Hive快速入门系列
-
- Hive的概述
- Hive架构
- Hive安装
- Hive配置文件修改
- 启动Hive
-
- [以命令行方式启动(在HIVE_HOME/bin目录下)](#以命令行方式启动(在HIVE_HOME/bin目录下))
- 以JDBC连接启动(beeline方式连接)
- Hive基本操作
- Hive应用简单示例:WorldCount
Hive的概述
什么是Hive?
Hive 是一个基于 Hadoop 的数据仓库工具,用于处理大规模数据集。它提供了类似于 SQL 的查询语言 HiveQL,允许用户在 Hadoop 分布式存储中执行查询和分析数据。
Hive的本质就是将HiveQL语句转换为MapReduce任务后运行,非常适合做数据仓库的数据分析。
使用Hive的原因
- Hive 使用类SQL 查询语法, 最大限度的实现了和SQL标准的兼容,大大降低了传统数据分析人员处理大数据的难度
- 以MR 作为计算引擎(也可选择Spark计算引擎)、HDFS 作为存储系统,为超大数据集设计的计算/ 扩展能力
Hive架构
Hive架构中主要包括客户端(Client)、Hive Server、元数据存储(MetaStore)、驱动器(Driver)
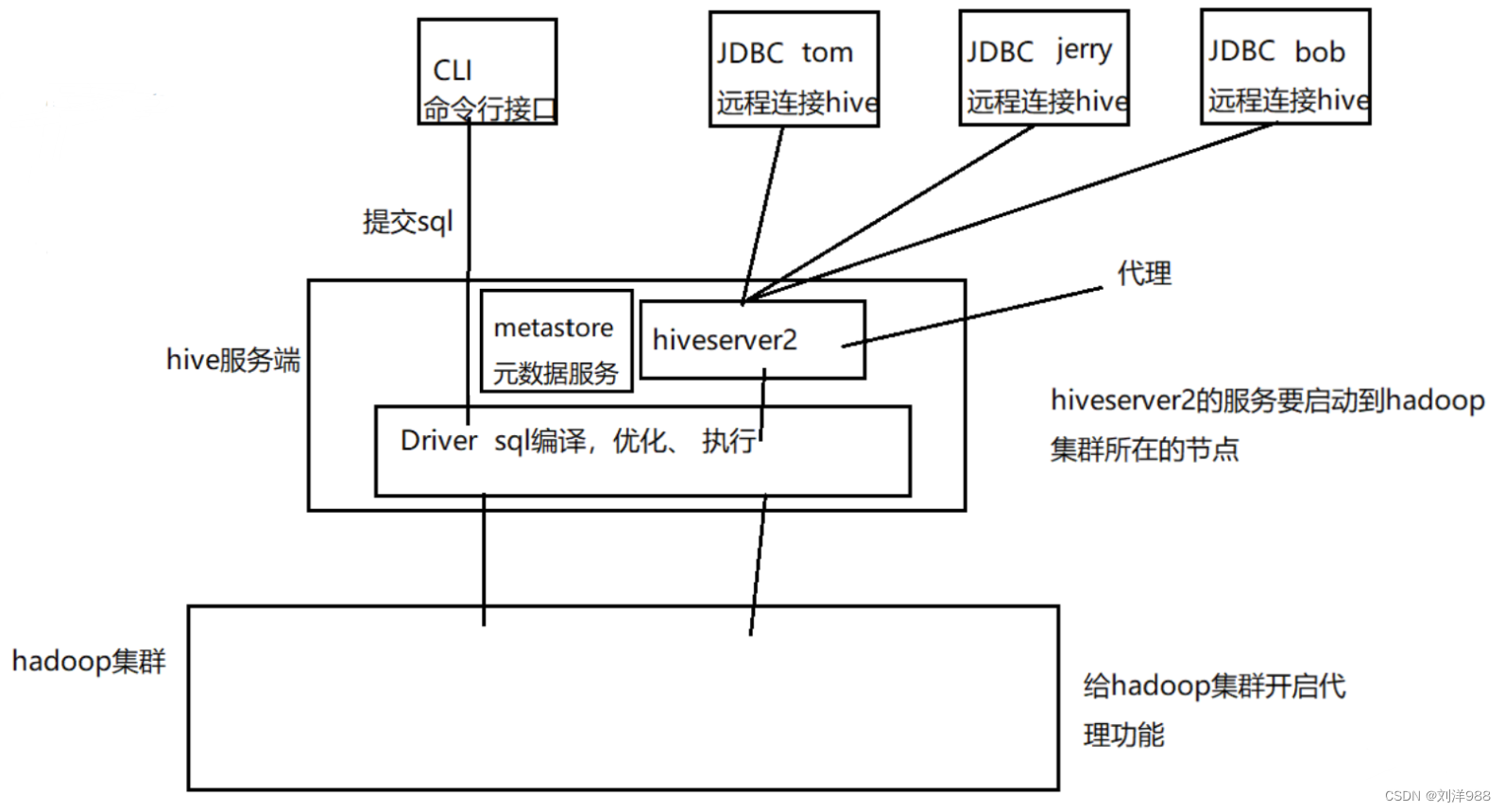
Hive Client:
Hive 客户端是用户与 Hive 交互的接口,用户可以通过 Hive 客户端(如命令行界面、Hue 等)提交 HiveQL 查询和管理 Hive 表结构等操作。
Hive Driver:
Hive Driver 接收用户提交的 HiveQL 查询,并负责编译、优化和执行查询计划。它将查询转换为 MapReduce 作业或 Tez 任务,并与相应的执行引擎进行交互。
Hive Metastore:
Hive Metastore 存储了 Hive 表的元数据信息,包括表结构、分区信息、表位置等。这些元数据通常存储在关系型数据库中(如MySQL),Hive 客户端和服务通过 Metastore 访问和管理表的元数据。
Hive安装
先安装MySQL(以在线安装方式为例)
下载mysql的repo源
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
安装mysql-community-release-el7-5.noarch.rpm包
rpm -ivh mysql-community-release-el7-5.noarch.rpm
查看下载的文件
ls -1 /etc/yum.repos.d/mysql-community*
安装MySQL
yum install mysql-server
启动MySQL服务
systemctl start mysql.service
使用MySQL
mysql -uroot -p
密码直接回车就进入了,若想设置密码,则
set password for 用户名@localhost = password('新密码');
退出mysql 下次登录就是新密码了
exit;
再安装Hive
解压apache-hive-3.1.3-bin.tar.gz到指定目录,例如:
tar -xzvf apache-hive-3.1.3-bin.tar.gz -C /export/servers
配置环境变量(在全局配置文件/etc/profile)
export HIVE_HOME=/export/servers/apache-hive-3.1.3-bin
export HIVE_CONF_DIR=/export/servers/apache-hive-3.1.3-bin/conf
export PATH= PATH: HIVE_HOME/bin
使配置生效
source /etc/profile
Hive配置文件修改
在hive根目录的conf目录,创建一个hive-site.xml文件,并添加如下内容:
xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<!-- 数据库 start -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_meta?useSSL=false</value>
<description>mysql连接</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>数据库使用用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>数据库密码</description>
</property>
<!-- 数据库 end -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<description>开启Hive的并发模式</description>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
<description>用于并发控制的锁管理器类</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>my2308-host</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>hive开启的thriftServer端口</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<!-- 其它 end -->
</configuration>修改$HADOOP_HOME/etc/hadoop/core-site.xml 开启hadoop代理功能
xml
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>配置超级用户允许通过代理用户所属组</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>配置超级用户允许通过代理访问的主机节点</description>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>拷贝hive-env.sh.template模版配置文件为hive-env.sh
cp hive-env.sh.template hive-env.sh
在hive-env.sh文件中添加Hadoop目录位置
HADOOP_HOME=/export/servers/hadoop-3.2.0
对日志文件改名
mv hive-log4j2.properties.template hive-log4j2.properties
在MySQL中创建hive用的元数据库hive_meta
create database hive_meta default charset utf8 collate utf8_general_ci;
拷贝mysql驱动jar 到/export/servers/apache-hive-3.1.3-bin/lib
cp mysql-connector-java-5.1.40-bin.jar /export/servers/apache-hive-3.1.3-bin/lib
删除冲突的log4j(log4j-slf4j-impl-2.4.1.jar)
rm -f /export/servers/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.4.1.jar
hive初始化mysql
schematool -dbType mysql -initSchema
启动Hive
以命令行方式启动(在$HIVE_HOME/bin目录下)
hive
以JDBC连接启动(beeline方式连接)
先启动hiveserver2服务(在$HIVE_HOME/bin目录下)
方式一:前台启动启动hiveserver2服务:
hiveserver2
方式二:后台启动hiveserver2服务:nohup hiveserver2 > /dev/null 2>&1 &
第一种:在hive的bin目录中执行:beeline然后:!connect jdbc:hive2://localhost:10000
输入操作hadoop集群的用户名和密码(本次以root用户名,123456为密码)
第二种:beeline -u jdbc:hive2://localhost:10000 -n root
Hive基本操作
Hive数据库操作
- 创建数据库
CREATE DATABASE IF NOT EXISTS database_nameCOMMENT database_comment
LOCATION hdfs_path
WITH DBPROPERTIES (property_name=property_value, ...);
其中:WITH DBPROPERTIES ,用来指定数据属性数据。
--创建带有属性的数据库create database testdb WITH DBPROPERTIES ('creator' = 'tp','date'='2024-06-12');
-- 显示创建语句
show create database testdb;
-- 显示所有数据库
show databases;
- 删除数据库
RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。
CASCADE:级联模式,若数据库不为空,则会将库中的表一并删除。
Hive表操作
- 建表语法
-- EXTERNAL 代表外部表
CREATE EXTERNAL TABLE IF NOT EXISTS table_name
(col_name data_type \[COMMENT col_comment\], ...)
COMMENT table_comment
-- 分区表设置 分区的字段和类型
PARTITIONED BY (col_name data_type \[COMMENT col_comment\], ...)
-- 桶表设置 按照什么字段进行分桶
[CLUSTERED BY (col_name, col_name, ...)
-- 桶内的文件 是按照 什么字段排序 分多少个桶
SORTED BY (col_name \[ASC\|DESC\], ...)\] INTO num_buckets BUCKETS
-- 分隔符 + 序列化反序列化
ROW FORMAT row_format
-- 输入输出格式
STORED AS file_format
-- 表所对应的hdfs目录
LOCATION hdfs_path
- 表分类
内部表
内部表又称受控表,当删除内部表的时候,存储在文件系统上的数据(例如HDFS上的数据)和元数据都会被删除。先有内部表,再向表中插入数据。
--创建inner_test表(内部表)
CREATE TABLE inner_test(word string, num int);
删除内部表,表对应的hdfs目录也一并删除-- 创建emp职工表(内部表)
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
外部表
创建外部表需要使用EXTERNAL关键字,当删除外部表的时候,只删除元
数据,不删除数据。
使用场景,例如:某个公司的原始日志数据存放在一个目录中,多个部门对原始数据进行分析,那么创建外部表就是比较好的选择了,因为即使删除了外部表,原始数据并不会被删除。
分区表
分区表是为了防止暴力扫描全表,提高查询效率。分区字段在源文件中是不存在的,需要在添加数据的时候手动指定。
每一个分区对应一个目录。通过partitioned by来在创建分区表的时候添加分区字段。分区表可以是内部表,也可以是外部表。
使用场景:可以通过分区表,将每天搜集的数据进行区分,查询统计的时候通过指定分区,提高查询效率。
导入数据到表中
追加Linux本地文件里的数据到emp表
load data local inpath '/root/data/emp.txt' into table emp;
overwrite覆盖操作,使用Linux本地文件里的数据覆盖掉原来emp表的数据
load data local inpath '/root/data/emp.txt' overwrite into table emp;
将hdfs上某文件里的数据追加到emp表(此操作完毕后,hdfs上的该文件就自动删除)
load data inpath 'hdfs://my2308-host:9000/data/emp.txt' into table emp;
overwrite覆盖操作,使用hdfs上某文件里的数据覆盖掉emp表的数据(此操作完毕后,hdfs上的该文件就自动删除)
load data inpath 'hdfs://my2308-host:9000/data/emp.txt' overwrite into table emp;
Hive应用简单示例:WorldCount
创建一个data目录准备worldcount计算的文件data1.txt、data2.txt
root@BigData01 \~# mkdir data
root@BigData01 \~# cd data
root@BigData01 data# vim data1.txt
hello world
hello hadoop
hello java
root@BigData01 data# vim data2.txt
welcome to hadoop
hello java hadoop
进入hive环境,编写HiveQL语句实现WordCount算法
root@BigData01 data# hive
hive> create database if not exists testdb;
hive> use testdb;
hive> create table if not exists docs(line string);
hive> load data local inpath '/root/data/' overwrite into table docs;
hive> create table wordcount as
select word,count(1) as count from
(select explode(split(line,' ')) as word from docs) w
group by word
order by word;