研究背景
研究关注于使用大型语言模型(LLMs)进行复杂的Text-to-SQL任务,目标是弥补精调模型与基于提示的方法之间的差距。早期系统依赖于特定领域或基于规则的方法,而最近的系统利用深度神经网络模型和LLMs,以提高领域独立性和效率。
研究目标
研究的目标是通过将任务分解成可管理的子任务并应用自我修正策略,来提高LLMs在Text-to-SQL任务中的表现,而无需训练。这种方法旨在增强推理过程并达到最先进的性能,甚至超过大量精调的模型。
相关工作
早期的Text-to-SQL系统要么是领域特定的,要么使用基于规则的方法。最近的进步包括使用LLMs,它们提供零样本和少样本提示能力,但在复杂SQL查询生成任务中通常落后于经过精调的模型。
方法论
解决方案
将复杂的SQL查询分解为更小、更易管理的子任务,这有助于通过上下文学习和自我修正系统地解决查询的每个部分。本文提出的分解文本到 SQL 任务的方法由四个模块组成:(1)模式链接,(2)查询分类和分解,(3)SQL 生成, (4) 自我修正,表明如果问题被简单地分解到正确的粒度级别,LLM 就有能力解决所有这些问题。
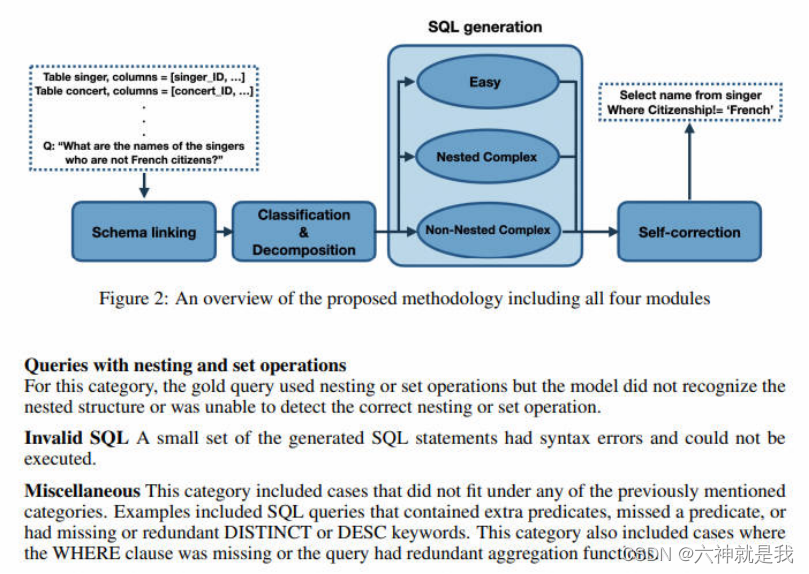
- 模式链接,负责识别自然语言查询中对数据库模式和条件值的引用,对于问题中每次提到的列名,都会从给定的数据库模式中选择相应的列及其表,还从问题中提取可能的实体和单元格值。它被证明有助于跨领域的通用性和复杂查询的综合(Lei 等人,2020),使其成为几乎所有现有文本到 SQL 方法的关键初步步骤。
- 查询分类和分解模块,对于每个连接,都有可能未检测到正确的表或连接条件。随着查询中联接数量的增加,至少一个联接无法正确生成的可能性也会增加。缓解该问题的一种方法是引入一个模块来检测要连接的表。此外,一些查询具有过程组件,例如不相关的子查询,它们可以独立生成并与主查询合并。为了解决这些问题,我们引入了查询分类和分解模块。该模块将每个查询分为三种:
- easy (简单),这类查询通常直接且简单,涉及基础的SQL语句,如简单的选择(SELECT)和过滤(WHERE)操作。这些查询不涉及复杂的逻辑或多重表连接,通常只针对单一表进行数据提取。
- Non-nested Complex (非嵌套复杂),这一级别的查询比简单查询复杂,可能涉及多表连接(JOIN),复杂的选择逻辑,但不包括嵌套查询。这种类型的查询可能要求进行数据的聚合(如计数、平均值等)或使用多个条件进行数据筛选。
- Nested Complex (嵌套复杂):最高复杂度的查询,包括嵌套的SQL语句,其中一个查询的结果被用作另一个查询的输入。这类查询可能涉及多级嵌套,复杂的逻辑运算和多个数据库表的综合使用。
- SQL生成,根据输入查询的复杂度(简单、非嵌套复杂、嵌套复杂)采用不同的生成策略。这种分类是由前面的分类与分解模块确定的。策略如下:
- 简单类:对于简单的查询,模块使用少量的示例提示,不涉及中间步骤。
- 非嵌套复杂:对于需要连接(JOIN)但不涉及子查询的复杂查询,模块可能采用中间表示来桥接自然语言查询和SQL语句。
- 嵌套复杂:对于包含嵌套查询、连接和集合操作的复杂查询,模块使用更复杂的中间表示和多步生成过程。
- self-correction(自我矫正),用来修正SQL生成模块可能产生的错误,例如缺失或多余的关键字(如DESC、DISTINCT和聚合函数)。这个模块的目的是在零样本(zero-shot)设置下自动识别并修正这些错误,即只提供存在错误的代码,并要求模型对其进行修复。其提示包括两种:
- 通用提示(Generic Prompt):直接请求模型识别并纠正"BUGGY SQL"中的错误。
- 温和提示(Gentle Prompt):不假设SQL查询存在错误,而是要求模型检查潜在的问题,并提供一些关于应检查的子句的提示。
数据处理
模式链接模块:
输入:用户查询文本。
输出:识别相关数据库模式元素。例如,将"课程的标题"链接到course.title列,"先决条件"链接到与course.course_id相关的prereq.course_id。
分类与分解模块:
输入:模式链接模块的输出。
输出:将查询分类为三个类别之一(简单,非嵌套复杂,嵌套复杂)并识别它为非嵌套复杂查询,因为它涉及到连接表但没有子查询。
SQL生成模块:
输入:分类与分解模块的输出。
中间表示:通过首先创建一个中间表示来简化复杂的SQL生成任务,可能简化连接操作并专注于分组和计数先决条件。
输出:生成SQL查询:
自我修正模块:
输入:SQL生成模块的初始输出。
输出:模块检查生成的SQL是否存在潜在错误或遗漏,如缺少关键词或不正确的聚合函数。如果检测到错误(例如,如果最初遗漏了HAVING count(*) = 2子句),它将进行修正。然而,在这个工作流程示例中,我们假设第一次生成的SQL已经是正确的。
实验
实验设计
实验设计主要围绕评估DIN-SQL方法在处理不同复杂度的Text-to-SQL任务上的性能。为此,研究者们采用了两个主要的数据集:Spider和BIRD。这些数据集提供了丰富的测试环境,因为它们涵盖了广泛的查询类型和复杂的数据库模式。
模型
- 使用了CodeX的两个变体(Davinci和Cushman)和GPT-4模型。
- 通过OpenAI API访问所有模型,使用贪婪解码(greedy decoding)并将最大令牌数设置为不同模块的特定值。
数据集
- Spider:广泛用于评估Text-to-SQL模型的能力,特别是在处理跨域和复杂查询方面。
- BIRD:用于测试模型在处理具有高查询复杂性的业务智能相关数据库的能力。
评估指标
- 执行准确性(EX):比较预测SQL查询的执行结果与真实SQL查询的执行结果。
- 精确集合匹配准确性(EM):评估生成的SQL查询的每个组件是否与基准查询的相应组件完全匹配。
- 有效效率得分(VES):测量生成的SQL查询的运行效率,考虑到查询的正确性和执行时间。
实验结论
实验结果表明,DIN-SQL在多个评估指标上均显著优于基准模型,尤其是在处理复杂查询的能力上。
- Spider数据集:DIN-SQL使用GPT-4和CodeX Davinci模型在执行准确性上达到85.3%和78.2%,在精确集合匹配准确性上分别达到60%和57%。
- BIRD数据集:在测试集上,DIN-SQL使用GPT-4模型实现了55.9%的执行准确性,设定了新的行业最佳水平(SOTA)。
- .DIN-SQL通过将Text-to-SQL任务分解为更细粒度的子任务,并利用大型语言模型(LLMs)的上下文学习能力,显著提高了模型处理复杂查询的准确性和效率。
此外,实验结果也证明了包括自我修正模块在内的DIN-SQL各个组件的有效性和对总体性能的贡献。这些发现强调了分解技术和自我修正策略在提升大型自然语言处理系统性能中的重要性。