本文档将对gd32ai-modelzoo中的使用方法进行更加细致的介绍。并对原博主提供的gd32ai-modelzoo部分代码进行了修改,使其可以更加顺利地运行。
原开源工程地址 :https://github.com/HomiKetalys/gd32ai-modelzoo
原作者博客 :https://mbb.eet-china.com/forum/topic/140687_1_1.html本文档开源工程地址 :https://download.csdn.net/download/qq_44897194/89569963
阅读此文当前,请先仔细阅读gd32ai-modelzoo\object_detection\yolo_fastestv2目录中的README.md文件和原作者的博客,其中包含了目标检测工程的详细使用步骤。此文档只用于自己移植使用过程中的补充说明。并且此文档之研究了目标检测的代码,没有对分类任务的代码进行调整。
★★★后续文档中出现的代码指令或者python文件,若其中出现路径,都需要根据自己的实际路径进行修改。此点后续不再说明!!!
STEP1:下载GD32AI工程文件(推荐在Windows中进行)
★以下针对原gd32ai-modelzoo开源项目。若使用该修改后的工程可直接下载。
▲1. 安装GIT
▲2. 通过GIT CMD打开命令窗口
▲3. cd 命令定位到待保存的目录
▲4. 使用命令进行下载
shell
git clone https://github.com/HomiKetalys/gd32ai-modelzoo▲5. 使用命令初始化和更新工程中的部分文件(该项必须使用,否则工程不完整)。
shell
git submodule update --init --recursive完成后会发现,工程中的
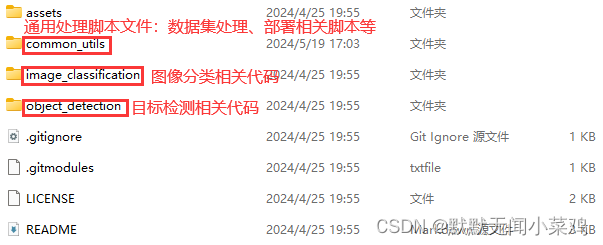
gd32ai-modelzoo\common_utils\facelandmarks文件夹
gd32ai-modelzoo\common_utils\onnx2tflite文件夹
gd32ai-modelzoo\image_classfication\submodules\ml_fastvit文件夹
gd32ai-modelzoo\object_detection\submodules\Yolo_FastestV2文件夹
均被更新并已下载完相关文件。
若使用本文档配套代码,则不需要上述第5个指令,直接下载所有文件即可。
STEP2.1:下载和处理数据集(需要与训练时所用系统相同)
▲1. 从COCO数据集官网进行下载:https://cocodataset.org/#download
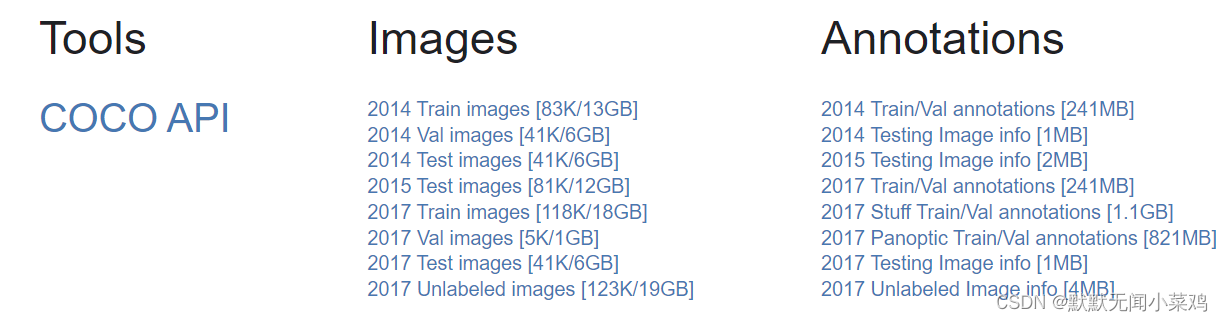
点击官网最上方的文件即可下载对应数据集文件:
我们只需要下载:

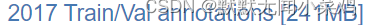
共3个文件。
(若直接点击无法下载,可能是被拦截,将其拖入新的标签页即可)
下载完整后,将其复制进想要保存的文件夹中,直接解压3个压缩包;
目录结构如下(略微进行了调整,删去了image文件夹):
COCO2017
├── train2017
│ ├──000000000009.jpg
| ...
│ └──000000581929.jpg
├── val2017
│ ├──000000000139.jpg
| ...
│ └──000000581781.jpg
└── annotations
├── instances_train2017.json
└── instances_val2017.json▲2. 使用工程中的脚本文件gd32ai-modelzoo\common_utils\coco2yolo.py对数据集进行格式转换,
仔细观察COCO数据集文件结构和下方指令,补充好指令中"···"处的路径。
(特别注意:推荐输出保存的路径与原图片路径一致,否则之后的训练指令可能报错:数据集图片路径无法找到)
shell
1.训练集转换
python coco2yolo.py --images_path "../../datasets/COCO2017/coco80/train2017" --json_file "../../datasets/COCO2017/coco80/annotations/instances_train2017.json" --ana_txt_save_path "../../datasets/COCO2017/coco80/train2017" --out_txt_path "../../datasets/COCO2017/coco80/train2017.txt"
2.验证集转换
python coco2yolo.py --images_path "../../datasets/COCO2017/coco80/val2017" --json_file "../../datasets/COCO2017/coco80/annotations/instances_val2017.json" --ana_txt_save_path "../../datasets/COCO2017/coco80/val2017" --out_txt_path "../../datasets/COCO2017/coco80/val2017.txt"也可以直接修改coco2yolo.py文件中的相关路径,然后直接运行指令 python coco2yolo.py
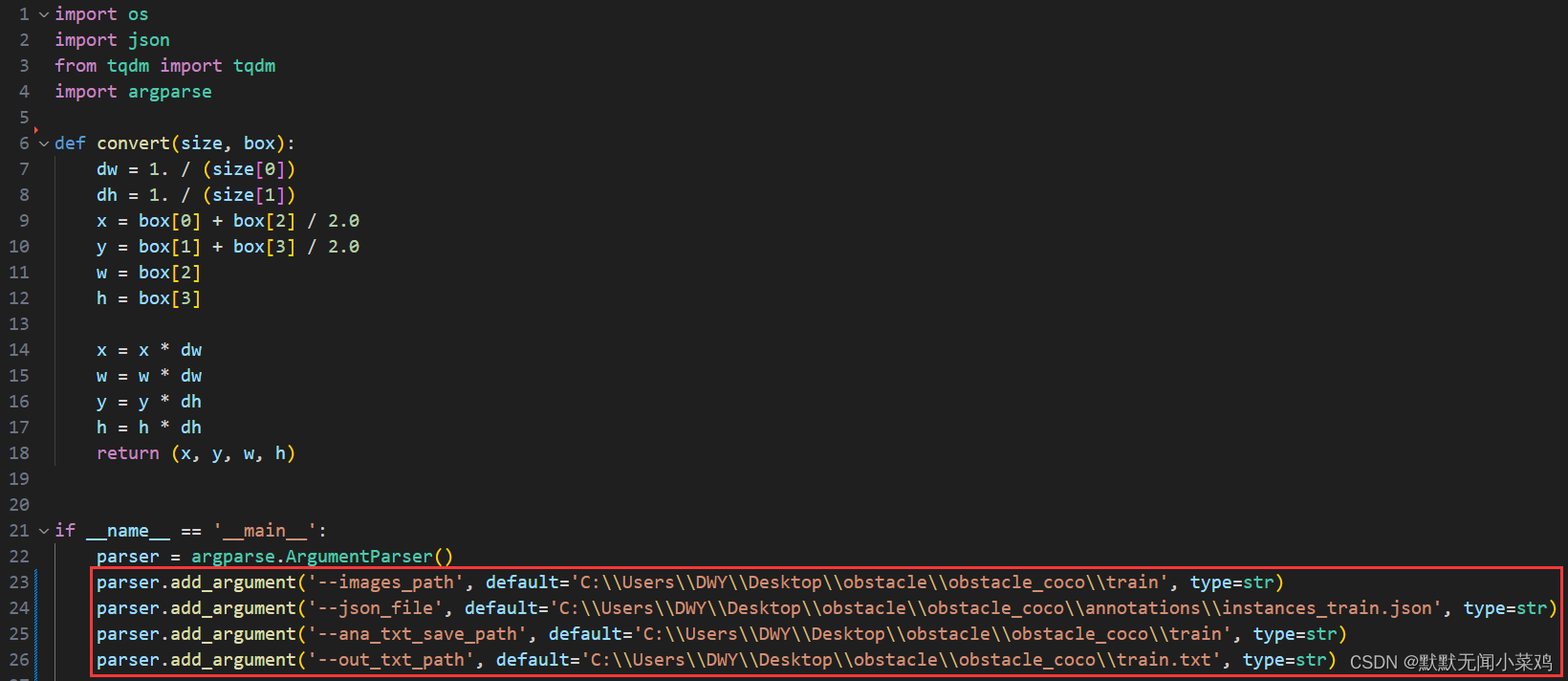
使用成功后就会发现,原数据集中多出了train2017.txt和val2017.txt两个文本文件,其中分别保存了数据集和验证集的原始图片路径;并且原数据集图片所在目录中,多出了保存每张图片对应标签的文本文件。
Windows指令:
shell
python coco2yolo.py --images_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\train" --json_file "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\annotations\instances_train.json" --ana_txt_save_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\train" --out_txt_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\train.txt"
python coco2yolo.py --images_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\val" --json_file "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\annotations\instances_val.json" --ana_txt_save_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\val" --out_txt_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\val.txt"Linux指令
shell
python coco2yolo.py --images_path "/home/dwy/test/datasets/obstacle_coco/train" --json_file "/home/dwy/test/datasets/obstacle_coco/annotations/instances_train.json" --ana_txt_save_path "/home/dwy/test/datasets/obstacle_coco/train" --out_txt_path "/home/dwy/test/datasets/obstacle_coco/train.txt"
python coco2yolo.py --images_path "/home/dwy/test/datasets/obstacle_coco/val" --json_file "/home/dwy/test/datasets/obstacle_coco/annotations/instances_val.json" --ana_txt_save_path "/home/dwy/test/datasets/obstacle_coco/val" --out_txt_path "/home/dwy/test/datasets/obstacle_coco/val.txt"STEP2.2:采集自己的数据集(推荐在Windows中进行)
▲1. 采集图片,可选择任意方式进行数据集图片采集,包括但不限于网络爬取、手机怕拍照采集、实际工程所用的摄像头采集。(若使用实际工程所用的摄像头进行采集,例如需要使用STM32 + OV5640进行识别,则可通过STM32的照相机实验进行图片采集,并保存到SD卡中)
▲2. 导出SD卡中的图片。(若使用STM32采集,则可能保存的时BMP格式图片,需要使用软件或脚本转换成JPG格式图片,此过程可自行百度。本工程使用的是迅捷图片转换软件:需要会员)
▲3. 创建数据集所需的文件夹结构,并存入原始JPG图片,文件夹结构目录如下(此处可自行设计):
OBSTACLE2024
├── obstacle_coco (与COCO数据集格式相同)
│ ├── annotations (最后的COCO格式标签文件夹)
│ ├── train (训练集图片文件夹)
│ └── val (验证集图片文件夹)
│
└── obstacle_labelme (原始labelme所需文件夹结构)
├── raw_picture (原始所有未划分的JPG图片)
├── labelmejson_train (训练集labelme标签文件夹)
├── labelmejson_val (验证集labelme标签文件夹)
├── train (训练集图片文件夹)
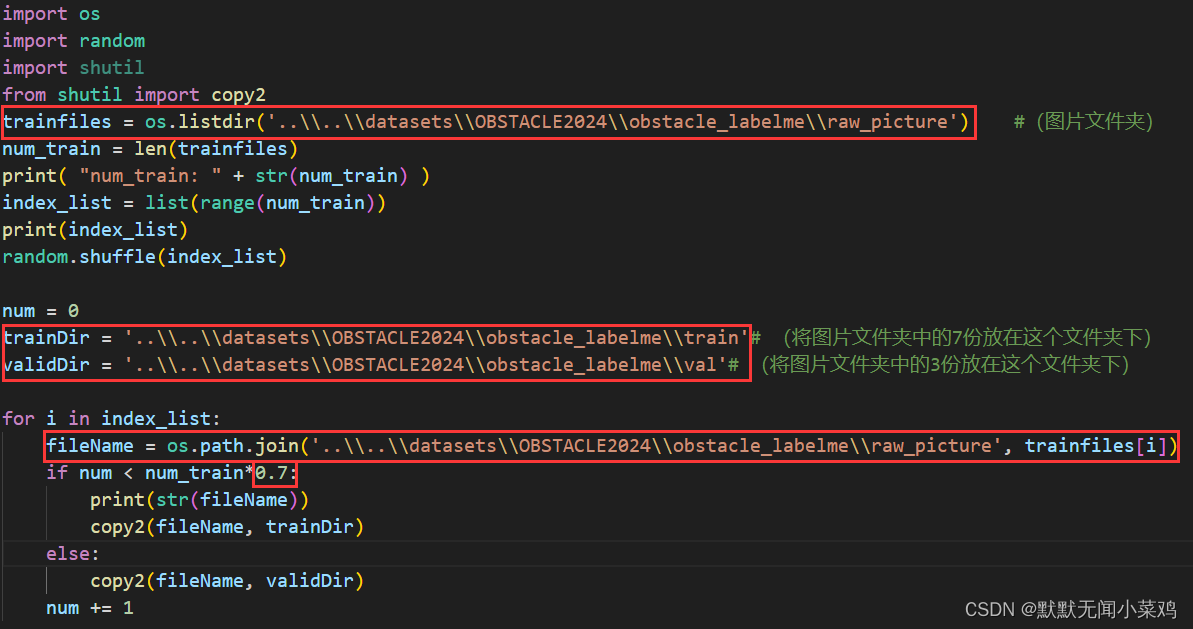
└── val (验证集图片文件夹)▲4. 把采集到的原始图片全部复制到raw_picture文件夹中,进入gd32ai-modelzoo/common_utils文件夹,并运行指令:
shell
python picture_divide.py把原始图片按比例划分为训练集和验证集,并分别保存到OBSTACLE2024/obstacle_labelme/train和OBSTACLE2024/obstacle_labelme/val路径下(注意修改picture_divide.py中的路径和划分比例)
▲5. 使用labelme软件进行标签制作(该软件使用难度不大,网上有很多安装和使用教程)。
- 训练集标注:设置打开目录为OBSTACLE2024/obstacle_labelme/train;设置输出目录为OBSTACLE2024/obstacle_labelme/labelmejson_train。
- 验证集标注:设置打开目录为OBSTACLE2024/obstacle_labelme/val;设置输出目录为OBSTACLE2024/obstacle_labelme/labelmejson_val。
▲6. 标注完成后,进入gd32ai-modelzoo/common_utils文件夹,并运行指令:
shell
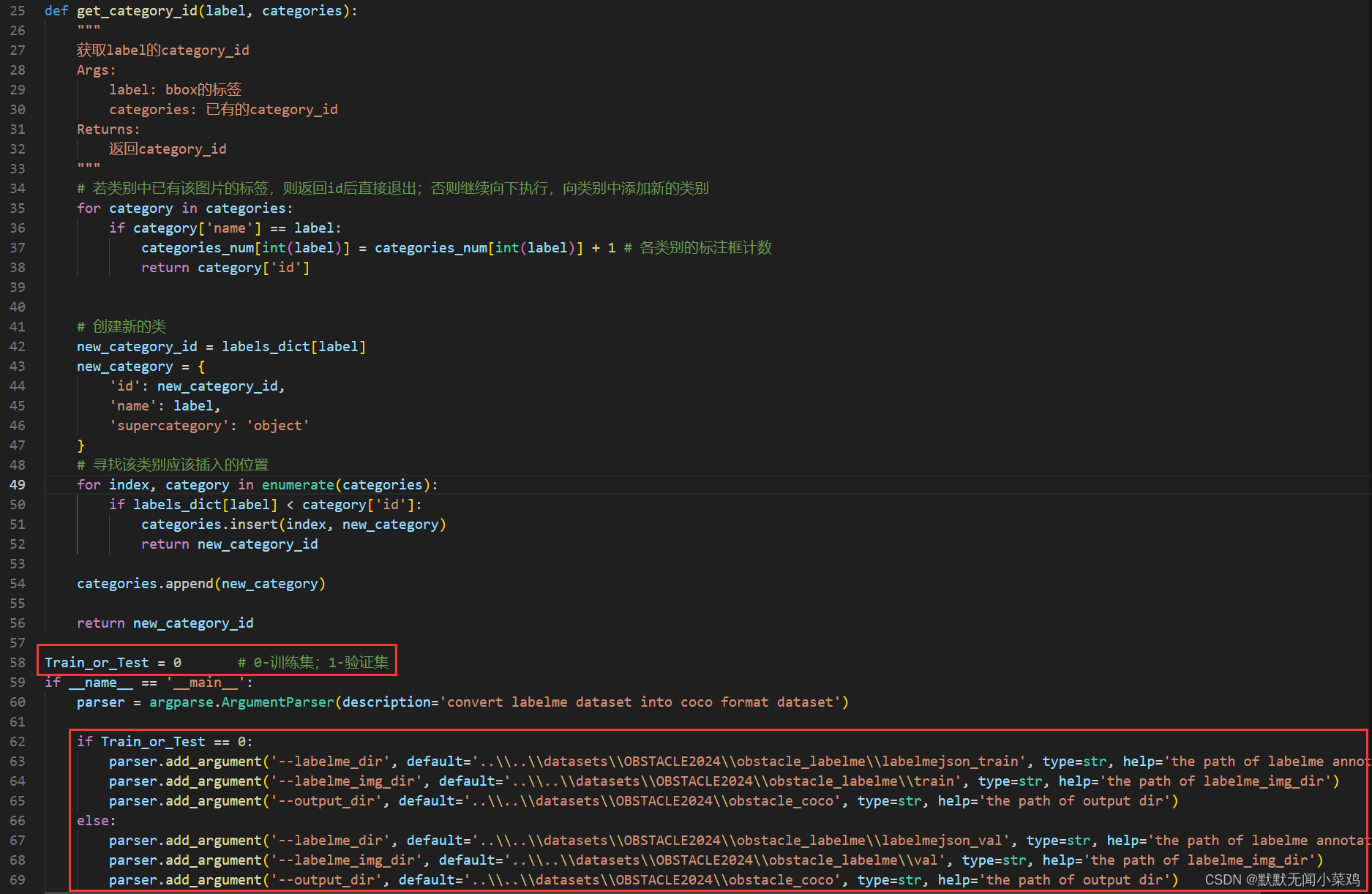
python labelme2coco.py根据实际的划分类别和在Labelme中做的标签,对字典进行修改:

把labelme格式的标注文件转换成coco格式的标注文件(注意修改labelme2coco.py文件中的训练集和验证集选择变量和路径,需要把Train_or_Test变量设置成0、1,各运行一遍程序,从而分别完成对训练集和验证集的转换。 )
补充:labelme的标注文件是每张图片对应一个json文件,coco的标注文件将训练集/验证集的所有图片整合成一个json文件。
至此,制作自己的数据集已完成,后续可同样采用2.1中的步骤进行coco格式到yolo所需格式的转换
STEP3:模型训练(推荐在Linux服务器中进行,没有条件也可以使用Windows)
环境配置
建议使用anaconda创建虚拟环境进行环境配置(网上有很多教程)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple(使用这个下载更快,且更容易找到包)
yolo_fastestv2所需
torchvision==0.10.0
tqdm==4.59.0
opencv_python==4.2.0.34
torchsummary==1.5.1(此包只有使用清华镜像才可以下载windows版本)
torch==1.8.1(同时需要搭配对应的cudatoolkit和cudnn)
numpy==1.19.5(此处有误,需要至少为1.23.4,否则导出模型时会出现module 'numpy' has no attribute 'object')onnx2tflite所需
onnx==1.10.0
onnxruntime
onnx-simplifier
numpy==1.19.5
tensorflow>=2.5(2.10也可以,不需要下载对应的cuda和cudnn,因为不需要使用tensorflow的gpu训练)
opencv-python
matplotlib(需要加上,源文件没有提到)
timm(需要加上,源文件没有提到)生成YOLO所需的Anchors
进入gd32ai-modelzoo/object_detection/yolo_fastestv2文件夹
使用脚本genanchors.py,输入命令(注意修改输入模型的尺寸)
shell
python genanchors.py --traintxt "{datasets_root}/COCO2017/train2017.txt" --output_dir "./" --label_flag "coco_80" --num_clusters 6 --input_width 256 --input_height 256
linux系统中:
python genanchors.py --traintxt "/home/dwy/test/datasets/COCO2017/coco80/train2017.txt" --output_dir "./" --label_flag "coco_80" --num_clusters 6 --input_width 256 --input_height 256
python genanchors.py --traintxt "/home/dwy/test/datasets/obstacle_coco/train.txt" --output_dir "./" --label_flag "abstacle" --num_clusters 6 --input_width 192 --input_height 192
windows系统中:
python genanchors.py --traintxt "C:\Users\DWY\Desktop\test\datasets\COCO2017\coco80\train2017.txt" --output_dir "./" --label_flag "coco_80" --num_clusters 6 --input_width 192 --input_height 192会发现目录中出现anchors6.txt文件夹,其中包含了6个anchors的尺寸(修改配置文件时将用到)
可能出现错误:
错误1:AttributeError: module 'numpy' has no attribute 'float'.
原因,numpy版本下载不正确,需要下载1.23.4
修改配置文件
修改gd32ai-modelzoo/object_detection/yolo_fastestv2/configs中的coco_sp.data文件:
shell
[name]
model_name=coco
[train-configure]
epochs=200 # 训练总epoch数,可自行修改
steps=50,100 # 多步学习率衰减相关参数,可自行修改
batch_size=64 # 批大小,可根据训练机器的性能自行修改
subdivisions=1
learning_rate=0.001 # 学习率,可自行修改
[model-configure]
pre_weights= pretrain # 预训练权重,可是这位None、pretrain或路径,可默认为pretrain
classes=80 # 类别数,可根据数据集自行修改
width=192 # 输入宽度,可自行修改(需要与上面python genanchors.py指令中的设置相同)
height=192 # 输入高度,可自行修改(需要与上面python genanchors.py指令中的设置相同)
anchor_num=3
separation=4 # 分离式结构(原博主说明该结构是为了减小最大RAM占用),先按默认设置进行训练部署
separation_scale=2
conf_thr=0.1
nms_thr=0.5
iou_thr=0.4
anchors=6.96682733,10.72855861 ,21.39902717,28.37262097 ,31.57415048,74.69314652 ,71.51949295,118.82159896 ,77.94421348,43.19736247 ,154.48875554,139.59583662
# anchors修改为anchors6.txt文件中的内容
[data-configure]
label_flag=coco_80
train=C:\Users\DWY\Desktop\test\datasets\COCO2017\coco80\train2017.txt # 修改为训练集的路径txt文件
val=C:\Users\DWY\Desktop\test\datasets\COCO2017\coco80\val2017.txt # 修改为验证集的路径txt文件
names=./configs/coco.names # 类别名字,若使用自制数据集需要修改其余没有注释的参数可不用修改,理解代码后可根据需要修改。
训练
若直接通过Vscode运行程序出现路径无法找到的情况(调试模型时使用),可以参考该方法:https://www.cnblogs.com/justsoso8/p/17756421.html
但是此方法在使用debug调试运行时仍然无效,需要在main文件中开头添加下述代码:
python
import os
import sys
os.chdir(sys.path[0])可以强制使工作目录设置为当前运行python文件所在目录。
在train.py开头添加路径,用于导入根目录中的库,否则会找不到common_utils
python
import sys
sys.path.append('../../')输入指令:
shell
python train.py --data configs/coco_sp.data模型默认设置每10个epochs保存一次。
可通过修改gd32ai-modelzoo/object_detection/yolo_fastestv2/submodules\Yolo_FastestV2文件夹中的train.py进行修改
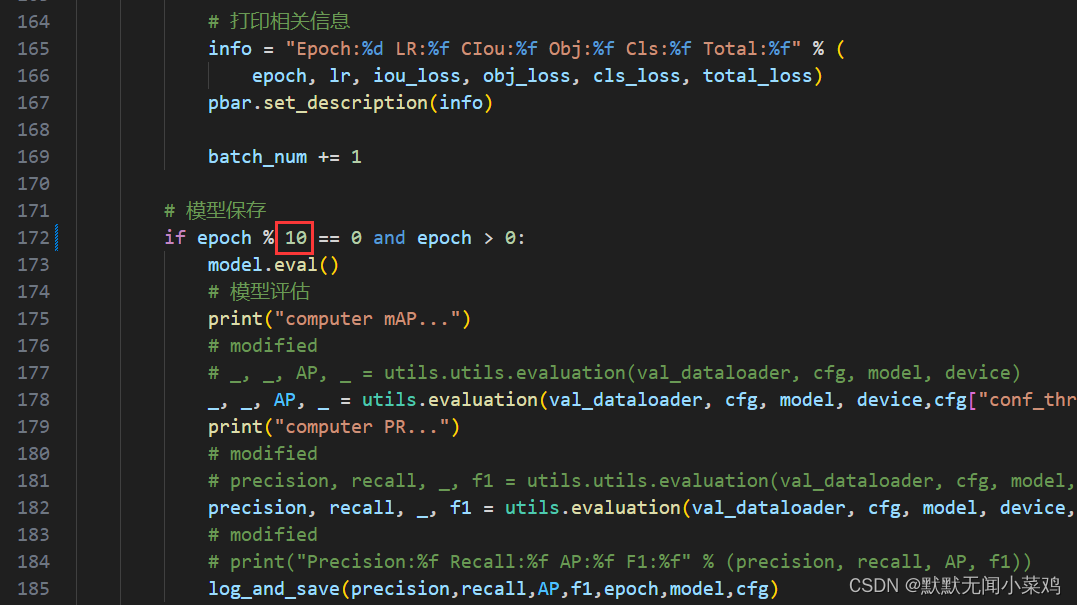
注意:定位损失使用CIOU可能会导致loss出现nan的情况导致训练失败,可切换为DIOU解决问题。
STEP4.1:导出模型并验证(该步骤用于验证元模型性能,若部署非必须)
先在pytorch2tflite.py开头添加路径,用于导入根目录中的库,否则会找不到common_utils
python
import sys
sys.path.append('../../')务必注意修改modelzoo文件夹里配置文件【data文件】中训练集和验证集的路径,否则会出现路径报错
shell
train=/home/dwy/test/datasets/COCO2017/coco80/train2017.txt
val=/home/dwy/test/datasets/COCO2017/coco80/val2017.txt输入指令:输入为权重和模型,输出为onnx,tflite格式模型,convert_type为0是输出onnx,为1时先经过onnx再经过tflite。
shell
python pytorch2tflite.py --data ./modelzoo/coco_sp_0005/coco_sp.data --model_path ./modelzoo/coco_sp_0005/best.pth --convert_type 1 --tflite_val_path "../../../datasets/COCO2017/coco80/val2017"STEP4.2:部署网络(推荐在Windows中进行)
注意修改配置文件的相关路径(使用Linux训练和Windows上部署的数据集路径不同)
该部分推荐在windows上进行,因为linux上操作STM32Cube和Keil不方便
相关软件下载:
- 下载STM32CubeMX软件,并安装STM32CUBE-AI 8.0.1包;下载地址
- 下载keil软件;下载地址
- 下载Download gcc-arm-none-eabi 10.3-2021.10;(若不使用GCC编译,可选择ARMCC编译,则不需要下载该内容)下载地址
- 下载GD32H7xx AddOn芯片包;下载地址
!!!特别注意,最新版的STM32Cube下载Cube-AI时,只会下载核心部分,不会自动下载exe相关文件,导致模型无法转成C文件。需要再Cube中创建工程并使用AI工具,才会自动下载对应的exe文件(否则无法把模型转成C文件。具体如下图
观察到从5.1.2版本开始,大小明显减小,主要就是缺少了exe相关支持。(仔细阅读deploy.py中的代码会发现,把模型转成C语言文件会调用···/Utilities/windows/stm32ai.exe文件)
随便创建一个工程
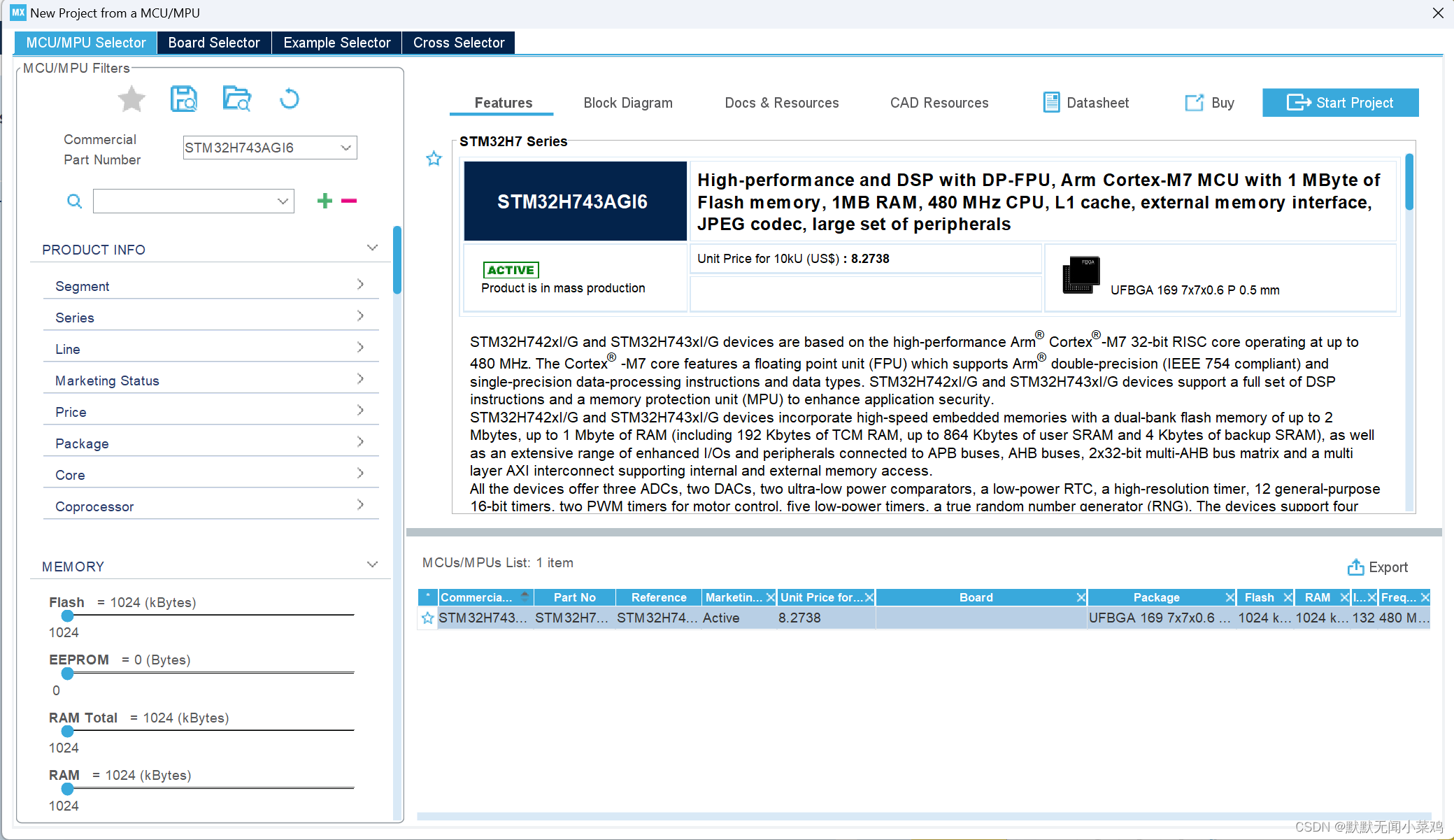
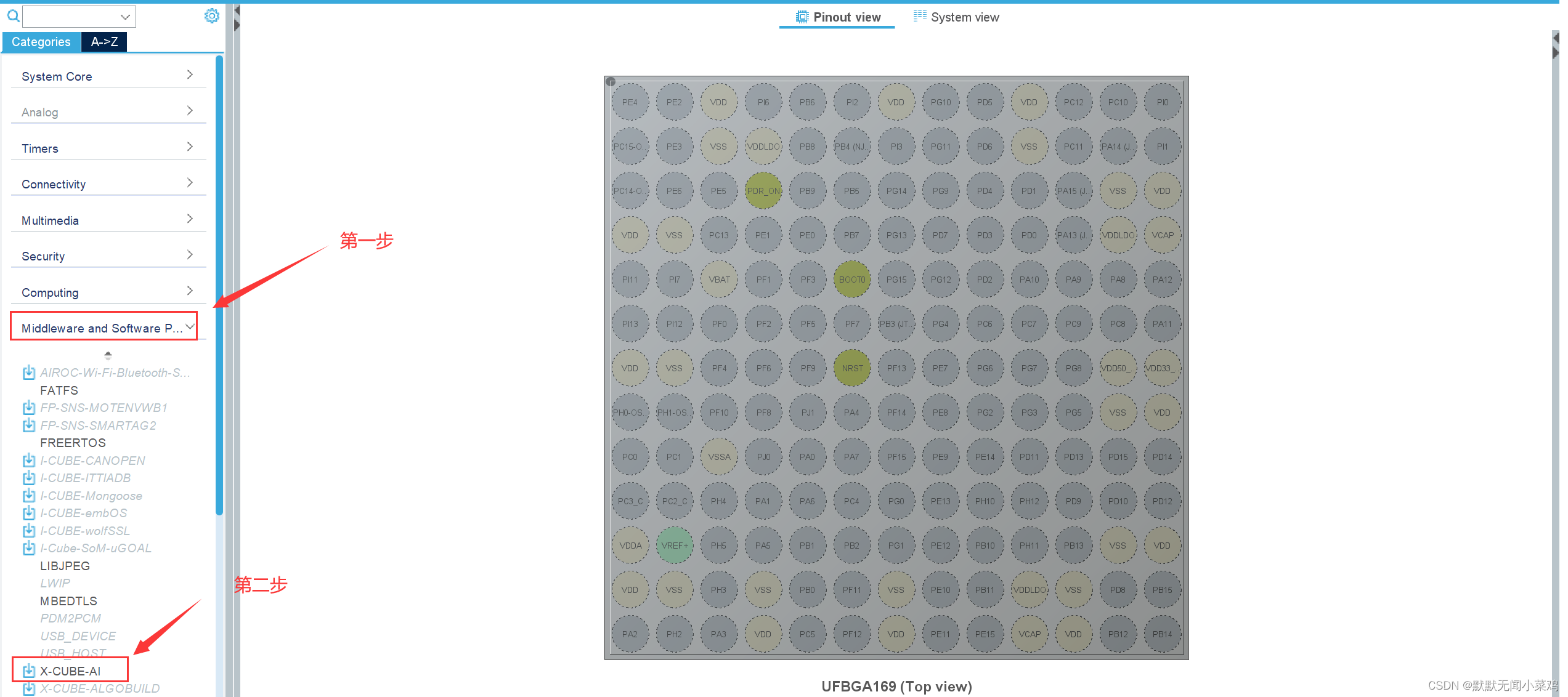
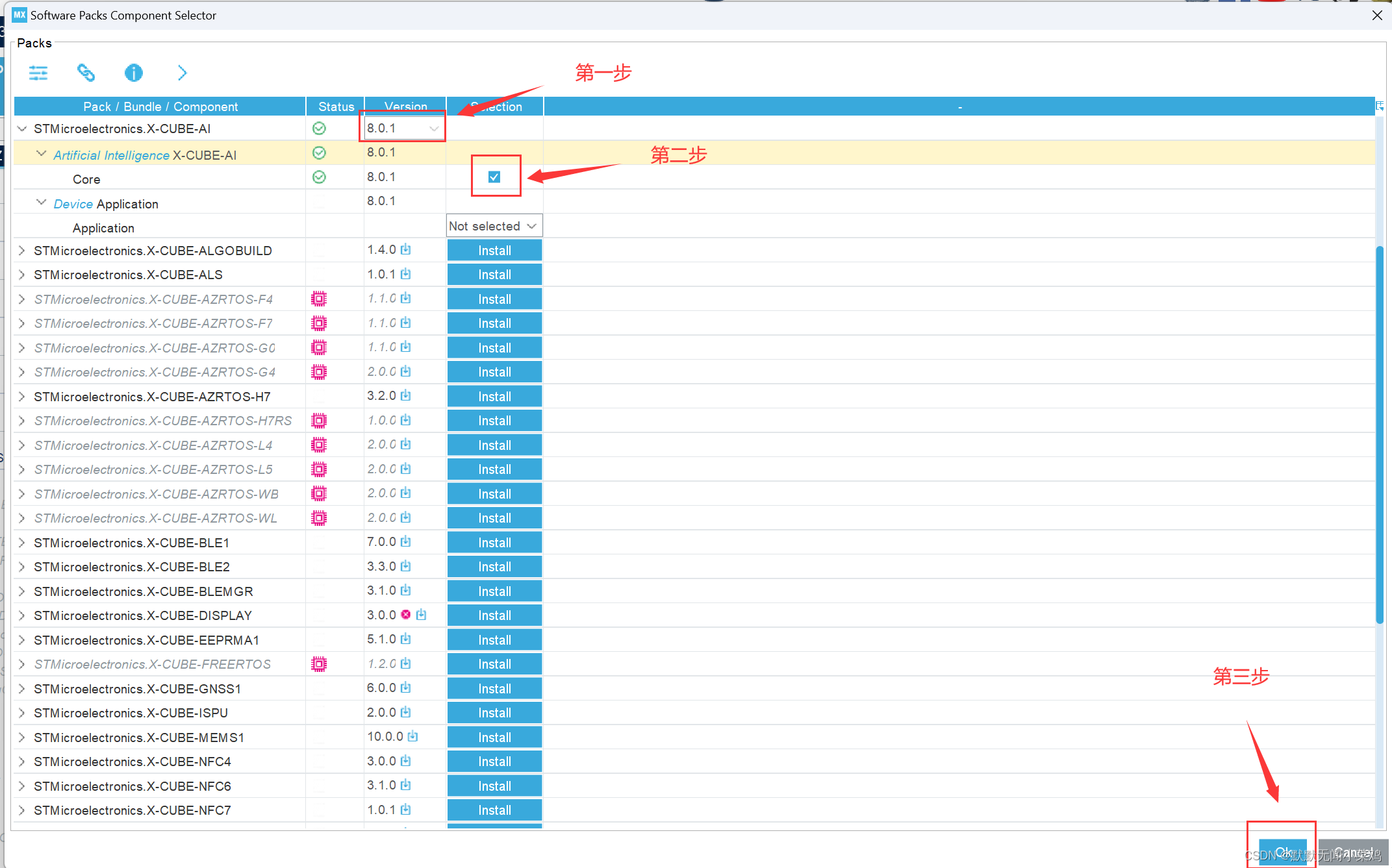
点击OK后,即会自动下载AI的exe相关文件。
修改deploy.py中的val_paths和--stm32cubeai_path(根据自己下载的位置:STM32CubeMX下载的库会有一个默认的下载地址,在help中可以查看)
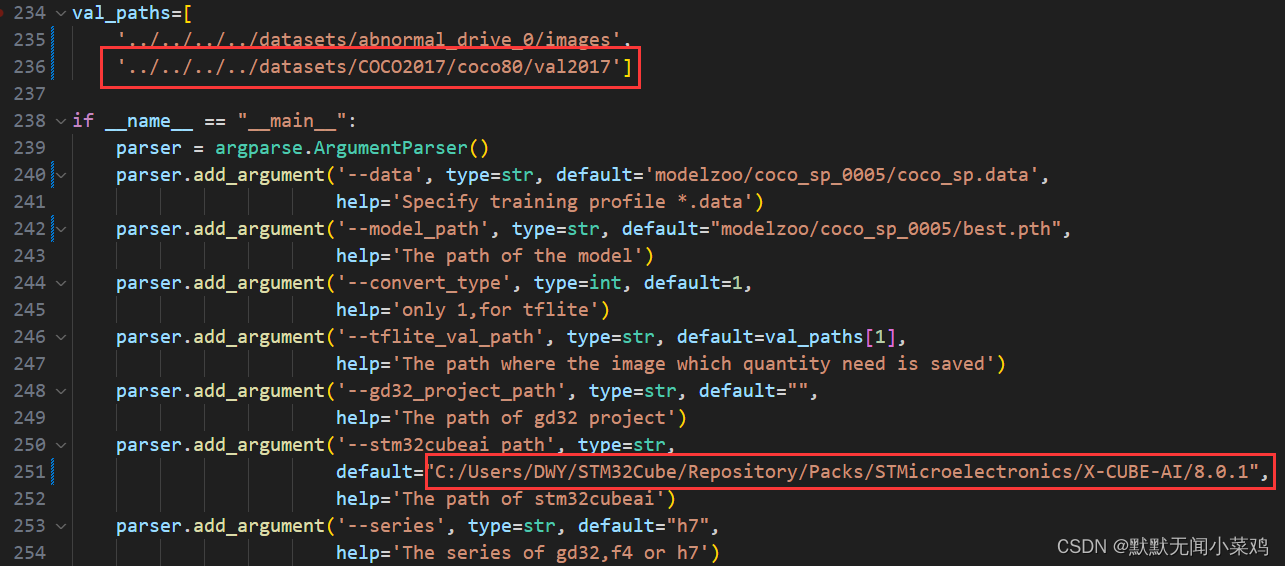
若训练和部署没有使用同一个设备进行,并且在进行模型转换部署时将deploy.py中的验证功能打开,如下图所示。则需要执行STEP4.1中一样的步骤,修改modelzoo文件夹里配置文件【data文件】中训练集和验证集的路径,否则会出现路径报错,无法进行模型验证。

把训练输出文件夹复制到modelzoo文件夹中(训练输出文件在gd32ai-modelzoo\object_detection\yolo_fastestv2\results\train路径下)。

输入命令:(特别注意:compiler为0时,使用Keil自带的ARMCC编译器;为1时使用GCC;若不使用GCC,则不用下载GCC,其余路径根据实际情况进行修改)
shell
python deploy.py --data modelzoo/coco_sp_0005/coco_sp.data --model_path modelzoo/coco_sp_0005/best.pth --convert_type 1 --tflite_val_path "../../../datasets/COCO2017/coco80/val2017" --gd32_project_path deployment/gd32h759IMK6_ARMCC_test --series h7 --compiler 0
python deploy.py --data modelzoo/coco_sp_0005/coco_sp.data --model_path modelzoo/coco_sp_0005/best.pth --convert_type 1 --tflite_val_path "C:\Users\DWY\Desktop\MCU_AI\datasets\OBSTACLE2024\obstacle_coco\val" --gd32_project_path deployment/gd32h759IMK6_ARMCC_test --series h7 --compiler 0之后将会生成输出工程,路径为gd32ai-modelzoo\object_detection\yolo_fastestv2\results\deploy,需要根据理解进行移植,主要就是将Edge_AI文件夹中的所有文件加入自己的工程中,并使用起来。
主要使用的代码是:
c
#include "ai_model.h" // 使用AI需要引入的头文件
AI_Init(IMAGE_WIDTH,IMAGE_HEIGHT,0); // AI_初始化函数
AI_Run((u8 *)frame); // 目标检测函数具体使用方法可借鉴:gd32ai-modelzoo\object_detection\yolo_fastestv2\deployment 路径下的Keil工程代码(main.c文件中)
想要顺利跑通完整的神经网络嵌入式部署需要不少努力。过程中可能会因为各自的硬件环境出现各种各样的问题,希望大家可以耐心解决,并欢迎在评论区讨论。
最后,十分感谢GD32AI-ModelZoo的原作者,为神经网络在的GD32上的部署开拓了道路。若有相关问题,大家也可以去原作者博客中讨论!!!