PgSQL内核算法 | Hash Agg数据溢出写盘机制解析
PgSQL进行Hash分组聚合时,针对数据的hash key(分组键)进行hash得到hash桶,同一个分组数据在同一桶上(为简化说明排除hash冲突场景)。当数据量比较大且比较分散造成分组数比较多时,构建的hash表在内存中放不下,就会将后续的不在当前分组中的数据写到磁盘临时文件。本文解析下写临时文件聚合的原理。
1、Hash聚合流程
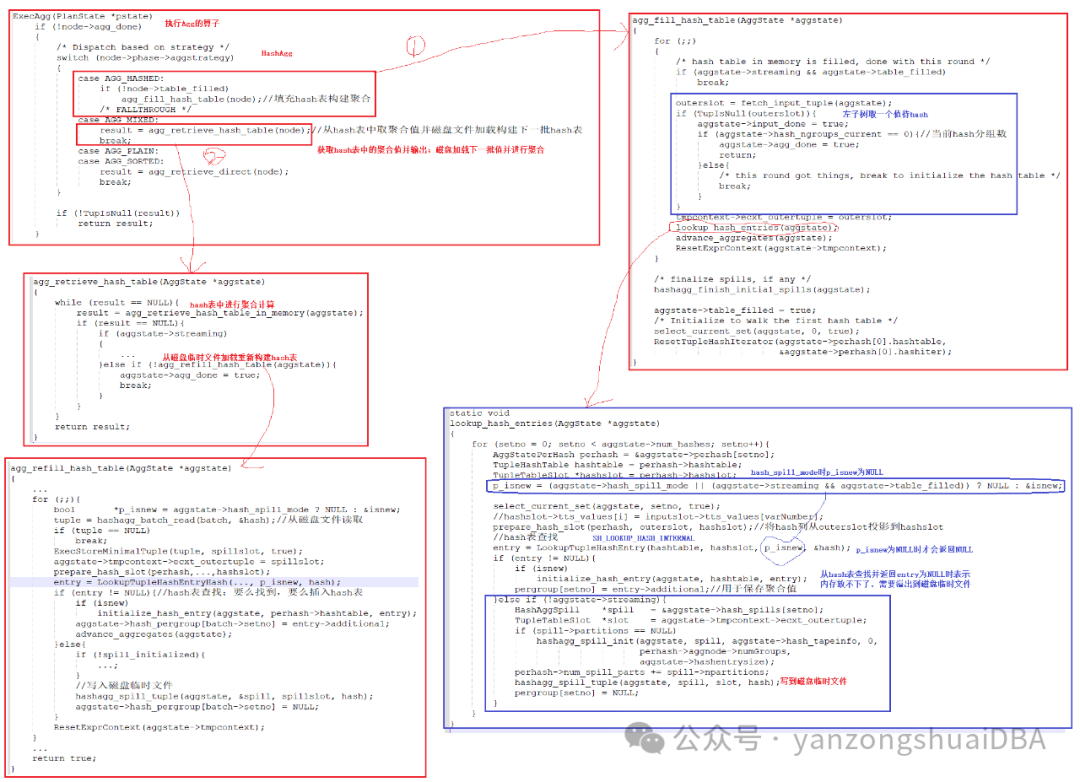
1)ExecAgg为聚合算子执行入口,分为四种聚合方式:hash agg、mixed agg(hash agg和plain/sort agg混合)、Plain agg(普通聚合)、sort agg(排序分组聚合)
2)Hash agg的构建hash表函数为agg_fill_hash_table:我们看上图的1分支
3)agg_fill_hash_table循环从聚合算子Agg左子树取一个值进入lookup_hash_entries构建hash表
4)lookup_hash_entries函数会对该记录每个hash key进行构建hash表即函数内for循环num_hashes次:主要关注p_isnew,当hash_spill_mode为true时,标记它为NULL。若为NULL则LoockupTupleHashEntry从hash表查找时,若没有找到并且内存不够时才会返回NULL;若返回NULL,则通过hashagg_spill_tuple将该tuple的targetlist+qual+hash key列写到磁盘临时文件。这里留个问题:hash_spill_mode何时为true?
5)返回ExecAgg函数,接着分析2分支:agg_retrieve_hash_table
6)agg_retrieve_hash_table先从agg_retrieve_hash_table_in_memory内存的hash表进行hash聚合计算,计算完后,再调用agg_refill_hash_table从临时文件加载记录重新构建hash表
7)agg_refill_hash_table中可以看到,重新构建hash表的过程中,内存再次不够用时,仍旧会将之后未在当前分组的记录写入磁盘临时文件:hash_agg_spill_tuple
2、什么时候hash_spill_mode为true
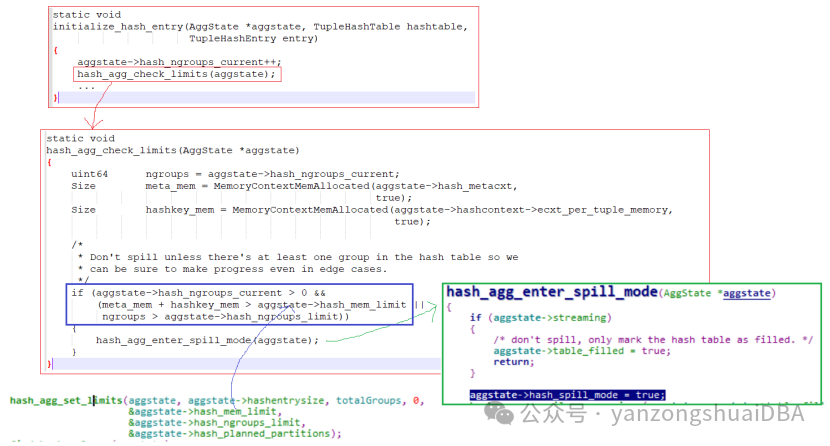
lookup_hash_entries调用LookupTupleHashEntry时,若返回entry不为NULL并且isnew为true即成功向hash表插入了一条entry,则调用initialize_hash_entry函数:
1)每次向hash表成功插入一条entry都会调用hash_agg_check_limits进行一次内存交验
2)hash_ngroups_current>0即当前要有分组值
3)meta_mem+hashkey_mem(hash表已使用的内存) > hash_mem_limit或者分组数ngroups > hash_ngroups_limit则将hash_spill_mode置为true
4)上述几个阈值来自hash_agg_set_limits计算:
cpp
void
hash_agg_set_limits(AggState *aggstate, double hashentrysize, double input_groups, int used_bits,
Size *mem_limit, uint64 *ngroups_limit,
int *num_partitions)
{
int npartitions;
Size partition_mem;
uint64 strict_memlimit = work_mem;
if (aggstate)
{
uint64 operator_mem = PlanStateOperatorMemKB((PlanState *) aggstate);
if (operator_mem < strict_memlimit)
strict_memlimit = operator_mem;
}
/* if not expected to spill, use all of work_mem */
if (input_groups * hashentrysize < strict_memlimit * 1024L)
{
if (num_partitions != NULL)
*num_partitions = 0;
*mem_limit = strict_memlimit * 1024L;
*ngroups_limit = *mem_limit / hashentrysize;
return;
}
/*
* Calculate expected memory requirements for spilling, which is the size
* of the buffers needed for all the tapes that need to be open at
* once. Then, subtract that from the memory available for holding hash
* tables.
*/
npartitions = hash_choose_num_partitions(aggstate,
input_groups,
hashentrysize,
used_bits,
NULL);
if (num_partitions != NULL)
*num_partitions = npartitions;
partition_mem =
HASHAGG_READ_BUFFER_SIZE +
HASHAGG_WRITE_BUFFER_SIZE * npartitions;
/*
* Don't set the limit below 3/4 of work_mem. In that case, we are at the
* minimum number of partitions, so we aren't going to dramatically exceed
* work mem anyway.
*/
if (strict_memlimit * 1024L > 4 * partition_mem)
*mem_limit = strict_memlimit * 1024L - partition_mem;
else
*mem_limit = strict_memlimit * 1024L * 0.75;
if (*mem_limit > hashentrysize)
*ngroups_limit = *mem_limit / hashentrysize;
else
*ngroups_limit = 1;
}