MongoDB的配置服务器
引入了分片机制之后,MongoDB启用了配置服务器 (config server) 来存储元数据,这些元数据包括分片信息、权限控制信息 ,用来控制分布式锁。其中分片信息还会被负责执行查询mongos使用。
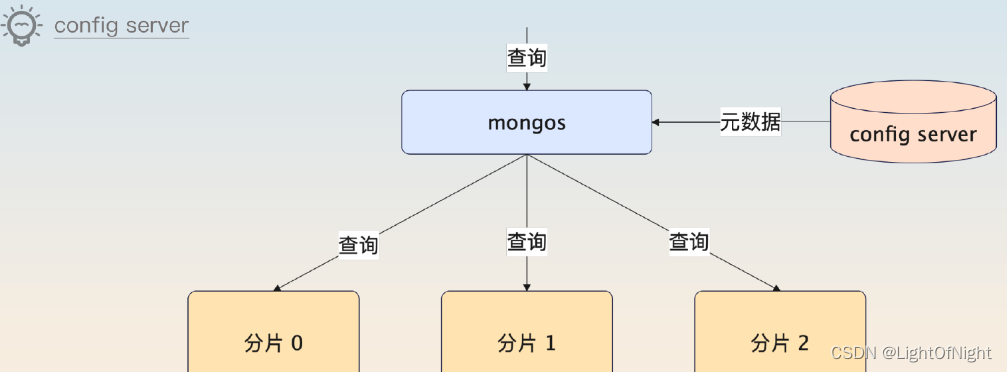
MongoDB的配置服务器有一个很大的优点,就是主节点崩溃了,它也可以继续提供读服务 。
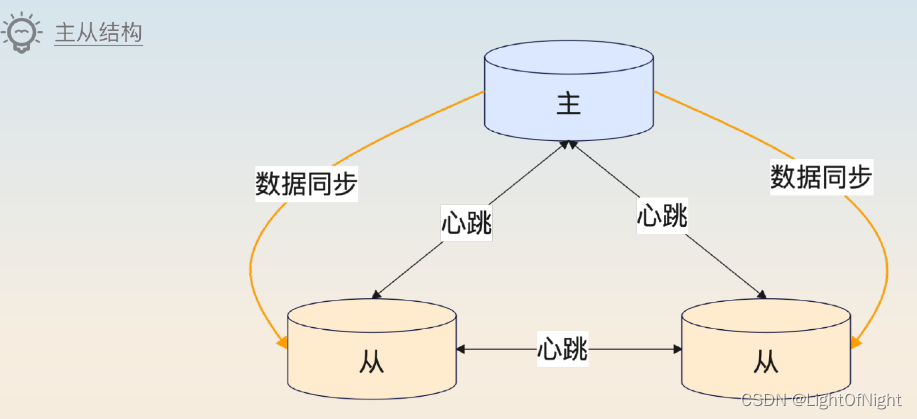
大多数中间件的主从结构都是在主节点崩溃之后完全不可用,直到选举出了一个新的主节点。
但是不管怎么说,配置服务器在MongoDB里是一个非常关键的组件,如果一旦配置服务器有问题,哪怕只是轻微地性能抖动一下,对整个MongoDB集群的影响都很大。
MongoDB的复制机制(主从机制)
MongoDB的副本也是MongoDB实例,它们和主实例持有一样的数据。在MongoDB里,用Primary来代表主实例,用Secondary来代表副本实例。主从实例合并在一起,也叫做一个复制集(Replica Set)
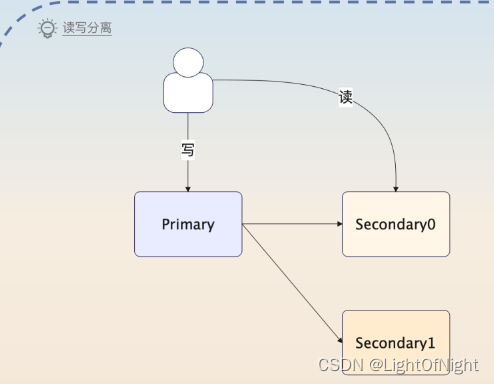
类似于数据库的读写分离机制,可以在MongoDB上进行读写分离。读从Secondary0实例读,写入Primary实例,同时Secondary0和Secondary1从Primary实例里同步数据
在MongoDB里,主从之间的数据同步是通过所谓的oplog来实现的,类似MySQL的binlog。但是oplog会有一些缺点:
- 在一些特定的操作里,oplog可能会超乎想象地大。这主要是因为oplog是幂等的,所以任何操作都比要转化为幂等操作 。简单来说,任何对MongoDB里数据的操作,最后都会被转化成一个set操作。所以可以预计的是,就是只更新了数据的一小部分,但是生成的oplpg还是set整个数据。
- oplog是有期限 的,即MongoDB限制了oplog的大小 。当oplog占据了太多的磁盘之后,就会被删除。就算某个从节点来不及同步,oplog也是会被删除的。这个时候,这个从节点只能重新发起一次全量的数据同步。
写入语义
和Kafka的写入语义非常像,可以通过参数来控制写入数据究竟写到哪里,写入语义对性能、可用性和数据可靠性 有显著的影响。
在MongoDB里,写入语义也叫Write Concern,它由w、j和wtimeout三个参数控制。
w参数
它的取值如下:
majority:要求写操作已经同步给大部分节点,默认取值,可用性强,但是写入性能差- 数字
N:如果N=1,要求必须写入主节点;如果N大于1,那么就必须写入主节点,而且写入N-1个从节点;如果N=0,那么就不用等任何节点写入。性能很好,但是虽然客户端收到了成功的响应,数据也有可能丢失。 - 自定义写入节点策略:可以给一些节点打上标签,然后要求写入的时候一定要写入带有这些标签的节点,实践中用的较少
j参数
控制数据有没有被写到磁盘上,对于j来说它的取值就是true或false
wtimeout参数
写入的超时时间,只会在w>1的时候生效。
在超时之后MongoDB就直接返回一个错误,但是这种情况下,MongoDB可能还是写入数据成功了
面试准备
- 负责的业务或公司有没有使用MongoDB,主要用来做什么
- 为什么要用MongoDB,用MySQL可以吗
- 用MongoDB的时候,文档支持分片吗?如果支持的话,按什么来分片的?
- 业务有多少数据量,并发有多高?
- MongoDB怎么部署的,主从节点有多少?有没有多数据中心的部署方案?
- MongoDB的写入语义,即w和j这两个参数的取值
面试话题引导
- Kafka的acks机制,可以引申到MongoDB的写入语义上
- 其他中间件的对等结构,或主从结构,可以引导到MongoDB的分片和主从机制上
- Kafka的元数据,可以结合MongoDB的元数据一起回答
- MongoDB数据不丢失的问题,可以结合写入语义来回答,参考Kafka分析的思路。
在整个MongoDB的面试过程中,注意和不同的中间件进行对比,凸显在这方面的积累