论文:High-fidelity GAN Inversion with Padding Space
paper:136750036.pdf (ecva.net)
code:EzioBy/padinv: ECCV 2022 PadInv: High-fidelity GAN Inversion with Padding Space (github.com)
关键词:GAN, GAN 反演 ( GAN Inversion ), CV, CNN
1:问题与解决
对于GAN反演当下存在的对于图像空间细节无法很好的恢复的问题,作者认为这可能来源于在卷积层之前对特征图的填充操作(padding)。padding 通常会在原特征图中填充0来扩大特征图的空间维度。这填充的值是固定的而不是在训练阶段学习的,作者认为这可能带来一些归纳偏差,使得生成的图像出现 "纹理粘附" 的问题。
可以理解为:假如我们对一幅特征图做填充操作的常数正好是另一个特征的编码信息,这样就会导致两个特征粘在一起(粘在一些像素上,那部分像素既是特征1的也是特征2的),但特征编码是不同的。如果粘附在一起的特征都是域内特征,这种问题在反演阶段可能并不明显,但是在图像编辑时就会发现像素的粘附,破坏了生成图像的质量。但如果是域外特征和域内特征粘在一起,在 latent space 内通过参数搜索来反演它们就变得很困难。
为解决这个问题,作者提出了一种新的GAN反演方法,称为PadInv,其通过将生成器的填充空间作为除 lantent space 之外的扩展反演空间。具体来说,作者为每个单独的图像调整生成器中使用的填充系数,而不是继承 GAN 训练中假设的归纳偏置(例如,零填充)。这种实例感知的重编程能够用足够的空间信息来补充潜在空间,特别是对于那些超出分布的情况。
2:方法
2.1 网络架构
图1:PadInv 网络
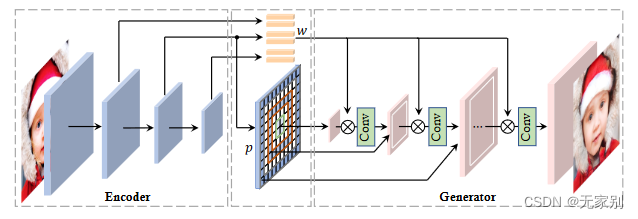
该网络中编码器 E E E 不仅仅产生图像对于 lantent code 还在同时产生一个系数张量 (图中的 p)来替换生成器 G G G 中卷积层中使用的填充。
2.2 训练
文中采用的损失都是常见的损失函数:
1:重构损失,包括一个逐像素L2损失和一个感知L2损失:
L p i x = ∣ ∣ x − G ( E ( x ) ) ∣ ∣ 2 L_{pix}=||x-G(E(x))||{2} Lpix=∣∣x−G(E(x))∣∣2
L p e r = ∣ ∣ ϕ ( x ) − ϕ ( G ( E ( x ) ) ) ∣ ∣ 2 L{per}= ||\phi(x)-\phi (G(E(x)))||_{2} Lper=∣∣ϕ(x)−ϕ(G(E(x)))∣∣2
其中 ϕ \phi ϕ 是一种预训练的感知特征提取神经网络。
2:身份损失,这类损失是专门为反演人脸生成模型而设计的:
L i d = 1 − cos ( ψ ( x ) , ψ ( G ( E ( x ) ) ) ) L_{id}=1-\cos(\psi(x),\psi(G(E(x)))) Lid=1−cos(ψ(x),ψ(G(E(x))))
其中 cos \cos cos 为计算余弦相似度, ψ \psi ψ 为一个预训练的身份特征提取神经网络。
3:对比损失。为了避免模糊重建,编码器还被要求与鉴别器竞争,从而产生对抗性训练方式。
L a d v = − E x ∼ X D ( G ( E ( x ) ) ) L_{adv}=-\mathbb{E}_{x\sim X} \left D(G(E(x))) \\right Ladv=−Ex∼XD(G(E(x)))
其中 E· 为期望运算,X 为实际数据分布。D(·) 表示鉴别器。
4:正则化损失。StyleGAN生成器维护一个平均的 lantent code w ˉ \bar{w} wˉ,它可以看作是潜在空间 w的统计量。我们期望反转的代码尽可能地服从于本地潜在分布:
L r e g = ∣ ∣ E l a n t e n t ( x ) − w ˉ ∣ ∣ 2 L_{reg}=||E_{lantent}(x)-\bar{w} ||_{2} Lreg=∣∣Elantent(x)−wˉ∣∣2
其中 E l a t e n t ( ⋅ ) E_{latent}(·) Elatent(⋅)表示编码器不包括填充的 lantent code。
编码器的总损失函数为以上损失函数的加和:
L E = λ pix L pix + λ per L per + λ i d L i d + λ adv L a d v + λ reg L reg \mathcal{L}{E}=\lambda{\text {pix }} \mathcal{L}{\text {pix }}+\lambda{\text {per }} \mathcal{L}{\text {per }}+\lambda{i d} \mathcal{L}{i d}+\lambda{\text {adv }} \mathcal{L}{a d v}+\lambda{\text {reg }} \mathcal{L}_{\text {reg }} LE=λpix Lpix +λper Lper +λidLid+λadv Ladv+λreg Lreg
5:判别器 D D D 损失函数:
L D = E x ∼ X D ( G ( E ( x ) ) ) − E x ∼ X D ( x ) − γ 2 E x ∼ X ∥ ∇ x D ( x ) ∥ 2 , \mathcal{L}D=\mathbb{E}{\mathbf{x}\sim\mathcal{X}}D(G(E(\\mathbf{x})))-\mathbb{E}{\mathbf{x}\sim\mathcal{X}}D(\\mathbf{x})-\frac{\gamma}{2}\mathbb{E}{\mathbf{x}\sim\mathcal{X}}\\\|\\nabla_{\\mathbf{x}}D(\\mathbf{x})\\\|_2, LD=Ex∼XD(G(E(x)))−Ex∼XD(x)−2γEx∼X∥∇xD(x)∥2,
其中 γ \gamma γ 为梯度惩罚的超参数。