基于python一/二手房数据爬虫分析预测系统+可视化 +商品房数据+Flask框架(附源码)
项目介绍
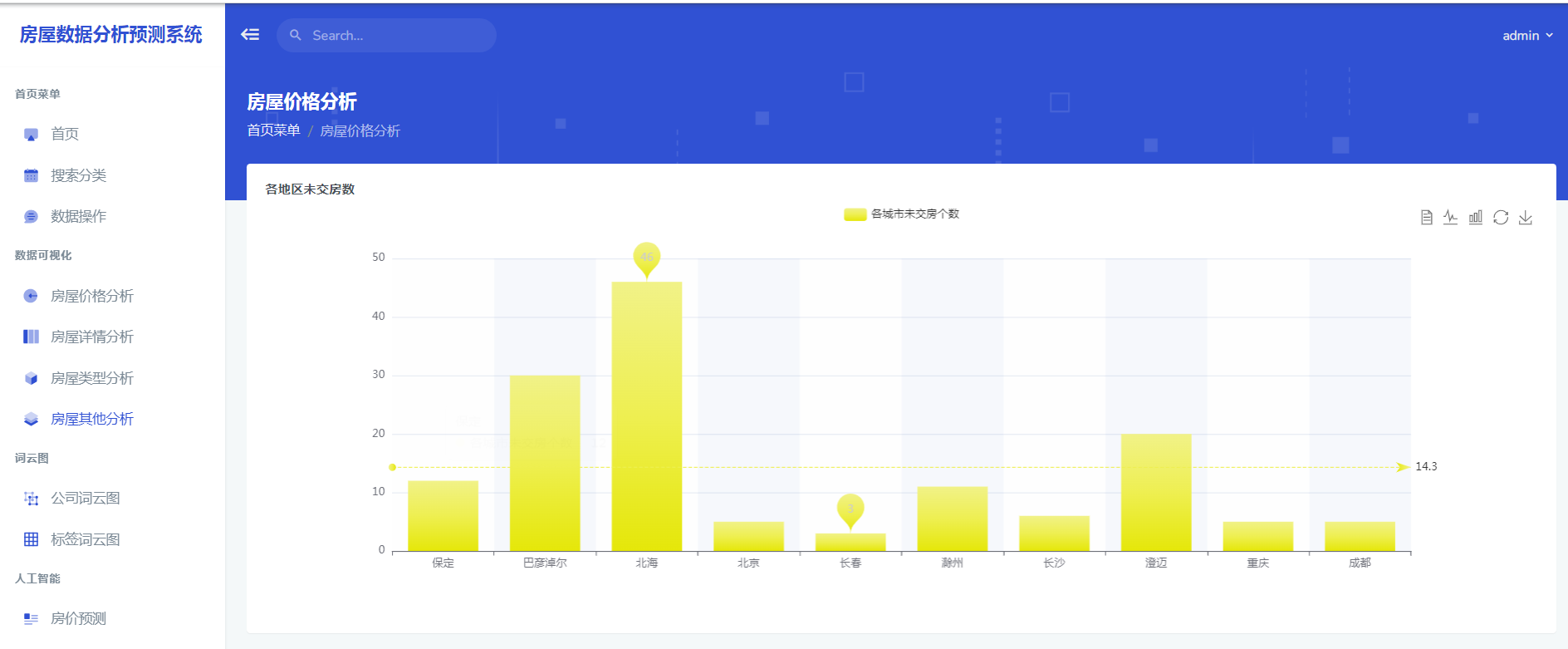
python语言、Flask框架、MySQL数据库、Echarts可视化
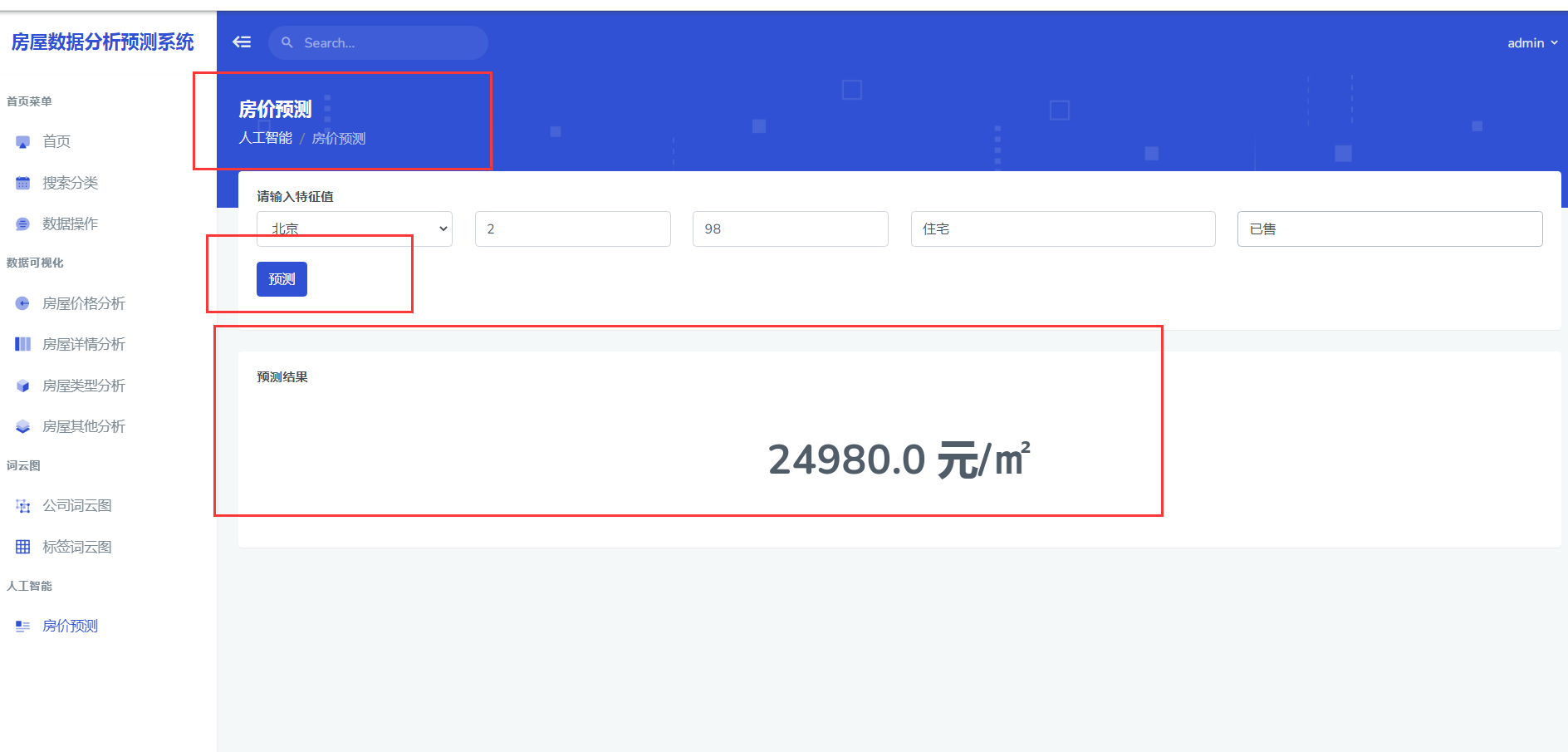
sklearn机器学习 多元线性回归预测模型、requests爬虫框架 链家一手房
一手房数据商品房数据、分析可视化预测系统
基于Flask的一手房链家数据采集分析预测系统是一款利用Python的Flask框架,对链家网站上的一手房房源信息进行数据采集、分析和预测的应用系统。
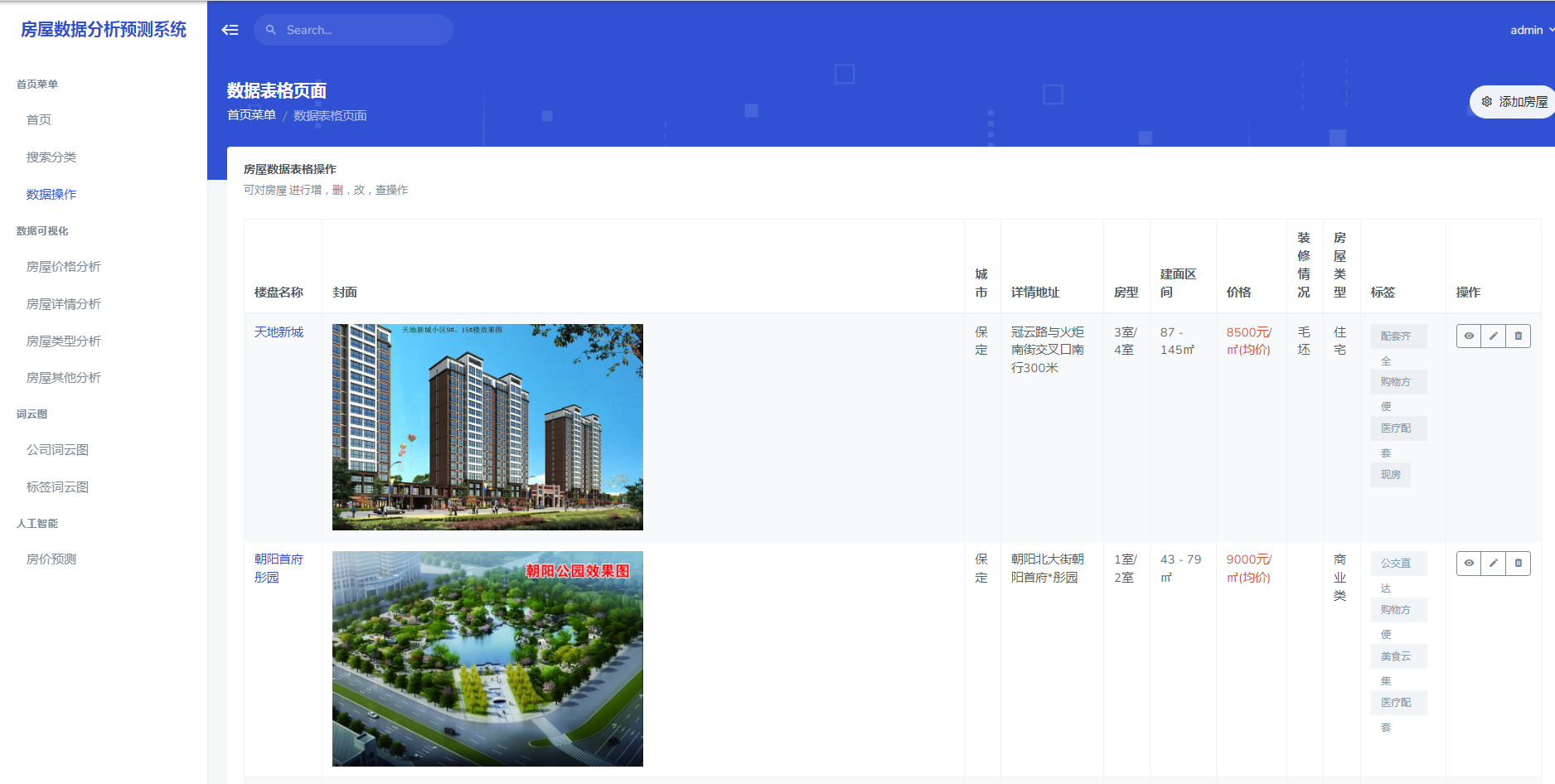
数据采集:系统通过网络爬虫技术,从链家网站上获取一手房房源信息。这些信息包括楼盘名称、开发商、楼盘地址、户型、价格、面积、朝向、装修情况、楼盘特点等。在采集数据时,可以设置关键词、地区筛选、价格范围、楼盘类型等参数,以获取感兴趣的房源信息。
















核心算法代码分享如下:
python
import requests
from lxml import etree
import csv
import os
def writerRow(row):
with open('./cityData.csv', 'a', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(row)
def init():
if not os.path.exists('./cityData.csv'):
with open('./cityData.csv','w',encoding='utf-8',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([
'city',
'cityLink'
])
def get_html(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
else:
return None
def parse_html(html):
root = etree.HTML(html)
cityList = root.xpath('//div[@class="fc-main clear"]//li[@class="clear"]//a')
for city in cityList:
cityName = city.text
cityLink = city.get('href') + '/loupan/pg1/?_t=1'
writerRow([
cityName,
cityLink
])
def main():
init()
url = 'https://bh.fang.lianjia.com/loupan/pg1/'
html = get_html(url)
parse_html(html)
if __name__ == '__main__':
main()