文章目录
- 一、前言
- [二、Delta Lake](#二、Delta Lake)
- [三、Apache Hudi](#三、Apache Hudi)
- [四、Apache Iceberg](#四、Apache Iceberg)
- [五、Apache Paimon](#五、Apache Paimon)
- 六、对比
- 七、笔者观点
- 八、总结
- 九、参考资料
一、前言
在上一篇从数据仓库到数据湖(上):数据湖导论文章中,我们简单讲述了数据湖的起源、使用原因及其本质。本篇文章将着重介绍市面上热门的数据湖开源框架,并分享笔者对当前数据湖技术的理解和看法。
截至目前,在数据湖领域,Delta Lake 、Apache Iceberg 和 Apache Hudi 无疑是三大热门开源框架。此外,Apache Paimon 最初是 Flink 的子项目,后来独立发展成为一个独立的框架,可以说是后起之秀。
二、Delta Lake
由于 Apache Spark 在商业化上取得巨大成功,由其背后的商业公司 Databricks 推出的 Delta Lake 也显得格外亮眼。Delta Lake 是一个流批一体的数据湖存储层,支持更新、删除和合并操作。
主要特点:
- 由于出自 Databricks,Delta Lake 与 Spark 的所有数据写入方式完全兼容,包括基于 DataFrame 的批处理、流处理,以及 SQL 的 Insert、Insert Overwrite 等操作(开源版本暂不支持 SQL 写入,EMR 已做支持)。
- 在数据写入方面,Delta Lake 与 Spark 强绑定;在查询方面,开源 Delta Lake 目前支持 Spark 和 Presto,但处理 delta log 需要使用 Spark。
核心能力 :

三、Apache Hudi
Apache Hudi 是 Uber 公司开源的数据湖架构,用于管理存储在 HDFS 上的数据。其设计目标如其名所示,即 Hadoop Upserts Deletes and Incrementals。Hudi 提供了"COW vs MOR"两种数据模型,以适应不同的业务需求。此外,Hudi 还提供了丰富的插件生态,可以方便地与其他大数据组件集成。

核心能力 :

四、Apache Iceberg
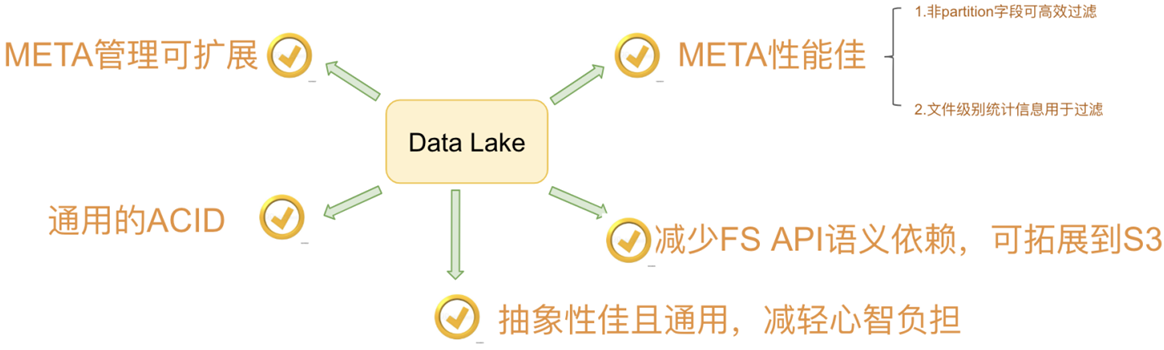
Apache Iceberg 是一种用于跟踪超大规模表的新格式,专门为对象存储(如 S3)而设计。尽管社区关注度暂时不如 Delta Lake,功能也不如 Hudi 丰富,但 Iceberg 是一个野心勃勃的项目,具有高度抽象和优雅的设计,为成为一个通用的数据湖方案奠定了良好基础。
Iceberg 为大数据带来了 SQL 表的可靠性和简单性,同时让 Spark、Trino、Flink、Presto 和 Hive 等引擎能够同时安全地使用相同的表。
五、Apache Paimon
Apache Paimon 是一种湖泊格式,可以使用 Flink 和 Spark 构建实时湖屋架构,用于流和批处理操作。Paimon 创新地结合了湖泊格式和 LSM(日志结构合并树)结构,将实时流更新引入湖泊架构。
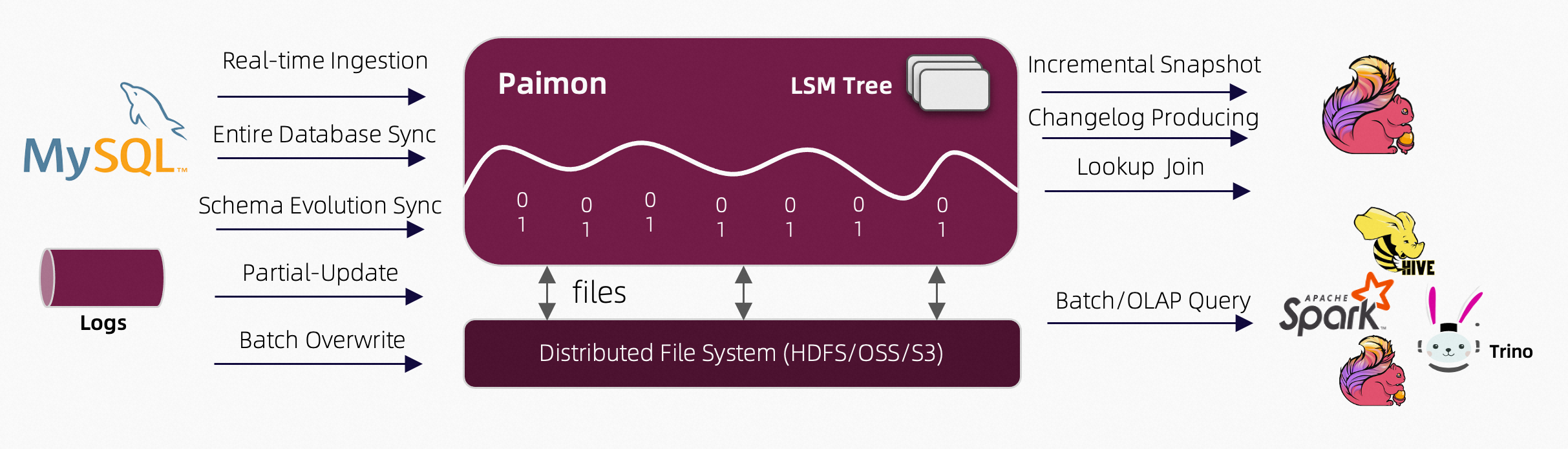
核心能力:
- 实时更新 :
- 主键表支持大规模更新,具有高性能,通常通过 Flink 流实现。
- 支持定义合并引擎,灵活更新记录。可重复保存最后一行,部分更新,或聚合记录。
- 支持定义变更日志生成器,在合并引擎的更新中产生正确和完整的变更日志,简化流分析。
- 大规模数据处理 :
- 附加表(无主键)提供大规模批处理和流处理能力,并自动进行小文件合并。
- 支持通过 z 顺序排序进行数据压缩,以优化文件布局,并使用 minmax 等索引提供快速查询。
- 数据湖功能 :
- 可伸缩元数据:支持存储 Petabyte 级别的大数据集和大量分区。
- 支持 ACID 事务、时间旅行和模式演化。
六、对比
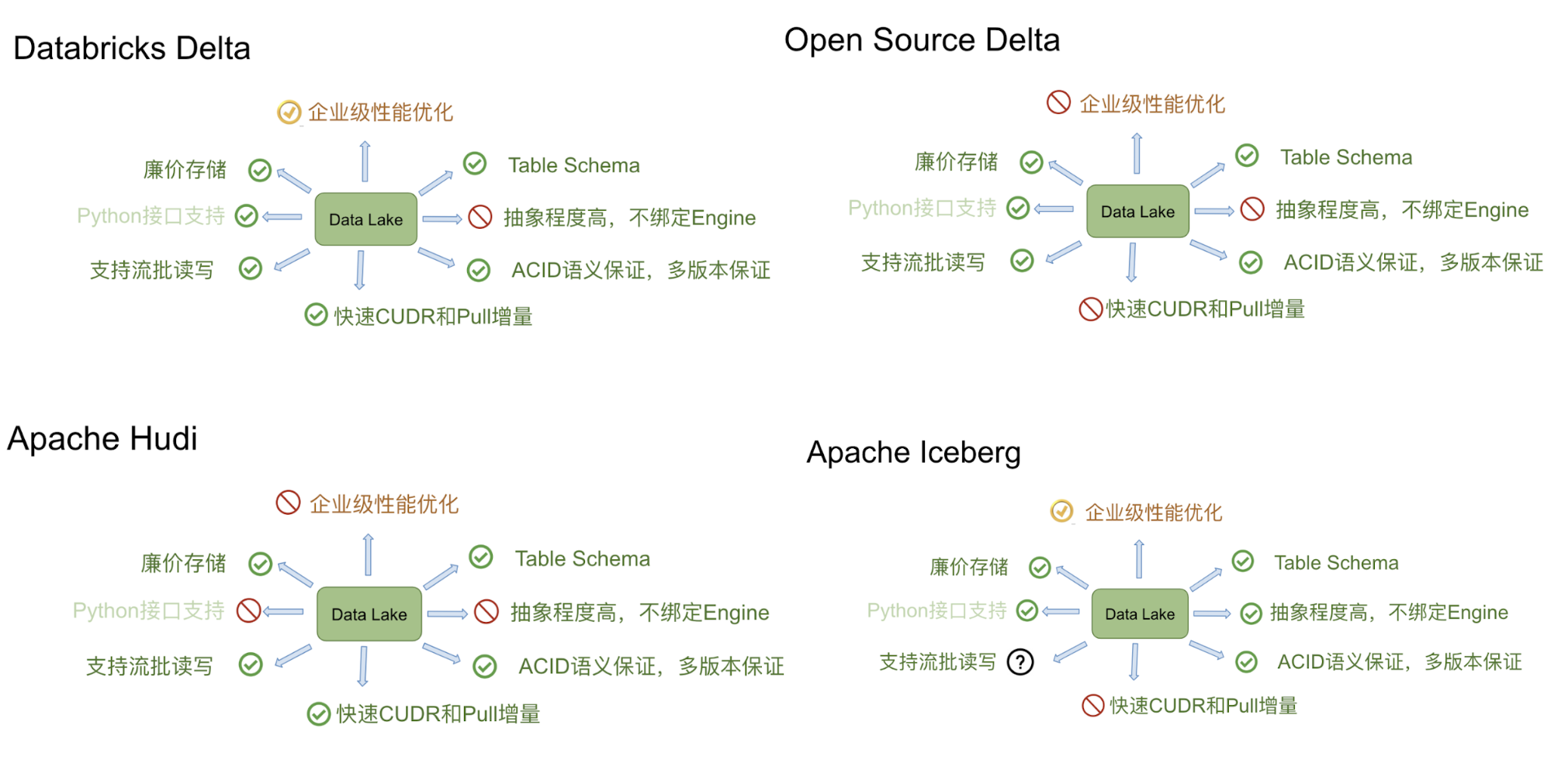
Delta、Iceberg、Hudi 和 Hive 四者的差异可以用建房子的比喻来说明。由于开源的 Delta 是 Databricks 闭源 Delta 的简化版本,主要提供 table format 的技术标准,而闭源版本的 Delta 基于这个标准实现了诸多优化,因此我们主要用闭源的 Delta 来做对比。
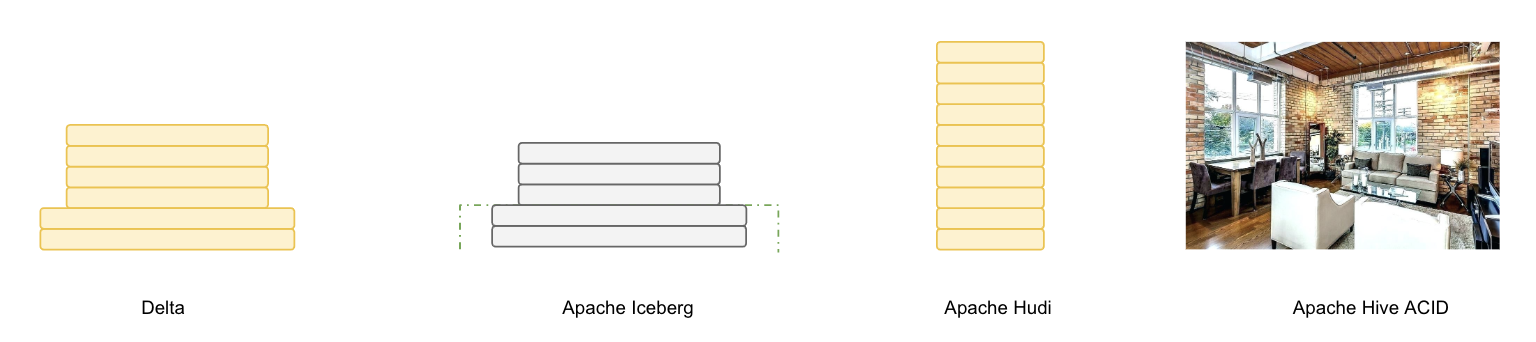
Delta 的房子基础相对结实,功能楼层也建得比较高,但这个房子可以说是 Databricks 的,本质上是为了更好地壮大 Spark 生态。在 Delta 上,其他计算引擎难以替代 Spark 的位置,尤其是在写入路径方面。Iceberg 的建筑基础非常扎实,扩展到新的计算引擎或文件系统都很方便,但目前功能楼层相对低一点,最缺的功能是 upsert 和 compaction。Iceberg 社区正在优先推动这两个功能的实现。Hudi 的情况不同,它的建筑基础设计不如 Iceberg 结实。例如,要接入 Flink 作为 Sink,需要从底向上重新设计房子,把接口抽象出来,并且考虑不影响其他功能。尽管如此,Hudi 的功能楼层还是比较完善的,提供的 upsert 和 compaction 功能直接命中用户的痛点。Hive 看起来像是一栋豪宅,绝大部分功能都有,但作为数据湖有点像靠着豪宅的一堵墙建房子,显得相对笨重。此外,正如 Netflix 的分析,细看这栋豪宅的墙面其实有一些问题。
七、笔者观点
虽然上述四款热门开源框架都宣称自己是数据湖解决方案,但根据我的了解和使用体验,这几款产品均不能完全满足数据湖所应具备的能力。
在前一篇文章中,笔者提到数据湖的本质是由数据存储架构 和数据处理工具 组成的解决方案。然而,这四款开源框架均沿用了传统数据库建表的思想,对数据有较强的 schema 约束,这与数据湖原始定义中的集成各类非结构化数据的要求相悖。
通过对这几款产品的使用和体验,我认为目前热门的数据湖技术均依赖于分布式文件系统的存储能力。它们的功能介于分布式文件系统与普通数据库之间,继承了文件系统中数据文件和目录对用户直观可见,以及数据库对数据使用表结构的管理、元数据管理和事务管理的优点,可以被称为一种数据管理中间件的开源产品。
这些产品的使用并不需要安装部署任何软件,也不需要启动额外的服务和端口,只需增加一个 jar 包,以插件的形式嵌入到计算引擎中,从而实现对分布式文件系统中数据的读写和各种数据管理功能。它们为计算引擎提供了一种数据组织和管理方式,但并非真正意义上的数据湖。
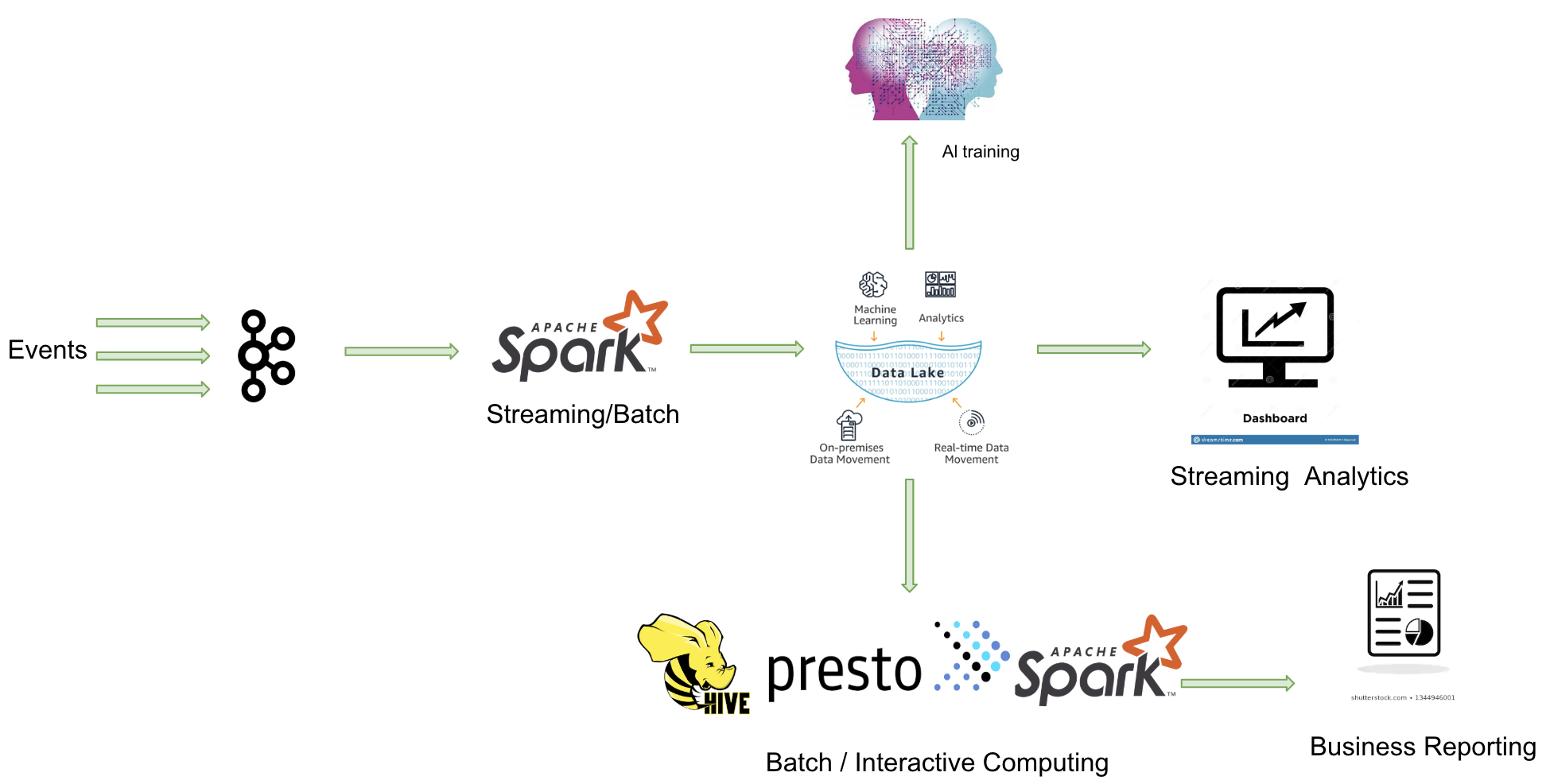
真正意义上的数据湖应该具备数据抽取 (ETL)、元数据管理、数据分析三大功能,如下图所示:

八、总结
数据湖就像其他新兴技术一样,在刚出现时往往受到广泛关注,成为热门话题。然而,很多新兴技术词汇大多是作为一个泛化的理论概念,但往往具有很大的吸引力,其实际应用还存在诸多挑战和局限性。
根据对当前几款热门开源框架(如Delta Lake、Apache Iceberg、Apache Hudi、Hive-ACID)的使用体验,这些产品均无法完全满足数据湖应具备的能力。数据湖的本质是由数据存储架构和数据处理工具组成的解决方案,但上述框架在设计上仍然沿用了传统数据库的schema约束,与数据湖集成各类非结构化数据的初衷相悖。
总体来说,数据湖等新兴技术在理论上提供了一个理想的解决方案,但在实际应用中,仍需不断发展和完善,以满足企业对数据存储、管理和分析的需求。这一过程需要时间和技术的积累,才能真正实现理论与实践的统一。