假设您拥有一台强大的计算机系统或一个应用,用于快速执行各种任务。但是,系统中有一个组件的速度跟不上其他部分,这个性能不佳的组件拉低了系统的整体性能,成为了整个系统的瓶颈。在软件领域中,瓶颈是指整个路径中吞吐量最低的部分。如果机器中的某个齿轮转得不够快,整个系统的速度都会受到影响。因此,及时识别和解决瓶颈问题的重要性不言而喻,能显著提升计算机系统和应用的效率。
在此前的文章中,我们已经介绍了评估各种向量数据库时使用的关键指标和性能测试工具。本文将以 Milvus 向量数据库为例,特别关注 Milvus 2.2 或以上版本,讲解如何监控搜索性能、识别瓶颈并优化向量数据库性能。
性能评估及监控指标
在向量数据库系统中,最常用且最重要的评估指标包括召回率(Recall)、延迟(Latency)和每秒查询数(QPS)。这些指标反映了系统的准确性、响应速度以及能够处理的请求量。
Recall
召回率是指在搜索查询中成功检索到的相关内容的比例。但是,通常并不是所有接近的向量都能被准确识别。这一不足往往源于索引算法的近似性 (除了暴搜以外)。这些算法牺牲召回率以换取速度的提升。这些索引算法的配置旨在为特定生产需求寻找一个合适的平衡。更多详细信息,请参阅milvus的文档页面:内存索引和磁盘索引。
计算召回率可能会消耗大量资源,通常由客户端完成。由于确立 Ground truth 需要大量计算,因此通常不会显示在监控仪表板上。在接下来的指南中,我们假定已经达到了一个可接受的召回率水平,且已经为向量索引选定了适当的索引参数。
Latency
延迟指的是响应速度------即从发起查询到接收到结果所需的时间,就好比水从一端流到另一端所需要的时间。较低的延迟可以确保更快的响应速度,这对于实时应用来说非常关键。
QPS
QPS 是衡量系统吞吐量的一个重要指标,它显示了系统每秒能处理的查询数量,类似于水流通过管道的流速。更高的 QPS 值意味着系统能够更有效地处理大量并发请求,这是衡量系统性能的关键因素。
QPS 和延迟之间的关系通常较为复杂。在传统数据库系统中,当 QPS 接近系统的最大容量并耗尽所有资源时,延迟往往会增加。但在 Milvus 中,系统通过批量处理查询来优化性能。这种策略减小了网络数据包的大小,并可能同时提高延迟和 QPS,从而提升系统的整体效率。
性能监控工具
我们将使用 Prometheus 来收集和分析 Milvus 性能。此外,我们还会使用 Grafana 的可视化界面来及时发现性能瓶颈问题。
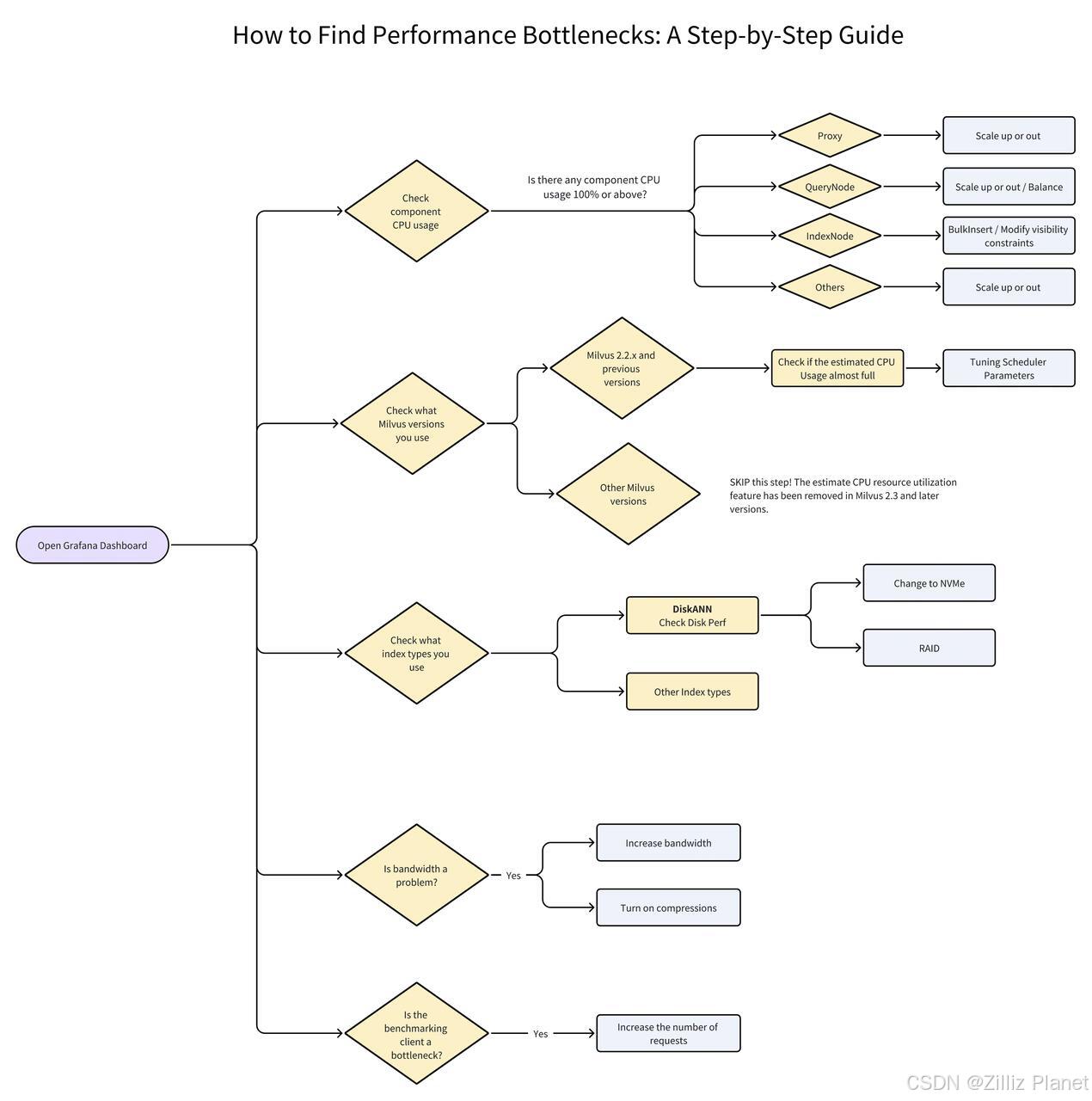
如何发现性能瓶颈
以下流程图展示了如何使用 Grafana 来有效识别性能瓶颈。图中的黄色菱形框代表需要评估的决策点,浅蓝框则提示具体操作或更多详细信息。在文章接下来的部分中,我们将指导您按照流程图所示的每一步骤监控和诊断性能问题。
前提条件
在开始监控 Milvus 向量数据库的性能之前,请先在 Kubernetes 上部署监控服务,并通过 Grafana 仪表盘对收集的指标进行可视化处理。 更多详细信息,请查阅我们的相关文档页面:
重要提示:Grafana 的最小间隔会影响性能监控结果
在开始使用 Grafana 监控 Milvus 前,需要先注意 Grafana 中的最小显示间隔(Minimum interval)可能与设定的间隔不一致。因此,经过平均处理后,图表中的一些尖峰可能会变得更加平滑,或者甚至不再可见。
为了解决这个问题:
-
点击指标名称,选择 Edit (编辑)或按下 e 键。

-
点击 Query Options(查询选项)。

-
将最小间隔(Min interval)改为 15 秒。

重要提示:NUMA 硬件会影响 Milvus 性能
非统一内存访问(NUMA)模式是多处理器系统中采用的一种内存设计方式。在 NUMA 架构下,每个 CPU 核心都直接链接到特定的内存块。访问与执行当前任务的处理器相连的本地内存要比访问连接到其他处理器的远程内存快。当处理器需要从没有直接连接的内存块中获取数据时,因为路径较长,将会产生额外的延迟。
在 NUMA 架构的机器上部署 Milvus 时,推荐使用 numactl、cpuset 或类似的工具来分配 Milvus 组件,以保证处理器的亲和性(affinity)。例如,Sapphire Rapids 处理器通常每个 NUMA 节点包含 32 核心,而传统的处理器通常每节点有 16 核心。可以通过在实例上执行 lscpu 命令来确认这一点。
现在,我们可以开始监控 Milvus 的性能,并查找可能存在的性能瓶颈。
1.打开 Grafana 仪表盘
成功在 Kubernetes 上部署监控服务并通过 Grafana 可视化指标之后,请打开 Grafana 仪表盘,如下所示。
注意:本文中,我们采用 Grafana V2 来进行性能监控和瓶颈分析。如果你使用的是 Grafana V1,监控流程可能会有所不同。
2.检查每个组件的 CPU 用量
我们需要检查几个关键组件(Proxy、QueryNode、IndexNode 等)的 CPU 使用情况。要查看每个组件的 CPU 用量,先展开"Overview"(概览)然后选择"CPU usage"(CPU 使用率)。
 注意:
注意:
-
当使用 Milvus 监控 CPU 使用率时,监控数据是在 pod 级别获取的。运行 Standalone Milvus 会显示一条单独的线,代表该 pod 的 CPU 使用情况。运行分布式 Milvus 则可以查看多个 pod 的 CPU 使用情况。在图表中,可以通过一个明显的浅蓝色线条识别 Proxy 的 CPU 使用率,该线条触及上限阈值时,表示已达到 CPU 上限。
-
如果面板丢失,且在"Service Quality"(服务质量)下找不到任何图表,您可以:
-
查看"Runtime "(运行时)下的 CPU Usage 。这里显示的是 Kubernetes 的单位使用情况,而非百分比。

-
或添加 pod 用量面板。点击 "Add"(添加)按钮并选择"Visualization"(可视化)。
-
输入 PromQL 查询。
sum(rate(container_cpu_usage_seconds_total{namespace="$namespace",pod=~"$instance-milvus.*",image!="",container!=""}[2m])) by (pod, namespace) / (sum(container_spec_cpu_quota{namespace="$namespace",pod=~"$instance-milvus.*",image!="",container!=""}/100000) by (pod, namespace))
- 选择"Unit"(单位)。

- 保存设置。
Proxy
当 QPS 较高并且执行网络密集型任务时,如搜索 Top-K 较大、启用 Partition key 以及在输出字段返回向量等,Proxy 可能会成为瓶颈。
如何解决这个问题?
要解决这个问题,您可以:
-
垂直扩展 Proxy:增加主机的 CPU/内存
-
水平扩展:增加更多 Proxy pods,并在前端使用负载均衡器(Load balancer)
QueryNode
如果查询节点(QueryNode)的性能受到 CPU 使用率的限制,可能有几个原因,您可以根据以下流程图所示的指示进行操作。
如果某个查询节点的 CPU 使用率达到 100%,如图所示,它可能承担了分发器(Delegator)的角色。
在 Milvus 中,Delegator 的作用类似于军队的指挥官。当搜索请求提交给 Proxy 时,Proxy 首先将请求发送至 Delegator,随后再将其分发到其他 QueryNode 并开始在各个 Segment 上执行搜索。搜索结果将按反向顺序返回。您可以通过选择:QueryNode > DML virtual channel 来验证 QueryNode 是否承担了 Delegator 的角色。
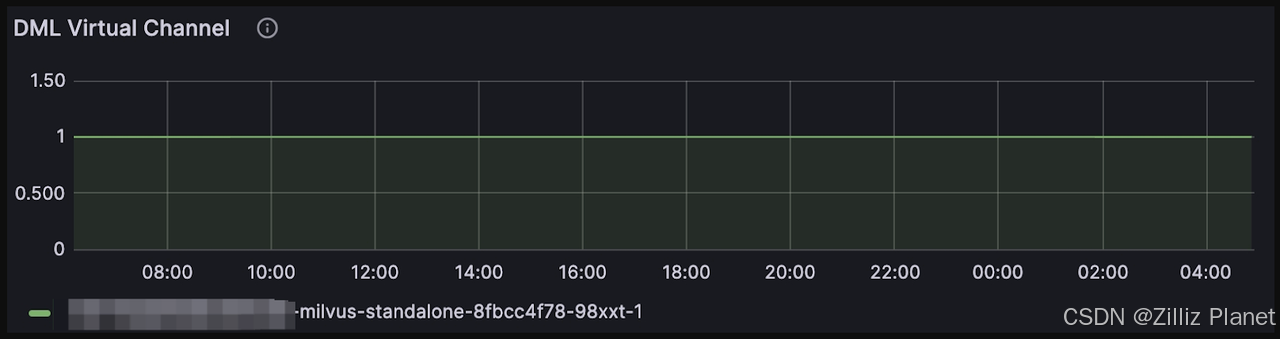
要查看段 Segment 的整体分布情况,请在仪表盘上选择"Query(查询) > Segment Loaded Num(已加载 Segment 数量)"。

如何解决这个问题?
基于您所插入的数据量,维护如此之多的 QueryNode 是否必要?过多的 QueryNode 可能导致 Delegator 需要处理更多的消息,从而降低整体性能。因此,缩减 QueryNode 的数量可能有助于减轻 Delegator 的负担。
另外,还可以考虑垂直扩展 QueryNode------这包括增加托管 QueryNode 的单个 pod 或实例的计算资源,例如 CPU 和内存。这样的调整能够显著提升处理能力,而不增加 Delegator 承担的消息负载。
如果您的数据库是静态的,可以通过手动将数据 Segment 平衡到其他查询节点来解决这个问题,这样 Delegator 就不进行 Segment 搜索,只专注于请求的分发和结果的简化。实施步骤包括:
-
在 Milvus 的 YAML 文件中关闭
autoBalance功能。 -
通过 SDK 调用
LoadBalanceAPI。参见:均衡查询负载。
如果您关闭了 autoBalance 并且向数据库中添加了新的向量,您可能需要重新触发 LoadBalance。
注意:如果您已经按照上述步骤操作,但 Delegator 仍是性能瓶颈,那么请通过 GitHub 提交问题或直接与我们联系。
IndexNode
当 IndexNote 的 CPU 使用率达到 100% 时,通常是因为 IndexNodes 正在创建索引。如果搜索请求不紧急且新数据的输入暂时中断,建议让 IndexNode 完成索引创建的过程。这样做可以确保在开始任何搜索操作之前,所有的索引都已创建成功。在数据插入的同时进行搜索查询可能会显著降低搜索性能。性能下降的程度受到多种因素的影响,包括您插入向量的方式以及您是否希望在插入后立即返回这些新插入的向量。
如何解决这个问题?
我们提供一些策略可以最小化影响:
-
如果条件允许,建议采用批量插入而不是单个插入向量。这可以减少网络传输并绕过"Growing segment",从而加速数据插入和搜索。更多相关信息,请参考 Bulk insert 文档。
-
如果不要求数据即时可见,可以考虑以下建议:
-
忽略 Growing segments;在搜索参数中使用
ignore_growing,具体方法请参考 https://milvus.io/docs/search.md。 -
在 API 调用是将搜索的一致性等级(Consistency level)设置为
Eventually。更多详情,请参考 https://milvus.io/docs/consistency.md。
-
其他组件
在 Milvus 的架构中,MixCoord、DataNode 等组件用于高效执行各自的任务,通常不会成为搜索性能的瓶颈。但是,如果监控结果表明这些组件的 CPU 利用率接近或达到满载,暗示可能出现瓶颈,那么请立即扩展这些组件。
3.检查使用的 Milvus 版本
如果您使用的是 Milvus 2.3.x 或以上版本,请跳过此步骤。
Milvus 2.2.x 及以下版本允许用户估算其 CPU 资源消耗,但这一功能在 Milvus 2.3.x 及后续版本中已被删除,因为它可能导致性能问题。
下方图表的 y 轴表示 CPU 数量与百分比的乘积,例如,12个 CPU 的完全利用率在 y 轴上的显示值为1200。
说明:这种估算有时可能会错误地表现为 CPU 的忙碌程度,导致实际 CPU 使用率较低时仍发生任务排队。
如何解决这个问题?
建议将 queryNode.scheduler.cpuRatio 的值调低,其默认值为10.0。
4.检查磁盘性能
如果您在创建索引时选择使用 DiskANN,请检查磁盘性能。
对于 DiskANN 索引类型,推荐使用 NVMe SSD。在 SATA SSD 或 HDD 上创建和搜索磁盘索引可能会因为 I/O 操作受限而导致较大的 Latency 和较低的 QPS。
如需检测磁盘性能,您可以使用 fio 或其他类似的 I/O 性能测试工具来评估 IOPS。一个 NVMe SSD 的 IOPS 应接近 500k。
# Write Test
fio -direct=1-iodepth=128 -rw=randwrite -ioengine=libaio -bs=4K -size=10G -numjobs=10 -runtime=600 -group_reporting -filename=/fiotest/test -name=Rand_Write_IOPS_Test
# Read Test
fio --filename=/fiotest/test --direct=1 --rw=randread --bs=4k --ioengine=libaio --iodepth=64 --runtime=120 --numjobs=128 --time_based --group_reporting --name=iops-test-job --eta-newline=1 --readonly在 Grafana 中查看 pod 级别的 IOPS:
-
在右上角,点击"Pod",然后选择"Kubernetes / Compute Resources / Pod"。如果您在使用 V2 仪表盘,请点击"Milvus2.0"。

-
选择您想要检查的 pod:

-
向下滚动并找到"Storage IO"。

如何解决这个问题?
-
考虑将 SATA SSD 或 HDD 升级到 NVMe SSD,以降低您当前系统的 Latency。多数云服务提供商,例如 AWS,提供 NVMe SSD 的存储选项。比如,AWS 的 m6id 实例在 m6 系列中就配备了基于 NVMe 的本地 SSD。但需要注意的是,虽然 EBS 采用 NVMe 驱动,但其提供的低延迟优势并不及本地 NVMe SSD。
-
在磁盘索引方面,我们强烈建议选择 NVMe SSD。如果您目前使用的是 SATA SSD 或 HDD,将它们配置为 RAID(独立磁盘冗余阵列)可以帮助减少延迟。
5.检查带宽
带宽限制往往会在系统中形成关键瓶颈,但这种挑战可能往往不会立即显现------可能会出现系统性能提升但 QPS 仍然不变的情况,或者像 gRPC 操作执行时间意外延长这样的间接效果。
理解带宽在这些场景中的角色对于诊断和解决性能限制是至关重要的。例如,在查询维度为 1024 且 TopK 设为 100 的 KNN 搜索请求中,每个请求可能消耗大约 4.8 KB,用于客户端与代理之间的双向通信。1000 的 QPS 意味着大约 4.7 MB的数据通过通道传输。因此,带宽至少应能支持 37 Mbps,以避免拉低 QPS。

虽然初看可能不觉得重要,但提高每秒查询数(QPS)或在输出字段中加入向量会大幅增加所需带宽。举个例子,如果输出字段需要包含向量,上述例子中需要的带宽会上升至至少 3 Gbps。
尽管进行这些计算可能比较繁琐,但使用 Grafana 这类监控工具可以帮助检查进出带宽,有效评估系统性能。

注意:如果您以集群模式部署Milvus,请不要忘记检查Milvus pods之间的带宽。
下图仅显示proxy的网络使用情况:
如何解决这个问题?
-
增加带宽
为了应对带宽限制,您可以考虑通过云平台控制台增加带宽,或联系云服务提供商或 DevOps 团队以获得支持。
-
启用压缩
我们正在 Milvus 中开发一项新功能,该功能将支持在 Milvus 各组件间以及 Milvus 与 SDK 客户端间实施 gRPC 压缩。通过压缩数据,能够显著降低数据量,虽然这可能因编解码过程而增加 CPU 使用率。预计该功能将在 Milvus 2.4.x 版本中推出,敬请期待!
6.检查性能测试客户端
设想这样一个场景:一个水龙头慢慢地向一根大水管滴水。如果水龙头的出水量很小,那么它将永远无法达到水管的最大容量。同理,当一个客户端每秒只发送少数几个请求时,它无法充分发挥 Milvus 处理大量数据的能力。为了验证客户端是否是性能瓶颈,您可以尝试以下方法:
-
增加并发数,查看是否有差异。
-
在不同的计算机或主机上部署多个客户端进行测试。
如何解决这个问题?
如果发现客户端是性能瓶颈,请考虑增加请求的数量。
-
检查并调整可能限制数据流的网络限制器。
-
如果您使用 PyMilvus:
a.在多进程操作中,选择使用 spawn 方法而非 fork。
b.在每一个进程中,执行以下操作:导入 from pymilvus import connections,然后运行 connections.connect(args)。
3.进行水平扩展------增加客户端数量,直至 QPS 值稳定。
联系我们
我们希望这份指南能够帮助您充分提升 Milvus 性能!但如果您无法定位性能瓶颈或在解决性能问题时需要帮助,欢迎随时联系我们。我们随时准备帮助您突破这些挑战!
欢迎通过以下方式联系我们:
点击下方链接,立即体验Zilliz Cloud:
Zilliz Cloud 向量数据库?utm_source=csdn