文章目录
- 前言:
- 今日所学:
-
- [1. 数据集处理](#1. 数据集处理)
- [2. 网络的构建](#2. 网络的构建)
- [3. 模型训练](#3. 模型训练)
- [4. 保存模型](#4. 保存模型)
- [5. 加载模型](#5. 加载模型)
- 总体代码与运行结果:
-
- [1. 总体代码](#1. 总体代码)
- [2. 运行结果](#2. 运行结果)
前言:
今天是学习打卡的第2天,今天的内容是对MindSpore的一个快速入门,主要通过MindSpore的API来快速实现一个简单的深度学习模型,首先我们要确保我们的实验环境安装了mindspore,可以通过如下代码来安装所需版本的mindspore如下:
python
%%capture captured_output
# 实验环境已经预装了mindspore==2.3.0rc1,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.3.0rc1今日所学:
1. 数据集处理
首先我们要在代码中申明我们所需要用到的库:
python
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset然后对我们所需要使用的Mnist数据集来进行下载:
python
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
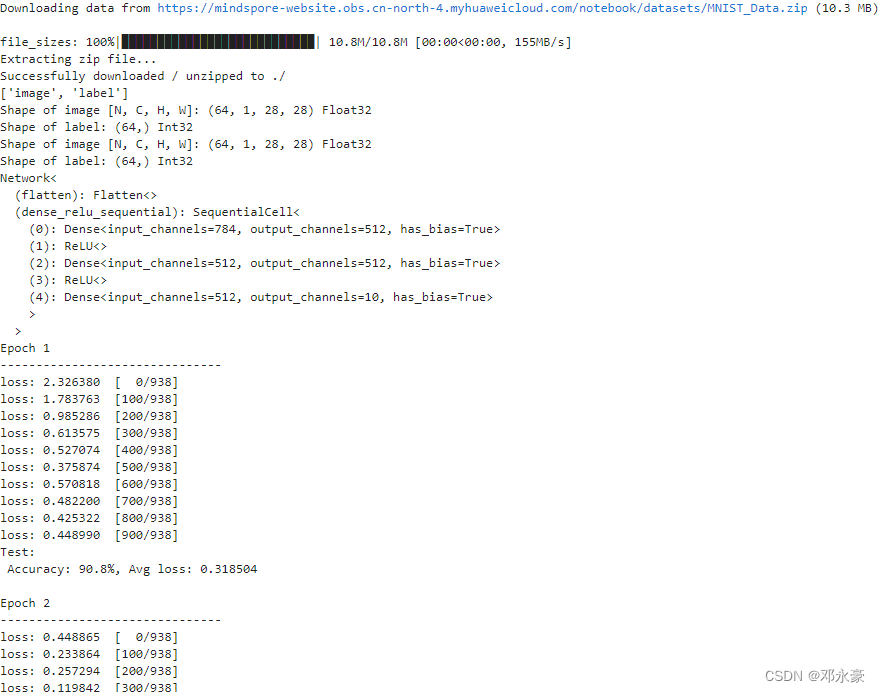
然后后去数据集对象后打印数据列名等用于dataset的预处理。
2. 网络的构建
通过mindspore.nn类来进行网络构建的过程,它是构建所有网络的基类,也是网络的基本单元,具体的构建如下:
python
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)得到如下的结果:
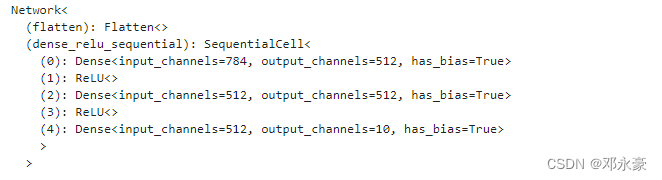
3. 模型训练
在进行了以上两步后我们进一步来进行模型训练,一个完整的模型训练一般需要如下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
针对以上模型训练的三个步骤我们通过如下代码来实现:
python
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 第一步:首先我们定义了正向计算函数
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 第二步:然后通过value_and_grad获得梯度计算函数
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 第三部:定义训练函数从而来执行正向计算、反向传播与参数优化
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")然后在此训练之外我们定义测试函数test来评估模型性能吗,并且设置多次迭代数据集来提高我们的预测准确率。
4. 保存模型
在模型训练完毕后我们通过如下的代码来对我们的模型保存:
python
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")5. 加载模型
通过一下代码加载模型:
python
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)加载之后的模型即可进行预测推理:
python
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break
总体代码与运行结果:
1. 总体代码
python
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
print(train_dataset.get_col_names())
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
# Map vision transforms and batch dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
break
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 第一步:首先我们定义了正向计算函数
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 第二步:然后通过value_and_grad获得梯度计算函数
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 第三部:定义训练函数从而来执行正向计算、反向传播与参数优化
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
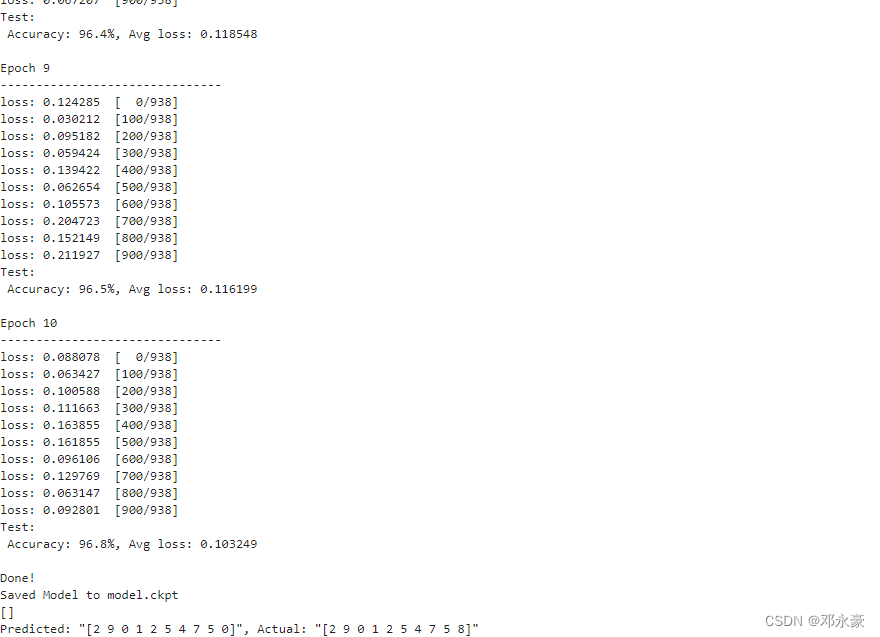
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)
print("Done!")
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break2. 运行结果