0. 引言
黄梅时节家家雨,青草池塘处处蛙。
有约不来过夜半,闲敲棋子落灯花。

当下,在移动设备上部署大型模型的趋势是愈演愈烈。Google推出了AI Core,使得Gemini Nano可以在智能手机上部署。此外,近期传闻苹果在iOS 18中整合了一个3B模型。端侧大模型的江湖,再次风起云涌。各种智能手机制造商也在探索在移动设备上部署大模型以增强数据隐私。然而,目前能在移动设备上运行的模型相对较小,且占用大量内存,这严重限制了大模型在端侧的应用场景。
1. 简介
近日,上海交大为大模型能够在智能手机上部署提出PowerInfer-2,该框架是专为智能手机设计且高度优化的推理框架。目前PowerInfer-2支持的最大模型是Mixtral 47B MoE模型,在inference的时候每秒可生成11.68个token,这比其他最先进的框架快22倍。即使是使用7B模型,PowerInfer-2只需将50%的FFN权重放置在手机上,在7B这个模型参数上,仍然是目前最快的推理框架!
视频号:AI科技爱科学
视频中的速度并不是PowerInfer-2的最快速度,因为渲染等过程会引入额外开销。
2. PowerInfer-2特点
PowerInfer-2具有以下特性:
-
异构计算:将粗粒度的矩阵计算分解为细粒度的"神经元族群"(neuron clusters),然后根据不同硬件组件的特性动态调整这些簇群的大小。
-
I/O-计算流水线:设计神经元缓存(Neuron caching)和细粒度的神经元族群级流水线技术以最大化神经元加载和计算之间的重叠。
更多技术细节可以参阅 PowerInfer-2论文:https://arxiv.org/abs/2406.06282。后续也会补充说明更加详细的技术细节,感兴趣的小伙伴敬请留意。
3. 评估
PowerInfer-2的一个显著优势是极度降低内存使用量。为了证明PowerInfer-2的有效性,实验过程对TurboSparse-Mixtral模型施加了各种内存约束,并比较了PowerInfer-2、LLM Flash和llama.cpp的解码速度。结果清楚地显示,PowerInfer-2显著性地、碾压性地优于其他框架。
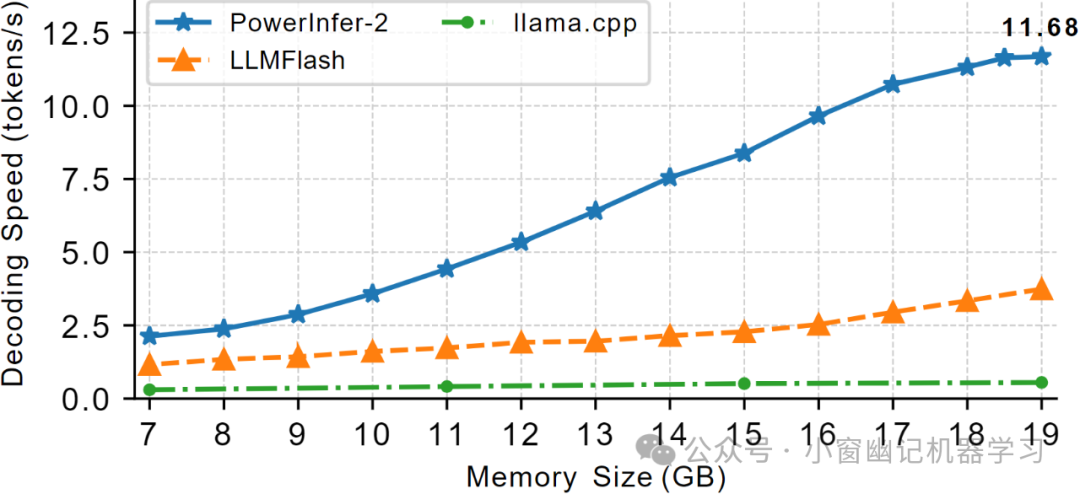
PowerInfer-2的另一个优势是推理速度的提高。无论是在full in-memory 场景还是offloading场景中,PowerInfer-2都明显优于其他框架,尤其是在智能手机上。对于7B LLM,PowerInfer-2可以节省近40%的内存使用量,并实现比llama.cpp和MLC-LLM更快推理速度。
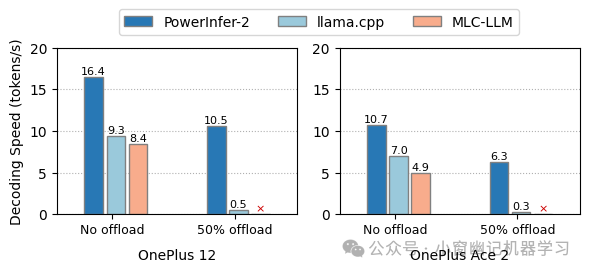
对于TurboSparse-Mistral-7B模型,设置不同的offloading,分别对比PowerInfer-2、llama.cpp和MLC-LLM的解码速度。"50% offloading"表示将FFN块的50%模型权重卸载到闪存存储器。"No offload"表示所有模型参数都驻留在内存中。红色的⨉标签表示由于不支持权重卸载而导致的执行失败。
4. 模型
PowerInfer-2是一个专为智能手机如何高速推理大型语言模型(LLM)而设计的框架,特别适用于模型大小超过设备内存容量的场景。PowerInfer-2的关键思路是通过将传统的矩阵计算分解为细粒度的神经元集群计算,利用智能手机中的异构计算、内存和I/O资源。具体而言,PowerInfer-2具备多态神经元引擎,能够根据LLM推理的不同阶段自适应采用不同的计算策略。此外,它引入了分段神经元缓存(neuron caching) 和细粒度神经元集群级流水线(fine-grained neuron-cluster-level pipelining) 技术,有效地减少I/O操作引起的开销。从PowerInfer-2的实测结果表明,它能够支持多种LLM模型在两款智能手机(OnePlus 12和Ace 2)上运行, 并在速度上比最先进的框架快29.2倍。值得注意的是,PowerInfer-2是第一个能够在智能手机上以每秒11.68个token的生成速度为TurboSparse-Mixtral-47B模型提供服务的系统。对于完全适应内存的模型,PowerInfer-2在保持与llama.cpp和MLC-LLM相当的推理速度的同时,内存使用量减少了约40%。
PowerInfer推出了两个新模型:TurboSparse-Mistral-7B和TurboSparse-Mixtral-47B。这些模型是Mistral和Mixtral的稀疏版本,不仅提高了模型性能,还具有更高的可预测稀疏性。值得注意的是,这2个模型的训练仅用150亿个token,成本不到10万美元。模型发布在https://huggingface.co/PowerInfer。更多技术细节请参阅TurboSparse论文:https://arxiv.org/abs/2406.05955。
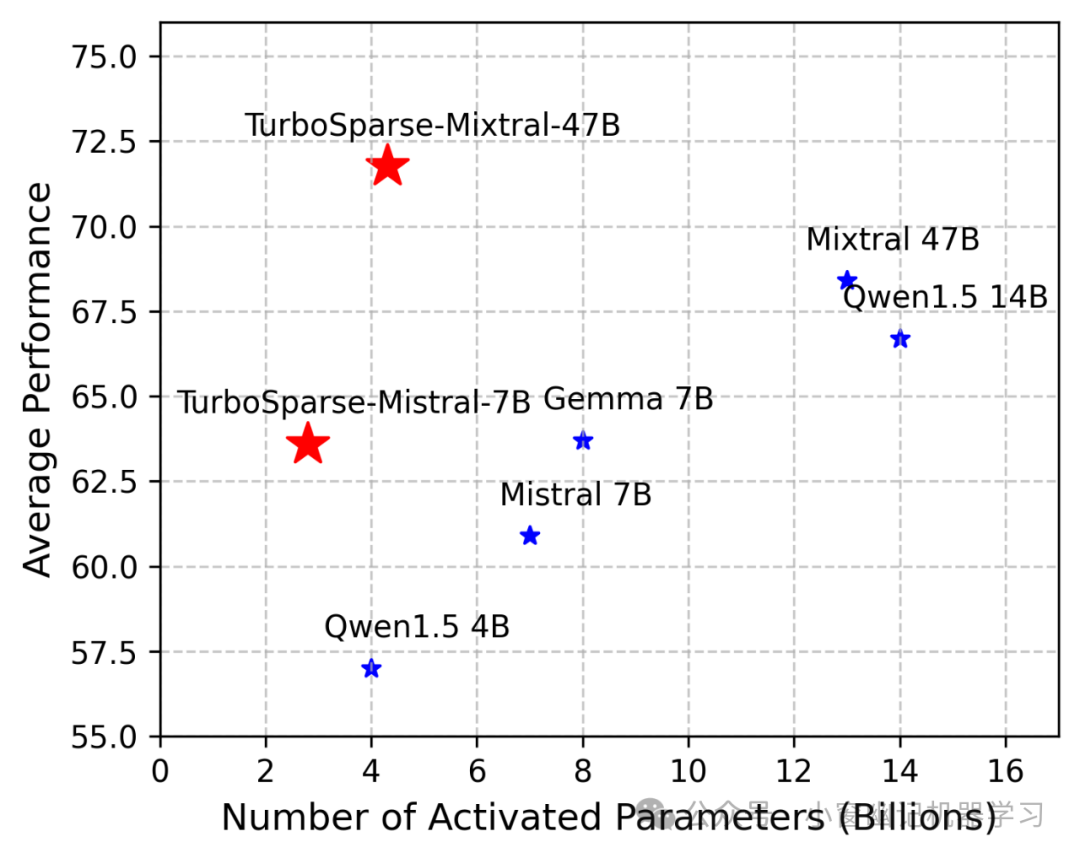
论文细节,留待后文补充,敬请期待。