Word 文档处理
概述
本报告详细分析了 Dify 项目中知识库对 Word 文档的处理流程,包括文档上传、解析、分段和索引的完整过程。
架构设计
Dify 采用分层架构处理 Word 文档:
- API 控制器层: 负责接收文档上传请求
- 服务层: 处理业务逻辑和流程编排
- 文档处理层: 负责文档内容提取
- 索引处理层: 负责文档分段和索引
- 存储层: 负责数据持久化
Word 文档处理流程
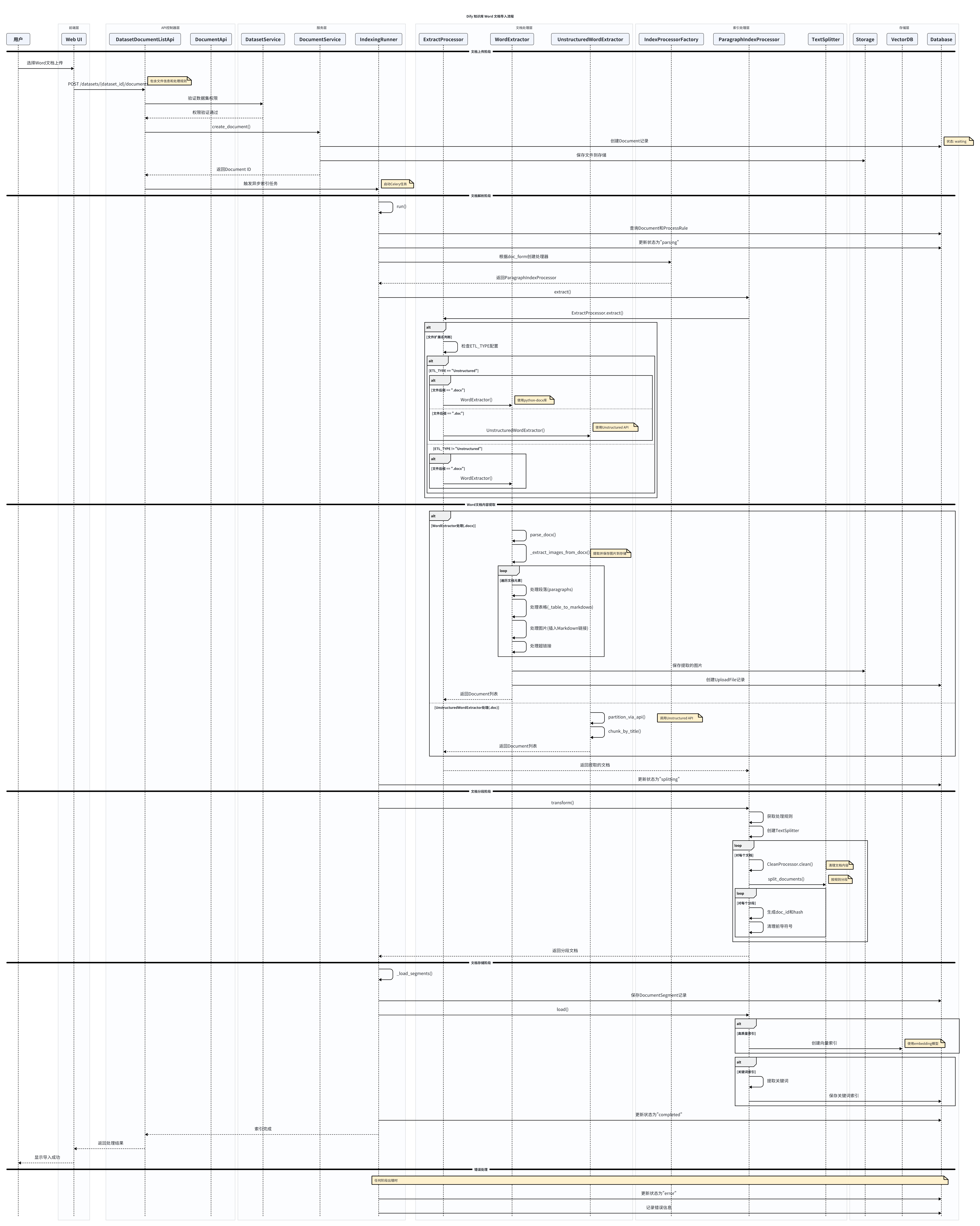
1. 文档上传阶段
- 入口 :
DatasetDocumentListApi接收 POST 请求 - 验证 : 通过
DatasetService验证用户权限 - 存储: 将文件保存到配置的存储系统(本地/云存储)
- 记录 : 在数据库中创建
Document记录,初始状态为 "waiting"
2. 文档解析阶段
2.1 提取器选择
根据 ETL_TYPE 配置和文件扩展名选择合适的提取器:
对于 .docx 文件:
- 使用
WordExtractor(基于 python-docx 库) - 支持本地处理,无需外部 API
对于 .doc 文件:
- 使用
UnstructuredWordExtractor - 需要调用 Unstructured API
- 需要配置
UNSTRUCTURED_API_URL和UNSTRUCTURED_API_KEY
2.2 WordExtractor 详细功能
核心方法 : parse_docx()
支持的内容类型:
- 文本段落: 提取段落文本,保持格式
- 表格: 转换为 Markdown 表格格式
- 图片:
- 提取嵌入的图片
- 支持外部链接图片
- 保存到存储系统
- 在文档中插入 Markdown 图片链接
- 超链接: 转换为 Markdown 链接格式
图片处理流程:
python
# 提取图片 -> 生成UUID -> 保存到存储 -> 创建UploadFile记录 -> 生成预览链接
image_map[rel.target_part] = f""表格处理:
- 计算总列数
- 处理合并单元格
- 转换为标准 Markdown 表格格式
3. 文档分段阶段
- 状态更新: 文档状态更新为 "splitting"
- 内容清理 : 使用
CleanProcessor清理文档内容 - 分段处理: 根据处理规则进行文档分段
- 支持自动分段和自定义分段
- 可配置最大 token 数、重叠长度、分隔符等
分段器类型:
FixedRecursiveCharacterTextSplitter: 固定字符分段EnhanceRecursiveCharacterTextSplitter: 增强递归分段
4. 索引创建阶段
- 向量索引: 对于高质量索引,创建向量嵌入
- 关键词索引: 提取并保存关键词索引
- 状态更新: 文档状态更新为 "completed"
核心类和方法
主要类
- IndexingRunner: 核心索引运行器
run(): 执行完整索引流程_extract(): 文档内容提取_transform(): 文档转换和分段_load(): 索引创建和存储
- WordExtractor: Word 文档提取器
parse_docx(): 解析 docx 文件_extract_images_from_docx(): 提取图片_table_to_markdown(): 表格转 Markdown
- ExtractProcessor: 提取处理器工厂
- 根据文件类型选择合适的提取器
- 支持多种文档格式
配置参数
ETL_TYPE: 提取类型(Unstructured/默认)UNSTRUCTURED_API_URL: Unstructured API 地址UNSTRUCTURED_API_KEY: Unstructured API 密钥INDEXING_MAX_SEGMENTATION_TOKENS_LENGTH: 最大分段长度
错误处理
- 文档暂停 :
DocumentIsPausedError - Provider 错误 :
ProviderTokenNotInitError - 通用错误: 更新文档状态为 "error",记录错误信息
存储和数据模型
数据库表
- Dataset: 数据集信息
- Document: 文档记录
- DocumentSegment: 文档分段
- UploadFile: 上传文件记录
- DatasetProcessRule: 处理规则
文档状态流转
waiting -> parsing -> splitting -> indexing -> completed
-> error (任何阶段)优势和特点
- 多格式支持: 同时支持 .docx 和 .doc 格式
- 丰富内容提取: 支持文本、图片、表格、超链接
- 灵活配置: 支持自定义分段规则
- 错误恢复: 完善的错误处理和状态管理
- 异步处理: 使用 Celery 进行异步索引
- 图片处理: 自动提取和存储文档中的图片
性能考虑
- 内存管理: 使用临时文件处理大文档
- 并发控制: 异步任务队列避免阻塞
- 存储优化: 图片和文档分离存储
- 索引策略: 支持向量和关键词两种索引方式