23年12月,加州大学圣地亚哥、谷歌研究院、南加州大学、剑桥大学联合发布Rich Human Feedback for Text-to-Image Generation论文。
作者受大模型中RLHF技术的启发,用人类反馈来改进Stable Diffusion等文生图模型,提出了先进的RichHF-18K数据集和多模态RAHF模型。这项技术旨在通过引入更为丰富和多样化的人类反馈,来提升文本到图像生成的质量和准确性。通过收集并整合来自不同领域专家的反馈,模型能够更准确地理解文本描述的意图,并生成与之更加匹配、细节更丰富的图像。
Abstract
最近的文本到图像 T2I 生成模型,例如稳定扩散和 Imagen,在基于文本描述生成高分辨率图像方面取得了重大进展。然而,许多生成的图像仍然存在伪影/不合理性、文本描述错位和审美质量等问题。受具有人类反馈 (RLHF) 的强化学习对大型语言模型的成功启发,先前的工作收集了人类提供的分数作为对生成图像的反馈,并训练了一个奖励模型来改进 T2I 生成。在本文中,我们通过 (i) )标记不可信或与文本没对齐的图像区域,以及 (ii) 标注文本提示中哪些单词在图像中被歪曲或丢失。我们在 RichHF18K 数据集上收集了丰富的人类反馈,训练多模态Transformer来自动预测如此丰富的反馈。实验表明,预测的丰富的人类反馈可用于改进图像生成,例如,通过高质量训练数据来微调和改进生成模型,或者通过创建带有预测热图的掩码来修复有问题的区域。值得注意的是,除了用于生成人类反馈数据的图像之外,这些改进还可以泛化推广到Muse模型(Stable Diffusion 变体)。
1. Introduction
文本到图像 (T2I) 生成模型正在迅速成为各个领域内容创建的关键,包括娱乐、艺术、设计和广告,也可以推广到图像编辑、视频生成等许多其他应用。尽管取得了重大进展,但输出通常仍然存在伪影/不可信、文本描述错位和审美质量等问题。例如,Pick-a-Pic数据集,它主要由稳定扩散模型变体生成的图像组成,许多图像(如图 1 所示)包含失真人体/动物身体(例如,手指超过5个的人手)、变形物体和不合理性问题,如漂浮灯。人工评估表明,数据集中只有 10% 生成图像没有伪影和不合理性。同样,文本图像错位问题也很常见,例如,提示"一个人跳入河",但生成的图像显示男人站着。
而且,现有生成图像自动评估指标,包括众所周知的IS和FID,都是在图像分布上计算,可能无法反映单个图像的细微差别。最近的研究收集了人类偏好/评级来评估生成图像质量,并训练了评估模型来预测这些评级,特别是ImageReward或Pick-a-Pic。虽然更集中,但这些指标仍然将一张图像质量总结为单纯的数字分数。在提示图像对齐方面,也有开创性的单一指标,如CLIPScore和最近的问题生成和回答方法。虽然这些模型更具校准性和可解释性,但它们昂贵而又复杂,仍然无法定位图像中的错误区域。
### 研究动机
- 现有文生图模型输出通常仍然存在伪影/不合理性、文本描述错位和审美质量等问题。
- 先前工作收集了人类提供的分数作为对生成图像质量的反馈,无法定位图像中的错误区域。
在本文中,我们提出了一个数据集和一个细粒度更全面的评估模型,这些评估是可解释和可归因的(例如,对于具有伪影/不可信或图像-文本未对齐的区域),它提供了比单个标量分数更丰富的图像质量理解。作为第一个贡献,我们收集了18K图像的丰富人类反馈数据集(RichHF-18K),其中包含(i)图像上的点标注,突出了不可信/伪影和文本图像不对齐的区域,(ii)提示词的标注,指定生成的图像中缺失或误传的概念,和(iii)四种类型的细粒度评分,用于图像合理性、文本图像对齐、美观性和总体评级。有了RichHF-18K,我们设计了一个多模态Transformer模型,我们将其命名为富自动人类反馈(RAHF),以学习预测生成图像及其相关文本提示上的丰富的人类标注。因此,我们的模型可以预测不可信和不一致的区域,不一致的关键字,以及细粒度的分数。这不仅提供了可靠的评级,而且还提供了关于生成图像质量的更详细和可解释的见解。据我们所知,这是第一个丰富的人类反馈数据集和模型,用于最先进的文本到图像生成模型,提供了一个自动和可解释的管道来评估T2I生成。
### 主要贡献:
- 基于Pick-a-Pic数据集,提出生成图像的丰富人类反馈数据集RichHF-18K(包括细粒度分数、不可信/伪影、未对齐图像区域和未对齐关键字)。
- 提出多模态Transformer模型RAHF,用于预测生成图像的丰富反馈。
- 实验证明RAHF预测的人类反馈对改善图像生成质量非常有效:
- 通过使用预测的热图作为掩码来修复有问题的图像区域。
- 通过使用预测的分数来帮助微调图像生成模型(如Muse),例如,通过选择/过滤微调数据,或作为奖励指导。
- 基于Muse模型的改进,RAHF模型具有良好的泛化能力。
2. Related works
Text-to-image generation
一个早期的工作是生成对抗网络GAN,它训练一个生成器来生成图像,并训练一个判别器来区分真实图像和生成的图像。另一类生成模型由变分自编码器VAEs发展而来,它优化了图像数据似然性的ELBO。最近,扩散模型(Diffusion Models, DMs)已经成为图像生成的最先进技术。DM经过训练,从随机噪声中逐步生成图像,能够捕获比GAN更好的多样性,并获得良好的样本质量。潜在扩散模型LDM是进一步的改进,它在一个紧凑的潜在空间中执行扩散过程,以提高效率。
Text-to-image evaluation and reward models
最近有很多关于文本到图像模型在多个维度上的评估工作。Xu等人收集了一个人类偏好数据集,要求用户对多个图像进行排序,并根据它们的质量对它们进行评级。他们训练了一个用于人类偏好学习的奖励模型ImageReward,并提出了奖励反馈学习(Reward Feedback Learning, ReFL),用ImageReward模型调整扩散模型。Kirstain等人构建了一个WEB应用程序,要求用户从一对生成图像中选择更好的图像来收集人类偏好,从而产生了一个名为Pick-a-Pic数据集,该数据集由T2I模型(如Stable Diffusion 2.1, Dreamlike Photoreal 2.05和Stable Diffusion XL变体)生成,包含超过500K个样本。他们利用人类偏好数据集来训练一个基于CLIP的评分函数,称为PickScore,以预测人类偏好。Huang等人提出了一个名为T2I-CompBench基准,用于评估文本到图像模型,该模型由6000个描述固有属性、对象关系和复杂组合的文本提示组成。他们利用CLIP和BLIP等多个预训练视觉语言模型来计算多个评价指标。Wu等人收集了生成图像上人类选择的大规模数据集,并利用该数据集训练一个分类器,该分类器输出人类偏好评分(human Preference Score, HPS)。通过调整HPS,生成图像质量有所改善。最近,Lee提出了使用多个细粒度指标对T2I模型进行整体评估。
尽管有这些有价值的贡献,但大多数现有作品仅使用二元人类评级或偏好排名来构建反馈/奖励,并且缺乏提供详细可操作的反馈能力,例如图像的不可信区域,未对齐区域或生成图像上的未对齐关键字。最近一篇与我们的工作相关的论文是Perceptual Artifacts Localization for lmage Synthesis Tasks,他们收集了用于图像合成任务的伪影区域数据集,训练了一个基于分割的模型来预测伪影区域,并提出了一种针对这些区域的图像修补方法。然而,他们的工作重点仅限于伪影区域,而在本文中,我们为T2I生成收集了丰富的反馈,其中不仅包括伪影区域,还包括未对齐区域、未对齐关键字以及四个细粒度评分。据我们所知,这是第一个针对文本到图像模型异构的、丰富的人类反馈工作。
3. Collecting rich human feedback
3.1. Data collection process
RichHF-18K数据集内容:
- 两个热图(伪像/不可信、未对齐)
- 四个细粒度分数(可信性、对齐、美学和总体分数)
- 一个文本序列(未对齐的关键字)
对于每个生成的图像,首先要求标注者检查图像并读取用于生成图像的文本提示。然后,他们在图像上标记点,以标明任何不可信/伪影或与文本提示不一致的位置。标注者被告知,每个标记点都有一个"有效半径"(图像高度的1/20),它形成了一个以标记点为中心的假想圆盘。这样,我们可以使用相对较少的点来覆盖有缺陷的图像区域。最后,标注者在5分的李克特量表上分别标记未对齐关键字和四种类型的分数。为了方便数据收集,我们设计了一个WebUI,如图 1 所示。有关数据收集过程的更多详细信息,请参见补充资料。

Figure 1. An illustration of our annotation UI.
### RichHF-18K数据集标注
- 标注任务
- 标注者首先检查生成的图像并阅读用于生成图像的文本提示。然后,他们在图像上标记点,以指示与文本提示相关的不可信不合理/伪影或不一致的区域。
- 有效半径
- 每个标记点都有一个1/20图像高度"有效半径",围绕标记点形成一个假想圆盘。这样,即使使用较少的点,也能覆盖图像中有缺陷的区域。
- 标注细节
- 对扭曲的人/动物身体/面部、物体、文本以及不真实/无意义等表现形式的定义。
- 为标注者提供了操作指导,包括当文本提示中的元素在图像中缺失、属性错误、动作错误、数量错误、位置错误或其他不一致的处理方法。
3.2. Human feedback consolidation
为了提高收集到的人类对生成图像反馈的可靠性,每个图像-文本对都由三个标注者进行标注。因此,我们需要为每个样本合并多个标注。对于分数,我们简单地对图像多个分数进行平均,以获得最终分数。对于未对齐的关键字标注,我们执行多数投票来获得对齐/未对齐的最终指示序列,同时使用最常见的关键字标签。对于点标注,我们首先将它们转换为每个标注的热图,其中每个点被转换为热图上的Disk区域(如上一小节所讨论的),然后我们计算跨标注者的平均热图。具有明显不可信的区域可能被所有人标注,并且在最终平均热图上具有较高的值。
### 反馈整合
- 多标注者
- 评分整合
- 关键词整合
- 点标注整合
3.3. RichHF-18K: a dataset of rich human feedback
我们从Pick-a-Pic数据集中选择图像-文本对子集进行数据标注。虽然采用了通用的方法,适用于任何生成的图像,由于其重要性和更广泛的应用,我们选择了数据集中大部分逼真的图像。此外,我们还希望在图像之间有类别的平衡。为了确保平衡,我们利用PaLI视觉问答(VQA)模型从Pick-a-Pic数据样本中提取一些基本特征。具体来说,我们对Pick-a-Pic中的每个图像-文本对都提出了以下问题。1)这张照片逼真吗?2)哪个类别最能描述图像?在"人"、"动物"、"物体"、"室内场景"、"室外场景"中选择一个。在我们人工检查下,PaLI对这两个问题的回答大体上是可靠的。我们使用这些答案对Pick-a-Pic中的不同子集进行采样,得到17K个图像-文本对。我们将17K个样本随机分成两个子集,一个包含16K个样本的训练集和一个包含1K个样本的验证集。16K训练样本的属性分布见补充资料。此外,我们从Pick-a-Pic测试集中收集了关于唯一提示及其相应图像的丰富的人类反馈,作为我们的测试集。总的来说,我们收集了来自Pick-a-Pic的18K图像-文本对的丰富的人类反馈。RichHF18K数据集由16K训练样本、1K验证样本和1K测试样本组成。
### 数据集RichHF-18K
- 从Pick-a-Pic数据集选择图像-文本对子集进行数据标注、采样。
- 类别平衡,我们利用PaLI视觉问答(VQA)模型从Pick-a-Pic数据样本中提取一些基本特征。
- 这张照片逼真吗?
- 哪个类别最能描述图像? 在"人"、"动物"、"物体"、"室内场景"、"室外场景"中选择一个。
- 人工参与检查以上问题是否处理得当。
- RichHF18K数据集由16K训练样本、1K验证样本和1K测试样本组成。
3.4. Data statistics of RichHF-18K
在本节中,我们总结了分数的统计数据,并对分数进行了标注者一致性分析。我们用公式
(s−smin)/(smax−smin) (smax = 5 and smin = 1)
对分数 s 进行标准化,使分数位于0,1范围内。得分直方图如图 2 所示。
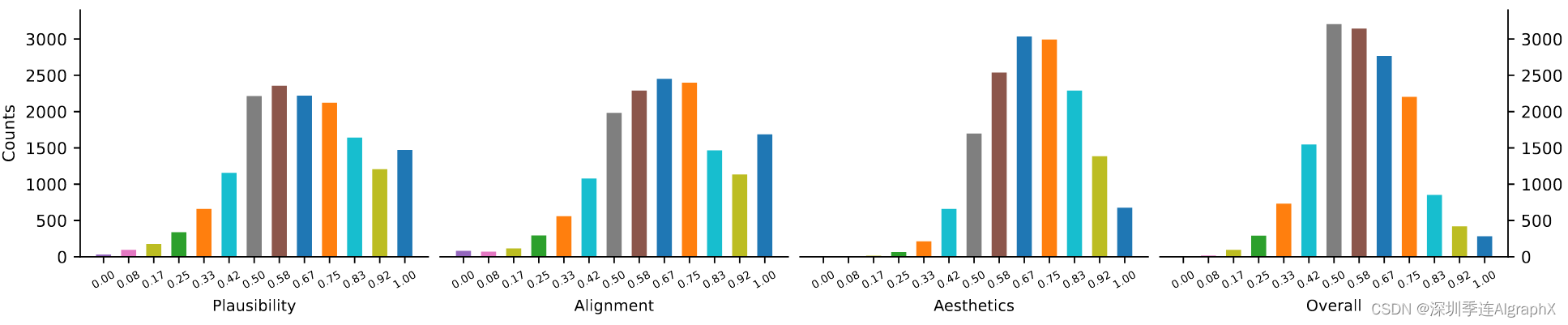
得分的分布与高斯分布相似,而合理性和文本-图像对齐得分的百分比略高1.0。收集到的分数分布确保我们有合理数量的正、负样本来训练一个好的奖励模型。为了分析图像-文本对标注者之间的评分一致性,我们计算分数之间的最大差异:
max_diff=max(scores)−min(scores)
其中分数是图像-文本对的三个分数标签,max_diff直方图如下:
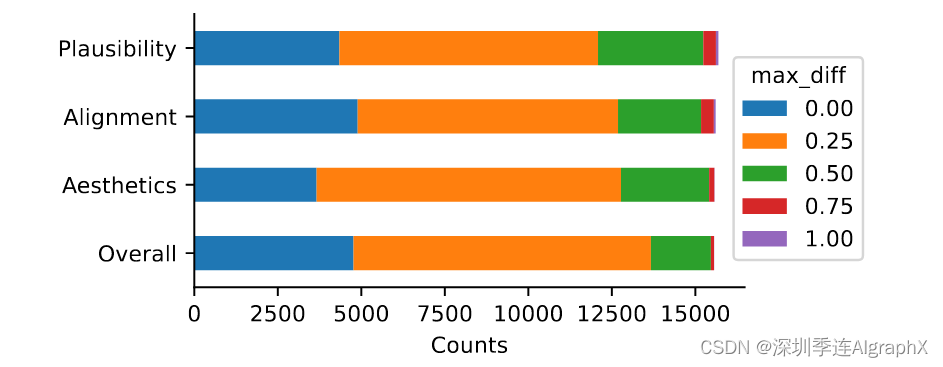
我们可以看到,大约25%的样本具有完美的标注者一致性,大约85%的样本具有良好的标注者一致性(标准化后maxdiff小于或等于0.25或李克特量表中的分数1分)。
### 数据统计和标注者一致性分析
-
分数标准化
-
分数分布
-
样本平衡
-
标注者一致性评估
4. Predicting rich human feedback
4.1. Models
4.1.1 Architecture
### 模型架构如图 3 所示
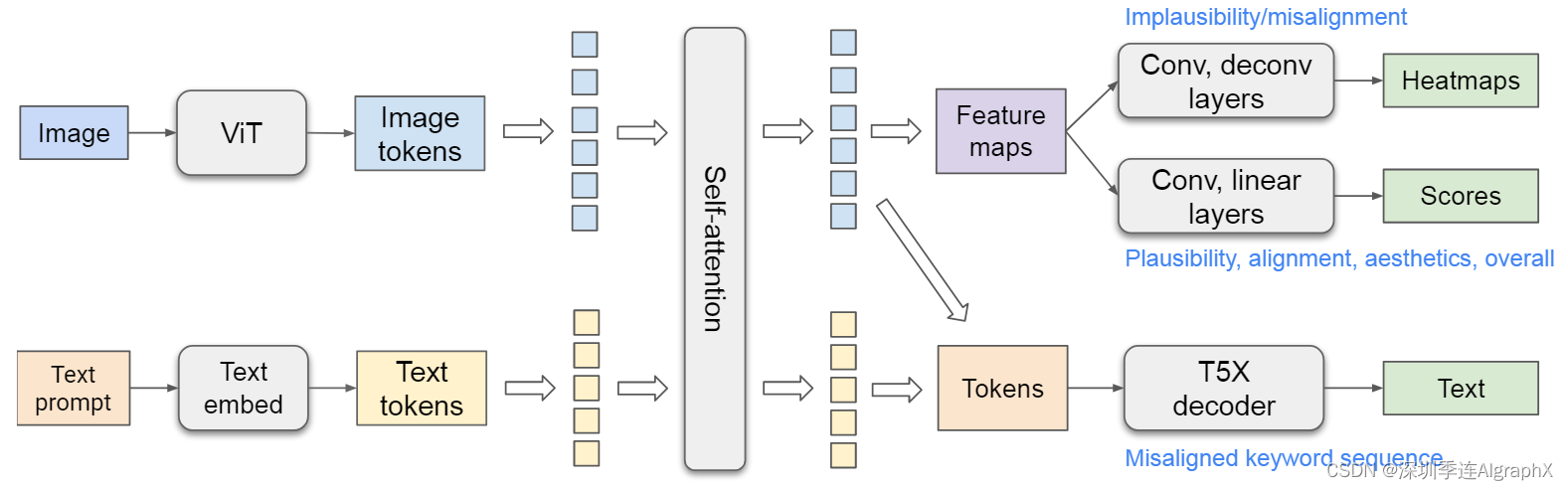
Figure 3. Architecture of our rich feedback model.
模型由两个计算流组成:一个视觉流、一个文本流。我们对ViT输出的图像令牌和文本嵌入模块输出的文本令牌进行自注意,以融合图像和文本信息。视觉标记被重塑为特征图,并映射到热图和分数。视觉和文本标记被发送到Transformer解码器以生成文本序列。
我们采用了基于ViT和T5X模型的视觉语言模型,受到Spotlight模型架构的启发,修改了模型和预训练数据集,以更好地适应我们的任务。我们在连接的图像令牌和文本令牌之间使用自注意模块,类似于PaLI,因为我们的任务需要双向信息传播。将文本信息传播到图像标记,用于文本未对齐评分和热图预测,而将视觉信息传播到文本标记,用于更好的视觉感知文本编码,以解码文本未对齐序列。为了在更多样化的图像上预训练模型,我们将WebLI数据集上的自然图像字幕任务添加到预训练任务混合物中。具体来说,ViT 将生成的图像作为输入,并将图像标记输出为高级表示。文本提示标记嵌入到密集向量中。图像标记和嵌入的文本标记由 T5X 中的 Transformer 自注意力编码器连接和编码。
在编码融合的文本和图像标记之上,我们使用三种预测器来预测不同的输出。
对于热图预测,图像token被重塑为特征图,并通过卷积层,反卷积层和sigmoid激活,并输出不可信和不对齐热图。
对于分数预测,特征映射通过卷积层、线性层和sigmoid激活,从而得到作为细粒度分数的标量。
为了预测关键字错位序列,生成图像的原始提示符用作模型的文本输入。修改后的提示符用作T5X解码器的预测目标。例如,如果图像中有一只黑色的猫,而文本提示是"a yellow cat",则修改后的提示可能是"a yellow_0 cat",这里的"0"表示"yellow"与图像不一致。在计算过程中,我们可以使用特殊后缀提取不对齐的关键字。
### 模型输入输出
- ViT图像编码
- 生成的图像作为输入,编码后的Token作为输出,高级表示。
- 文本编码
- 文本提示tokens嵌入embedded到高维向量空间中,密集向量表示。
- 自注意模块
- 图像token和文本token由 T5X 中的 Transformer 自注意力编码器连接和编码。T5X decoder 可以接收来自图像的编码表示,并生成描述图像的文本。
- 文本信息传播到图像token,帮助模型评估文本与图像的不一致性,并预测热图。
- 图像信息传播到文本token,增强文本编码对视觉内容的感知,这对于解码文本不一致序列特别重要。
- 在编码融合文本和图像token之后,我们使用三种预测器来预测不同的输出。
- 热图预测、分数预测、关键字未对齐序列的预测
4.1.2 Model variants
Multi-head
预测多个热图和分数的一种直接方法是使用多个预测头,每个分数和热图类型都有一个头。这将总共需要七个预测头。
Augmented prompt
另一种方法是为每种预测类型使用一个头,即总共三个头,分别用于热图、分数和未对齐序列。为了向模型通知细粒度热图或分数类型,通过在提示中增加输出类型信息来进行增强。更具体地说,我们将任务字符串(例如,"不合理的热图")添加到示例的每个特定任务提示中,并使用相应的标签作为训练目标。在推理过程中,通过相应的任务字符串增加提示,单个热图(分数)头可以预测不同的热图(分数)。正如我们在实验中所展示的,这种增强提示方法可以创建特定于任务的视觉特征图和文本编码,在某些任务中表现得更好。
### 模型变体
- 多头和增强提示方法。
4.1.3 Model optimization
我们使用逐像素均方误差(MSE)损失来训练模型,用于热图预测、分数预测。对于偏差序列的预测,使用teacher-forcing cross-entropy loss教师强制交叉熵损失训练模型。最后的损失函数是热图MSE损失、分数MSE损失和序列教师强制交叉熵损失的加权组合。
### 损失函数
- 热图MSE损失
- 分数MSE损失
- 教师强制交叉熵损失。交叉熵损失衡量预测序列与真实序列之间的差异,而教师强制是一种在序列生成任务中常用技术,它在训练过程中使用真实输出作为下一个时间步输入,以提高学习效率。
4.2. Experiments
4.2.1 Experimental setup
数据集和模型架构参见前面章节的解读,评估指标和基线参见后面章节的实验效果呈现。
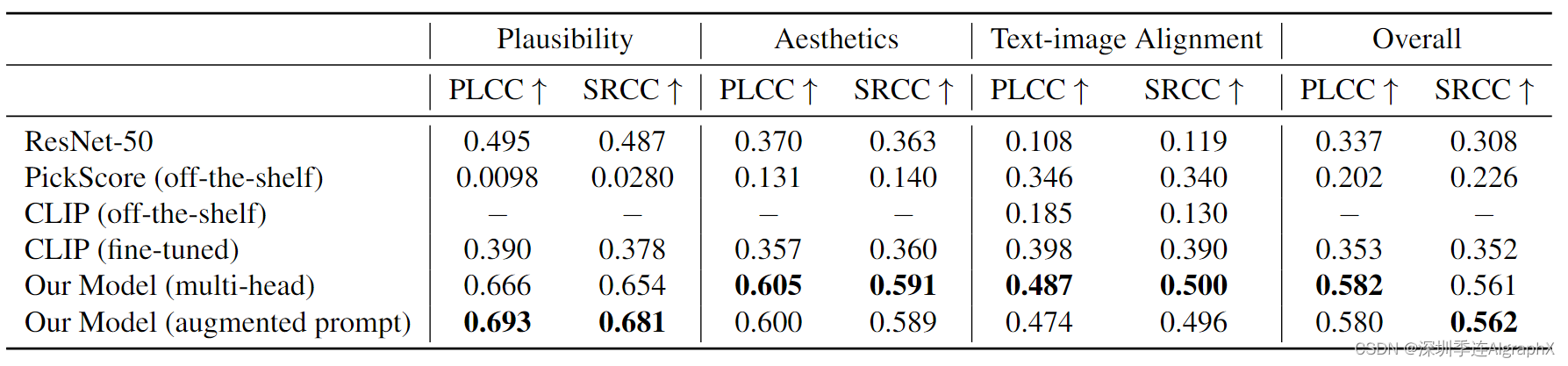
4.2.2 Prediction result on RichHF-18K test set Quantitative analysis
Qualitative examples



Qualitative examples


5. Learning from rich human feedback
在本节中,我们将研究预测的丰富的人类反馈(例如,分数和热图)是否可以用于改进图像生成。为了确保我们的RAHF模型在生成模型家族中得到推广,我们主要使用Muse作为我们的目标模型进行改进,该模型基于掩码Transformer架构,因此不同于我们RichHF-18K数据集中的稳定扩散模型变体。

Figure 8. Examples illustrating the impact of RAHF on generative models.
Finetuning generative models with predicted scores
我们首先说明了使用RAHF分数进行微调可以改善Muse。首先,我们使用预训练 Muse 模型为 12,564 个提示中的每一个生成 8 张图像(提示集是通过 PaLM 2 创建的,带有一些种子提示)。我们预测每个图像的RAHF分数,如果来自每个提示的图像的最高分高于固定阈值,它将被选择作为我们调优数据集的一部分。然后使用该数据集对Muse模型进行微调。这种方法可以看作是直接偏好优化的简化版本。在图8 (a)-(b)中,我们展示了一个使用我们预测的可信性分数(阈值=0.8)微调Muse的例子。为了量化Muse微调的收益,我们使用了100个新的提示来生成图像,并要求6个标注者分别在原始Muse和微调Muse的两张图像之间进行并排比较(为了合理性)。标注者从五种可能的响应(图像A明显/略好于图像B,大致相同,图像B略好于图像A)中进行选择,而不知道使用哪种模型生成图像A/B。实验表明,具有RAHF可信性分数的微调Muse比原始Muse具有更少的伪像/不可信性。
此外,在图8 (c)-(d)中,我们展示了一个使用RAHF美学评分作为潜在扩散模型的分类器指导的示例,类似于Bansal等人的方法,表明每个细粒度评分都可以改善生成模型/结果的不同方面。
Region inpainting with predicted heatmaps and scores
实验证明模型预测热图和分数可以用于执行区域修复,以提高生成图像的质量。对于每个图像,我们首先预测不可信热图,然后通过处理热图(使用阈值和扩张)创建一个掩码。Muse修复应用于掩码区域内,以生成与文本提示匹配的新图像。生成多个图像,并通过我们的RAHF以最高的预测合理性得分来选择最终图像。

Figure 9. Region inpainting with Muse generative model
在图 9 中,预测的不可信性热图和可信性分数显示了几个修复结果。如图所示,修复后生成的图像更合理可信,伪影更少。再一次,这表明我们的RAHF可以很好地泛化到生成模型的图像,这与用于训练RAHF的图像非常不同。更多的细节和例子可以在补充材料中找到。
6. Conclusions and limitations
在这项工作中,我们贡献了RichHF-18K,这是第一个用于图像生成的丰富的人类反馈数据集。我们设计并训练了一个多模态 Transformer 模型RAHF来预测丰富的人类反馈,并展示了一些实例来改进具有丰富人类反馈的图像生成。
虽然我们的一些结果非常令人兴奋和有前途,但我们的工作有一些限制。首先,模型在未对准热图上的性能比在不可信热图上的性能差,这可能是由于未对准热图中的噪声。如何标注一些未对齐的情况,如图像上的缺失对象,还有些模棱两可。提高错位标签的质量是今后的发展方向之一。其次,收集更多的除Pick-a-Pic(稳定扩散)以外的生成模型的数据,并研究它们对RAHF模型的影响将会有所帮助。此外,虽然我们提出了三种很有前途的方法来改善T2I的生成,但还有许多其他方法可以探索,例如,如何使用预测的热图或分数作为奖励信号并通过强化学习微调生成模型,以及如何使用预测热图作为加权图,或者如何在从人类反馈中学习时使用预测的错位序列来帮助改善图像生成,等等。我们希望RichHF-18K和RAHF初始模型能启发人们在未来工作中探索这些研究方向。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删,转发请注明出处。
https://arxiv.org/abs/2312.10240
The RichHF-18K dataset can be downloaded at GitHub - google-research-datasets/richhf-18k.