谈到多模态大模型的应用场景,除了生成任务以外,应用最广泛的可能就是在图像和视频中进行目标检测。
目标检测要求从图像中识别并标注出所有感兴趣的对象,并给每个对象分配一个类别标签。典型的目标检测方法会生成边界框,标记出图像中每个目标的位置和类别,如人、车、动物等。
然而,今天我们要聊的并非仅限于对象类别的目标检测,而是一个更具挑战性的任务------Referring Expression Comprehension(REC),即指称表达理解。REC侧重于根据冗长且复杂的自然语言描述来精准定位并标记特定对象。
比如根据以下描述,标记图中的对象:
这款淡绿色的长方形橡皮上绘有一只熊,旁边用绿色写着"橡皮"字样。一层透明的带有图案的塑料覆盖物部分包裹着它。在图片的右下角,橡皮放在杂乱的桌子上,周围是各种各样的艺术材料和图纸。

REC更强调根据特定的自然语言描述定位和标记目标,适用于需要通过语言与视觉信息交互的场景,也是目前多模态大模型领域研究较少的任务。
现在常用的评估基准一般有三个:RefCOCO(2015年)、RefCOCO+(2016年)和RefCOCOg(2016年)。但是简单的描述与单一测试样本,对于很多强大的大模型来说 so easy,例如CogVLM 在RefCOCO基准上达到了92.44% 的准确率。
这些基准已经不足以有效评估现代多模态大模型理解多样语言输入并关联语言与视觉元素的细微能力。因此,港科大提出了多模态大模型时代评估REC的新基准------Ref-L4,规模更大,高度多样化,更长的指称表达并具有丰富的词汇量。在Ref-L4上对24种大模型进行了评估,普遍得分偏低,GPT-4V还不足10%,极具挑战性。
论文标题 :
Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
论文链接 :
https://arxiv.org/pdf/2406.16866
github链接 :
https://github.com/JierunChen/Ref-L4

现有基准存在较高的错误率
现在常用的评估基准一般有三个:RefCOCO(2015年)、RefCOCO+(2016年)和RefCOCOg(2016年):
-
在RefCOCO中,指称表达相当简洁,包含"女士"、"黄色"这样的单个词汇,以及"最左边的人"和"白衬衫"这样的简短描述。
-
RefCOCO+有意排除了RefCOCO中常见的位置介词,倾向于如"只有冰的塑料杯"和"屏幕上的男人"这样短而富含语义的表达。
-
RefCOCOg提供了更详细的标注,例如"带有盘子、披萨、饮料罐和玻璃杯的食物桌"和"带有两把木椅的红白格子桌"。
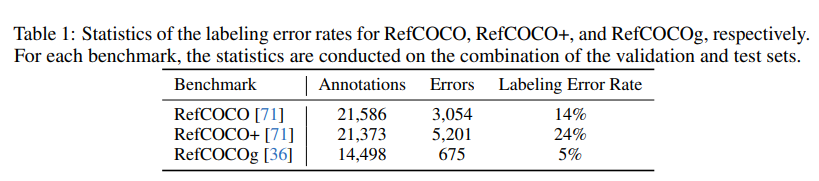
作者在手动评估了RefCOCO、RefCOCO+和RefCOCOg的验证集和测试集的标注错误率,发现这些基准普遍存在较高的错误率。
标注错误包括拼写错误、指称表达与目标实例的不匹配,以及不准确的边界框标注。

经过统计发现,RefCOCO、RefCOCO+和RefCOCOg的标注错误率分别为14%、24%和5%。
为此, 作者手动排除了问题实例。然后重新评估了四个能够处理REC任务的大型多模态模型------ONE-PEACE,OFA-L ,Qwen-VL以及CogVLM-Grounding
所有的模型在清理后的基准上的准确率有了显著提高,这表明基准测试中的噪声影响了模型的真实能力。
可以看到,这些基准对于大模型来说 so easy,准确率可以达到80+,最高达到了94+。因此作者提出了一个更具挑战的REC基准------Ref-L4。
全面的指称表达理解基准------Ref-L4
Ref-L4的优势
Ref-L4有四个显著特点:
-
大规模:Ref-L4 包含 9,735 张图片,18,653 个独特实例,总共有 45,341 个标注,远超 RefCOCO、RefCOCO+ 和 RefCOCOg。RefCOCOg 只有 3,900 张图片,7,596 个实例和 14,498 个标注。
-
高多样性:Ref-L4 包含 365 个独特类别。而 RefCOCO 系列来自 COCO 2014 数据集,仅涵盖 78 个类别。Ref-L4还覆盖了更广泛的实例规模,实例面积从 30 到 3,767 不等(以实例面积的平方根度量)。
-
详细的指代表达:Ref-L4 中每个指代表达都是对特定实例的详细描述,长度从 3 到 117 个词不等,平均长度为 24.2 个词。相比之下,RefCOCO、RefCOCO+ 和 RefCOCOg 的平均标注长度分别为 3.6、3.6 和 8.4 个词。
-
丰富的词汇量:由于指代表达的详细性,Ref-L4 拥有 22,813 个词汇,比 RefCOCO、RefCOCO+ 和 RefCOCOg 的词汇量大四到六倍。

Ref-L4构建
数据来源
Ref-L4基准数据集来源于两个部分:1) RefCOCO、RefCOCO+ 和 RefCOCOg 数据集的清理后的验证和测试集;2) 大规模目标检测数据集 Objects365 的测试集。Objects365 数据集提供了更广泛的类别、多样的实例尺寸、更高的图像分辨率和更复杂的场景。经过清洗与处理后,Ref-L4 基准数据集共包含 9,735 张图像和 18,653 个实例。
指称表达生成。
给定目标实例及其对应的图像,利用GPT-4V和人类的循环,生成精确和详细的指称表达,分成三个步骤,如下图所示:

-
使用GPT-4V对从原图中裁剪出来的实例与提示生成一个与上下文无关的描述,这一步只针对Objects365 数据集,因为RefCOCO的每个实例已经有简短的描述。
-
由于GPT-4V 更关注图像中用红圈标出的实例,因此将目标实例用红圈标出,让 GPT-4V 生成上下文相关的指代表达,指导 GPT-4V 描述各种特征,如颜色、大小、位置和上下文。此外,在提示中提供步骤1中生成的与上下文无关的描述,以减少幻觉问题,从而生成更准确的描述。
-
人工手动审核所有生成的指代表达,纠正错误。确保每个表达准确地描述实例,并且内容真实、无害。
基准扩展
为了评估 REC 模型对多样化输入的鲁棒性,作者还使用 GPT-4 与不同的提示生成了每个指称表达的重述版本,并同样进行了人工手动审核。
Ref-L4评估实验
作者对24个能够执行REC任务的代表性多模态大模型进行了评估。根据它们的输出类型将其分为两类:生成边界框的模型和生成分割掩码的模型。对于输出分割掩码的模型,将这些掩码转换为紧凑的边界框,以便评估。

在生成边界框的模型中,强大如GPT-4V的准确率不足10%,CogVLM-Grounding表现出最佳性能,而GlaMM在生成掩码的模型中处于领先地位。但仍然有很大的提升空间。
类别性能
另外,作者按照基准中的类别统计了不同类别下模型的性能,一共有365个类别标签,按它们的类别平均性能降序排列,如下图:

结果显示存在明显的训练偏见问题,这四个模型在某些常见类别上的表现都较差。
规模感知评估
为了评估模型处理不同规模实例的能力,将基准中的所有样本分为小、中和大三类。实例的大小定义为其面积的平方根,小实例是指小于 128 的,中实例的大小在 128 到 256 之间,大实例则超过256。

在输出边界框的模型中,CogVLM-Grounding 在小和中等实例上表现出色,而SPHINX-v2-1k 在大实例上取得了最佳性能。对于输出掩码的模型,GlaMM在三类大小中都优于其他模型。
多数据源评估
Ref-L4基准源于COCO和Objects365数据集。作者评估了模型在不同子集上的性能,这些子集包括:
-
COCO:来自COCO的数据子集。
-
O365-P1:Objects365中的子集,其类别在COCO中也存在。
-
O365-P2:Objects365中的子集,其类别在COCO中不存在。

"COCO"子集的准确性较高,因为大多数模型基于RefCOCO系列进行训练,对Objects365图像接触较少。"O365-P1"的准确性高于"O365-P2",因为"O365-P2"包含更多罕见的类别。
结论
本文指出了当前REC基准的局限性,如标注不准确和指称表达过于简短。为更好地评估多模态大模型在REC任务中的表现,提出了规模更大、描述更详细的REC新基准------Ref-L4,并使用多种评估协议对24个模型进行了评估。
相信Ref-L4能成为研究人员和开发者的宝贵资源,推动更强大和多用途REC模型的发展。

