
摘要
检索问答(ReQA)任务采用检索增强框架,该框架由检索器和生成器组成。
生成器根据检索器检索到的文档制定答案。将大型语言模型(llm)作为生成器是有益的,因为它们具有先进的QA功能,但它们通常太大而无法根据预算限制进行微调,而且其中一些只能通过api访问。为了解决这个问题并进一步提高ReQA性能,我们提出了一个可训练的可插拔的奖励驱动上下文适配器(PRCA),将生成器作为一个黑盒。PRCA以可插拔的方式定位在检索器和生成器之间,通过最大化强化学习阶段的奖励,以token自回归策略操作来精炼检索到的信息。我们的实验验证了PRCA在三个数据集上提高ReQA性能的有效性,将黑盒llm与现有框架相匹配,提高了20%,显示了其在llm时代的巨大潜力。
1 引言
检索问答(ReQA)任务包括利用相关的上下文文档生成给定问题的适当答案。为此,采用检索增强(Chen et al ., 2017;Pan等人,2019;Izacard and Grave, 2021),由两个关键部分组成:一个检索器和一个生成器。检索器的作用是从大型语料库中检索相关文档以响应问题,而生成器则使用此上下文信息来制定准确的答案。这样的系统缓解了幻觉的问题(Shuster et al, 2021),从而提高了输出的整体准确性。
大型语言模型(llm)的最新进展,如生成式预训练transformer (GPT)系列(Brown等人,2020;欧阳等,2022;OpenAI, 2023年)已经展示了非凡的潜力,特别是在QA任务领域的零样本和少样本能力。由于这些功能,llm是检索增强框架中作为生成器的绝佳选择。然而,由于llm的参数非常大,在有限的计算预算内对它们进行微调变得非常困难。此外,某些llm,如GPT-4 (OpenAI, 2023)是闭源的,因此无法对它们进行微调。为了在特定数据集上获得最佳结果,需要微调检索增强模型(Guu et al, 2020;Lewis等,2020b;An et al, 2021)。以前将llm集成到检索增强框架中的尝试有过成功的例子,但是也遇到了一些挑战。(Shi et al ., 2023)在计算损失函数时使用了llm最后一层的logits,而某些通过api提供服务的功能强大的llm可能无法使用这些logits。(Ma et al ., 2023)涉及频繁调用昂贵的llm,忽略了输入令牌长度对系统准确性和有效性的影响。
为了克服这些障碍,我们提出了一个可训练的可插拔的奖励驱动上下文适配器(PRCA),它使人们能够在特定数据集的检索增强框架下对适配器进行微调,而不是llm,并实现更高的性能。此外,PRCA通过强化学习从生成器中提取由奖励引导的检索文档信息。通过PRCA对检索信息进行提炼,减少了输入到生成器的文本长度,构建了高质量的上下文,减轻了答案生成过程中的幻觉问题。如图1所示,PRCA被放置在检索器和生成器之间,形成了一个基于PRCA的范例,其中生成器和检索器都保持冻结状态。
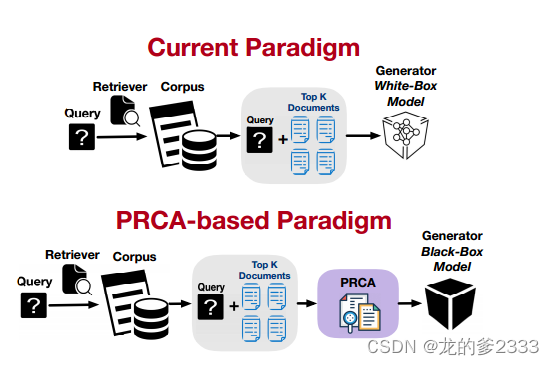
图1:两种信息检索和生成范例的比较。上面的部分展示了传统方法,其中查询由检索器处理,检索器扫描语料库以获取Top-K文档,然后将其提供给白盒生成器。下一节介绍了我们提出的PRCA方法,该方法在将提取的Top-K文档馈送给黑箱生成器之前,对其进行处理,以获得更好的域内任务性能
总的来说,引入基于PRCA的范例带来以下好处:
- 通过使用PRCA, llm可以被视为集成到检索增强框架中的黑盒,从而消除了对资源密集型微调的需要和对封闭性质模型的限制。
- 健壮性PRCA作为可插拔适配器,与各种检索器和生成器兼容,因为基于PRCA的范式使生成器和检索器保持冻结状态。
- 基于PRCA的范式通过减少输入到生成器中的文本长度来保证框架的效率,并能适应不同的检索语料库。
2 相关工作
2.1 LLM作为黑盒模型的潜力
LLM在下游QA任务中表现出了卓越的能力,即使在训练数据有限或没有训练数据的情况下也是如此(Wei et al, 2022)。这种涌现能力使它们能够有效地处理此类任务,使它们成为推理中黑箱模型的潜在候选对象。此外,这些模型的非开源性质和大参数尺寸进一步导致它们倾向于被视为黑盒。
一方面,像GPT-4 (OpenAI, 2023)和PaLM (Scao et al, 2023)这样的LLM在QA任务中展示了令人印象深刻的性能。然而,它们的闭源特性限制了对这些模型的访问,使得基于api的利用成为唯一可行的选择,因此将它们归类为黑盒模型。
另一方面,以Bloom (Scao et al ., 2022)和GLM130B (Zeng et al ., 2023)等模型为例的LLM训练需要大量的算力。具体来说,训练Bloom花了3.5个月的时间,使用了384个NVIDIA A100 80GB gpu。同样,GLM-130B需要在96个DGX-A100 GPU服务器集群上进行为期两个月的培训。这些资源需求使得大多数研究人员部署这些模型极具挑战性。LLM的发展速度也非常快。例如,从LLaMA(Touvron等人,2023)到Alpaca(Taori等人,2023),再到现在的Vicuna(Peng等人,2023),迭代在一个月内完成。很明显,训练模型的速度落后于模型迭代的速度。因此,为下游任务上的任何序列到序列LLM调优小型适配器可能是一种更简单、更有效的方法。
2.2 检索增强框架
为了提高ReQA任务的性能,各种检索增强思想被逐步发展和应用。
在研究的初始阶段,使用独立的基于统计相似度的检索器,如TF-IDF (Sparck Jones, 1972)和BM25 (Robertson and Zaragoza, 2009)作为基本检索引擎。它们帮助从语料库中提取最相关的文档用于QA任务(Chen等人,2017;伊扎卡德和格雷夫,2021)。
随后引入了向量化的概念,其中问题和文档都被表示为向量,向量相似性成为检索的关键参数。这种范式转变是由DPR所体现的密集检索等方法主导的(Karpukhin et al, 2020)。基于对比学习的模型,如SimCSE (Gao等人,2021)和Contriver (Izacard等人,2022a),以及句子级元数据模型,如Sentence-BERT(Reimers和Gurevych, 2019),代表了这个时代。这些方法可以看作是预先训练的检索器,提高了ReQA任务的有效性。
进一步的开发导致了ReQA框架内检索和生成组件的融合。这是在REALM(Guu等人,2020)和RAG(Lewis等人,2020b)等系统中实现的,在这些系统中,检索器与生成器共同训练,从而进一步提高ReQA任务的性能。
最近,已经引入了Atlas(Izacard等人,2022b)和RETRO(Borgeud等人,2022)等先进方法,这些方法可以用更少的参数实现与Palm(Chowdhery等人,2022年)和GPT3(Brown等人,2020年)等大型模型相当的性能。
3 方法
3.1 PRCA的两阶段训练
PRCA被设计用于接收由给定查询和检索器检索到的Top-K相关文档组成的序列。PRCA的目的是提炼这些结果,为生成器呈现一个简洁且有效的上下文,同时保持检索器和生成器不变。这种基于PRCA的范式引入了两个挑战:检索的有效性不能直接评估,因为它严重依赖于生成器生成的响应,而且由于生成器是黑盒的,通过反向传播学习生成器输出与输入序列之间的映射关系受到阻碍。为了解决这些问题,我们提出了一个两阶段的PRCA训练策略,如图2所示。在上下文阶段,采用监督学习来训练PRCA,鼓励它从输入文本中输出富含上下文的信息提取。在奖励驱动阶段,将生成器视为奖励模型。生成答案与真实答案之间的差异作为奖励信号,用于进一步训练PRCA。这个过程有效地优化了信息提炼,使其更有利于生成器准确回答问题。
3.2 上下文提取阶段
在上下文提取阶段,我们训练PRCA以提取文本信息。给定一个输入文本,PRCA生成一个输出序列
,代表从输入文本中提取的上下文。训练过程的目标是最小化
与真实上下文
之间的差异,损失函数如下所示:
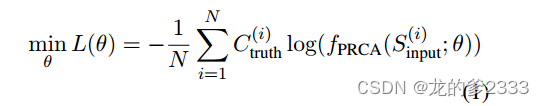
代表PRAC的参数。
在上下文提取阶段,从CNN Daily Mail数据集预训练的BART-Large模型初始化PRCA (Lewis et al, 2020a)。
3.3 奖励驱动阶段
在奖励驱动阶段,目标是使前一阶段提取的上下文与下游生成器对齐,确保PRCA提炼的文本有效地指导生成器的回答。鉴于生成器的黑盒特性,直接更新PRCA是不可行的。因此,我们采用强化学习来优化PRCA的参数。具体来说,生成器提供奖励来指导PRCA参数的更新,旨在提高答案质量。奖励基于生成答案
与真实答案
之间的ROUGE-L分数。同时,PRCA保留从长文本中提取信息的能力至关重要,这是在上下文提取阶段学到的。我们的目标有两方面:最大化生成器的奖励,并保持PRCA在上下文提取训练后更新参数与原始参数之间的相似性。为了适应操纵序列令牌的策略动作的奖励驱动训练,策略优化,特别是通过近端策略优化(Proximal Policy Optimization, PPO)(Schulman等,2017;Stiennon等,2020),是首选方法。然而,当使用黑盒生成器作为奖励模型时,我们发现了使用PPO的某些局限性。
在(2)中,我们展示了PPO的目标函数J()。这个函数旨在优化优势值,该值来源于广义优势估计(Generalized Advantage Estimation, GAE)(Schulman等,2016)。GAE利用
和
作为折扣因子,根据时间差分
调整估计的优势,如(3)所示。在这里,
(() **·** ,((), 1- , 1 + ) **·** )捕获了期望的优势。剪辑函数通过限制策略更新步骤来防止过度的策略更新,确保学习过程的稳定性。
(V(
) -
)^2是一个关于V(
)和
的平方误差项。这个项旨在最小化预测值和实际值之间的差异,确保准确的价值预测。然而,批评网络V通常被初始化为与奖励模型具有相同的参数(Yao等,2023;Fazzie等,2023),这在奖励模型为黑盒时是不适用的。此外,供应商的API通常有有限的返回参数数量,这可能导致计算
变得不可能。
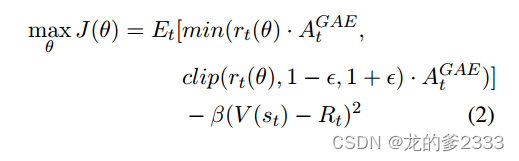
其中(
) =
表示的是更新后的策略
与原策略
之比;
代表的是行动(下一个token);
表示的是状态(前面token的序列);
表示的是裁剪参数;
是一个批评网络;
是状态
的预测值;
是一个加权误差平方项的系数;
表示的是
时刻的预期收益是多少。

其中;
和
分别作为贴现参数和GAE参数。
为了解决这个问题,我们引入了一种估算的策略。在PRCA中,当生成令牌〈EOS〉时,我们可以通过将生成的答案与基本事实进行比较来获得奖励REOS。我们认为它是在生成的令牌的每个时间步
上获得的奖励
的累积。对于
,它作为
中的目标来训练批评家网络
进行拟合,表示当前行为的平均回报,从而评估当前策略的优势。对于每个token,生成的概率越大,当前策略认为该代币越重要,因此我们认为其对总奖励的贡献越大。因此,我们将生成每个令牌的概率作为
的权值,
的表示为:
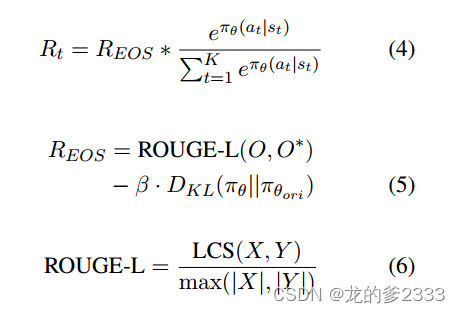
其中是在一个生成的上下文中标记的数量,
表示序列X和序列Y之间的最长公共子序列的长度,而|X|和|Y |分别表示序列X和Y的长度。
当将黑盒生成器解释为奖励模型时,此方法减轻了与计算Rt相关的挑战。它提供的一个重要优势是,对于每个上下文生成,只需要调用一次奖励模型。与为每个token计算使用奖励模型的原始PPO相比,我们的方法将奖励模型的使用减少到,这是经济有效的,特别是在使用LLMs作为生成器时。
4 实验设置
4.1 数据集
我们在三个QA数据集上进行了实验:SQuAD (Rajpurkar等人,2016)、HotpotQA (Yang等人,2018)和TopiOCQA (Adlakha等人,2022)。三个数据集的复杂性依次增加:SQuAD是一个以一对一的方式匹配问题、文档和答案的数据集。HotpotQA是一个多跳QA数据集,需要从多个文档中合成正确答案。TopiOCQA是一个具有主题切换功能的会话式QA数据集。
为了使这些数据集与我们的ReQA任务一致,我们将所有三个数据集重构为(Q, C, A)的形式,其中Q和A表示问题和答案对,C分别表示由数据集中所有文档组成的语料库。在表1中,我们给出了每个数据集在PRCA训练和测试阶段使用的问题和答案的数量。此外,我们还提供了每个语料库中包含的文档数量。
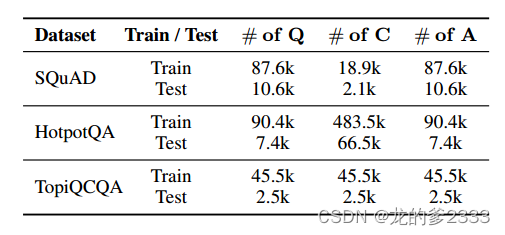
表1:跨三个基准数据集用于训练和测试的数据量概述。
4.2 基线检索器和生成器
我们对五种不同的检索器进行了实验,分别是BM25 (Robertson and Zaragoza, 2009)、SentenceBert (Reimers and Gurevych, 2019)、DPR (Karpukhin等人,2020)、SimCSE (Gao等人,2021)和Contriver (Izacard等人,2022a)。我们还使用了T5-large (rafael等人,2020)、Phoenix7B (Chen等人,2023)、Vicuna-7B (Peng等人,2023)、ChatGLM (Du等人,2022)和GPT-3.5 五个生成器来评估PRCA的有效性。请注意,在整个实验过程中,检索器和生成器都保持冻结状态。
通过将每个检索器与每个生成器配对,我们在三个数据集上建立了总共七十五个基线配置。对于每个配置,我们评估了应用PRCA前后的性能,并以此差异作为我们提出方法有效性的指标。
4.3 GPT-4评估
值得注意的是,我们使用GPT-4而不是传统指标如F1和BLEU进行评估,因为这些指标经常误判语义上相似的句子。LLMs通常为答案输出更长的文本解释,即使正确的答案可能只有一两个词。尽管试图限制答案长度,但结果并不理想。然后,我们使用人工方法和GPT-4对预测进行评估,与黄金答案进行对比。GPT-4的评估显示,在三个数据集上的正确率分别为96%,93%和92%,这证明了其可靠性和与人类判断的一致性。特别是,GPT-4评估的模板如下所示。最后,回答"Yes"的准确率被计为评估指标。

4.4 超参数配置
为了在我们的PRCA训练中达到最佳结果,精心选择超参数是关键。我们在实验中使用的配置设置如表2所述。
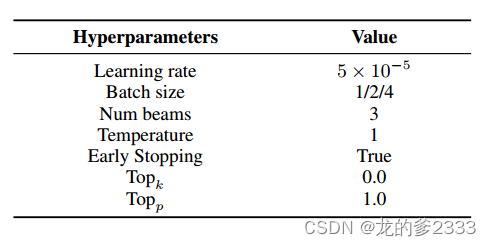
表2:实验中使用的超参数设置
5 实验结果和分析
5.1 整体性能
如表3所示,在七十五种配置中,我们的实验结果建议,在七十一种配置中包含PRCA可以提高性能。平均而言,我们观察到在SQuAD、HotpotQA和TopiOCQA数据集上分别有3%、6%和9%的提升。这证明了PRCA具有鲁棒性,并可以增强不同检索器和生成器组合在ReQA任务上的性能。如图3所示,PRCA对生成器的改进在所有三个数据集上都是显著的。特别是在TopiOCQA数据集上,对于五个不同检索器,生成器Vicuna的平均提升达到了14%。值得注意的是,当SimSCE作为检索器时,PRCA提供的提升是20%。
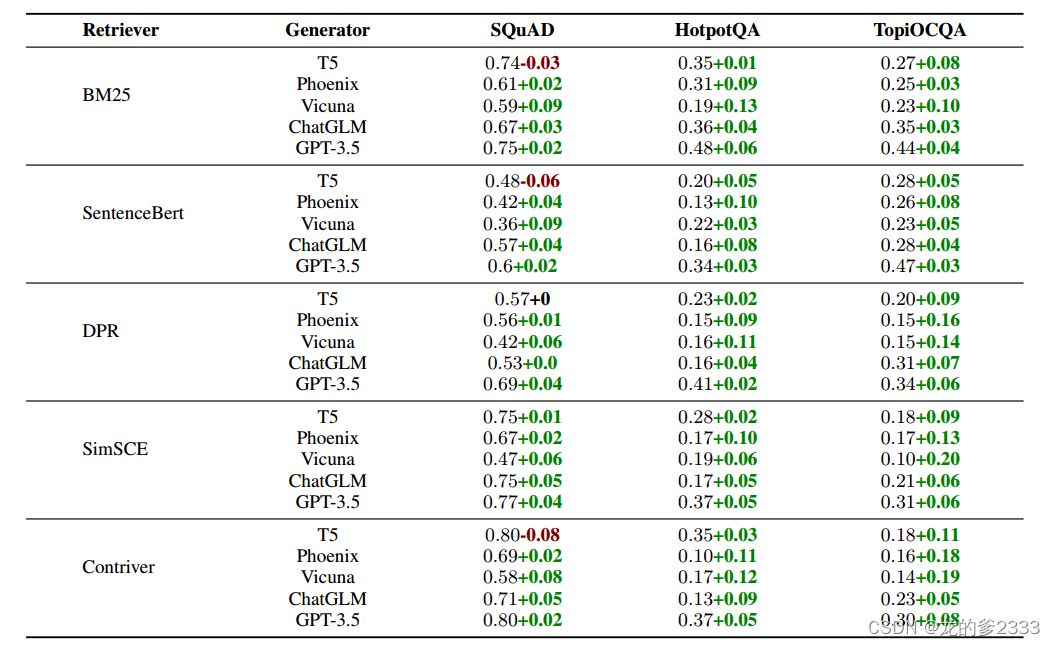
表3:在有无PRCA集成的不同检索器和生成器组合下的性能比较结果。结果基于使用三个基准数据集:SQuAD、HotpotQA和TopiOCQA的评估,并专注于选择Top-5最相关的文档
"+" 表示在引入 PRCA 后性能指标的改善。颜色编码提供了一个视觉表示效果:绿色表示性能的正向提升,而红色表示性能的下降
在图3中,我们注意到PRCA对生成器性能的改善在三个数据集上是逐渐增加的,而没有PRCA时,生成器在三个数据集上的原始性能是逐渐下降的,这与数据集的复杂性直接相关。这是因为当面对更复杂的问题时,例如HotpotQA中的多跳问题以及在TopiOCQA中多轮QA的话题转换,PRCA能够保留并整合从检索到的文档中对生成器有益的关键信息。PRCA的这一特性缓解了生成器在处理长文本时遇到的问题,例如无法正确回答问题或产生幻觉,从而提升了性能。
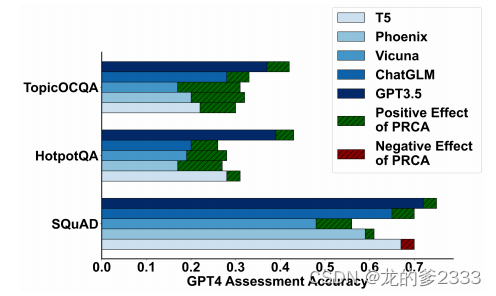
图3:不同生成器(T5、Phoenix、Vicuna、ChatGLM和GPT-3.5)在三个基准数据集(SQuAD、HotpotQA和TopicOCQA)上的性能比较。水平轴代表GPT-4评估的准确率。条形图显示了每个生成器的性能水平,绿色和红色箭头分别表示由于PRCA集成导致的性能提升或降低效果
然而,引入PRCA对生成器T5在SQuAD数据集上的性能产生了负面影响。这是因为SQuAD数据集相对简单,答案通常直接对应于文本中的一个短语。作为一个编码器-解码器架构模型,T5倾向于直接提取答案,而不是基于上下文进行深入推断。因此,在没有PRCA从检索到的文档中进行信息提炼的情况下,T5表现良好,因为其特性非常适合处理这个数据集,能够直接从上下文中提取答案。但在PRCA的影响下,文本的结构可能被改变,T5的直接答案提取可能导致一些错误,从而降低性能。虽然在少数配置中,PRCA的特性可能产生负面影响,但对于绝大多数配置,我们的实验验证了在基于PRCA的范式下,PRCA可以有效提升ReQA任务中的性能,展现了其鲁棒性。
5.2 PRCA的效率
PRCA代表了一种有效的方法,用于提升ReQA任务的性能,而不会显著增加计算需求。其效率体现在通过优化参数来实现优越的结果,以及简化输入文本,从而帮助生成器处理复杂文本。
参数效率图4展示了在PRCA帮助下性能提升最大的生成器与没有PRCA的GPT-3.5模型在3个数据集上的比较分析。PRCA拥有大约40亿个参数,平均而言,通过PRCA获得最显著性能提升的生成器大约有70亿个参数,而GPT-3.5大约有1.75万亿个参数。如图4所示,参数的少量增加使得这些生成器的性能分别提升了12.0%,27.1%和64.5%。因此,PRCA有望成为一种高效的提升ReQA任务性能的方法,同时保持计算资源消耗的可接受性。在推理过程中,完全训练好的PRCA将只执行标准的正向传播,因此对推理延迟的影响有限。我们在表4中报告了对SQUAD的推理延迟测试。这种低延迟确保了系统在集成PRCA后能够保持流程的顺畅,而不会出现显著的延迟,从而突显了PRCA在提升系统性能方面的高效性。
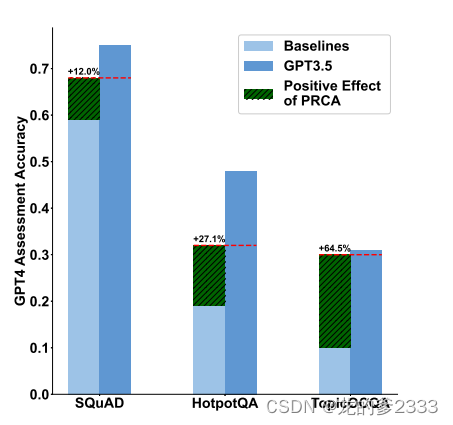
图4:PRCAenhanced基线模型和GPT-3.5在SQuAD、HotpotQA和TopicOCQA中的性能比较。浅蓝色和深蓝色条表示基线和GPT-3.5的表现,而绿色条表示PRCA的改善

表4:PRCA推理速度测试结果
输入简化如图5所示,我们分析了在奖励驱动阶段,对于HotpotQA数据集中的一个问题-答案对,在有无PRCA的情况下,奖励与令牌数量的关系。有无PRCA的奖励轨迹之间存在明显的差异。两条奖励曲线都随着令牌数量的增加而上升,但PRCA的上升梯度明显更陡峭。这意味着当PRCA起作用时,生成器能够在显著减少的令牌数量下达到最佳性能。在PRCA的影响下,生成器能够使用大约四分之一的令牌数量得出正确答案。这表明PRCA可以在确保生成答案质量的同时,提炼检索到的文本。这个简化过程过滤掉了冗余信息,从而促使生成器使用更精简的上下文更准确地提取答案。此外,令牌数量的减少使得生成器能够更快地处理文本并更迅速地产生输出。总体而言,PRCA在信息提炼方面的效率极大地增强了生成器处理和解释复杂文本的能力。
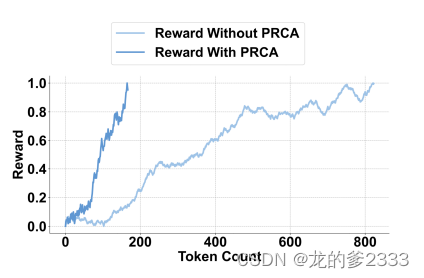
图5:HotpotQA数据集中QA对在奖励驱动阶段增加令牌计数的奖励轨迹描述。不同的线条表示在使用和不使用PRCA的情况下获得的奖励,强调了PRCA提取更简洁和高质量文本的能力。
5.3 Top-K选择的影响
我们进行了参数敏感性实验,以观察当检索到的相关文档数量变化时PRCA的性能。图6中展示的结果表明,在SQuAD数据集上,无论是否使用PRCA,随着检索到的文档数量的增加,性能都会提升,而添加PRCA在不同的Top-K值下始终提供积极的效果。由于该数据集相对简单,正确答案被包含在检索到的文档中的可能性增加,因此两种趋势都表现出上升的轨迹。
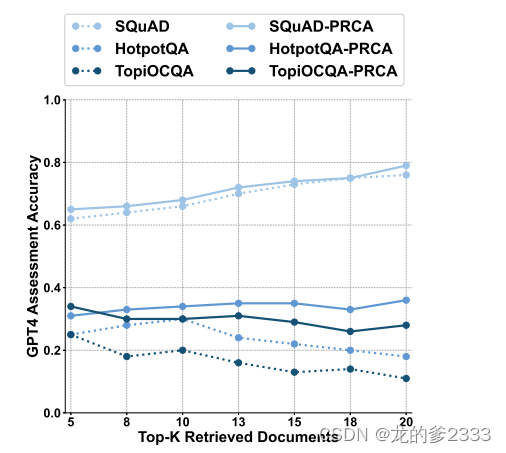
图6:使用和不使用PRCA时检索文档数量不同的性能比较
相比之下,在HotpotQA和TopiOCQA数据集上,如果没有实施PRCA,当添加更多文档时,性能会出现明显的下降。这种下降归因于模型生成准确答案的能力下降,因为干扰信息的增加和幻觉问题的出现。然而,通过实施PRCA,这些不利影响被系统地缓解,这不仅减少了幻觉的发生,还增强了生成器在干扰中处理复杂查询的能力。
总的来说,无论Top-K值如何变化,PRCA在所有三个数据集上都展示了积极的效果,从而证明了PRCA无论检索到的文档数量多少都具有普遍适用性。
5.4 案例分析
当回答梅森质数问题形式时,检索到的文本包含两个不同的信息来源。一个直接指定形式为2p-1,准确地反映了梅森质数的本质。另一个来源错误地将"阶乘质数"作为答案。没有PRCA的干预,这种误导会使生成器误入歧途,导致错误的答案"阶乘质数"。然而,当启用PRCA时,它会筛选信息,优先考虑准确的内容。这种精炼的上下文提取引导生成器朝向正确的答案。

5.5 PRCA消融实验
我们评估了PRCA对三个数据集的影响,使用的是第5.2节中显示最大改进的配置。评估是在有无奖励驱动阶段的情况下进行的,以观察PRCA对性能的影响。如图7所示,如果没有奖励驱动训练阶段,PRCA对整个配置的影响变得不利,因为PRCA只是简化文本,而没有辨别哪些信息对生成器回答问题有益,导致有用的文本被省略。相比之下,一旦训练过程纳入了奖励驱动阶段,上下文的质量就与奖励值直接对齐,帮助PRCA更有效地提炼相关信息。因此,奖励驱动阶段至关重要,它允许PRCA在简化文本的同时保留关键细节,增强了其整体效果。
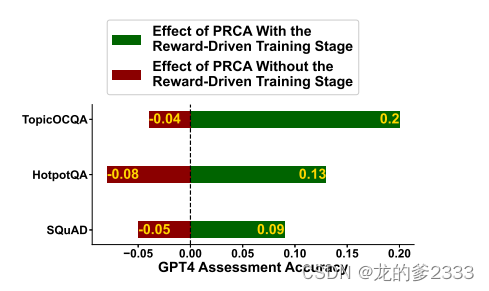
图7:展示奖励驱动阶段对PRCA绩效影响的插图
6 结论
总之,这项研究成功引入了一种基于PRCA的ReQA任务范式,解决了在检索增强框架中微调LLM固有的挑战,尤其是考虑到它们庞大的参数规模和封闭源代码特性。PRCA创新地通过生成器奖励提炼检索文档,导致ReQA任务性能显著提升。实验结果一致表明,当与各种检索器和生成器配对时,PRCA表现出稳健性和有效性,表明其有望作为ReQA任务的适配器广泛部署。
局限性
尽管PRCA在提高ReQA任务性能方面显示出了有效性,但它也存在局限性,包括对生成器的依赖、收敛问题以及与检索器的有限集成。在强化学习训练期间,奖励来自于生成器,这要求PRCA与不同的生成器一起重新训练,这可能会耗时。PRCA也可能在单个训练会话中难以收敛,这影响了其性能的稳定性和一致性。最后,PRCA作为可插拔适配器的运作限制了它与检索器一起训练的能力,这意味着如果检索质量不佳,PRCA的有效性可能会受到影响。