【深度学习聚类】 在近年来的深度学习领域中备受关注,通过结合深度学习模型与传统聚类 方法,显著提升了聚类算法在处理高维数据和复杂模式识别任务中的表现。深度学习聚类技术已经在图像处理、文本分析、生物信息学等多个领域取得了显著成果,其独特的方法和有效的表现使其成为研究热点之一。
为了帮助大家全面掌握深度学习聚类 的方法并寻找创新点,本文总结了最近两年 【深度学习聚类】 相关的20篇顶会顶刊的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望能为各位的研究工作提供有价值的参考。
需要的同学 扫码添加我
回复"深度学习聚类20 "即可全部领取

1、Deciphering 'What' and 'Where' Visual Pathways from Spectral Clustering of Layer-Distributed Neural Representations
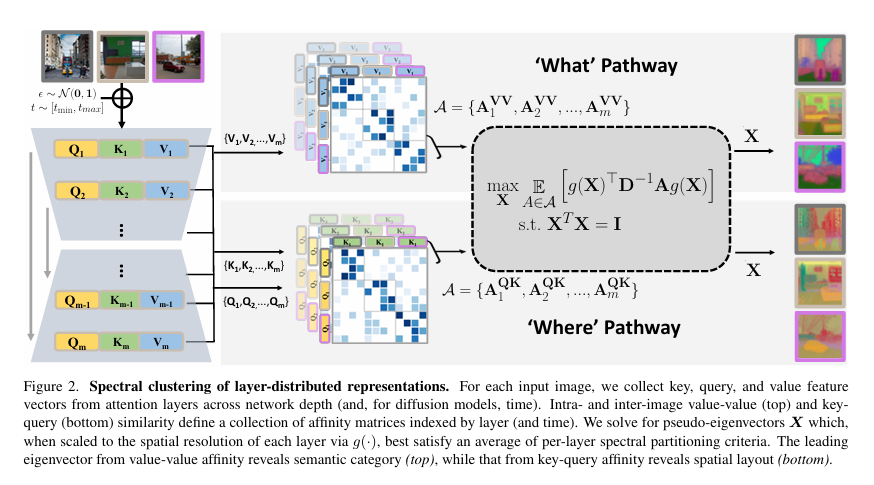
-这篇文章提出了一种新颖的方法,用于分析神经网络激活中包含的分组信息,从而能够从大型预训练视觉模型的行为中提取空间布局和语义分割。与以往的研究不同,该方法对网络的激活状态进行了全面分析,利用了所有层级的特征,避免了猜测模型中哪一部分包含相关信息的需要。该方法受到经典谱聚类算法的启发,通过一组亲和矩阵来构建分析,这些矩阵是通过比较不同层中的特征形成的。通过梯度下降求解这个优化问题,使得该技术能够从单一图像扩展到数据集级别的分析,包括数据集中的内部和图像间关系。
-文章中介绍了一种新的分析方法,提供了对模型功能的洞察,并且直接提取了有关图像分割的重要视觉信息。这种方法不需要事先知道信息存储在网络的哪个位置,也不需要对网络进行超参数搜索。通过对整个网络激活状态的分析,从浅层到深层,将其耦合成一个全局谱聚类目标。解决这个聚类问题不仅产生了新的与下游分割任务直接相关的特征表示(以特征向量嵌入的形式),而且还提供了对视觉模型内部工作方式的洞察。文章的贡献包括:
-
一种受谱聚类启发的分析深度神经网络激活的新方法。
-
与分析单一层的方法相比,提取区域的质量有所提高。
-
一个高效的基于梯度的优化框架,使得该方法能够扩展到对整个数据集的网络行为进行联合分析。
-
与STEGO方法相当且无需训练的无监督语义分割结果,但提取自预训练的生成模型而非对比背骨。
-
对大型视觉模型学习到的计算策略的洞察:内部特征被划分为"什么"和"哪里"的路径,分别维护语义和空间信息。
文章还讨论了与图像分割、无监督语义分割和可解释性相关的工作,并介绍了所提出方法的详细过程,包括谱聚类中分布式特征的使用、每个图像的分析、跨数据集的扩展以及正交表示的恢复。实验部分展示了如何使用该方法研究模型如何在内部对图像区域进行分组,以及如何发现依赖于用于分组的内部特征选择的空间/语义分割。通过对Stable Diffusion模型的分析,文章展示了如何有效地从图像中提取区域,并探讨了模型如何在空间和语义上处理信息,揭示了模型内部的"什么"和"哪里"路径。最后,文章讨论了所提出方法的潜在影响,并提出了未来研究方向。
2、 S2MVTC: aSimple yet Efficient Scalable Multi-View Tensor Clustering

-这篇文章介绍了一种新型的大规模多视图张量聚类方法,称为S2MVTC(Scalable Multi-View Tensor Clustering)。这种方法主要关注于学习不同视图内部以及跨视图之间的嵌入特征的相关性。文章首先提出了通过将不同视图的嵌入特征堆叠成一个张量并进行旋转来构建嵌入特征张量。接着,作者设计了一种新颖的张量低频近似(Tensor Low-Frequency Approximation, TLFA)算子,该算子将图相似性整合到嵌入特征学习中,有效地实现了不同视图内嵌入特征的平滑表示。
-此外,文章还引入了共识约束,以确保嵌入特征之间的语义一致性。通过将这些组件整合到统一框架中,S2MVTC能够高效地利用多视图信息进行大规模多视图聚类任务。实验结果表明,S2MVTC在聚类性能和CPU执行时间上显著优于现有的最先进算法,特别是在处理大规模数据时。
-文章的主要贡献包括:
-
与现有基于锚点的方法不同,S2MVTC直接学习嵌入特征的视图间和视图内的相关性。
-
利用新定义的TLFA算子,S2MVTC在不同视图中实现了嵌入特征的平滑表示。
-
在六个大型多视图数据集上的实验结果表明,S2MVTC在聚类性能上显著优于现有的最先进算法,特别是随着数据规模的增加,S2MVTC的优势更加明显。
文章还详细介绍了S2MVTC的工作原理和算法流程,包括张量奇异值分解(t-SVD)的相关定义和操作,以及如何通过交替优化方法解决优化问题。此外,作者对算法的存储和计算复杂度进行了分析,并证明了算法的理论收敛性。
-在实验部分,作者使用了六个大型多视图数据集来评估S2MVTC的有效性,并与多个现有的聚类算法进行了比较。评估指标包括准确度(ACC)、归一化互信息(NMI)、纯度(Purity)、F分数、精确度(PRE)、召回率(REC)、调整后的兰德指数(ARI)和CPU时间。实验结果证明了S2MVTC在各个方面的优越性,特别是在处理大规模数据集时的高效率和优越的聚类性能。
-最后,文章通过模型分析和消融研究进一步探讨了S2MVTC的工作原理和各个组成部分对聚类性能的影响。研究表明,探索视图间的语义一致性和视图内的图相似性对于提高聚类性能至关重要。此外,非线性锚图在处理样本量非常大的数据集时,能够更好地捕捉样本之间的关系,从而提高聚类性能。
-综上所述,这篇文章提出的S2MVTC方法为大规模多视图聚类问题提供了一种简单、高效且可扩展的解决方案,具有很好的实际应用前景。
需要的同学 扫码添加我
回复"深度学习聚类20 "即可全部领取

3、Laplacian-guided Entropy Model in Neural Codec with Blur-dissipated Synthesis
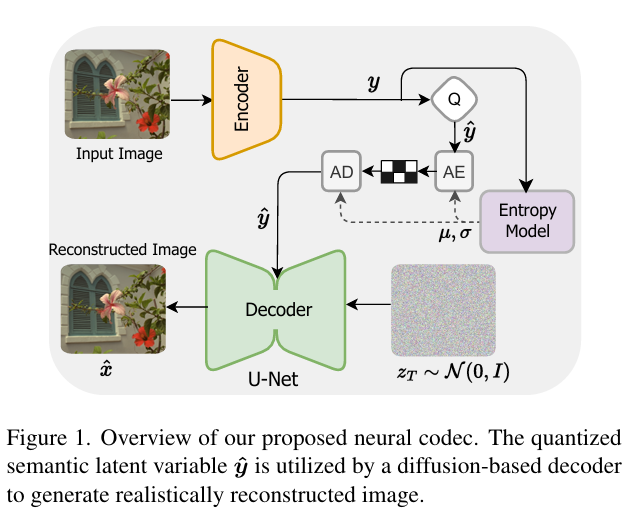
-这篇文章提出了一种新颖的神经网络图像压缩模型,旨在通过非各向同性扩散模型提高重建图像的感知质量。该模型在解码器端采用条件扩散模型,以增强图像数据的感知水平,同时引入了一种新的熵模型,通过利用潜在空间中的时空通道相关性,准确模拟潜在表示的概率分布,从而加速熵解码步骤。
-文章首先介绍了基于学习的图像压缩方法,这些方法通常包括转换、量化和无损熵编码三个步骤。作者指出,尽管现有方法在压缩效率方面取得了进展,但在图像质量的感知水平上仍有提升空间。为此,文章提出采用条件扩散模型来改善解码图像的模糊问题,并通过引入感知偏差来区分图像的频率内容,以生成高质量的图像。
-文章的核心贡献包括:
-
提出了一种基于模糊扩散模型的条件扩散解码器,该解码器能够根据图像的频率分量进行不同程度的扩散,实现从粗糙到精细的图像重建。
-
设计了一种新颖的通道条件自回归熵模型,该模型利用全局空间上下文和Transformer模块中的拉普拉斯形状位置编码,有效捕获每个通道块内的局部和全局空间依赖性。
-
通过实验验证了所提出框架与最先进的基于生成模型的编解码器相比,在感知质量上具有更好的表现,并且所提出的熵模型有助于显著节省比特率。
-在相关工作部分,文章回顾了基于学习的图像压缩、扩散模型和神经熵模型的研究进展。在方法部分,详细介绍了模糊扩散模型的定义、扩散过程、去噪过程和优化方法。此外,还介绍了文章提出的熵模型的设计,包括空间上下文建模和基于Transformer的空间上下文建模。
-实验部分展示了所提出模型在不同数据集上的性能,并与现有技术进行了比较。结果表明,新模型在感知质量上优于其他编解码器,并且在低比特率下仍能保持较少的伪影和较高的图像质量。
-最后,文章进行了消融研究,探讨了最大模糊度、位置编码和上下文块对模型性能的影响。实验结果表明,拉普拉斯形状的位置编码在压缩效率方面优于其他编码方式,并且结合局部和全局上下文可以提高熵模型的准确性。
-文章的结论强调了利用扩散模型和先进的熵建模实现卓越图像压缩性能的有效性,并指出这项研究得到了美国国家航空航天局(NASA)的支持。
需要的同学 扫码添加我
回复"深度学习聚类20 "即可全部领取
