这医学图像分割领域啊,终究还是被 Stable Diffusion 闯进去了~
SDSeg:第一个基于 Stable Diffusion 的 latent 扩散医学图像分割模型,在五个不同医学影像模态的基准数据集上超越了现有的最先进方法~
论文:Stable Diffusion Segmentation for Biomedical Images with Single-step Reverse Process
代码:https://github.com/lin-tianyu/Stable-Diffusion-Seg
0、摘要
扩散模型已经证明了它们在各种生成任务中的有效性。然而,当应用于医学图像分割时,这些模型遇到了一些挑战,包括大量的资源和时间需求。他们还需要一个多步骤的反向过程和多个样本来产生可靠的预测。
为了解决这些挑战,本文引入了第一个 latent diffusion 分割模型 SDSeg,建立在 stable diffusion(SD)上。SDSeg 采用了一个简单的 latent 估计策略,以促进单步反向过程,并利用潜在融合连接来消除对多个样本的必要性。
大量的实验表明,SDSeg在五个具有不同成像模态的基准数据集上超越了现有的最先进的方法。
1、引言
1.1、现有基于diffusion的图像分割模型的局限性
(1)与普通图像相比,分割mask的信息是稀疏的,在 pixel 空间做 diffusion 会导致优化效率低,计算成本高;
(2)扩散模型采样过程需要多个步骤迭代完成,在分割应用中,常需要多个样本平均以进行稳定的预测;
1.2、本文贡献
(1)SDSeg 基于 LDM(latent diffusion model),在较低分辨率的感知等效潜在空间上进行扩散过程,使扩散过程计算友好;
(2)引入了一种简单的潜在估计损失(latent estimation loss),使 SDSeg 能够在单步反向过程( a single-step reverse process)中生成分割结果,并提出了一种连接潜在融合技术( a concatenate latent fusion technique)来消除对多样本的需要;
(3)SDSeg 在5个基准数据集上实现了最先进的性能,并通过减少训练资源、提高推理速度和增强生成稳定性,显著改进了基于扩散的分割模型;
2、方法
方法框架如图1所示,训练时冻结编解码器。
SDSeg 结构图,基本跟 LDM 差不多: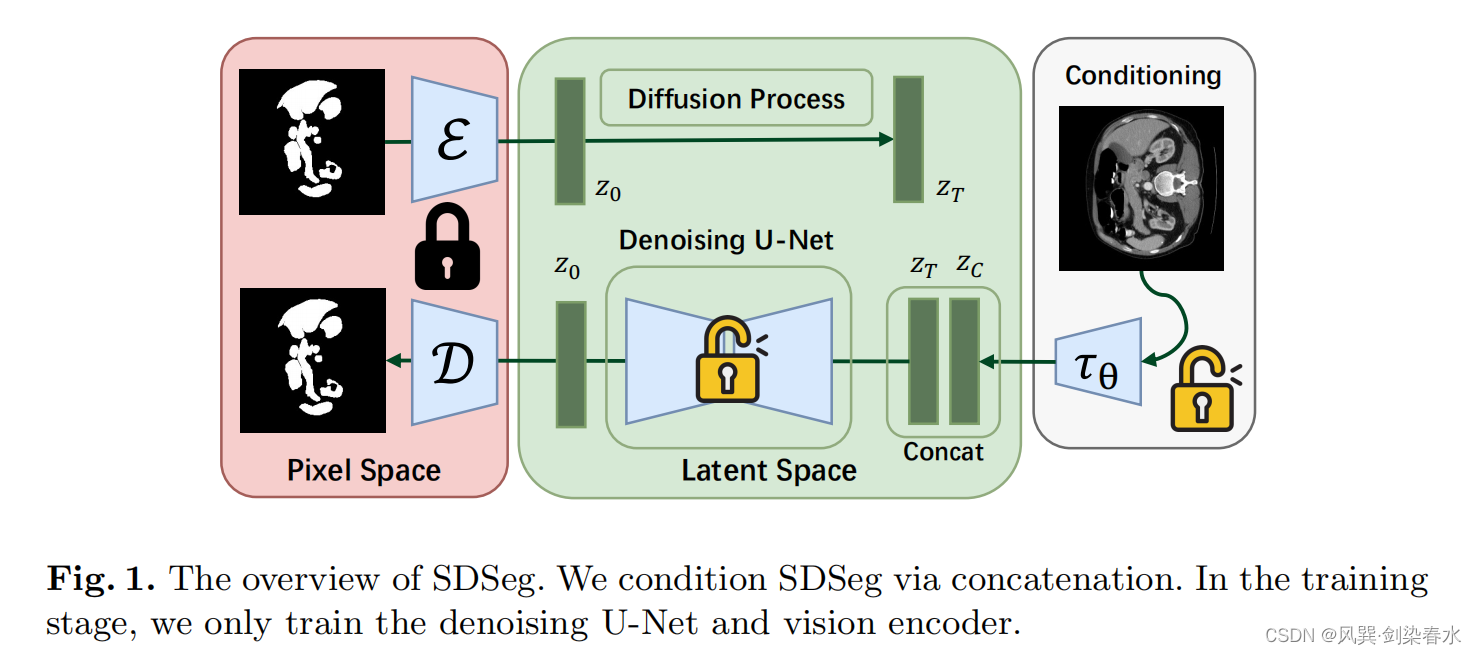
2.1、潜在估计
(1)扩散前向过程:
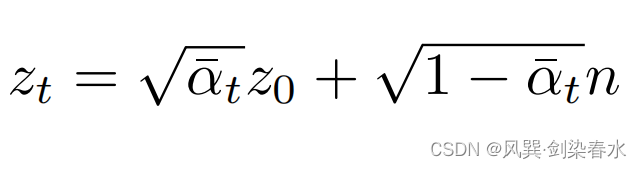
(2)U-Net 网络采用预测噪声的方法;
本文认为分割任务 mask 相比其他图像简单,因此没有从扩散的多步反向过程中显著获益,一个成熟的去噪 U-Net 能够恢复包含分割 mask 的所有必要的结构和空间特征的潜在特征。
(3)故在得到估计的噪声后,可以通过等式的简单变换直接推导出相应的潜在估计(前向过程公式变形):
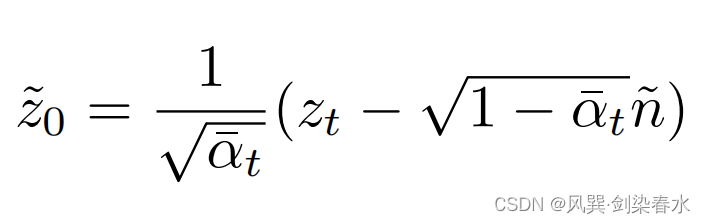
(4)损失函数,noise 和 latent 损失均采用 MAE, λ = 1 {λ=1} λ=1:
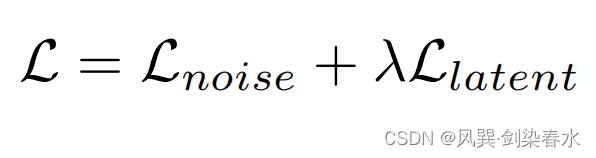
2.2、连接潜在融合
本文认为,分割图与相应的潜在表征表现出明显的空间相关性,其中可能包含了必要的结构和特征信息,有利于分割任务。
故采用 concatenation 方式,这是一种常用的有效的整合图像语义特征的策略,将分割映射的潜在表示与原始图像的潜在表示合并,即图1中的 Z T {Z_T} ZT 和 Z C {Z_C} ZC 。(朴实无华,简单有效)
潜在表示和重建可视化:

2.3、可训练的视觉编码器
编码原始图像和编码 mask 的编码器结构一样,若冷冻其权重,效果也还过得去,但作者为了使 SDSeg 适应各种医学图像数据集模式,增强其多功能性和有效性,编码原始图像的编码器 τ θ { τ_θ } τθ 是可训练的。
3、实验与结果
3.1、数据集
5个公开数据集,3个RGB数据集二维分割(肠镜息肉、眼底照相视杯),2个CT数据集三维分割(腹部器官、牙齿),(好像数据也不是特别多呀~)
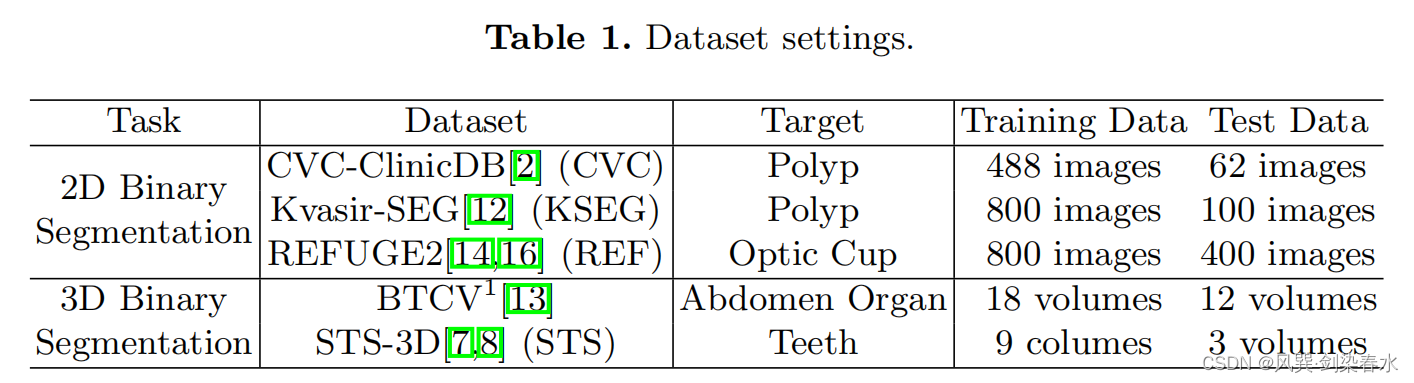
3.2、评价指标
(1)分割效果评价:Dice系数、IoU;
(2)计算资源的使用和推理速度;
(3)分割结果的稳定性:LPIPS、PSNR、SSIM、MS-SSIM
3.3、实施细节
(1)显卡:V100 16GB;
(2)优化器:AdamW;
(3)学习率: 1 × 1 0 − 5 {1×10^{−5}} 1×10−5;
(4)步数:100000;
(5)batch size:4;
(6)隐空间降采样率:8;
(7)输入图像大小:256×256;
(8)隐空间图像大小:4×32×32;
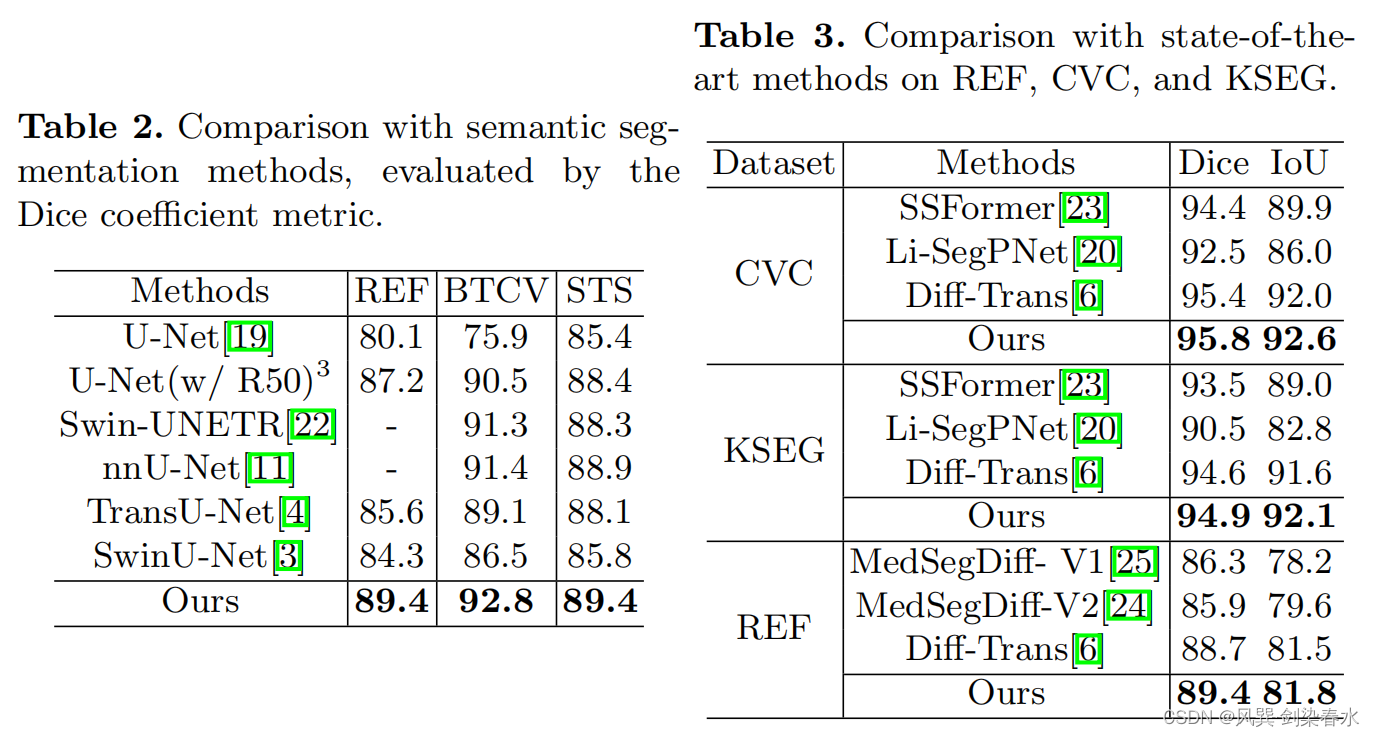
3.4、与当前最优结果对比
3.5、计算资源和时间效率的比较
公平比较:同一个服务器上使用其他模型的源代码进行训练的;

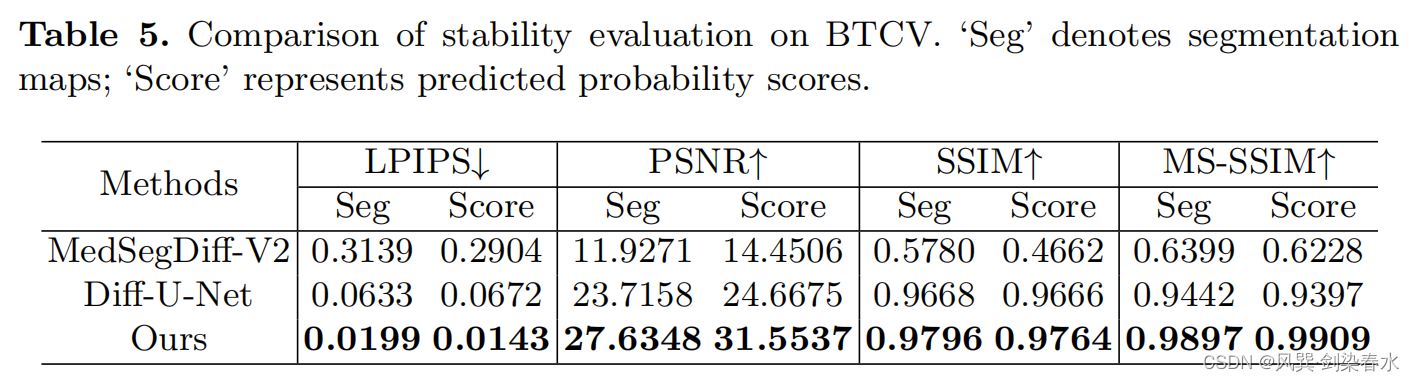
3.6、稳定性比较
扩散模型是生成模型,它们生成的样本可以表现出可变性。然而,在医学分割模型的背景下,多样性并不被认为是一个有利的特征,因为医学专业人员需要人工智能的帮助,才能保持一致和可靠。
(1)Dataset-level 稳定性:使用LIPIS指标,以测量不同推断之间的可变性;
(2)Instance-level 稳定性:以PSNR、SSIM和MS-SSIM为指标,通过在固定条件下进行重复推断,来检验模型在不同初始噪声下的一致性;
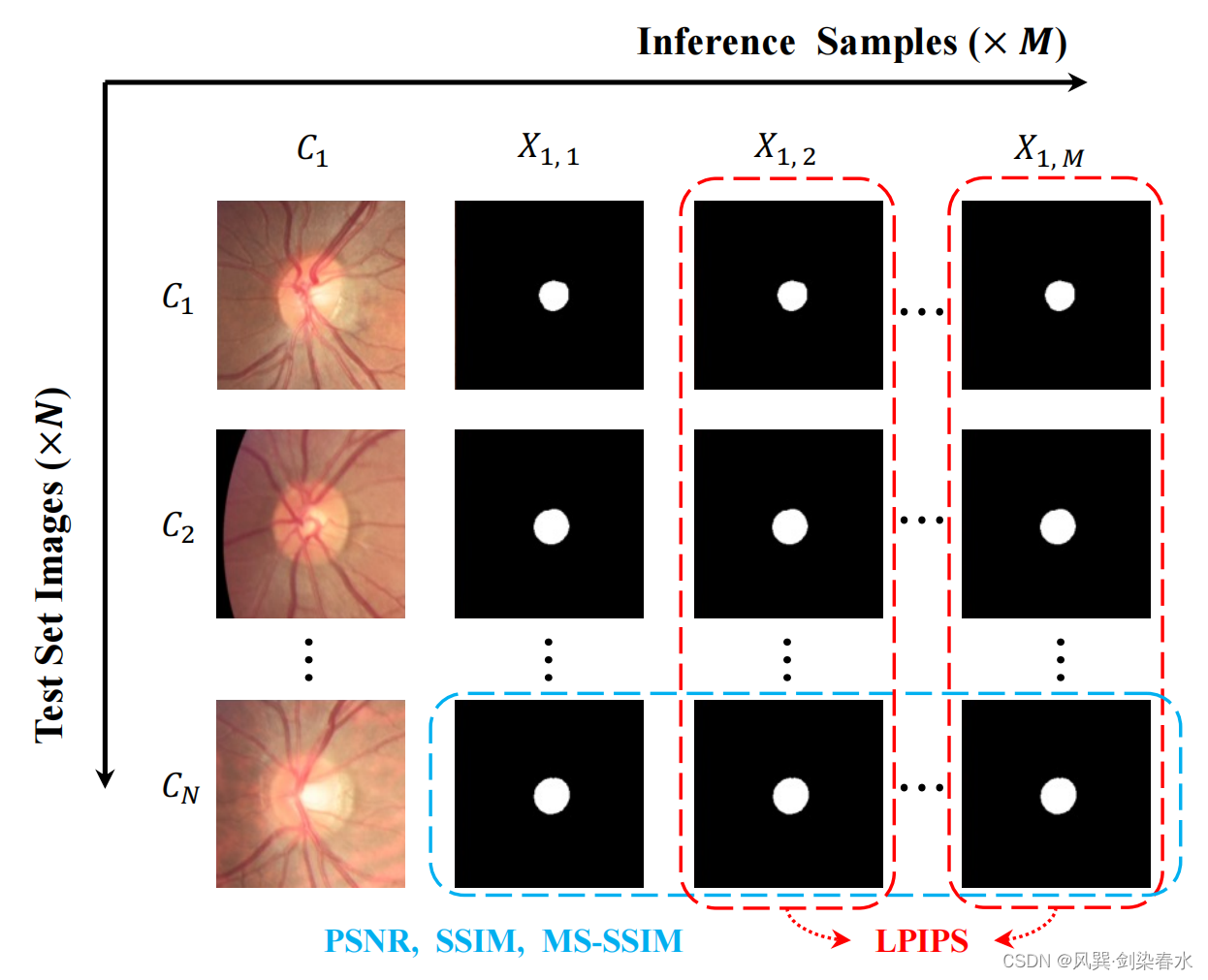
评价指标含义:
3.7、消融实验
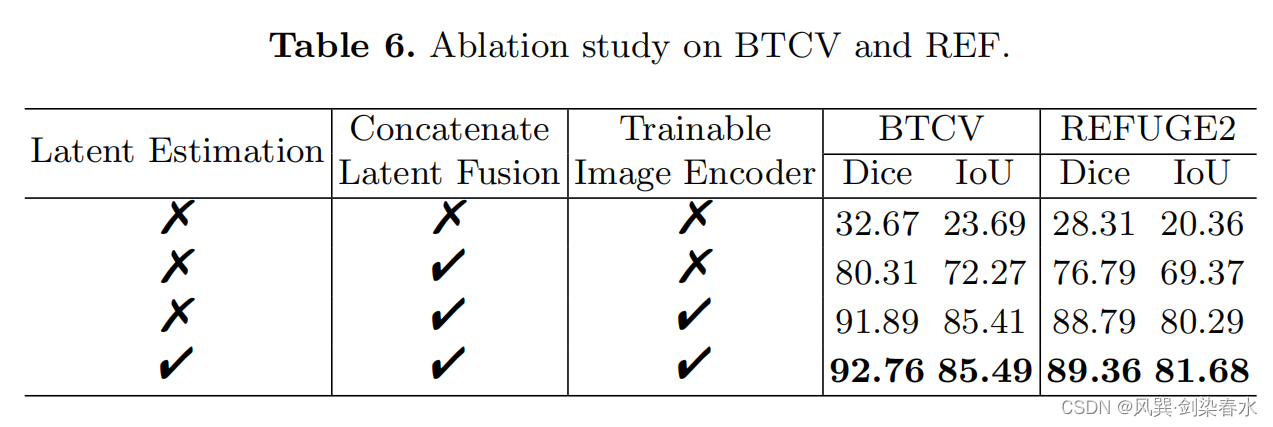
为什么别人的 diffusion 那么好训又好使呢,暴风哭泣 /(ㄒoㄒ)/~~