流
一、背景
在扩散模型经过了一系列发展之后,Openai 开始探索文本条件下的图像生成,并在这篇论文里对比了两种不同的 guidance 策略,分别是通过 CLIP 引导和 classifier-free 的引导。
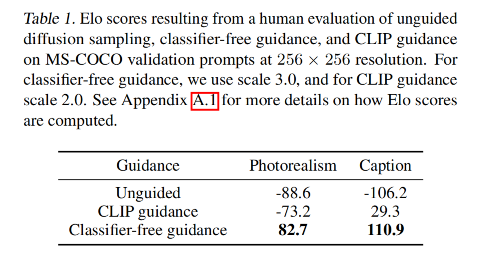
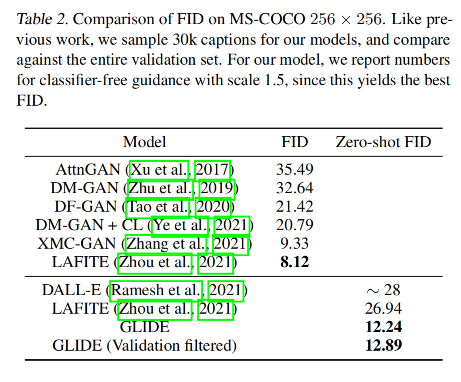
验证了 classifier-free 的方式生成的图片更真实,与提示的文本有更好的相关性。并且使用 classifier-free 的引导的 GLIDE模型在 35 亿参数的情况下优于 120 亿参数的 DALL-E 模型

二、方法
作者训练的模型包括:
- 一个 35 亿参数量的 text-conditional 扩散模型,分辨率为 64*64
- 一个 15 亿参数量的 text-conditional 上采样扩散模型,将分辨率提升至 256x256
- 对于 CLIP guidance 模型,还额外训练了一个 64x64 noised ViT-L CLIP
三、效果
3.1 不同引导方式的对比:

3.2 定量对比

精选
- 轻松构建聊天机器人,大模型 RAG 有了更强大的AI检索器
- 一文搞懂大模型训练加速框架 DeepSpeed 的使用方法!
- 保姆级学习指南:《Pytorch 实战宝典》来了
- MoE 大模型的前世今生
- 从零解读 SAM(Segment Anything Model)
- AI 绘画爆火背后:扩散模型原理及实现
- 从零开始构建和训练生成对抗网络(GAN)模型
- CLIP/LLaVA/LLaVA1.5/VILA 模型全面梳理!
- 从零开始创建一个小规模的稳定扩散模型!
- Stable Diffusion 模型:LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo 等
- 文生图模型:AE、VAE、VQ-VAE、VQ-GAN、DALL-E 等 8 模型
- 一文搞懂 BERT(基于Transformer的双向编码器)
- 一文搞懂 GPT(Generative Pre-trained Transformer)
- 一文搞懂 ViT(Vision Transformer)
- 一文搞懂 Transformer
- 一文搞懂 Attention(注意力)机制
- 一文搞懂 Self-Attention 和 Multi-Head Attention
- 一文搞懂 Embedding(嵌入)
- 一文搞懂 Encoder-Decoder(编码器-解码器)