文章目录
- 一、提示词用法
- [二、提示词 Prompt 构成](#二、提示词 Prompt 构成)
- [三、提示词 Prompt 调优](#三、提示词 Prompt 调优)
-
- [1、结合 训练数据 写提示词](#1、结合 训练数据 写提示词)
- [2、不知道训练数据的情况 - 不断尝试](#2、不知道训练数据的情况 - 不断尝试)
- [3、高质量提示词特征 - 小作文](#3、高质量提示词特征 - 小作文)
- [四、OpenAI 的 API 类型](#四、OpenAI 的 API 类型)
-
- [1、续写文本 API 示例](#1、续写文本 API 示例)
- [2、对话 API 示例](#2、对话 API 示例)
- [五、OpenAI API 中的重要参数说明](#五、OpenAI API 中的重要参数说明)
一、提示词用法
提示词 Prompt 的 两种用法 :
- 直接提问 : 直接向 GPT 大模型提问 , 得到一个具体问题的答案 , 如 : XXX 错误如何处理 ;
- 集成应用 : 将 提示词 Prompt 集成到自己开发的应用程序中 , 结合自己公司的实际业务状况 , 生成与自己业务相关的一系列提示词 , 如 : 基于公司的一套知识库 + GPT 大模型 进行使用 ;
二、提示词 Prompt 构成
1、提示词构成
提示词 Prompt 构成 :
- 指定角色 : 为 大模型 指定一个角色 , 明确指出 " 你是一个 XX " 是很有用的 ;
- 如 : 你是一位软件工程师 , 请写出 XXX 代码 ;
- GPT 大模型 在训练文本 时 , 没有想过角色 , 后来使用时发现添加 " 你是一个 XX " 角色设置 非常有效 , 慢慢后面 训练 大模型时 , 都会将角色作为一个 参数 设置到训练中, 之后就越来越有效 ;
- 将 指定角色 " 你是一个 XX " 提示词 , 必须放在最前面 , 已经有论文研究过了 , 指定角色提示词放在最前面 , 生成的结果最准确 ;
- 大模型 对 提示词 Prompt 开头和结尾的文本更加敏感 , 最重要的内容要放在开头和结尾 , 开头 > 结尾 ;
- 任务描述 : 给出一个具体的 任务 , 信息越丰富越好 ;
- 如 : 写出 XX 代码 , 实现以下功能 : XX ;
- 案例说明 : 期望 大模型 生成 特定 的 输出时 , 给出一个例子 , 可以帮助模型更好地理解任务并生成正确的输出 , 提升输出质量 ;
- 如 : 你是程序员 , 实现 XX 功能 , 例如 下面的代码 : XX , 在上述代码的基础上进行微调 ;
- 输入信息 : 任务的输入信息 要在 提示词 中 明确的标识出来 ;
- 如 : 写出的函数 输入参数 有 X 个 , 分别是 X / X ... ;
- 输出信息 : 详细的描述你对输出信息的要求 , 比如 : 输出格式 , 输出结果个数 , 输出语言 ;
- 如 : 输出 MarkDown 格式的文本 , 输出为英文 , 300 字 ;
2、提示词位置对权重的影响
大模型 对 提示词 Prompt 开头和结尾的文本更加敏感 , 最重要的内容要放在开头和结尾 , 开头 > 结尾 ;
相对来说 重要性不太强的内容 , 放在中间位置 ;
3、定义角色的好处
在文章开头 定义角色 , 会将 问题领域 收窄 , 减少歧义 ,
比如 : 你定义 " 你是一个 程序员 " 提示词 , 就会将整个问题领域 局限在 编程领域 , 当我们提出 " 模式 " 一词 时 ,
- 大模型 就会想到 设计模式 , 开发模式 ,
- 而不会想到 做饭模式 , 睡觉模式 ,
这样能极大的提升准确性 , 得到更好的输出结果 ;
三、提示词 Prompt 调优
提示词 Prompt 需要 不断的进行调优 , 每当 通过 提示词 得到的结果不满意 , 我们就对 提示词 进行迭代修改 , 不断进行调优 , 直到得到 令我们满意的输出为止 ;
1、结合 训练数据 写提示词
知道训练数据 : 了解 提示词 的 训练数据 , 如果是 自己训练的数据 , 肯定知道 写什么提示词 能得到最佳结果 ;
2、不知道训练数据的情况 - 不断尝试
不知道训练数据 : 如果不知道 GPT 的训练数据 , 那就需要 不断与 大模型 进行聊天 , 了解 GPT 都训练了哪些数据 , 都输出了哪些数据 ;
如何 知道 GPT 大模型训练了哪些数据 , 借助这些数据 进行 提示词 Prompt 的 调优 , 以 " 西游记 " 为例 ,
如果知道 GPT ( Generative Pre-trained Transformer ) 大模型 训练 " 西游记 " 相关知识文本 的 数据 , 参考 该方面知识 的 " 训练数据 " 进行 提示词 Prompt 调优 , 是最佳途径 ;
跟 GPT 大模型聊天 , 就 聊 " 西游记 " 相关内容 , 聊 几十轮 对话 , 看看 大模型 都训练了哪些数据 ;
尽量选择 与 GPT 输出的内容 类似的 文本 作为 提示词 ;
不断尝试 修改 提示词 , 增加一个字 , 减少一个字 , 使用不同的间隔 和 标点符号 , 对输出结果都有一定的影响 ;
该方案有一定的运气成分 , 门槛比较低 ;
3、高质量提示词特征 - 小作文
高质量提示词 有如下特点 :
- 描述具体 : 提示词不能太概括 , 描述的越具体越好 ;
- 信息丰富 : 提供丰富的上下文信息 , 给出 几百上千字 的参考信息 ;
- 没有歧义 : 目标必须明确 , 不能有歧义 , 不能让 大模型 理解错方向 , 反面案例就是 " 武汉市长江大桥 " ;
高质量的提示词 , 都是 几百字 或者 上千字 的 , 内容丰富 的 " 小作文 " ;
四、OpenAI 的 API 类型
OpenAI 的大模型 出现最早 , 其它的大模型的 API 基本都参考 OpenAI 的大模型 , 学会使用 OpenAI 的 API , 基本其它的大模型提供的 API 都可以很快学会 ;
OpenAI 提供了两种 API 版本 :
- 续写文本 API : https://platform.openai.com/docs/api-reference/completions/create
- 对话 API : https://platform.openai.com/docs/api-reference/chat/create
基本上使用 对话 API 就可以解决所有问题 , 续写文本 API 几乎很少使用 ;
1、续写文本 API 示例
续写文本 API : https://platform.openai.com/docs/api-reference/completions/create
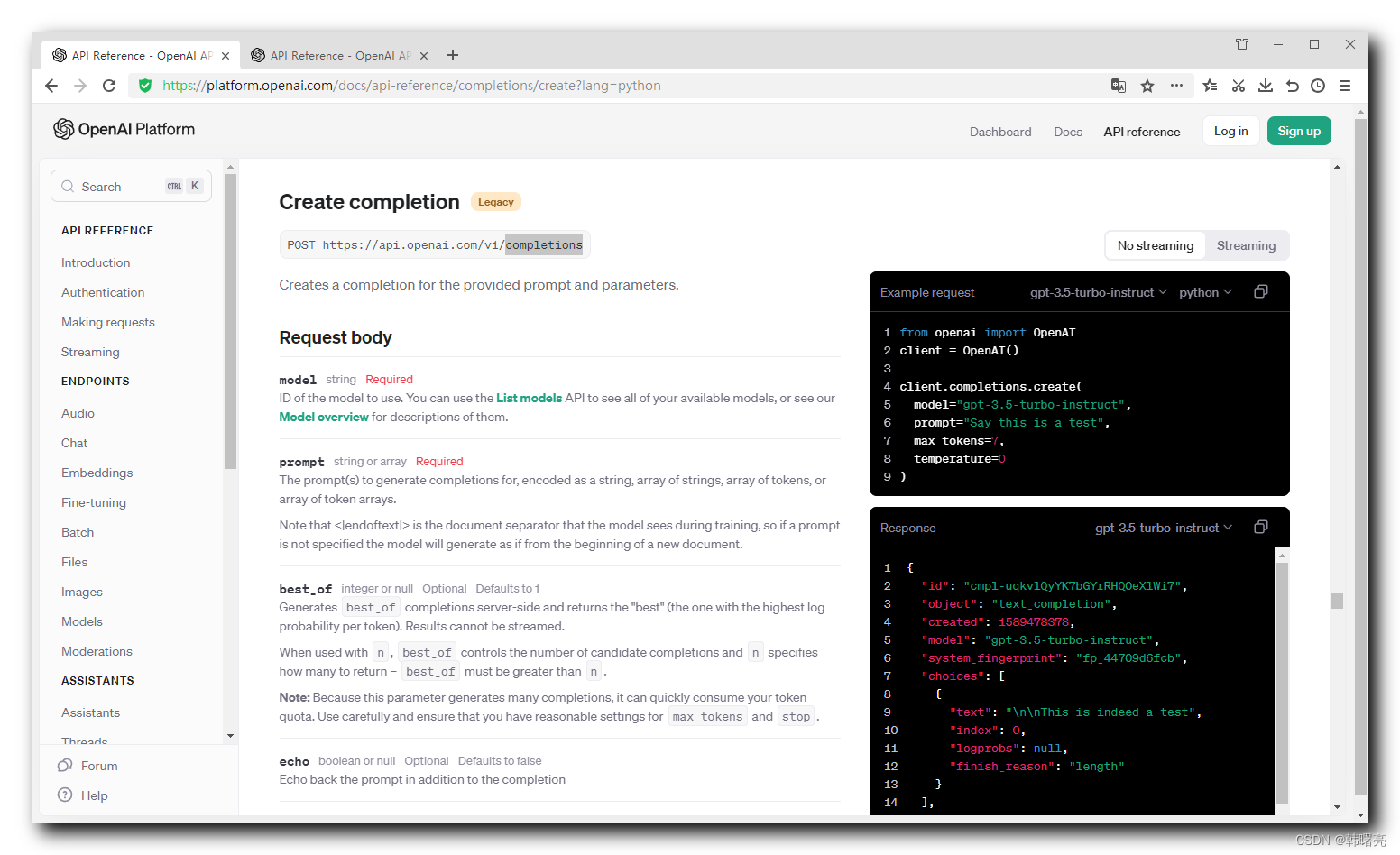
官方给出了一个 调用 OpenAI 续写文本 API 的 Python 示例代码 :
javascript
from openai import OpenAI
client = OpenAI()
client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Say this is a test",
max_tokens=7,
temperature=0
)在之前的博客 【AI 大模型】OpenAI 接口调用 ① ( 安装 openai 软件包 | 查看 openai 软件包版本 | PyCharm 中开发 Python 程序调用 OpenAI 接口 ) 中 , 购买了 API-KEY , 设置 API-KEY 和 请求地址 ,
- API-KEY 为
sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a, - 请求地址是
https://api.xiaoai.plus/v1,
这是一个 GPT 3.5 的 API-KEY ;
javascript
from openai import OpenAI
client = OpenAI(
api_key="sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a",
base_url="https://api.xiaoai.plus/v1",
)
completion = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Say this is a test",
max_tokens=7,
temperature=0
)
print(completion.choices[0].message)在 PyCharm 中 直接执行该代码 , 这个代码执行的时间比较长 , 需要等待 几分钟 左右 , 执行结果如下 :
javascript
{'role': 'assistant', 'content': '*nods* Understood. I am now roleplaying as an AI assistant with broad knowledge'}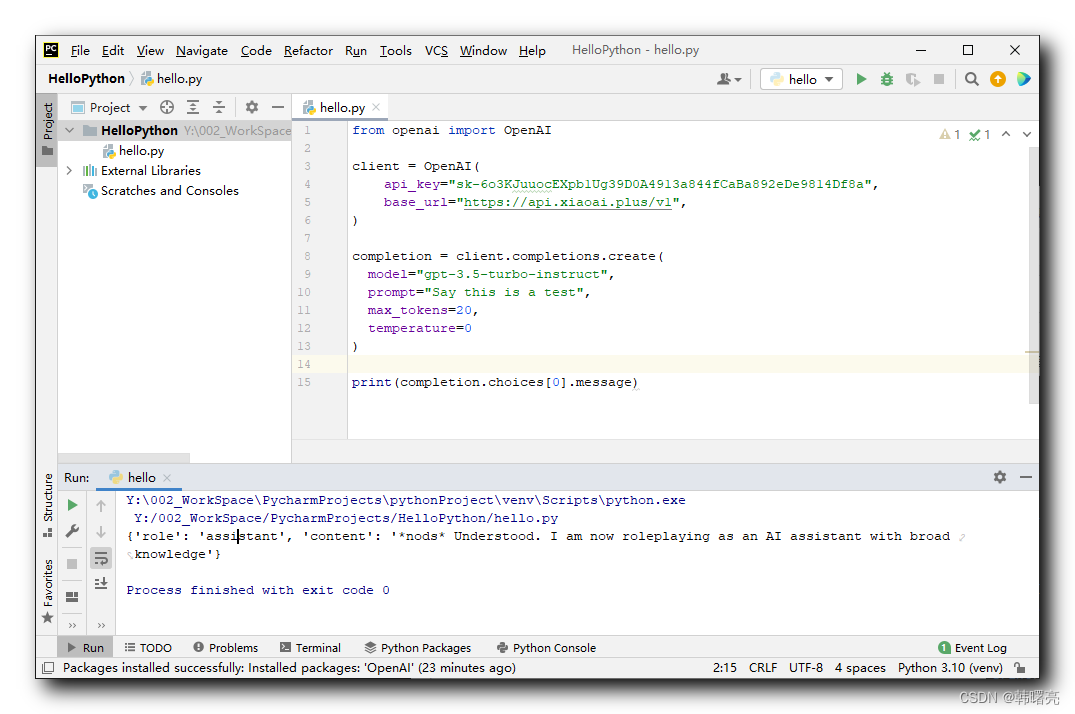
2、对话 API 示例
对话 API : https://platform.openai.com/docs/api-reference/chat/create
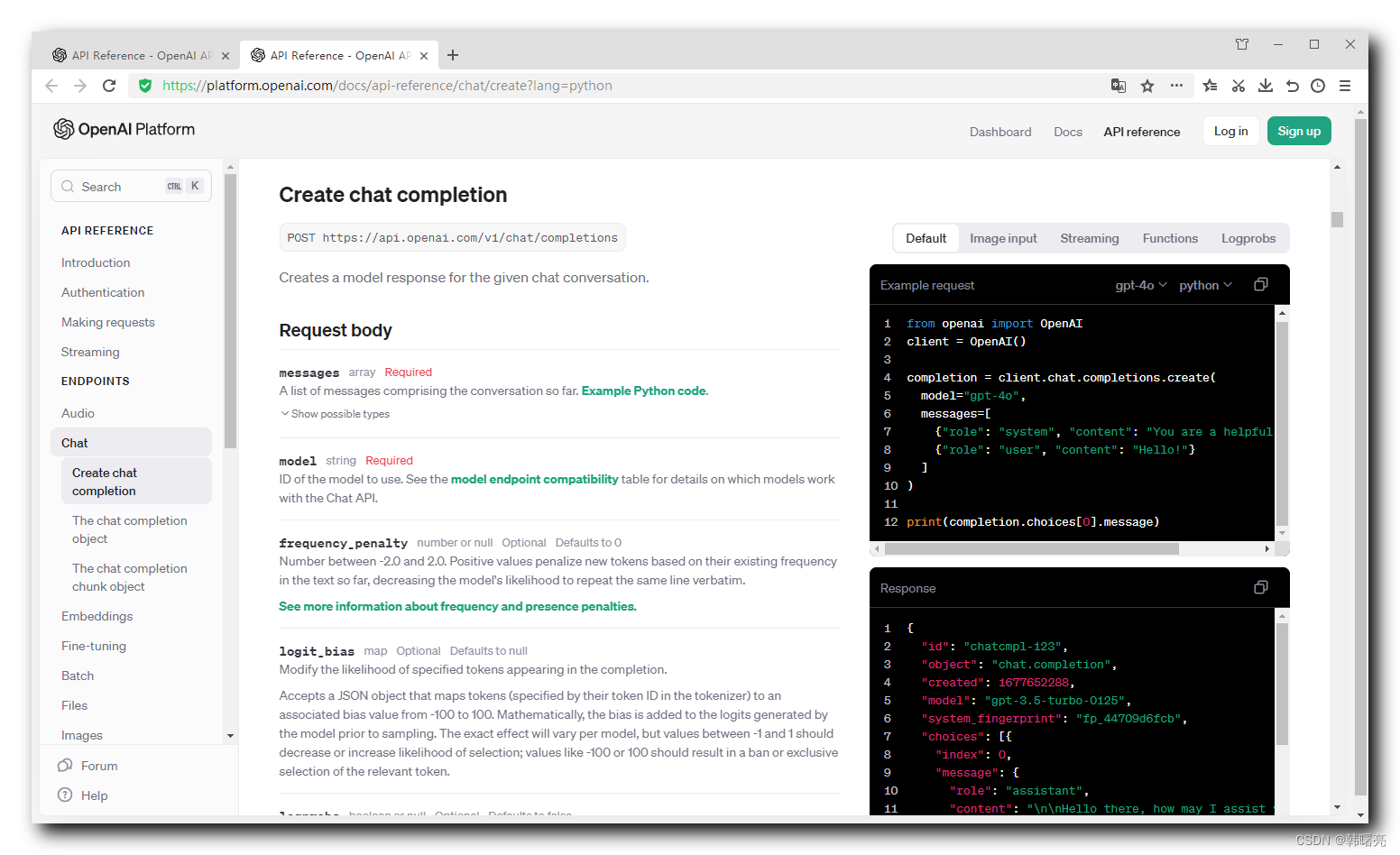
官方给出的示例如下 :
javascript
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)同理 , 设置 API-KEY 和 请求地址 ,
- API-KEY 为
sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a, - 请求地址是
https://api.xiaoai.plus/v1,
这是一个 GPT 3.5 的 API-KEY ;
最终代码如下 :
javascript
from openai import OpenAI
client = OpenAI(
api_key="sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a",
base_url="https://api.xiaoai.plus/v1",
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)在 PyCharm 中执行上述代码 , 执行结果为 :
javascript
ChatCompletionMessage(content='Hello! How can I assist you today?', role='assistant', function_call=None, tool_calls=None)
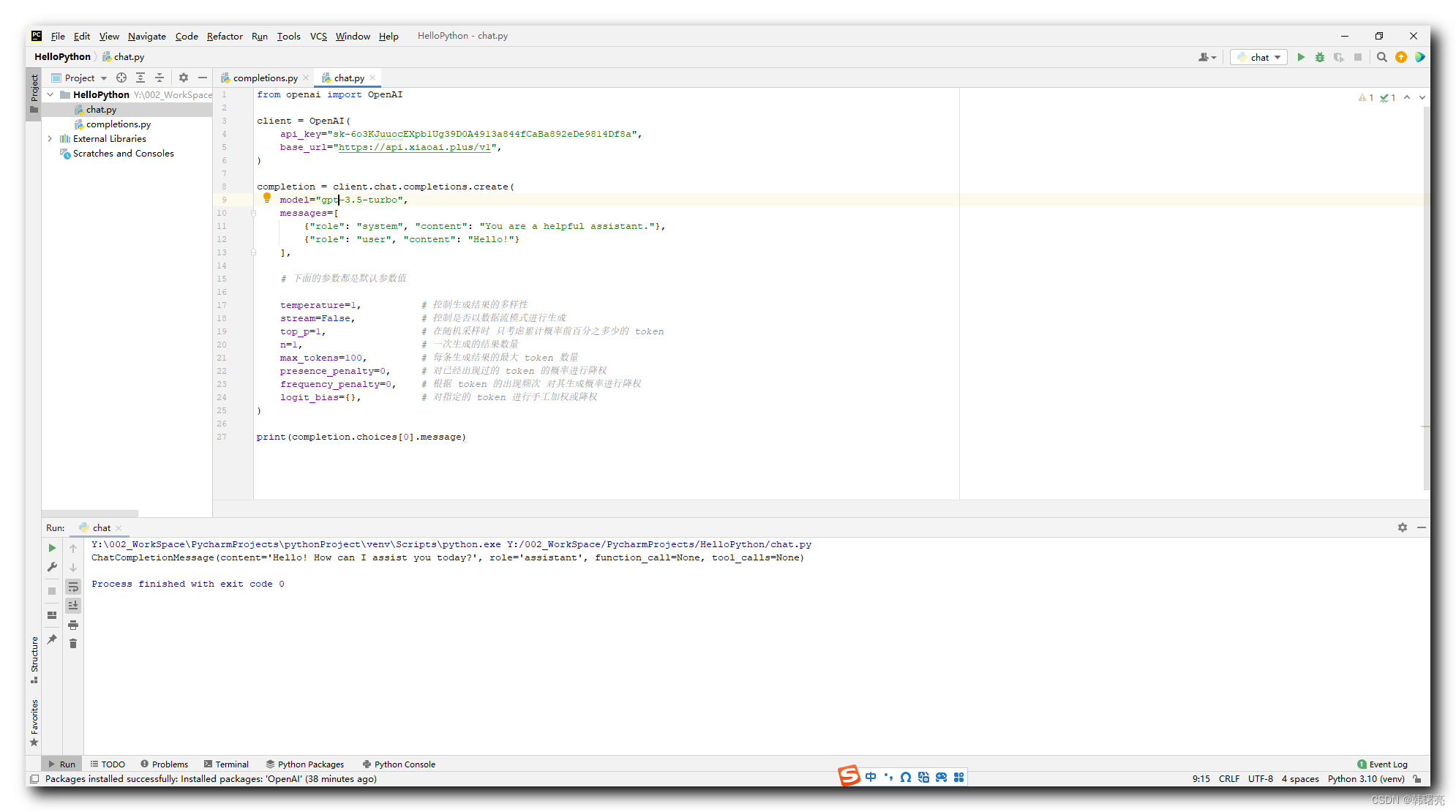
五、OpenAI API 中的重要参数说明
OpenAI API 中的重要参数说明 :
- temperature 参数 : 控制生成结果的多样性 ; 默认值为 0 , 取值范围 0 ~ 2 ;
- 值越高 , 生成的结果越随机 , 设置为 2 基本胡说八道 ;
- 值越低 , 生成的结果越固定 , 0 的时候基本固定 ;
- seed 参数 : 随机种子 , 如果不指定 则 OpenAI 自己随机决定用什么随机种子 ;
- 指定该 seed 参数后 , 如果 temperature = 0 , 则固定的种子生成的结果是固定的 ;
- stream 参数 : 控制是否以数据流模式进行生成 ; 默认值为 False ;
- 如果设置为 True , 在数据流模式下 , 一个字一个字的输出 , 浪费流量 ;
- 默认 False , 整个生成完了 , 在一次性返回 ;
- top_p 参数 : 在随机采样时 , 只考虑累计概率前百分之多少的 token , 有助于控制生成文本的多样性 ;
- 与 temperature 参数作用相似 , 不建议与 temperature 一起使用 ;
- n 参数 : 一次生成的结果数量 ;
- 使用提示词的 自洽性 时使用 , 一次返回多个结果再进行比较 ;
- max_tokens 参数 : 每条生成结果的最大 token 数量 , 超过这个限制的部分会被截断 ;
- 省钱方案 , 防止某个用户大量消耗 token ;
- presence_penalty 参数 : 对已经出现过的 token 的概率进行降权 , 帮助生成更多样化的文本结果 ;
- 避免输出很多重复的话 , 浪费 token ;
- frequency_penalty 参数 : 根据 token 的出现频次 , 对其生成概率进行降权 ;
- logit_bias 参数 : 对指定的 token 进行手工加权或降权 , 可以通过这个参数来调整特定 token 的生成概率 , 但不常用 ;
OpenAI 参数示例 :
javascript
from openai import OpenAI
client = OpenAI(
api_key="sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a",
base_url="https://api.xiaoai.plus/v1",
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
# 下面的参数都是默认参数值
temperature=1, # 控制生成结果的多样性
stream=False, # 控制是否以数据流模式进行生成
top_p=1, # 在随机采样时 只考虑累计概率前百分之多少的 token
n=1, # 一次生成的结果数量
max_tokens=100, # 每条生成结果的最大 token 数量
presence_penalty=0, # 对已经出现过的 token 的概率进行降权
frequency_penalty=0, # 根据 token 的出现频次 对其生成概率进行降权
logit_bias={}, # 对指定的 token 进行手工加权或降权
)
print(completion.choices[0].message)执行上述代码结果 :
javascript
ChatCompletionMessage(content='Hello! How can I assist you today?', role='assistant', function_call=None, tool_calls=None)