Inception_V2_V3_pytorch
在上一节我们已经精度了Inception_V2_V3这篇论文,本篇我们将用pyorch复现论文中的网络结构!
从论文中我们可以知道InceptionV3的主要改进为:
- 5 * 5卷积分解为2个3 * 3卷积核
- 分解为不对称卷积
- 滤波器组
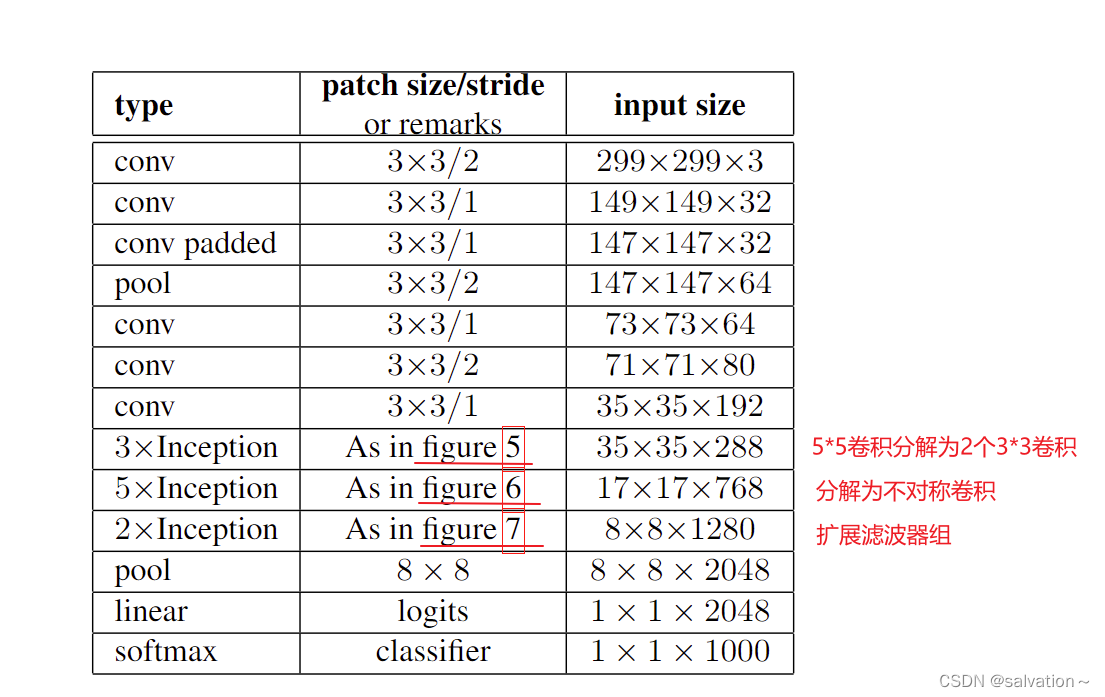
我们可将GoogLeNetv3分解为以下5个模块:
- InceptionV3模块
- 辅助分类器模块
- 非对称分离式卷积
- 滤波器组
- 用2个3 * 3卷积核代替1个5 * 5 卷积核
接下来我们将在Layers.py中定义Separable_Conv2d,Concat_Separable_Conv2d,Conv2d,Flatten,Squeeze这些类。
Separable_Conv2d
实现的是下面这中非对称分离式卷积结构!
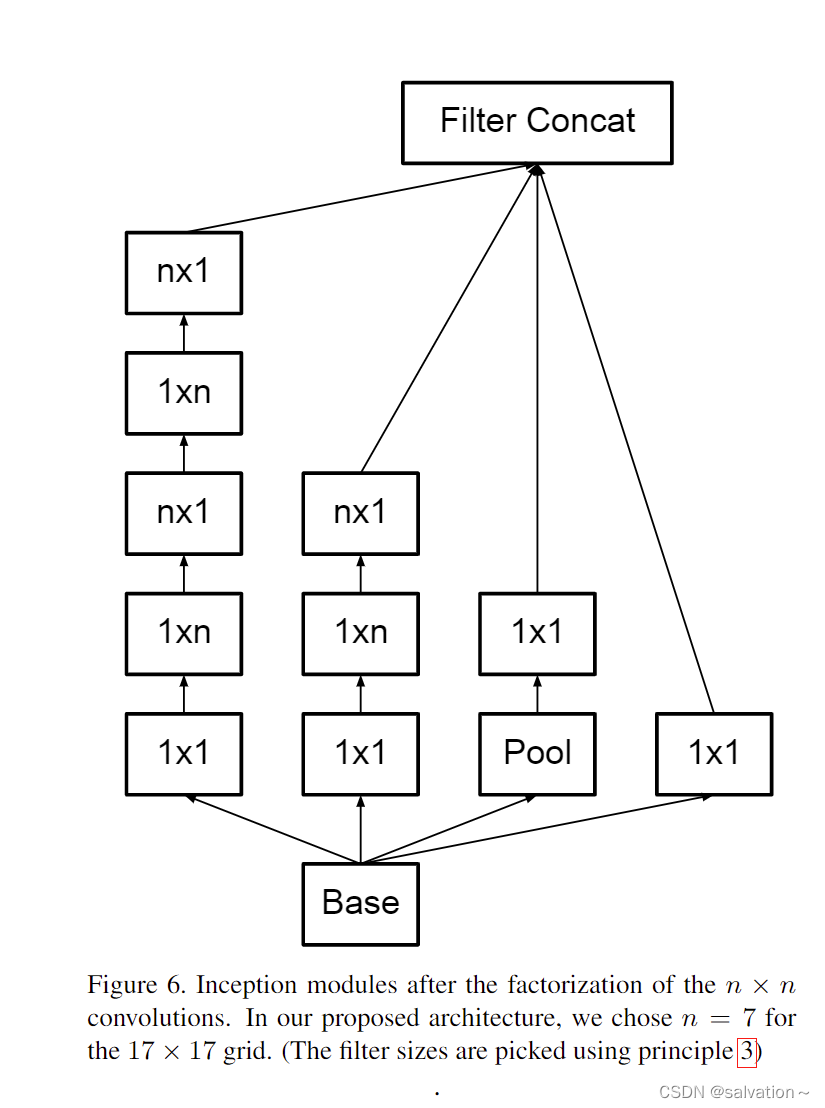
Concat_Separable_Conv2d
实现的是下面滤波器组的结构

Layers.py中代码如下:
python
import torch
import torch.nn as nn
# 非对称分离式卷积
class Separable_Conv2d(nn.Module):
def __init__ (self,in_channels,out_channels,kernel_size,stride = 1,padding = 0):
super(Separable_Conv2d,self).__init__()
self.conv_h = nn.Conv2d(in_channels,in_channels,(kernel_size,1),stride=(stride,1),padding=(padding,0))
self.conv_w = nn.Conv2d(in_channels,out_channels,(1,kernel_size),stride=(1,stride),padding=(0,padding))
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
x = self.conv_h(x)
x = self.conv_w(x)
x = self.bn(x)
x = self.relu(x)
return x
# 滤波器组
class Concat_Separable_Conv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride = 1,padding=0):
super(Concat_Separable_Conv2d,self).__init__()
self.conv_h = nn.Conv2d(in_channels,in_channels,(kernel_size,1),stride=(stride,1),padding=(padding,0))
self.conv_w = nn.Conv2d(in_channels,out_channels,(1,kernel_size),stride=(1,stride),padding=(0,padding))
self.bn = nn.BatchNorm2d(out_channels * 2)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
x_h = self.conv_h(x)
x_w = self.conv_w(x)
x = torch.cat([x_h,x_w],dim=1)
x = self.bn(x)
x = self.relu(x)
return x
# 定义基础的卷积模块添加BN和ReLU
class Conv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, output=False):
super(Conv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.output = output
if self.output == False:
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
if self.output:
return x
else:
x = self.bn(x)
x = self.relu(x)
return x
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
return torch.flatten(x, 1)
class Squeeze(nn.Module):
def __init__(self):
super(Squeeze, self).__init__()
def forward(self, x):
return torch.squeeze(x)
python
import torch
import torch.nn as nn
from Layers import *
import torch.nn.functional as F
from functools import partial
class Inceptionv3(nn.Module):
def __init__(self,input_channels,conv1_channel,conv3_reduce_channel,conv3_channel,
conv3_double_reduce_channel,conv3_double_channel,
pool_reduce_channel,stride = 1,pool_type = 'AVG',mode = 1):
super(Inceptionv3,self).__init__()
self.stride = stride
if stride == 2:
padding_conv3 = 0
padding_conv7 = 2
else:
padding_conv3 = 1
padding_conv7 = 3
if conv1_channel != 0:
self.conv1 = Conv2d(input_channels,conv1_channel,kernel_size = 1)
else:
self.conv1 = None
self.conv3_reduce = Conv2d(input_channels,conv3_reduce_channel,kernel_size = 1)
match mode:
case '1': # 用两个3*3卷积代替一个5*5卷积
self.conv3 = Conv2d(conv3_reduce_channel,conv3_channel,kernel_size = 3,stride = stride,padding = padding_conv3)
self.conv3_double1 = Conv2d(conv3_double_reduce_channel,conv3_double_channel,kernel_size = 3,padding = 1)
self.conv3_double2 = Conv2d(conv3_double_channel,conv3_double_channel,kernel_size = 3,stride=stride,padding = padding_conv3)
case '2': # 非对称分离式卷积
self.conv3 = Separable_Conv2d(conv3_reduce_channel,conv3_channel,kernel_size = 7,stride = stride,padding = padding_conv7)
self.conv3_double1 = Separable_Conv2d(conv3_double_reduce_channel,conv3_double_channel,kernel_size = 7,padding = 3)
self.conv3_double2 = Separable_Conv2d(conv3_double_channel,conv3_double_channel,kernel_size = 7,stride=stride,padding = padding_conv7)
case '3': # 滤波器组
self.conv3 = Concat_Separable_Conv2d(conv3_reduce_channel,conv3_channel,kernel_size = 3,stride = stride,padding = 1)
self.conv3_double1 = Conv2d(conv3_double_reduce_channel,conv3_double_channel,kernel_size = 3,padding = 1)
self.conv3_double2 = Concat_Separable_Conv2d(conv3_double_channel,conv3_double_channel,kernel_size = 3,stride=stride,padding = 1)
self.conv3_double_reduce = Conv2d(input_channels,conv3_double_reduce_channel,kernel_size = 1)
if pool_type == 'MAX':
self.pool = nn.MaxPool2d(kernel_size = 3,stride = stride,padding = padding_conv3)
elif pool_type == 'AVG':
self.pool = nn.AvgPool2d(kernel_size = 3,stride = stride,padding = padding_conv3)
if pool_reduce_channel != 0:
self.pool_reduce = Conv2d(input_channels,pool_reduce_channel,kernel_size = 1)
else:
self.pool_reduce = None
def forward(self,x):
output_conv3 = self.conv3(self.conv3_reduce(x))
output_conv3_double = self.conv3_double2(self.conv3_double1(self.conv3_double_reduce(x)))
if self.pool_reduce != None:
output_pool = self.pool_reduce(self.pool(x))
else:
output_pool = self.pool(x)
if self.conv1 != None:
output_conv1 = self.conv1(x)
outputs = torch.cat([output_conv1,output_conv3,output_conv3_double,output_pool],dim = 1)
else:
outputs = torch.cat([output_conv3,output_conv3_double,output_pool],dim = 1)
return outputs
python
# 辅助分类器
class InceptionAux(nn.Module):
def __init__(self,input_channels,num_classes):
super(InceptionAux,self).__init__()
self.aux = nn.Sequential(
nn.AvgPool2d(kernel_size = 5,stride = 3),
Conv2d(input_channels,128,kernel_size = 1),
Conv2d(128,1024,kernel_size = 5),
Conv2d(1024,num_classes,kernel_size = 1,output = True),
Squeeze()
)
def forward(self,x):
x = self.aux(x)
return x
python
class GoogLeNetv3(nn.Module):
def __init__(self,num_classes,mode = 'train'):
super(GoogLeNetv3,self).__init__()
self.num_classes = num_classes
self.mode = mode
self.layers = nn.Sequential(
Conv2d(3,32,3,stride=2),
Conv2d(32,32,3,stride = 1),
Conv2d(32,64,kernel_size = 3,stride=1,padding = 1),
nn.MaxPool2d(kernel_size= 3 ,stride = 2),
Conv2d(64,80,kernel_size = 3),
Conv2d(80,192,kernel_size=3,stride=2),
Conv2d(192,288,kernel_size=3,stride=1,padding=1),
Inceptionv3(288,64,48,64,64,96,64,mode='1'), #3a
Inceptionv3(288,64,48,64,64,96,64,mode='1'), #3b
Inceptionv3(288,0,128,384,64,96,0,stride=2,pool_type='MAX',mode='1'), #3c
Inceptionv3(768,192,128,192,128,192,192,mode='2'), #4a
Inceptionv3(768,192,160,192,160,192,192,mode='2'), #4b
Inceptionv3(768,192,160,192,160,192,192,mode='2'), #4c
Inceptionv3(768,192,192,192,192,192,192,mode='2'), #4d
Inceptionv3(768,0,192,320,192,192,0,stride=2,pool_type='MAX',mode='2'), #4e
Inceptionv3(1280,320,384,384,448,384,192,mode='3'), #5a
Inceptionv3(2048,320,384,384,448,384,192,pool_type='MAX',mode='3'), #5b
nn.AvgPool2d(8,1),
Conv2d(2048,num_classes,kernel_size=1,output=True),
Squeeze(),
)
if mode == 'train':
self.aux = InceptionAux(768,num_classes)
def forward(self,x):
for idx,layer in enumerate(self.layers):
if(idx == 14 and self.mode == 'train'):
aux = self.aux(x)
x = layer(x)
if self.mode == 'train':
return x,aux
else:
return x
def init_weights(self,init_mode = 'VGG'):
def init_function(m,init_mode):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
if init_mode == 'VGG':
torch.nn.init.normal_(m.weight,mean=0.0,std=0.01)
elif init_mode == 'XAVIER':
fan_in,fan_out = torch.nn.init._calculate_fan_in_and_fan_out(m.weight)
std = (2.0 / float(fan_in + fan_out)) ** 0.5
a = (3.0)**0.5 * std
with torch.no_grad():
m.weight.uniform_(-a,a)
elif init_mode == 'KAMING':
torch.nn.init.kaiming_uniform(m.weight)
m.bias.data.fill_(0)
_ = self.apply(partial(init_function,init_mode = init_mode))
python
from torchsummary import summary
net = GoogLeNetv3(1000).cuda()
summary(net, (3, 299, 299))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 149, 149] 896
BatchNorm2d-2 [-1, 32, 149, 149] 64
ReLU-3 [-1, 32, 149, 149] 0
Conv2d-4 [-1, 32, 149, 149] 0
Conv2d-5 [-1, 32, 147, 147] 9,248
BatchNorm2d-6 [-1, 32, 147, 147] 64
ReLU-7 [-1, 32, 147, 147] 0
Conv2d-8 [-1, 32, 147, 147] 0
...
Concat_Separable_Conv2d-331 [-1, 768, 8, 8] 0
MaxPool2d-332 [-1, 2048, 8, 8] 0
Conv2d-333 [-1, 192, 8, 8] 393,408
BatchNorm2d-334 [-1, 192, 8, 8] 384
ReLU-335 [-1, 192, 8, 8] 0
Conv2d-336 [-1, 192, 8, 8] 0
Conv2d-337 [-1, 320, 8, 8] 655,680
BatchNorm2d-338 [-1, 320, 8, 8] 640
ReLU-339 [-1, 320, 8, 8] 0
Conv2d-340 [-1, 320, 8, 8] 0
Inceptionv3-341 [-1, 2048, 8, 8] 0
AvgPool2d-342 [-1, 2048, 1, 1] 0
Conv2d-343 [-1, 1000, 1, 1] 2,049,000
Conv2d-344 [-1, 1000, 1, 1] 0
Squeeze-345 [-1, 1000] 0
================================================================
Total params: 28,850,400
Trainable params: 28,850,400
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 1.02
Forward/backward pass size (MB): 270.86
Params size (MB): 110.06
Estimated Total Size (MB): 381.94
----------------------------------------------------------------1, 1000, 1, 1] 2,049,000
Conv2d-344 -1, 1000, 1, 1 0
Squeeze-345 -1, 1000 0
================================================================
Total params: 28,850,400
Trainable params: 28,850,400
Non-trainable params: 0
Input size (MB): 1.02
Forward/backward pass size (MB): 270.86
Params size (MB): 110.06
Estimated Total Size (MB): 381.94