【图解大数据技术】流式计算:Spark Streaming、Flink
- [批处理 VS 流式计算](#批处理 VS 流式计算)
- [Spark Streaming](#Spark Streaming)
- Flink
-
- Flink简介
-
- Flink入门案例
- [Streaming Dataflow](#Streaming Dataflow)
- Flink架构
-
- Flink任务调度与执行
- [task slot 和 task](#task slot 和 task)
- EventTime、Windows、Watermarks
批处理 VS 流式计算
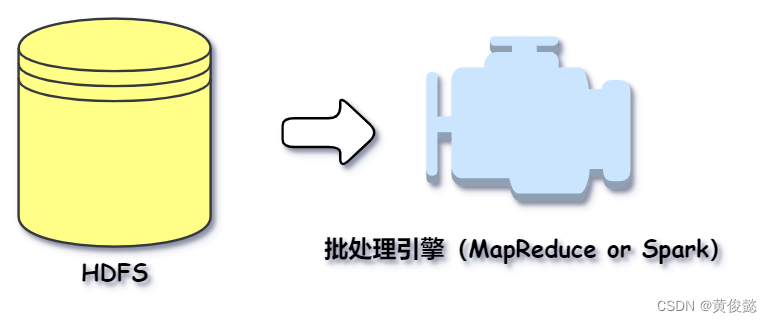
计算存储介质上的大规模数据,这类计算叫大数据批处理计算。数据是以批为单位进行计算,比如一天的访问日志、历史上所有的订单数据等。这些数据通常通过 HDFS 存储在磁盘上,使用 MapReduce 或者 Spark 这样的批处理大数据计算框架进行计算,一般完成一次计算需要花费几分钟到几小时的时间。
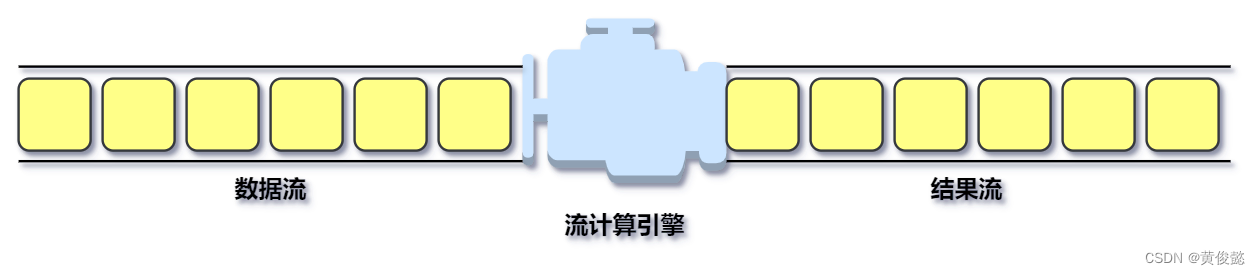
还有一种是针对实时产生的大规模数据进行即时计算处理,比如摄像头采集的实时视频数据、淘宝实时产生的订单数据等。实时处理最大的不同就是这类数据,是实时传输过来的针对这类大数据的实时处理系统也叫大数据流计算系统。
Spark Streaming

Spark是一个批处理大数据计算引擎,而 Spark Steaming 则利用了 Spark 的分片和快速计算的特性,把实时传输过来的数据按时间范围进行分段,转成一个个的小批,再交给 Spark 去处理。因此 Spark Streaming 的原理是流转批,Spark Streaming 不是真正意义上的实时计算框架,它是一个准实时的计算框架。
Flink
Flink简介
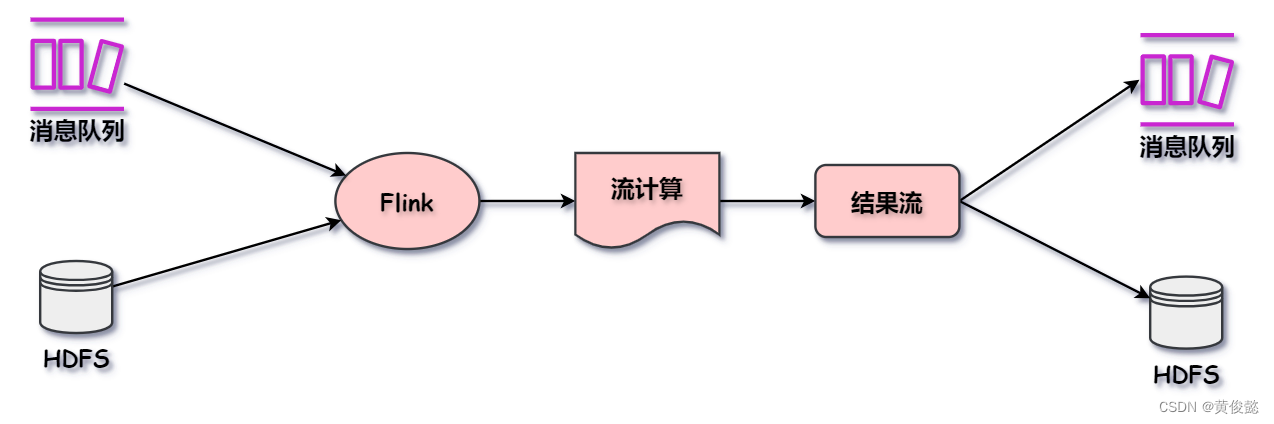
Flink 和 Spark Streaming 不一样,Flink 一开始设计就是为了做实时流式计算的。它可以监听消息队列获取数据流,也可以用于计算存储在 HDFS 等存储系统上的数据(Flink 把 这些静态数据当做数据流来进行处理)。
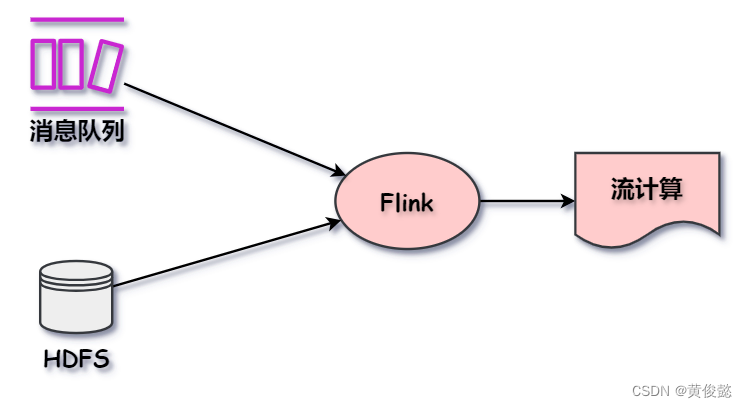
然后 Flink 计算后生成的结果流,也可以发送到其他存储系统。
Flink入门案例
java
public static void main(String[] args) throws Exception {
// 初始化一个流执行环境
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 利用这个执行环境构建数据流 DataStream(source操作)
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
// 执行各种数据转换操作(transformation)
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
// 打印结果(sink类型操作)
adults.print();
// 执行
env.execute();
}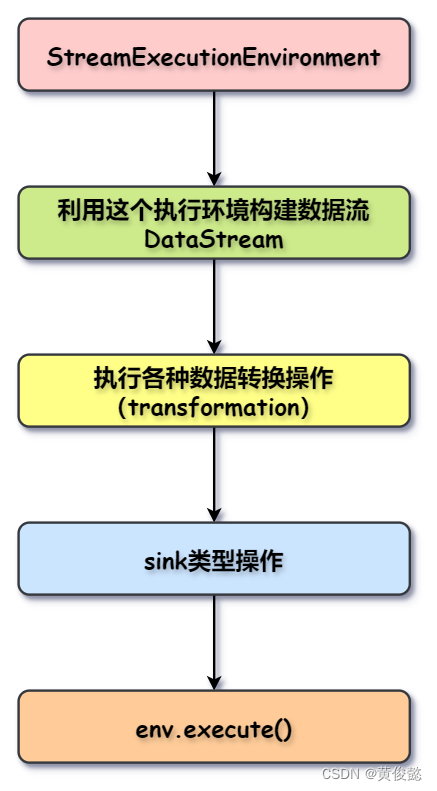
首先构建一个执行环境env,然后通过执行环境env构建数据流DataStream(这就是source操作),然对这个数据流进行各种转换操作(transformation),最后跟上一个sink类型操作(类似是Spark的action操作),然后调用env的execute()启动计算。
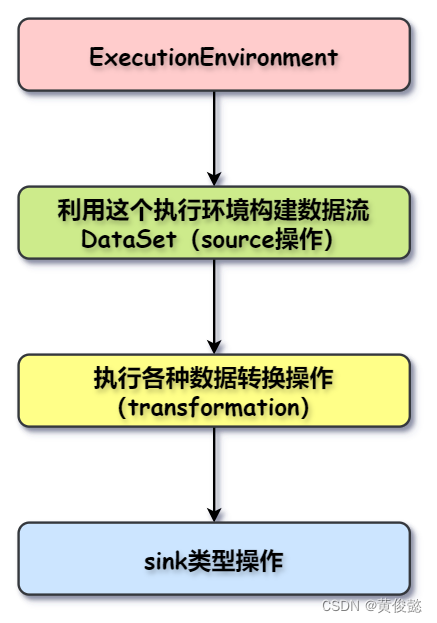
上面是流计算的例子,如果要进行批计算,则要构建ExecutionEnvironment类型的执行环境,然后使用ExecutionEnvironment执行环境构建一个DataSet。
Streaming Dataflow
Flink程序代码会被映射为Streaming Dataflow(类似于DAG)。一个Streaming Dataflow是由一组Stream(流)和Operator(算子)组成,并且始于一个或多个Source Operator,结束于一个或多个Sink Operator,中间有一个或多个Transformation Operator。
Source Operator:
java
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));Transformation Operator:
java
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});Sink Operator:
java
adults.print();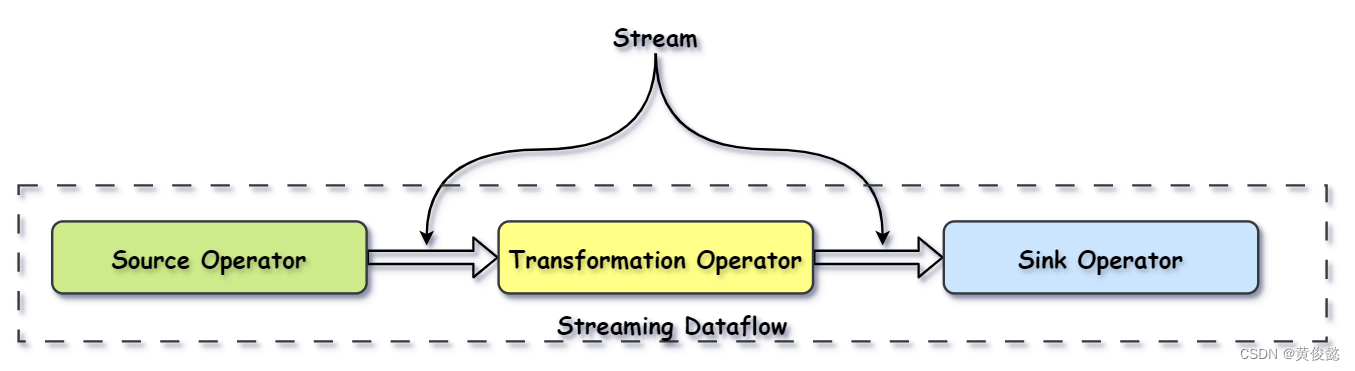
由于Flink是分布式并行的,因此在程序执行期间,一个Stream流会有多个Stream Partition(流分区),一个Operator也会有多个Operator Subtask(算子子任务)。
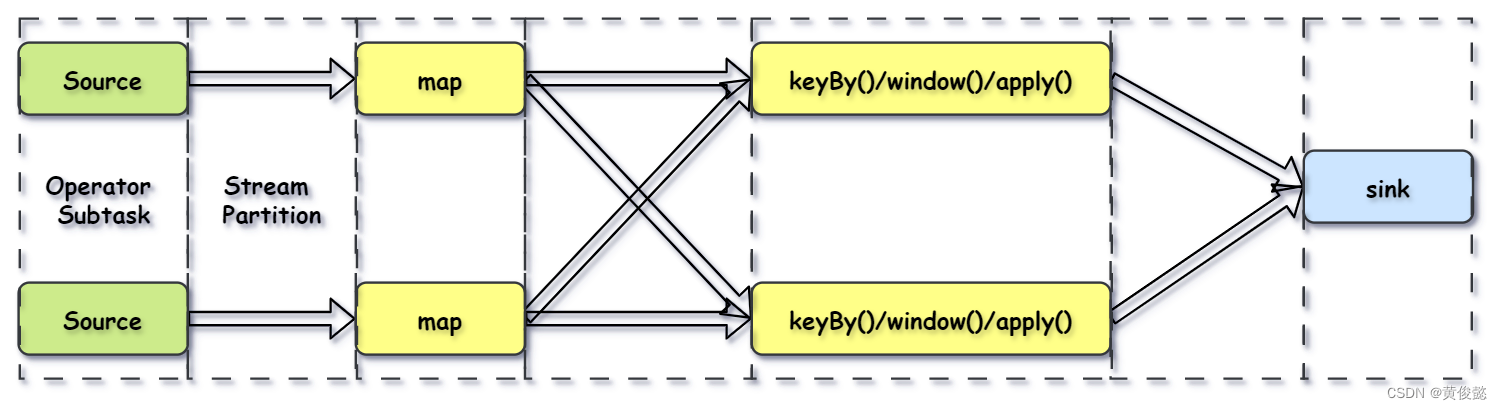
两个 operator 之间传递的时候有两种模式:
- One to One 模式:像Source到map这种传递模式,不会改变数据的分区特性。
- Redistributing (重新分配)模式:像map到keyBy这种传递模式,会根据key的hashcode进行重写分区,改变分区特性的。
Flink还会进行优化,将紧密度高的算子结合成一个Operator Chain(算子链)。
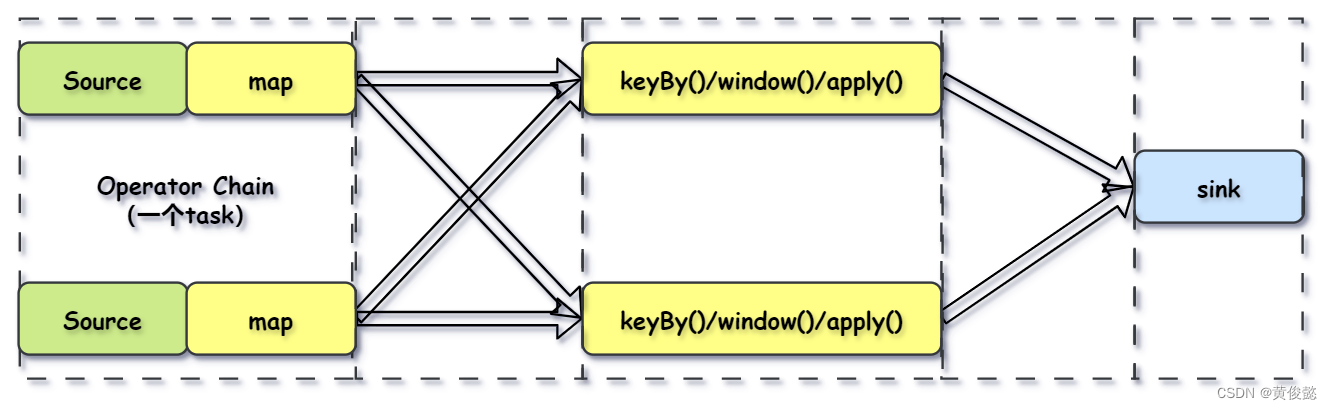
比如Source操作和map操作可以结合成一个Operator Chain,结合成Operator Chain后就在一个task中由一个thread完成。
Flink架构
Flink任务调度与执行
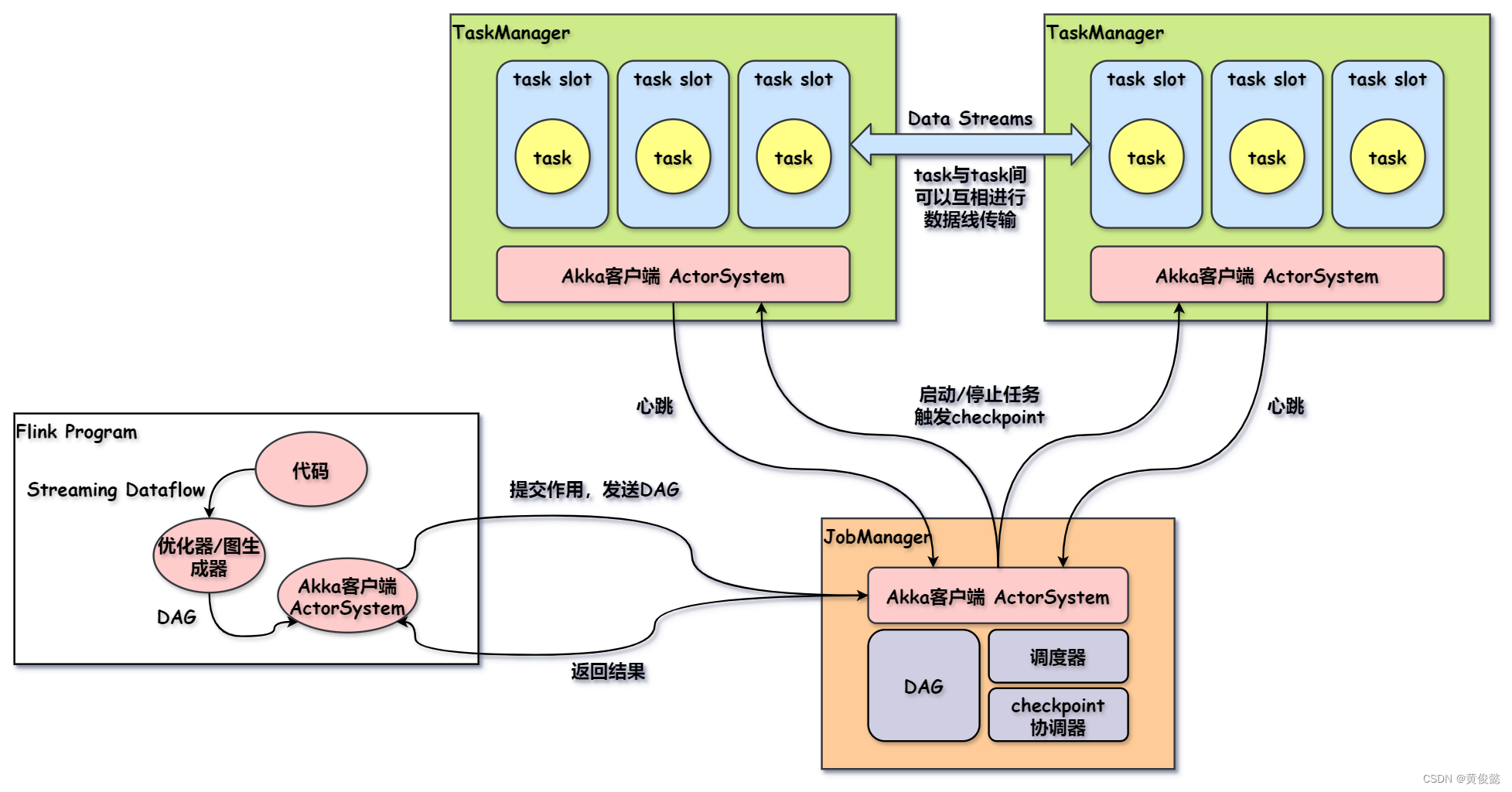
- 我们的代码会被Flink解析成一个DAG图,当我们调用env.execute()方法后,该DAG图就会被打包通过Akka客户端发送到JobManager。
- JobManager会通过调度器,把task调度到TaskManager上执行。
- TaskManager接收到task后,task将会在一个task slot中执行。
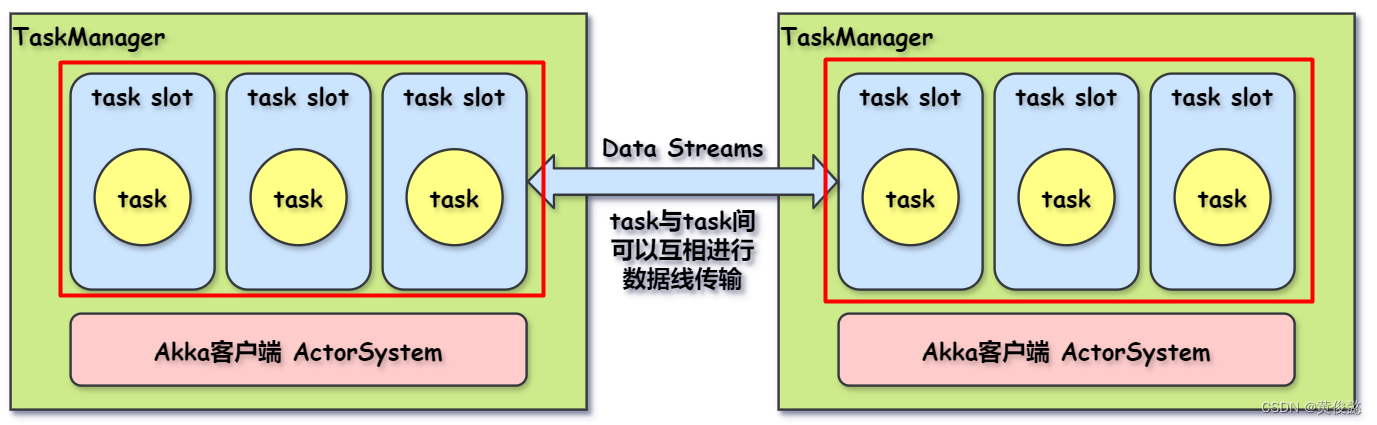
task slot 和 task
我们看到在TaskManager上有一个个的task slot被划分出来,task slot的数量是在TaskManager创建之初就设置好的。每个task(正确来说应该是subtask)都会调度到一个task slot上执行。task slot的作用主要是进行内存隔离,比如TaskManager设置了3个task slot的数量,那么每个task slot占用TaskManager三分之一的内存,task在task slot执行时,task与task之间将不会有内存资源竞争的情况发生。
EventTime、Windows、Watermarks
由于Flink处理的是流式计算,数据是以流的形式源源不断的流过来的,也就是说数据是没有边界的,但是对数据的计算必须在一个范围内进行,比如实时统计高速公路过去一个小时里的车流量。

那么就需要给源源不断流过来的数据划分边界,我们可以根据时间段或数据量来划分边界。
如果要按照时间段来划分边界,那么是通过时间字段进行划分。
EventTime

Flink有三种类型的时间:
- Event Time
- Ingestion Time
- Processing Time
一般用的较多的时Event Time,因为Event Time是固定不变的,不管什么时候计算,都会得到相同的输出结果。
Windows
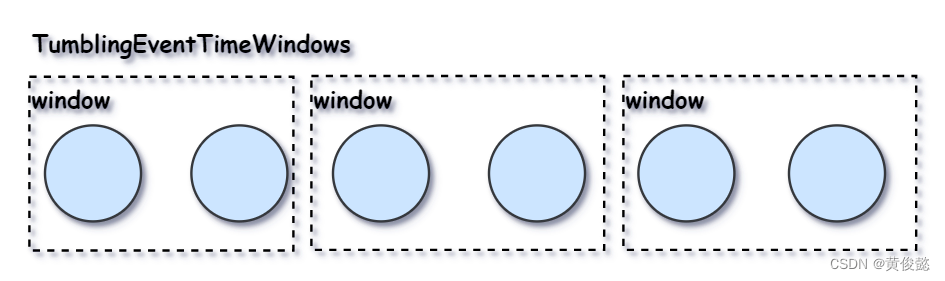
有了时间字段后,就可以根据时间划分时间窗,比如下面就是划分1分钟为一个时间窗,然后就可以对时间窗内的数据做计算。
java
.window(TumblingEventTimeWindows.of(Time.minutes(1)))TumblingEventTimeWindows是滚动时间窗:
还有SlidingEventTimeWindows滑动时间窗:
java
// 没10秒计算前1分钟窗口内的数据
.window(SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10)))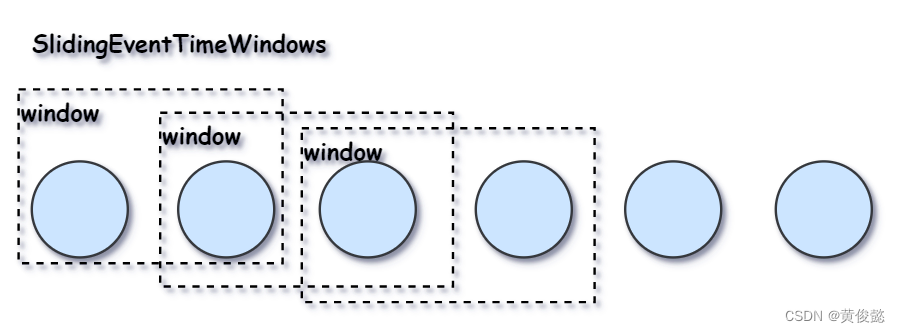
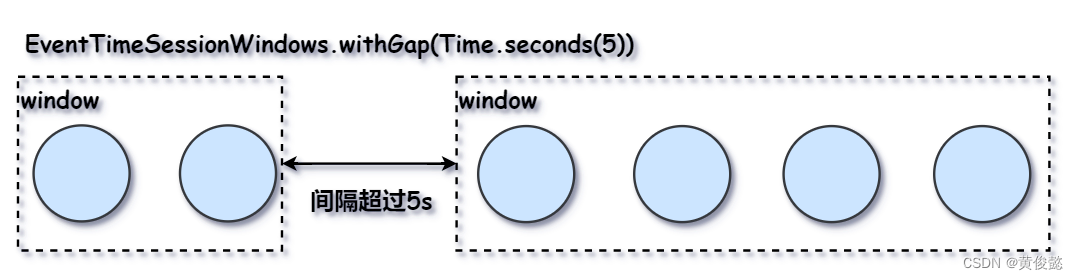
以及EventTimeSessionWindows会话时间窗:
java
// 间隔超过5s的话,下一达到的事件在新的窗口内计算,否则在同一窗口内计算
.window(EventTimeSessionWindows.withGap(Time.seconds(5)))上面设置的会话时间窗表示如果两个事件间的间隔超过5秒,那么后一个事件就会在新的窗口中计算;如果两个事件间隔没有超过5秒,那么就在同一窗口内计算。
Watermarks
但是事件流并不一定是有序的,它有可能是无序,有可能早发生的事件反而比晚发生的事件更晚到达。这时Flink需要等待较早发生的事件都到达了,才能进行一个时间窗的计算。
但是Flink无法得知什么时候边界内的所有事件都达到,因此必须有一种机制控制Flink什么时候停止等待。
这时候就要使用watermarks ,Flink接收到每一条数据时,会使用watermark生成器根据EventTime计算出一个watermark然后插入到数据中。当我们设置watermark的延迟时长是t时,那么watermark就等于当前所有达到数据中的EventTime中的最大值(maxEventTime)减去时间t,代表EventTime在 maxEventTime - t 之前的数据都已达到,结束时间为 maxEventTime - t 的时间窗可以进行计算。
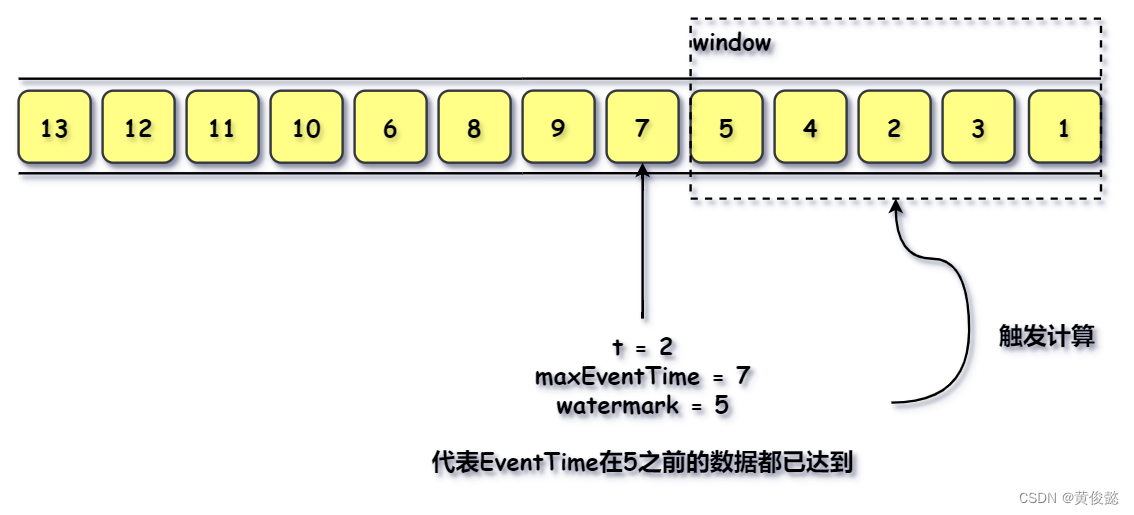
比如上面的例子,我们设置wartemark的延时时间t为2,那么当EventTime为7的事件到达时,该事件的watermark就是5(maxEventTime = 7, t = 2, watermark = maxEventTime - t = 7 - 2 = 5),那么表示Flink认定EventTime在5或5之前的时间都已经达到了,那么如果有一个窗口的结束时间为5的话,该窗口就会触发计算。
watermarks的使用:
java
DataStream<Event> stream = ...;
WatermarkStrategy<Event> strategy = WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, timestamp) -> event.timestamp);
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(strategy);当然,使用了watermarks之后,也不一定就能保证百分之一百准确。当我们把延时时间t设置的较短时,就能获取更低的延迟,但是准确性也相对下降;而如果我们把t设的较大,那么延迟就更大,但是准确性就想对较高。