MySQL 分区技术深入解析
分区的基本概念
MySQL分区 是一种数据库优化的技术,它允许将一个大的表、索引或其子集分割成多个较小的、更易于管理的片段,这些片段称为"分区"。每个分区都可以独立于其他分区进行存储、备份、索引和其他操作。这种技术主要是为了改善大型数据库表的查询性能、维护的方便性以及数据管理效率。
物理存储与逻辑分割
- 物理上,每个分区可以存储在不同的文件或目录中,这取决于分区类型和配置。
- 逻辑上,表数据根据分区键的值被分割到不同的分区里。
查询性能提升
- 当执行查询时,MySQL能够确定哪些分区包含相关数据,并只在这些分区上进行搜索。这减少了需要搜索的数据量,从而提高了查询性能。
- 对于范围查询或特定值的查询,分区可以显著减少扫描的数据量。
数据管理与维护
- 分区可以使得数据管理更加灵活。例如,可以独立地备份、恢复或优化某个分区,而无需对整个表进行操作。
- 对于具有时效性的数据,可以通过删除或归档某个分区来快速释放存储空间。
扩展性与并行处理
- 分区技术使得数据库表更容易扩展到更大的数据集。当表的大小超过单个存储设备的容量时,可以使用分区将数据分布到多个存储设备上。
- 由于每个分区可以独立处理,因此可以并行执行查询和其他数据库操作,从而进一步提高性能。
分区的原理和类型
InnoDB 逻辑存储结构
InnoDB存储引擎的逻辑结构是一个层次化的体系,主要由表空间、段、区和页构成。
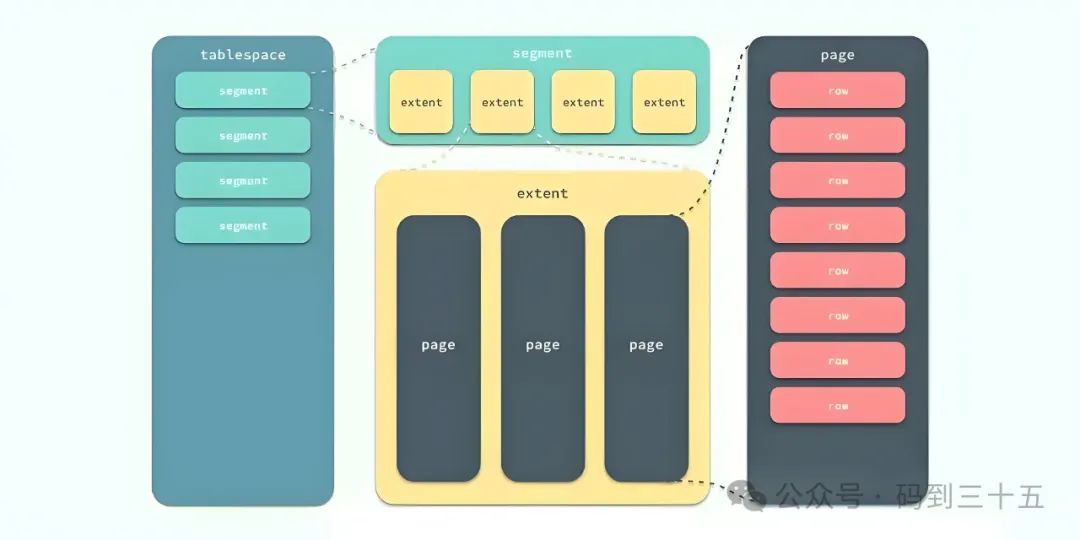
- 表空间:是InnoDB数据的最高层容器,所有数据的逻辑地址存储在这里。
- 段(Segment):是表空间的重要组成部分,根据用途可分为数据段、索引段和回滚段等。InnoDB引擎负责管理这些段,确保数据的完整性和高效访问。
- 区(Extent):由连续的页组成,每个区默认大小为1MB,不论页的大小如何变化。为保证页的连续性,InnoDB会一次性从磁盘申请多个区。每个区包含64个连续的页,当默认页大小为16KB时。在段开始时,InnoDB会先使用32个碎片页存储数据,以优化小表或特定段的空间利用率。
- 页(Page):是InnoDB磁盘管理的最小单元,也被称为块。其默认大小为16KB,但可通过配置参数进行调整。页的类型多样,包括数据页、undo页、系统页等,每种页都有其特定的功能和结构。
分区的原理
分区技术是将表中的记录分散到不同的物理文件中,即每个分区对应一个.idb文件。这是MySQL 5.1及以后版本支持的一项高级功能,旨在提高大数据表的管理效率和查询性能。
- 分区类型:MySQL支持水平分区,即根据某些条件将表中的行分配到不同的分区中。这些分区在物理上是独立的,可以单独处理,也可以作为整体处理。
- 性能和影响:虽然分区可以提高查询性能和管理效率,但如果不恰当使用,也可能对性能产生负面影响。因此,在使用分区时应谨慎评估其影响。
- 索引与分区:在MySQL中,分区是局部的,意味着数据和索引都存储在各自的分区内。目前,MySQL尚不支持全局分区索引。
- 分区键与唯一索引:当表存在主键或唯一索引时,分区列必须是这些索引的一部分。这是为了确保分区的唯一性和查询效率。
分区类型
MySQL支持几种不同类型的分区方式,包括RANGE、LIST、HASH和KEY。
- RANGE分区:基于列的值范围将数据分配到不同的分区。例如,可以根据日期范围将数据分配到不同的月份或年份的分区中。
- LIST分区:类似于RANGE分区,但LIST分区是基于列的离散值集合来分配数据的。可以指定一个枚举列表来定义每个分区的值。
- HASH分区:基于用户定义的表达式的哈希值来分配数据到不同的分区。这种分区方式适用于确保数据在各个分区之间均匀分布。
- KEY分区:类似于HASH分区,但KEY分区支持计算一列或多列的哈希值来分配数据。它支持多列作为分区键,并且提供了更好的数据分布和查询性能。
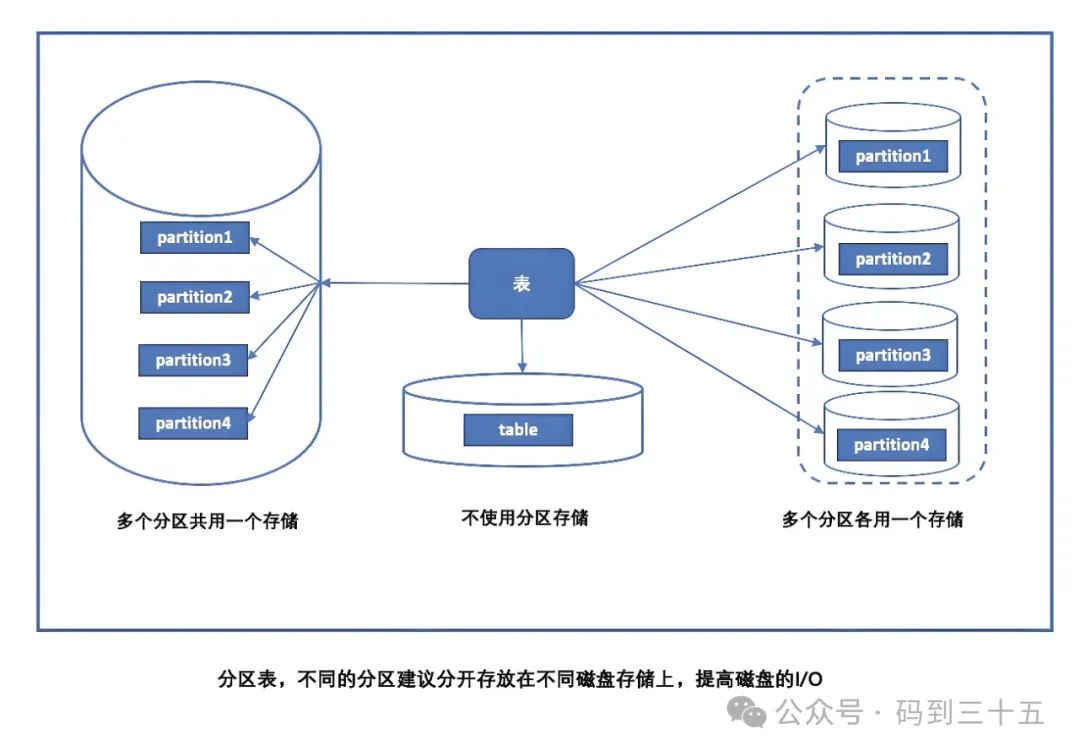
分区的优势和使用场景
- 性能提升:通过将数据分散到多个分区中,可以并行处理查询,从而提高查询性能。同时,对于涉及大量数据的维护操作(如备份和恢复),可以单独处理每个分区,减少了操作的复杂性和时间成本。
- 管理简化:分区可以使得数据管理更加灵活。例如,可以独立地备份、恢复或优化某个分区,而无需对整个表进行操作。这对于大型数据库表来说尤为重要,因为它可以显著减少维护时间和资源消耗。
- 数据归档和清理:对于具有时间属性的数据(如日志、交易记录等),可以使用分区来轻松归档旧数据或删除不再需要的数据。通过简单地删除或归档某个分区,可以快速释放存储空间并提高性能。
- 可扩展性:分区技术使得数据库表更容易扩展到更大的数据集。当表的大小超过单个存储设备的容量时,可以使用分区将数据分布到多个存储设备上,从而实现水平扩展。
如何实施分区
-
确定分区键:选择一个合适的列作为分区键,该列的值将用于将数据分配到不同的分区中。通常选择具有连续值或离散值的列作为分区键。
-
选择合适的分区类型:根据数据的特点和查询需求选择合适的分区类型(RANGE、LIST、HASH或KEY)。确保所选的分区类型能够均匀地分布数据并提高查询性能。
-
创建分区表 :使用
CREATE TABLE语句创建分区表,并指定分区键和分区类型等参数。例如,使用RANGE分区类型创建一个按月分区的销售数据表。CREATE TABLE sales ( sale_date DATE NOT NULL) PARTITION BY RANGE (YEAR(sale_date)) ( PARTITION p0 VALUES LESS THAN (2022));
-
查询和维护:一旦创建了分区表,就可以像普通表一样执行查询操作。MySQL会自动定位到相应的分区上执行查询。同时,可以独立地备份、恢复或优化每个分区。
-
监控和调整:定期监控分区的性能和存储使用情况,并根据需要进行调整。例如,可以添加新的分区来容纳新数据,或者删除旧的分区以释放存储空间。
分区表的操作
包括创建分区表、修改分区和删除、合并、拆分等。
创建带有分区的表
RANGE 分区
CREATE TABLE sales_range ( sale_date DATE NOT NULL) PARTITION BY RANGE (YEAR(sale_date)) ( PARTITION p0 VALUES LESS THAN (2010), ...... PARTITION p3 VALUES LESS THAN MAXVALUE);LIST 分区
CREATE TABLE sales_list ( region ENUM('North', 'South', 'East', 'West') NOT NULL) PARTITION BY LIST COLUMNS(region) ( PARTITION pNorth VALUES IN('North'), ...... PARTITION pWest VALUES IN('West'));HASH 分区
CREATE TABLE sales_hash ( sale_date DATE NOT NULL) PARTITION BY HASH(YEAR(sale_date)) PARTITIONS 4;KEY 分区
CREATE TABLE sales_key ( id INT NOT NULL) PARTITION BY KEY(id) PARTITIONS 4;修改分区表
添加分区
对于 RANGE 或 LIST 分区,可以使用 ALTER TABLE 语句添加分区:
ALTER TABLE sales_range ADD PARTITION (PARTITION p4 VALUES LESS THAN (2013));对于 HASH 或 KEY 分区,由于它们是基于哈希函数进行分区的,因此不能直接添加分区,但可以通过重新创建表或调整分区数量来间接实现。
删除分区
可以使用 ALTER TABLE 语句删除分区:
ALTER TABLE sales_range DROP PARTITION p0;这将删除名为 p0 的分区及其包含的所有数据。
合并分区
对于相邻的 RANGE 或 LIST 分区,可以使用 ALTER TABLE 语句将它们合并为一个分区:
ALTER TABLE sales_range REORGANIZE PARTITION p1, p2 INTO ( PARTITION p1_2 VALUES LESS THAN (2012));把 p1 和 p2 分区合并为一个名为 p1_2 的新分区。
分区拆分限制:
- 分区数量限制:MySQL对单个表的分区数量有限制,通常最大分区数目不能超过1024个。这意味着在进行拆分操作时,需要注意新生成的分区数量是否会超过这个限制。
- 分区键和分区类型的限制:拆分操作通常受到分区键和分区类型的约束。例如,在RANGE分区中,拆分点必须基于分区键的连续值。对于LIST分区,拆分需要基于离散的枚举值。HASH和KEY分区由于其基于哈希函数的特性,不直接支持拆分操作。
- 数据完整性:拆分分区时,需要确保数据的完整性。如果拆分操作导致数据丢失或损坏,那么这将是一个严重的问题。因此,在执行拆分操作之前,最好进行数据备份。
- 性能考虑:拆分大分区可能会影响数据库性能,因为需要重建索引和移动大量数据。这种操作最好在数据库负载较低的时候进行。
拆分分区
使用ALTER TABLE语句来拆分分区。语法,用于RANGE分区:
ALTER TABLE table_name REORGANIZE PARTITION partition_name INTO ( PARTITION new_partition1 VALUES LESS THAN (value1), PARTITION new_partition2 VALUES LESS THAN (value2) );table_name是你要修改的表名,partition_name是要拆分的分区名,new_partition1和new_partition2是新分区的名称,而value1和value2是定义新分区键值范围的值。
分区合并限制:
- 相邻分区合并:在MySQL中,通常只能合并相邻的分区。这意味着你不能随意选择两个不相邻的分区进行合并。
- 分区类型和键的限制:与拆分操作类似,合并操作也受到分区类型和分区键的约束。不是所有类型的分区都可以轻松合并。
- 数据迁移和重建:合并分区时,可能需要进行数据迁移和索引重建,这可能会影响数据库的性能和可用性。
重建分区
重建分区相当于先清除分区内的所有数据,并随后重新插入,这有助于整理分区内的碎片。
ALTER TABLE tbl_name REBUILD PARTITION partition_name_list;优化分区
当从分区中删除了大量数据,或者对包含可变长度字段(如VARCHAR或TEXT类型列)的分区进行了多次修改后,优化分区可以回收未使用的空间并整理数据碎片。
ALTER TABLE tbl_name OPTIMIZE PARTITION partition_name_list;分析分区
此操作会读取并保存分区的键分布统计信息,有助于查询优化器制定更有效的查询计划。
ALTER TABLE tbl_name ANALYZE PARTITION partition_name_list;检查分区
此操作用于验证分区中的数据或索引是否完整无损。
ALTER TABLE tbl_name CHECK PARTITION partition_name_list;修补分区
如果分区数据或索引受损,可以使用此操作进行修复。
ALTER TABLE tbl_name REPAIR PARTITION partition_name_list;查看分区信息
可以使用以下查询来查看表的分区信息:
SELECT * FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'sales_range';或者使用 SHOW CREATE TABLE 语句来查看表的创建语句,包括分区定义:
SHOW CREATE TABLE sales_range;复合分区
复合分区是指在分区表中的每个分区再次进行分割,这种再次分割的子分区既可以使用HASH分区,也可以使用KEY分区。这种技术也被称为子分区。
使用场景
- 数据量巨大:当表中的数据量非常大时,单一分区可能无法满足性能需求。复合分区可以将数据更细致地划分,从而提高查询效率。
- 多维度查询优化:如果查询经常涉及多个维度(如时间和地区),复合分区可以针对这些维度进行分区,从而优化查询性能。
在复合分区中,常见的组合是RANGE或LIST与HASH或KEY的组合
创建一个记录用户行为日志的表,首先根据日志日期进行RANGE分区,然后在每个日期范围内根据用户ID进行HASH子分区。
CREATE TABLE user_activity_logs ( user_id INT NOT NULL, activity_date DATE NOT NULL)PARTITION BY RANGE COLUMNS(activity_date) ( PARTITION p2022 VALUES LESS THAN ('2023-01-01') ( SUBPARTITION sp2022a HASH(user_id) PARTITIONS 4 ), -- 可以根据需要继续添加更多的年份分区和HASH子分区 PARTITION pfuture VALUES LESS THAN (MAXVALUE) ( SUBPARTITION spfuture HASH(user_id) PARTITIONS 4 ));- 先根据
activity_date进行范围分区。每个范围分区内部,又根据user_id进行了HASH子分区。这样做的好处是可以更均匀地分布数据,提高查询性能,特别是当查询条件同时包含日期和用户ID时。 - 预留了一个名为
pfuture的分区,它的范围是小于最大值(MAXVALUE),这样可以确保未来的日志也能被正确地插入到表中。 PARTITIONS 4表示在每个范围分区内创建4个哈希子分区。这个数字可以根据数据量的大小和查询模式进行调整。
注意事项和限制
- 分区键选择:选择合适的分区键至关重要。确保分区键能够均匀地分布数据,并且与查询条件相匹配,以提高查询性能。
- 分区数量限制:MySQL对单个表的分区数量有限制(通常为1024个分区)。在设计分区策略时要考虑这个限制。
- 全局唯一索引限制:在分区表上创建全局唯一索引时存在限制。确保了解这些限制,并根据需要进行调整。
- 性能和资源消耗:虽然分区可以提高性能,但在某些情况下,过多的分区可能导致额外的性能和资源消耗。因此,要合理设计分区策略以平衡性能和资源消耗。
- 兼容性和迁移:在迁移现有表到分区表之前,要确保备份原始数据并测试迁移过程的正确性。此外,要了解不同MySQL版本之间对分区功能的支持和兼容性差异。
解释几个问题
MySQL 分区处理NULL值的方式
MySQL中,当涉及到分区时,系统并不会特别禁止NULL值。不论是列的实际值还是用户自定义的表达式结果,MySQL通常会将NULL值视为0进行处理。然而,这种行为可能并不总是符合数据完整性和准确性的要求。为了避免这种隐式的NULL到0的转换,最佳实践是在设计数据库表时,对相关列明确声明为"NOT NULL"。这样做可以确保数据的准确性和一致性,同时避免由于NULL值被错误地解释为0而导致的潜在问题。因此,在设计分区表时,应该谨慎考虑NULL值的处理方式,并根据需要采取相应的预防措施。
此外,如果确实需要存储NULL值,并且不希望MySQL将其视为0,可以考虑使用其他特殊值(如某个不可能在实际业务中出现的标识值)来代替NULL,或者在设计分区策略时明确考虑NULL值的处理逻辑。这样可以在保持数据完整性的同时,更好地满足业务需求。
分区列必须主键或唯一键的一部分
在MySQL中,当表存在主键(primary key)或唯一键(unique key)时,分区的列必须是这些键的一个组成部分的原因主要涉及到数据的完整性和查询性能:
-
数据完整性:
主键和唯一键用于保证表中数据的唯一性。如果分区列不是这些键的一部分,那么在不同分区中可能存在具有相同主键或唯一键值的数据行,这将破坏数据的唯一性约束。
-
查询性能:
分区的主要目的是为了提高查询性能,特别是针对大数据量的表。如果分区列不是主键或唯一键的一部分,那么在进行基于主键或唯一键的查询时,MySQL可能需要在所有分区中进行搜索,从而降低了查询性能。
-
数据一致性:
当表被分区时,每个分区实际上可以看作是一个独立的"子表"。如果分区列不是主键或唯一键的一部分,那么在执行更新或删除操作时,MySQL需要确保跨所有分区的数据一致性,这会增加操作的复杂性和开销。
-
分区策略:
MySQL的分区策略是基于分区列的值来将数据分配到不同的分区中。如果分区列不是主键或唯一键的一部分,那么分区策略可能会变得复杂且低效,因为系统需要额外处理主键或唯一键的约束。
分区与性能考量
技术的运用需要恰到好处才能发挥其优势。以显式锁为例,虽然功能强大,但使用不当可能导致性能下降或其他不良后果。同样地,分区技术也并非万能的性能提升工具。
分区确实可以为某些SQL查询带来性能上的提升,但其主要价值在于提高数据库的高可用性管理。在应用分区技术时,我们需要根据数据库的使用场景来谨慎选择。
数据库应用大体上可分为OLTP(在线事务处理)和OLAP(在线分析处理)两类。对于OLAP应用来说,分区能够显著提升查询性能,因为分析类查询往往需要处理大量数据。按时间进行分区,例如按月划分用户行为数据,可以使得查询只需扫描相关分区,从而提高效率。
然而,在OLTP应用中,使用分区则需更为谨慎。这类应用通常不会查询大表中超过10%的数据,而是通过索引快速检索少量记录。例如,对于包含1000万条记录的表,如果查询使用了辅助索引但未涉及分区键,可能导致性能下降。原本在单个B+树中3次逻辑IO就能完成的操作,在10个分区的情况下可能需要(3+3)*10次逻辑IO(分别访问聚集索引和辅助索引)。
因此,在OLTP应用中采用分区表时,务必进行充分的性能测试和优化。
为了便于开发者观察SQL查询对分区的利用情况,可以使用EXPLAIN PARTITIONS语句与SELECT查询结合,从而清晰地看到哪些分区被查询涉及。
MySQL 与 ES 数据同步的方案
在实际项目开发中,常用MySQL作为业务数据库,ElasticSearch作为查询库。ElasticSearch主要用来应对海量数据的复杂查询,提高查询效率和缓解MySQL数据库的压力。
1、同步双写方案
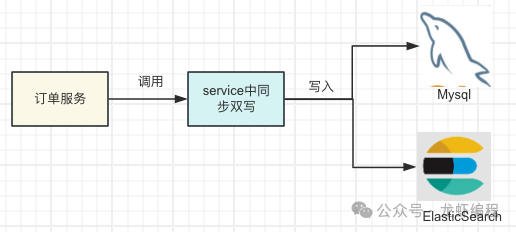
同步双写是指在MySQL上进行数据增删改操作时,同步将数据写入到ElasticSearch中,使用此方式保证MySQL与ElasticSearch中的数据一致性的优/缺点如下:
|----|--------------------------------------------|
| 优点 | 实现简单;实时性高 |
| 缺点 | 1、存在数据丢失风险; 2、性能不高; 3、和业务之间的耦合性强; 4、不方便做扩展 |
2、异步写入方案
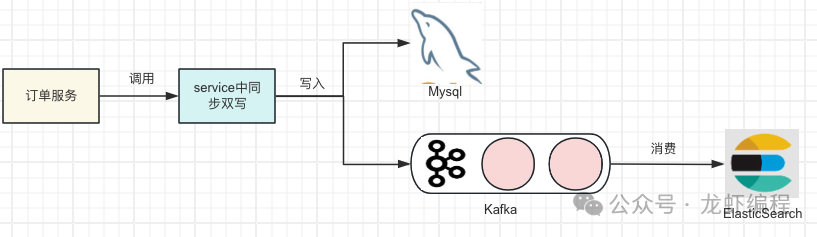
在MySQL上进行数据增删改操作时,通过MQ(如Kafka)异步将数据写入到ElasticSearch中。这种异步方式可以降低MySQL的写入延迟并有效的防止了ElasticSearch自身问题而影响到MySQL数据的写入,但是可能会出现存在MySQL和ElasticSearch数据长时间的不一致的现象。此方案的优缺点如下:
|----|------------------------------------------------------------------|
| 优点 | 性能高;数据不易丢失;支持多数据源写入 |
| 缺点 | 1、增加了系统的复杂度,因为需要接入MQ; 2、数据之间的同步可能延迟高,MQ消费可能不及时; 3、发送消息需要硬编码到业务中; |
3、定时任务同步方案
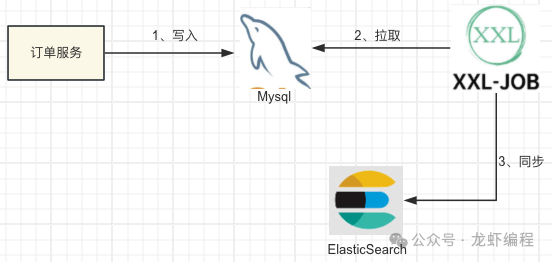
定时任务的方案就是设定一个频率去MySQL中拉取数据来同步到ElasticSearch中,但是这个频率如何选择要根据自身的业务特性来选取。当前,如果频率设置很高就给系统造成一定的压力(如CPU、内存使用率居高不下),频率设置很低数据的实时性比较差。此方案的优缺点如下:
|----|--------------------------------------------------|
| 优点 | 实现简单;无额外的代码的侵入业务中 |
| 缺点 | 1、实时性差,因为依赖定时任务的执行频率; 2、给数据库带来一定的压力,因为是不断的轮询数据库; |
4、使用LogStash同步
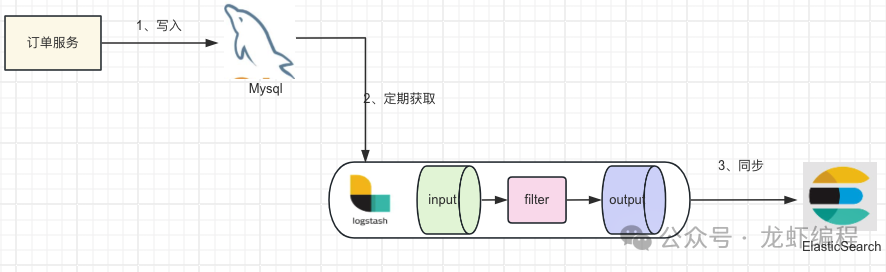
此方案是针对定时任务同步的方案的一种改进,原理是LogStash提供了JDBC插件,它可以定期使用SQL查询数据库并且获取数据变化,然后通过配置来实现MySQL数据同步到ElasticSearch中。此方案的优缺点如下:
|----|----------------------------------------|
| 优点 | 实现简单;无额外的代码的侵入业务中 |
| 缺点 | 1、实时性差,因为Logstash是定期同步数据的; 2、需要中间件的支持; |
5、使用binlog同步---自建binlog服务中心

此方案是先读取MySQL的binlog日志,然后将binlog日志交给binlog中心服务处理,然后把读取的binlog转化成MQ消息,通过消费MQ消息将Mysql中的数据同步到ElasticSearch中。此方案的优缺点如下:
|----|-------------------------------------------|
| 优点 | 性能高;业务解耦;无额外的代码的侵入业务中 |
| 缺点 | 1、构建binlog中心服务复杂; 2、采用MQ消费binlog也会存在延迟风险; |
6、使用binlog同步------开源中间件
基于binlog同步的方式,目前有许多的优秀数据迁移工具可以实现,如canal,其实现的原理是binlog订阅的方式,模拟一个MySQL的Slave订阅 binlog日志,然后通过binlog将数据同步到监听者中。
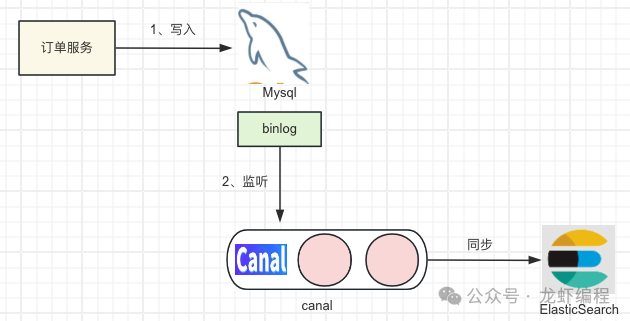
数据同步方案有多种,需要根据自身的业务对数据的实时性来选择,业内常用的还是使用binlog的方案实现。
深度分页:limit 0,100 和 limit 10000000,100
MySQL 的LIMIT m n工作原理是先读取前 m+n 条记录,再抛弃前 m 条,然后返回后面的 n 条数据。因此,当 m 值增大时,偏移量也增大,性能表现就会变差。因此,LIMIT 10000000,100要比LIMIT 0,100的性能差得多,因为它需要先读取 10000100 条数据,然后再抛弃前 10000000 条。
limit 优化
通常,在查询数据时,如果已经明确知道所需行数,建议在查询语句中使用LIMIT,而不是先检索整个结果集再丢弃不需要的数据。尽管我们前面提到,在深度分页时,MySQL 也会先检索全部数据再丢弃,但 MySQL 对LIMIT也进行了一些优化。然而,以下优化前提假设在使用LIMIT时没有使用HAVING语句。
- MySQL 通常更倾向于执行全表扫描,但如果您使用
LIMIT只查询少量记录,MySQL 在某些情况下可能会选择使用索引。 - 如果将
LIMIT子句与ORDER BY子句结合使用,MySQL 会在找到排序结果的前 row_count 行数据后立即停止排序,而不是对整个结果进行排序。如果使用索引完成排序,这将非常快。
当使用索引来执行 ORDER BY 子句时,MySQL 能够利用已经排好序的索引树,从而快速找到所需的前 N 行数据,而无需对整个表进行全表扫描和排序。
- 当将
LIMIT row_count与DISTINCT一起使用时,一旦找到 row_count 个唯一的行,MySQL 就会停止。 - 使用
LIMIT 0可以快速返回一个空的结果集,这是一种很有用的方法,用于检测查询是否有效。 - 如果
ORDER BY不适用索引,并且后面还有LIMIT子句,优化器可能会避免使用合并文件,而是使用内存中的filesort操作对内存中的行进行排序。
limit 和 order by
在查询过程中,如果对某个字段进行排序(ORDER BY),而该字段存在重复值,MySQL 可能以任意顺序返回这些行记录,并且根据执行计划的不同,排序结果可能会有所不同。换句话说,排序结果可能是不确定的。因此,当ORDER BY语句中有LIMIT时,每次查询结果都可能不同。解决这个问题的一个好方法就是在排序时不仅使用一个字段,而是再加一个字段,比如像 id 这样保证不会重复的字段。
mysql> SELECT * FROM ratings ORDER BY category,id LIMIT 5;MySQL 联合索引的最左匹配原则
联合索引 和 MySQL 调优的关系
MySQL 调优的一个核心动作,就是通过联合索引实现索引覆盖。在MySQL中,合理使用联合索引可以提高查询效率,通过联合索引实现索引覆盖 ,常常需要注意一些技巧:
- 选择合适的列: 联合索引的列顺序非常重要。应该优先选择最频繁用于查询条件的列,以提高索引的效率。其次考虑选择性高的列,这样可以过滤出更少的数据。
- 避免冗余列: 联合索引的列应该尽量避免包含冗余列,即多个索引的前缀相同。这样会增加索引的维护成本,并占用更多的存储空间。
- 避免过度索引: 不要为每个查询都创建一个新的联合索引。应该根据实际情况,分析哪些查询是最频繁的,然后创建针对这些查询的索引。
- 覆盖索引: 如果查询的列都包含在联合索引中,并且不需要访问表的其他列,那么MySQL可以直接使用索引来执行查询,而不必访问表,这种索引称为覆盖索引,可以提高查询性能。
- 使用EXPLAIN进行查询计划分析: 使用MySQL的EXPLAIN语句可以查看MySQL执行查询的执行计划,以便优化查询语句和索引的使用。
- 定期优化索引: 随着数据库的使用,索引的效率可能会下降,因此需要定期进行索引的优化和重建,以保持查询性能的稳定性。
- 分析查询日志: 监控数据库的查询日志,分析哪些查询是最频繁的,以及它们的查询模式,可以帮助确定需要创建的联合索引。
- 避免过度索引更新: 避免频繁地更新索引列,因为每次更新索引都会增加数据库的负载和IO操作。
综上所述,联合索引是MySQL 调优的一个核心动作, 通过 联合索引进行MySQL 调优时,需要综合考虑列的选择、索引的覆盖、查询的频率和模式等因素,以提高MySQL数据库的查询性能。
MySQL索引机制
在关系型数据库中,索引是一种单独的、物理的数据,对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合,以及相应的指向表中物理标识这些值的数据页的逻辑指针清单。
通俗的理解为
在关系型数据库中,索引是一种用来帮助快速检索目标数据的存储结构。
索引的创建
MySQL可以通过CREATE、ALTER、DDL三种方式创建一个索引。
-
使用CREATE语句创建
CREATE INDEX indexName ON tableName (columnName(length) [ASC|DESC]);
-
使用ALTER语句创建
ALTER TABLE tableName ADD INDEX indexName(columnName(length) [ASC|DESC]);
-
建表时DDL语句中创建
CREATE TABLE tableName(
columnName1 INT(8) NOT NULL,
columnName2 ....,
.....,
INDEX [indexName] (columnName(length))
);
索引的查询
SHOW INDEX from tableName;索引的删除
ALTER TABLE table_name DROP INDEX index_name;
DROP INDEX index_name ON table_name;MySQL联合索引
什么是联合索引
联合索引(Composite Index)是一种索引类型,它由多个列组成。MySQL的联合索引(也称为复合索引)是建立在多个字段上的索引。这种索引类型允许数据库在查询时同时考虑多个列的值,从而提高查询效率和性能。
- 联合索引:也称复合索引,就是建立在多个字段上的索引。联合索引的数据结构依然是 B+ Tree。
- 当使用(col1, col2, col3)创建一个联合索引时,创建的只是一颗B+ Tree,在这棵树中,会先按照最左的字段col1排序,在col1相同时再按照col2排序,col2相同时再按照col3排序。
联合索引存储结构
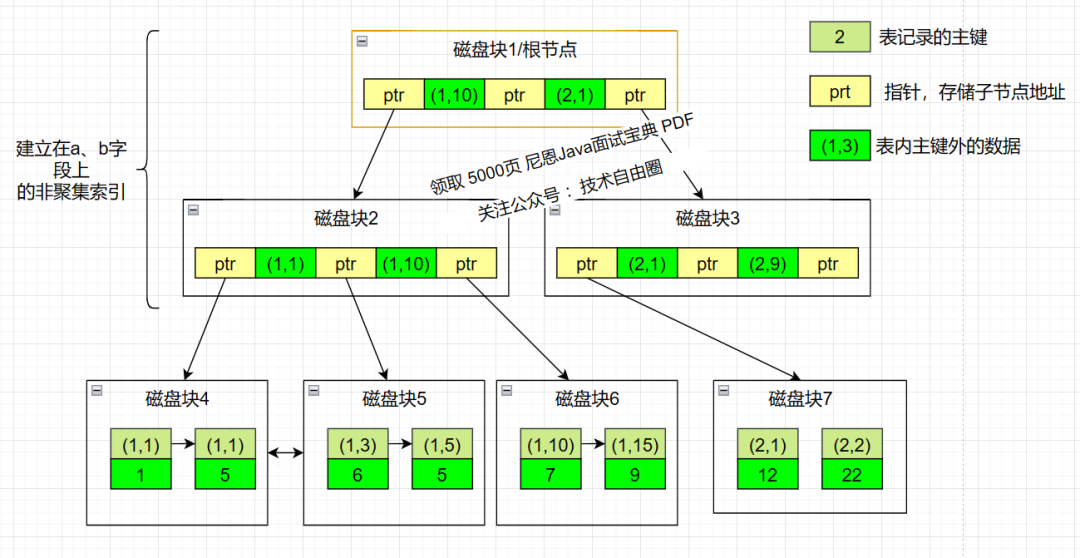
联合索引是一种特殊类型的索引,它包含两个或更多列。在MySQL中,联合索引的数据结构通常是B+Tree,这与单列索引使用的数据结构相同。当创建联合索引时,需要注意列的顺序,因为这将影响到索引的使用方式。
如下图所示,表的数据如右图,ID 为主键,创建的联合索引为 (a,b),注意联合索引顺序,下图是模拟的联合索引的 B+ Tree 存储结构
最左前缀匹配原则
联合索引还是一颗B+树,只不过联合索引的健 数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
假如创建一个(a,b)的联合索引,联合索引B+ Tree结构如下:
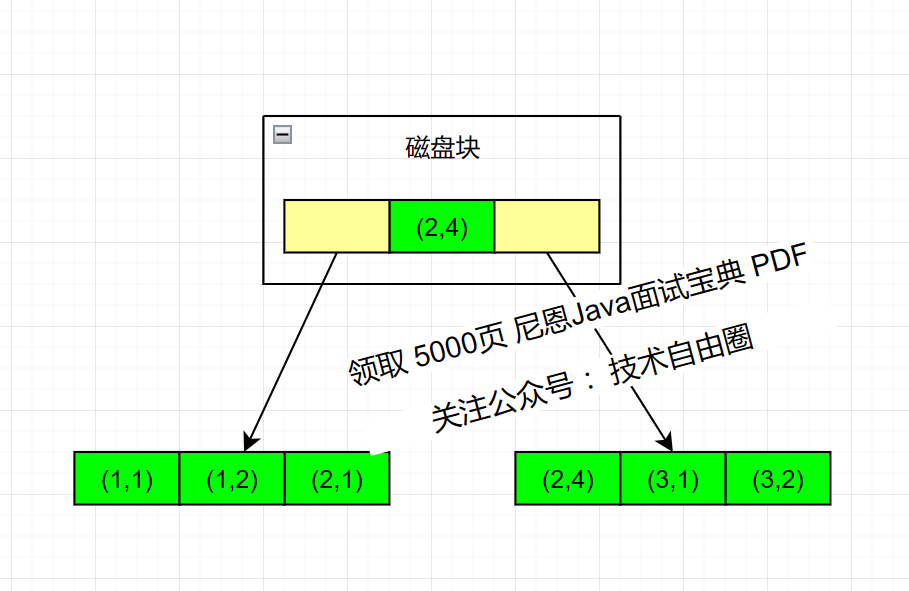
结合上述联合索引B+ Tree结构,可以得出如下结论:
- a的值是有顺序的1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
- 当a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。
- 最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。
例如:a = 1 and b = 2中,a和b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1 and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
最左匹配原则:
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。下面我们以建立联合索引(a,b,c)为例,进行详细说明。
1 全值匹配查询时
下述SQL会用到索引,因为where子句中,几个搜索条件顺序调换不影响查询结果,因为MySQL中有查询优化器,会自动优化查询顺序。
select * from table_name where b = '2' and a = '1' and c = '3'2 匹配左边的列时
下述SQL,都从最左边开始连续匹配,用到了索引。
select * from table_name where a = '1' and b = '2'下述SQL中,没有从最左边开始,最后查询没有用到索引,用的是全表扫描。
select * from table_name where b = '1' and c = '3'下述SQL中,如果不连续时,只用到了a列的索引,b列和c列都没有用到
select * from table_name where a = '1' and c = '3'3 匹配列前缀
如果列是字符型的话它的比较规则是先比较字符串的第一个字符,第一个字符小的哪个字符串就比较小,如果两个字符串第一个字符相通,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小,依次类推,比较字符串。
如果a是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描。
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询
select * from table_name where a like '%As%'; //全表查询
4 匹配范围值
下述SQL,可以对最左边的列进行范围查询
select * from table_name where a > 1 and a < 3多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引。在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤。
select * from table_name where a > 1 and a < 3 and b > 1;5 精确匹配某一列并范围匹配另外一列
如果左边的列是精确查找的,右边的列可以进行范围查找,如下SQL中,a=1的情况下b是有序的,进行范围查找走的是联合索引。
select * from table_name where a = 1 and b > 3;
6 排序
一般情况下,我们只能把记录加载到内存中,再用一些排序算法,比如快速排序,归并排序等在内存中对这些记录进行排序,有时候查询的结果集太大不能在内存中进行排序的话,还可能暂时借助磁盘空间存放中间结果,排序操作完成后再把排好序的结果返回客户端。
MySQL中把这种在内存中或磁盘上进行排序的方式统称为文件排序。文件排序非常慢,但如果order子句用到了索引列,就有可能省去文件排序的步骤。
因为b+树索引本身就是按照上述规则排序的,所以可以直接从索引中提取数据,然后进行回表操作取出该索引中不包含的列就好了,order by的子句后面的顺序也必须按照索引列的顺序给出,比如下SQL:
select * from table_name order by b,c,a limit 10;在以下SQL中颠倒顺序,没有用到索引
select * from table_name order by a,b limit 10;以下SQL中会用到部分索引,联合索引左边列为常量,后边的列排序可以用到索引
select * from table_name where a =1 order by b,c limit 10;为什么要遵循最左前缀匹配?
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
如下,我们以age,name两个字段建立一个联合索引,非叶子节点中记录age,name两个字段的值,而叶子节点中记录的是age,name两个字段值及主键Id的值,在MySQL中B+ Tree 索引结构如下:

在上述联合索引存储数据过程中,首先会按照age排序,当age相同时则按照name排序。
-
结合上述索引结构,可以看出联合索引底层也是一颗B+Tree,在联合索引中构造B+Tree的时候,会先以最左边的key进行排序,如果左边的key相同时,则再依次按照右边的key进行排序。
-
所以在通过索引查询的时候,也需要遵守最左前缀匹配的原则,也就是需要从联合索引的最左边开始进行匹配,这时候就要求查询语句的where条件中,包含最左边的索引的值。
一定要遵循最左前缀匹配吗?
最左前缀匹配原则,也就是SQL的查询条件中必须要包含联合索引的第一个字段,这样才能命中联合索引查询,但实际上这条规则也并不是100%遵循的。
因为在MySQL8.x版本中加入了一个新的优化机制,也就是索引跳跃式扫描,这种机制使得咱们即使查询条件中,没有使用联合索引的第一个字段,也依旧可以使用联合索引,看起来就像跳过了联合索引中的第一个字段一样,这也是跳跃扫描的名称由来。
我们来看如下例子,理解一下索引跳跃式扫描如何实现的。比如此时通过(A、B、C)三个列建立了一个联合索引,此时有如下一条SQL:
SELECT * FROM table_name WHERE B = `xxx` AND C = `xxx`;
按正常情况来看,这条SQL既不符合最左前缀原则,也不具备使用索引覆盖的条件,因此绝对是不会走联合索引查询的。但这条SQL中都已经使用了联合索引中的两个字段,结果还不能使用索引,这似乎有点亏啊?因此MySQL8.x推出了跳跃扫描机制,但跳跃扫描并不是真正的"跳过了"第一个字段,而是优化器为你重构了SQL,比如上述这条SQL则会重构成如下情况:
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx`
UNION ALL
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx` AND A = "yyy"
......
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx` AND A = "zzz";
通过MySQL优化器处理后,虽然你没用第一个字段,但我(优化器)给你加上去,今天这个联合索引你就得用,不用也得给我用。
但是跳跃扫描机制也有很多限制,比如多表联查时无法触发、SQL条件中有分组操作也无法触发、SQL中用了DISTINCT去重也无法触发等等,总之有很多限制条件,具体的可以参考《MySQL官网8.0-跳跃扫描》。
最后,可以通过通过如下命令来选择开启或关闭跳跃式扫描机制。
set @@optimizer_switch = 'skip_scan=off|on';
联合索引注意事项
-
选择合适的列:应选择那些经常用于查询条件的列来创建联合索引。
-
考虑列的顺序:在创建联合索引时,应该根据实际的查询需求来安排列的顺序,以确保索引能够被有效利用。
-
避免过长的索引:虽然联合索引可以包含多个列,但过长的索引可能会增加维护成本,并且在某些情况下可能不会带来预期的性能提升。
-
避免范围查询:如果查询中包含范围操作符(如BETWEEN, <, >, LIKE),则MySQL可能无法有效地利用联合索引,因为它需要检查索引中的每个范围边界。
-
考虑索引的区分度:如果某个列的值重复率很高,那么该列作为联合索引的一部分可能不会提供太大的性能提升,因为它不能有效地区分不同的记录。
联合索引作为数据库中的一种索引类型,它由多个列组成,在使用时,一般遵循最左匹配原则,以加速数据库查询操作。
Record Lock, Gap Lock 和 Next-Key Lock
在MySQL的InnoDB引擎的行锁主要有三类:
-
Record Lock:记录锁,是在索引记录上加锁; -
Gap Lock:间隙锁,锁定一个范围,但不包含记录; -
Next-key Lock:Next-key Lock = Gap Lock + Record Lock,它锁定了一个范围(Gap Lock实现),并且锁定记录本身(Record Lock实现);
Record Lock
Record Lock,记录锁,它是针对索引记录的锁,锁定的总是索引记录。在多用户数据库系统中,多个事务可能会同时尝试读取或修改同一条记录,Record Lock确保只有一个事务能在某一时刻修改该记录,其他事务只能读取,或者在写锁释放后再进行修改。
Gap Lock
Gap Lock,间隙锁,它是一种行级锁,锁住两个索引记录之间的间隙,而不是实际的数据记录,由InnoDB隐式添加。
如下图:(1,3) 表示锁住记录1 和记录3 之间的间隙,这样记录2 就无法插入,间隙可能跨越单个索引值、多个索引值,甚至是空。

在InnoDB中,间隙锁是通过索引来实现的。这意味着间隙锁只能作用于索引,而不能直接作用于非索引列。当一个事务对某个索引列上的间隙加锁时,其他事务就无法在这个间隙中插入新的记录。
- 事务通过
show engine innodb status\G指令可以查看到间隙锁的存在。
需要说明,间隙锁只是锁住间隙内部的范围,在间隙外的insert/update操作不会受影响。
Next-Key Lock
Next-Key Lock,称为临键锁,它是Record Lock + Gap Lock的组合,用来锁定一个范围,并且锁定记录本身锁,它是一种左开右闭的范围,可以用符号表示为:(a,b]。如下图:

Record Lock,Gap Lock和Gap Lock 3种锁是存在MySQL的InnoDB引擎的行锁,MyISAM引擎没有:
-
Record Lock:记录锁,是在索引记录上加锁; -
Gap Lock:间隙锁,锁定一个范围,但不包含记录,即(A,B); -
Next-key Lock:Next-key Lock = Gap Lock + Record Lock,它锁定了一个范围(Gap Lock实现),并且锁定记录本身(Record Lock实现),即(A,B];
这 3种锁都是InnoDB引擎隐式添加的,目的是为了解决可重复读隔离级别下幻读的现象。
MySQL 和 Linux 面试集
Docker和虚拟机的主要区别
Docker容器与虚拟机的主要区别在于它们的虚拟化层面。Docker容器是在操作系统层面上进行虚拟化,共享同一内核,而虚拟机则是在硬件层面上进行虚拟化,每个虚拟机都有独立的操作系统。因此,Docker容器启动更快,资源开销更小,密度更高。
令牌桶算法来限流
用令牌桶算法来控制访问API的速率,以此来防止服务被过载。我们会为每个用户分配一个令牌桶,每次用户发起请求时,都需要从令牌桶中取出一个令牌,如果令牌不足,则请求会被限流。至于压力测试,我们使用了JMeter和Gatling等工具,通过模拟用户访问来测试服务的极限性能和稳定性。
Redis的持久化
Redis提供了两种主要的持久化方式,一种是RDB快照,另一种是AOF日志。为了保证数据库与缓存的一致性,我们可以采用延迟双删策略,在更新数据库的同时,先删除缓存,待数据库更新成功后,再次删除缓存。这样可以在大部分情况下保证数据的一致性。
Redis的**「过期删除策略」** 和**「定期删除默认检查间隔」**
Redis的过期删除策略主要包括定时删除、惰性删除和定期删除。定时删除会在键到期时立即删除,惰性删除是在访问时发现键已过期才删除,而定期删除则是每隔一段时间随机检查一些键并删除到期的键。而定期删除的默认检查间隔是10秒钟。
Redis Cluster模式
Redis Cluster是Redis的分布式解决方案,它允许我们在多个节点之间进行数据分片。每个节点存储数据的一部分,并且节点之间通过gossip协议进行通信。Redis Cluster还提供了数据的自动分片和高可用性,当一个节点失败时,其他节点可以接管其数据分片。
MapReduce的应用
使用MapReduce来处理大规模数据集。MapReduce工作的基本原理是将大的计算任务分解为小的块,然后在多个节点上并行处理。Map阶段进行数据分片和初步处理,Reduce阶段则进行数据汇总和最终处理。使用Hadoop框架来实现MapReduce,并解决了数据倾斜和资源调度等问题。
MySQL的存储引擎、 InnoDB和MyISAM
MySQL支持多种存储引擎,其中InnoDB和MyISAM是最常见的两种。InnoDB支持事务处理、行级锁定和外键,而MyISAM则不支持这些特性,它提供了全表锁定和较快的读取速度。如果是大量的插入操作,MyISAM可能会更好,因为它的插入速度通常比InnoDB快。
MySQL的四种事务隔离级别
MySQL的四种事务隔离级别分别是读未提交、读已提交、可重复读和串行化。读未提交允许事务读取未提交的数据,可能会导致脏读。读已提交只允许读取已提交的数据,可以避免脏读。可重复读保证了在同一个事务中多次读取相同的数据结果是一致的,但可能会出现幻读。而串行化是最严格的隔离级别,它通过对读写操作加锁来避免脏读、不可重复读和幻读。在可重复读级别下,MySQL通过MVCC(多版本并发控制)来实现,但MVCC并不能解决所有的幻读问题,这通常需要通过Next-Key Locks来解决。
MySQL为什么使用B+树作为索引结构
MySQL使用B+树作为索引结构的一个主要原因是它能够保持数据的平衡和排序。B+树的特点是所有的值都存在于叶子节点上,并且叶子节点之间是相互链接的,这使得范围查询非常高效。另外,因为B+树的树高较低,相对于其他树结构,如二叉搜索树,它可以减少磁盘I/O操作,提高查询速度。
索引优化,考虑使用全文索引吗?这是什么原理?
在某些情况下,比如进行文本搜索时,会考虑使用全文索引。全文索引是通过建立文档或者文本数据的反向索引来实现的,可以快速定位包含特定词汇的记录。MySQL中的全文索引通常用于MyISAM和InnoDB引擎,并且支持自然语言搜索和布尔搜索等功能。
TCP三次握手
TCP三次握手的过程是建立一个可靠的连接所必需的。首先,客户端向服务器发送一个带有SYN标志的数据包,请求建立连接。服务器接收到这个数据包后,会回复一个带有SYN和ACK标志的数据包,以确认收到了客户端的请求。最后,客户端再发送一个带有ACK标志的数据包给服务器,以确认收到了服务器的确认。这样就完成了三次握手,双方可以开始通信了。
网络层的协议、 ICMP
网络层的协议包括IP、ICMP、ARP等。ICMP(Internet Control Message Protocol)是一个网络层协议,主要用于传输控制消息,比如网络拥塞、路由器指示等。一个典型的ICMP应用是ping命令,我们用它来测试网络连通性。
IP协议是可靠的吗?UDP 又适用于哪些场景?
IP协议并不是可靠的,它只是负责将数据包从源地址发送到目标地址,但不保证数据包一定能到达,也不保证顺序。因此,TCP在传输层对IP协议提供了可靠性的增强。而UDP(User Datagram Protocol)是一个不可靠的、无连接的协议,适用于那些对即时性要求高但不要求可靠传输的场景,比如视频会议和在线游戏。
TCP的拥塞控制
TCP的拥塞控制包括四个主要的算法:慢启动、拥塞避免、快速重传和快速恢复。慢启动会从一个小的拥塞窗口开始,逐渐增加窗口大小来探测网络容量。拥塞避免则是在网络接近拥塞时减慢窗口增长的速度。快速重传会在接收到三个重复的ACK时重传丢失的数据包,而快速恢复会在重传后快速恢复发送窗口的大小。
TCP四次挥手中的TIME_WAIT状态
TCP四次挥手是用于终止一个TCP连接的过程。当一方准备关闭连接时,会发送一个FIN数据包给对方表示已经没有数据发送了,然后对方会回复一个ACK。然后,对方也会发送一个FIN数据包,等待本方的ACK。在发送最后一个ACK后,连接处于TIME_WAIT状态,这是为了确保最后一个ACK能够到达对方。如果对方没有收到ACK,它会重发FIN数据包。TIME_WAIT状态通常会持续2倍的MSL(Maximum Segment Lifetime)时间,以确保连接可靠地终止。
I/O多路复用是Linux中的什么机制?边缘触发和水平触发又有什么不同?
I/O多路复用是一种系统机制,允许一个进程监视多个文件描述符,一旦某个文件描述符就绪(例如,数据可读取或能够写入),它就能通知进程。在Linux中,select、poll和epoll都是实现这一机制的系统调用。边缘触发(ET)和水平触发(LT)是epoll的两种工作模式。水平触发会在文件描述符就绪时不断通知进程,而边缘触发只在文件描述符状态变化时通知一次,这要求进程能够一次性处理所有数据。
epoll的性能一定比select和poll更好吗?
不一定。epoll的性能在处理大量并发连接时确实比select和poll更好,因为它不需要像select和poll那样每次调用都传递整个文件描述符集合。epoll使用事件通知机制和一个文件描述符就绪列表来提高效率。但是,在只有少量连接时,select和poll的性能差异可能并不明显。
Linux系统中的文件描述符限制
可以使用ulimit命令来查看和修改文件描述符的限制。比如,ulimit -n可以查看当前shell进程的文件描述符限制,而ulimit -n 1024可以将其修改为1024。
socket和文件描述符之间的关系
在Unix和类Unix系统中,socket也是一种文件描述符。操作系统通过文件描述符来代表所有的输入输出资源,包括普通文件、管道和网络连接。每个socket在创建时都会被分配一个文件描述符,应用程序可以像操作普通文件一样操作socket,使用read、write等系统调用。
查看进程信息、 ps命令的底层实现
查看进程信息通常使用 ps 命令,例如 ps aux 可以显示系统中所有的进程信息。 ps 命令的底层实现会读取 /proc 文件系统中的信息,这个文件系统包含了系统中所有进程的详细信息,如进程ID、状态、内存使用情况等。当执行 ps 命令时,它会遍历 /proc 下的目录来收集和展示进程信息。
进程间通信
在众多进程间通信(IPC)方法中,共享内存是最快的一种方式,因为它允许进程直接读写同一块内存区域,无需任何数据传输的开销。其他如管道、消息队列、信号量和套接字等IPC机制,都涉及到数据在用户空间和内核空间之间的复制,因此速度相对较慢。
信号以及如何使用kill命令发送信号
信号是一种软件中断,用于通知进程发生了某个事件。在Unix系统中,我们可以使用kill命令来向进程发送信号。例如,kill -9会向进程ID为的进程发送SIGKILL信号,强制终止该进程。kill命令实际上可以发送各种类型的信号,不仅仅是用于杀死进程。
在操作系统中,用户态如何切换到内核态?软中断是什么?
用户态切换到内核态通常发生在进行系统调用或发生中断时。当应用程序执行系统调用,如读写文件,操作系统会通过中断门将控制权从用户态切换到内核态,以执行必要的内核级操作。软中断是一种由软件异常或显式请求引起的中断机制,它允许用户态代码触发内核态的处理流程。
人工智能
人工智能是一个非常有潜力的领域,它正在改变我们的生活和工作方式。通过学习和模拟人类智能,AI能够在数据分析、图像识别、自然语言处理等多个领域实现自动化和优化。不过,随着AI技术的发展,也需要注意到它的伦理和社会影响,确保技术的发展能够惠及社会。
MySQL 索引核心底层原理
MySQL 索引的底层数据结构是什么?
常用的就是B+树和hash索引结构,常用的 InnoDB 引擎就是 B+ 树实现的。
为什么采用B+树作为索引的首选数据结构呢?
得从B+树结构特性、MySQL底层数据页式存储、磁盘IO、Innodb 行锁并发粒度,常用查询方式等方面说。说说结构特性,B+树是一种平衡多路查找树,正是这种变种后的B树结构为它提供了先天结构优势。首先,B+树的非叶子节点不存储数据记录,只存储索引键和子节点指针;所有数据记录都存储在叶子节点上,且叶子节点间通过指针形成了一个链表。B+树的这种结构有助于提高数据的局部性原理,即最近访问的数据很可能在不久之后再次被访问。这种特性使得数据库缓存(Buffer Pool)能更高效地工作。
Buffer Pool【面试笔记】
同时数据库是以页(Page)为单位进行磁盘IO,且Innodb支持页级压缩与行锁的并发粒度的特性,让B+树成为天选结构。
1、极大减少磁盘I/O:B+树的非叶子节点不存储数据记录,只存储索引键和子节点指针,这使得每个节点可以存储更多的索引项,规定大小下(通常为一磁盘页大小),树的出度更大,则树的高度更小,这减少了查找数据时所需的磁盘I/O次数,从而提高了查询效率。
2、更适合顺序I/O :由于B+树的这种结构可以使得数据存储更加紧凑,减少了页的分裂和合并,提高了顺序读写的性能,对于聚集索引来说就是天然适配结构。
3、更好支持范围查询:由于B+树叶子节点形成了有序链表,对于执行范围查询(如BETWEEN, >, <等)非常有利,可以直接在链表上做顺序扫描,快速找到范围内的记录。
4、查询效率(时间复杂度)稳定,B+树的查询时间复杂度为O(log n),这使得即使是大规模数据集,也能在对数时间复杂度内完成查找,查询效率稳定。
适配页式存储和行锁的并发粒度
数据库通常以页(page)为单位存储数据,而 B+树 中的叶子节点通常对应一个数据页,且B+树结构在磁盘I/O、顺序I/O,范围查询的优化完美的适配页式存储;因此它可以很好地利用页空间,减少页的分裂和合并从而极大提高查询效率,可以说B+树先天适配数据库的页式存储。
这种树结构可以有效地锁定树的特定部分,而不影响其他部分的操作因此,从而很好的成就了行锁的并发粒度。
还有一个共识原因,数据访问模式高度匹配。 其实就是在数据库的查询操作中,很多都是基于主键的查找和范围扫描,B+树的结构恰好又适合这种数据访问模式。B+树成为了实现索引的首选数据结构,特别是在需要频繁进行范围查询和排序操作的应用场景中。
InnoDB 预防死锁策略
InnoDB引擎内部(或者说是所有的数据库内部),有多种锁类型:事务锁(行锁、表锁),Mutex(保护内部的共享变量操作)、RWLock(又称之为Latch,保护内部的页面读取与修改)。
InnoDB每个页面为16K,读取一个页面时,需要对页面加S锁(共享锁),更新一个页面时,需要对页面加上X锁(排他锁)。任何情况下,操作一个页面,都会对页面加锁,页面锁加上之后,页面内存储的索引记录才不会被并发修改。因此,为了修改一条记录,InnoDB内部如何处理:
-
根据给定的查询条件,找到对应的记录所在页面;
-
对页面加上X锁(RWLock),然后在页面内寻找满足条件的记录;
-
在持有页面锁的情况下,对满足条件的记录加事务锁(行锁:根据记录是否满足查询条件,记录是否已经被删除,分别对应于上面提到的3种加锁策略之一);
相对于事务锁,页面锁是一个短期持有的锁 ,而事务锁(行锁、表锁)是长期持有的锁。因此,为了防止页面锁与事务锁之间产生死锁,InnoDB做了死锁预防的策略:
-
持有事务锁(行锁、表锁),可以等待获取页面锁;
-
但反之,持有页面锁,不能等待持有事务锁。
根据死锁预防策略,在持有页面锁,加行锁的时候,如果行锁需要等待,则释放页面锁,然后等待行锁。此时,行锁获取没有任何锁保护,因此加上行锁之后,记录可能已经被并发修改。因此,此时要重新加回页面锁,重新判断记录的状态,重新在页面锁的保护下,对记录加锁。
如果此时记录未被并发修改,那么第二次加锁能够很快完成,因为已经持有了相同模式的锁。但是,如果记录已经被并发修改,那么,就有可能导致死锁问题。在数据库系统中,死锁的检测和解决通常是通过**锁管理器(Lock Manager)**来实现的。
-
当一个事务请求某个数据页的锁时,锁管理器会检查当前锁的状态以及其他事务是否持有或等待相同的锁。
-
如果存在潜在的死锁风险,系统会通过死锁检测算法来检测并解决死锁。其中,常用的死锁检测算法包括等待图(Wait-for graph)算法和超时算法。
在数据库系统的实现中,锁管理器会维护一个锁表(Lock Table),用于记录当前数据页的锁状态以及事务之间的关系。当一个事务请求锁时,锁管理器会根据锁定顺序来判断是否存在死锁风险,并根据具体情况采取相应的措施,比如阻塞等待或者回滚事务。
在数据库系统的源代码级别,锁管理器通常是数据库引擎的一部分,具体实现方式会根据不同的数据库系统而有所不同。例如,MySQL、PostgreSQL、Oracle等数据库系统都有自己的锁管理器实现,通常会涉及到并发控制、事务管理等核心模块的代码。
总之,在MySQL 5.5.5及以上版本中,MySQL的默认存储引擎是InnoDB。该存储引擎使用的是行级锁,在某种情况下会产生死锁问题,所以InnoDB存储引擎采用了一种叫作等待图(wait-for graph)的方法来自动检测死锁,如果发现死锁,就会自动回滚一个事务
死锁日志分析
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
查看加锁信息
-- information_schema.innodb_locks: 当前出现的锁
-- information_schema.innodb_trx: 当前运行的所有事务
-- information_schema.innodb_lock_waits: 锁等待的对应关系
查看InnoDB状态(包含最近的死锁日志信息):show engine innodb status;
information_schema.innodb_locks:lock_rec=4 表示是对唯一索引进行的加锁,lock_mode= X 表示这里加的是X锁。
查看死锁日志
- ACTIVE 309秒 sec : 表示事务活动时间
- starting index read : 表示读取索引
- tables in use 1: 表示有一张表被使用了
- LOCK WAIT 3 lock struct(s): 表示该事务的锁链表的长度为3,每个链表节点代表该事务持有的一个锁结构,包括表锁,记录锁以及 autoinc 锁等.
- heap size 1136 : 为事务分配的锁堆内存大小
- 3 row lock(s): 表示当前事务持有的行锁个数/gap锁的个数
死锁产生的前提和建议
前提:
-
互斥:不能共享。
-
持有并等待:当前事务保持至少一个资源,同时在等待获取其他资源。
-
不可剥夺:已获得的资源不能被强制释放,只能由获取该资源的事务主动释放。
-
循环等待:系统中若干事务之间形成了一个循环等待资源的链。
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序
建议:
-
一致性排序:
对索引加锁顺序 的不一致很可能会导致死锁,所以如果可以,尽量以相同的顺序来访问索引记录和表。在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
-
间隙锁
往往是程序中导致死锁的真凶,由于默认情况下 MySQL 的隔离级别是 RR(Repeatable Read,可重复读),所以如果能确定幻读和不可重复读对应用的影响不大,可以考虑将隔离级别改成 RC,可以避免 Gap 锁导致的死锁。
-
为表添加合理的索引, 如果不走索引将会为表的每一行记录加锁, 死锁的概率就会大大增大。
-
避免大事务 , 尽量将大事务拆成多个小事务来处理。
因为大事务占用资源多,耗时长,与其他事务冲突的概率也会变高。
-
避免在同一时间点运行多个对同一表进行读写的脚本,特别注意加锁且操作数据量比较大的语句。
-
超时和重试机制 :设置锁等待超时参数。
innodb_lock_wait_timeout,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。
我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。
线上发生死锁的操作
数据库的死锁是指不同的事务在获取资源时相互等待,导致无法继续执行的情况。MySQL中可能发生死锁的情况包括事务同时更新多个表、事务嵌套、索引顺序不一致以及不同事务同时更新相同的索引等。虽然数据库有死锁的预防策略,以及自动的处理措施。但是,在线上很多场景下, 数据的的死锁预防策略和回滚策略 , 通常达不到预期的效果。如果线上发生了死锁,我们应该采取以下步骤进行处理:
监控死锁
通过数据库的监控工具或命令查看是否存在死锁情况,了解死锁的具体情况,包括死锁的事务和死锁的资源。
step1:查看当前正在等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
运行以上SQL语句,可以查看当前正在等待锁的事务列表。根据返回结果,可以分析哪些事务在等待哪些锁,以及等待锁的具体类型。
step2:查看当前持有的锁信息
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
运行以上SQL语句,可以查看当前数据库中的锁信息。通过分析返回结果,可以了解哪些锁正在被持有,以及锁的持有者和锁的类型。
step3:查看当前的死锁信息
SHOW ENGINE INNODB STATUS;
运行以上SQL语句,可以显示当前的InnoDB存储引擎的状态信息。其中包括死锁检测结果。如果存在死锁,可以通过分析该信息来解决死锁问题。
终止死锁事务
一旦发现死锁,需要找到造成死锁的事务,并选择其中一个事务终止。可以根据事务的执行时间、影响行数、优先级等因素进行终止决策。可以采取以下方法来解决死锁问题:
-
回滚事务:
使用以下命令回滚某个事务以解除死锁:ROLLBACK;
-
杀死进程:
使用以下命令查找引起死锁的进程:SHOW PROCESSLIST;
找到引起死锁的进程ID后,使用以下命令杀死该进程:KILL <process_id>;
重试事务
终止死锁事务后,需要重新执行被终止的事务。重试事务之前,需要调整事务顺序。这可能需要一些逻辑处理,例如对数据进行回滚或者重新执行一些操作。
防止死锁再次发生
通过数据库的日志和监控信息,分析死锁的原因。可以根据死锁原因对数据库的设计和代码进行优化,以尽量减少死锁的发生。根据分析结果,针对性地进行数据库结构调整、索引优化、事务隔离级别调整等措施,以降低死锁的概率。
字符串类型不能忽视的问题
在MySQL中,字符串类型有CHAR、VARCHAR、BINARY、BLOB、TEXT、ENUM、SET。不同的类型,在业务设计、数据库性能方面有完全不同的表现,其中我们使用最多的应该是CHAR、VARCHAR。
CHAR和VARCHAR的定义
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,N 表示的是字符,而不是字节。VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字符。这里有个情况要注意:在字符串存储的长度超过65536情况下,可以使用TEXT和BLOB来存储,这两个类型的最大存储长度为4G,TEXT和BOLB两者的区别在于BLOB没有字符集属性,属于二进制存储。
MySQL与其他关系型数据库(ORACLE、SQLSERVER)不同的是,MySQL的VARCHAR字符类型最大能存储65536个字符,所以在MySQL下,很大部分场景的字符串存储,使用VARCHAR类型就足够了。
字符集
在表结构的设计中,除了设计字段的数据类型外,我们还需要定义字符的字符集,不同的字符在不同的字符集编码下,对应着不同的二进制值。常见的字符集有GBK、UTF8,通常推荐把默认字符集设置为UTF8。而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E;
排序规则
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,我们可以使用SHOW CHARSET查看:
mysql> SHOW CHARSET LIKE 'utf8%';
mysql> SHOW COLLATION LIKE 'utf8mb4%';排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。需要注意的是,比较 MySQL 字符串,默认采用不区分大小的排序规则:
mysql> SELECT 'a' = 'A';
mysql> SELECT CAST('a' as char) COLLATE utf8mb4_0900_as_cs = CAST('A' as CHAR) COLLATE utf8mb4_0900_as_cs as result;建议 :大部分的业务表结构设计无需设置排序规则为大小写敏感。
修改字符集
如果前期在表结构设计时,没有考虑字符集对业务数据存储的影响,后期需要对字符集进行转换,但修改后依然无法插入emoji这类字符时。
ALTER TABLE emoji_test CHARSET utf8mb4;这种情况是因为上述语句只是将表的字符集修改了,新增列的时候会变为utf8mb4,但对于已存在的列,其默认的字符集并不做修改。如果列 A 的字符集依然是UTF8,应该使用ALTER TABLE ... CONVERT TO...这样才能将之前的列 A 字符集从 UTF8 修改为 UTF8MB4。
业务表设计实战
用户性别字段设计
在用户表设计时,通常会遇到固定选项值的字段,比如性别(SEX),选项有男、女、未知。状态(state),选项有正常、禁用等状态。但在日常设计时,常可以看到有些技术人员把这类字段设计为INT型去存储。tinyint 列 sex 表示用户性别,但这样设计问题比较明显。
-
表达不清:在具体存储时,0 表示女,还是 1 表示女呢?每个业务可能有不同的潜规则;
-
脏数据:因为是 tinyint,因此除了 0 和 1,用户完全可以插入 2、3、4 这样的数值,最终表中存在无效数据的可能,后期再进行清理,代价就非常大了。
在 MySQL 8.0 版本之前,可以使用 ENUM 字符串枚举类型,只允许有限的定义值插入。如果将参数 SQL_MODE 设置为严格模式,插入非定义数据就会报错。
由于类型 ENUM 并非 SQL 标准的数据类型,而是 MySQL 所独有的一种字符串类型。抛出的错误提示也并不直观,这样的实现总有一些遗憾,主要是因为MySQL 8.0 之前的版本并没有提供约束功能。自 MySQL 8.0.16 版本开始,数据库原生提供 CHECK 约束功能,可以方便地进行有限状态列类型的设计。
CONSTRAINT `user_chk_1` CHECK (((`sex` = _utf8mb4'M') or (`sex` = _utf8mb4'F')))
mysql> INSERT INTO User VALUES (NULL,'Z');
ERROR 3819 (HY000): Check constraint 'user_chk_1' is violated.账号密码存储设计
在数据库表结构设计时,千万不要直接在数据库表中直接存储密码,一旦有恶意用户进入到系统,则面临用户数据泄露的极大风险。比如金融行业,从合规性角度看,所有用户隐私字段都需要加密,甚至业务自己都无法知道用户存储的信息(隐私数据如登录密码、手机、信用卡信息等)。
相信不少开发人员会通过函数 MD5 加密存储隐私数据,这没有错,因为 MD5 算法并不可逆。然而,MD5 加密后的值是固定的,如密码 12345678,它对应的 MD5 固定值即为 25d55ad283aa400af464c76d713c07ad。
因此,可以对 MD5 进行暴力破解,计算出所有可能的字符串对应的 MD5 值。
所以,在设计密码存储使用,还需要加盐(salt),每个公司的盐值都是不同的,因此计算出的值也是不同的。若盐值为 psalt,则密码 12345678 在数据库中的值为:
password = MD5('psalt12345678')这样的密码存储设计是一种固定盐值的加密算法,其中存在三个主要问题:
-
若 salt 值被(离职)员工泄漏,则外部黑客依然存在暴利破解的可能性;
-
对于相同密码,其密码存储值相同,一旦一个用户密码泄漏,其他相同密码的用户的密码也将被泄漏;
-
固定使用 MD5 加密算法,一旦 MD5 算法被破解,则影响很大。
一个真正好的密码存储设计,应该是:动态盐 + 非固定加密算法。
这里推荐一个密码设计方式,password字段存储格式如下:
$salt$cryption_algorithm$value-
$salt:表示动态盐,每次用户注册时业务产生不同的盐值,并存储在数据库中。若做得再精细一点,可以动态盐值 + 用户注册日期合并为一个更为动态的盐值。
-
$cryption_algorithm:表示加密的算法,如 v1 表示 MD5 加密算法,v2 表示 AES256 加密算法,v3 表示 AES512 加密算法等。
-
$value:表示加密后的字符串。