
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开源库如Scikit-learn、TensorFlow和PyTorch。本专栏介绍机器学习的相关算法以及基于Python的算法实现。
文章目录
第一部分 数据准备
一、数据质量校验
如果机器学习中用于分析的基础数据有问题,那么基于这些数据分析得到的结论也会变得不可靠。因为对于机器学习而言,只有使用一份高质量的基础数据,才能得到正确、有用的结论,所以有必要进行数据质量校验。数据质量校验的主要任务是检查原始数据中是否存在噪声数据,常见的噪声数据包括不一致的值、缺失值和异常值。
(一)一致性校验
数据不一致性,是指各类数据的矛盾性、不相容性。数据不一致是由于数据冗余、并发控制不当或各种故障、错误造成的。
对数据进行分析时需要对数据进行一致性校验来确认数据中是否存在不一致的值。
1. 时间校验
时间不一致是指数据在合并或者联立后时间字段出现时间范围、时间粒度、时间格式和时区不一致等情况。
时间范围不一致通常是不同表的时间字段中所包含的时间的取值范围不一致,如表所示,两张表的时间字段的取值范围分别为2016年1月1日---2016年2月29日和2016年1月15日---2016年2月18日,此时如果需要联立这两张表,就需要对时间字段进行补全,否则会产生大量的空值或者会导致报错。

时间粒度不一致通常是由于数据采集时没有设置统一的采集频率,如系统升级后采集频率发生了改变,或者不同系统间的采集频率不一致,导致采集到的数据的时间粒度不一致。
如表所示,某地部分设备的系统尚未升级,采集的数据为每分钟采集一次。另一部分设备已经升级,升级后采集频率提高至每30秒采集一次。如果此时将这两部分数据合并,会导致数据时间粒度不一致的问题。

时间格式不一致通常是不同系统之间设置时间字段时的采用的格式不一致导致时间格式不一致的情况,尤其是当系统中的时间字段使用字符串格式的时候。
如表所示,订单系统的时间字段order_time与结算系统的时间字段ord_time采用了不同的格式导致时间格式不一致。

时区不一致通常是由于在数据传输时的设置不合理,导致时间字段出现不一致的情况,如由于设置在海外的服务器时没有修改时区,导致数据在传输回本地的服务器时由于时区差异造成时间不一致。这种情况下的时间数据往往会呈现较为规律的差异性,即时间可能会有一个固定的差异值。
如表所示,海外服务器时间global_server_time与本地服务器时间local_serve_time由于时区差异造成固定相差2个小时。

2. 字段信息校验
合并不同数据来源的数据时,字段可能存在以下3种不一致的问题。
(1)同名异义
两个名称相同的字段所代表的实际意义不一致。如表所示,数据源A中的ID字段和数据源B中的ID字段分别描述的是菜品编号和订单编号,即描述的是不同的实体。

(2)异名同义
两个名称不同的字段所代表的实际意义是一致的。
如表所示,数据源A中的sales_dt字段和数据源B中的sales_date字段都是描述销售日期的,即A.sales_dt=B.sales_date。

(3)单位不统一
两个名称相同的字段所代表的实际意义一致,但是所使用的单位不一致。
如表所示,数据源A中的sales_amount字段的单位使用是人民币,而数据源B中sales_amount字段的单位使用是美元。

(二)缺失值校验
缺失值是指数据中由于缺少信息而造成的数据的聚类、分组或截断,它指的是现有数据集中某个或某些特征的值是不完全的。
缺失值按缺失的分布模式可以分为完全随机缺失、随机缺失和完全非随机缺失。
- 完全随机缺失(Missing Completely At Random,MCAR)指的是数据的缺失是随机的,数据的缺失不依赖于任何不完全变量或完全变量。
- 随机缺失(Missing At Random,MAR)指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量。
- 完全非随机缺失(Missing Not At Random,MNAR)指的是数据的缺失依赖于不完全变量自身。
在Python中,可以利用如表所示的缺失值校验函数,检测数据中是否存在缺失值。
| 函数名 | 函数功能 | 所属扩展库 | 格式 | 参数及返回值 |
|---|---|---|---|---|
isnull |
判断是否空值 | Pandas | pandas.DataFrame.isnull()或pandas.isnull(obj) | 参数为DataFrame或pandas的Series对象,返回的是一个布尔类型的DataFrame或Series |
notnull |
判断是否非空值 | Pandas | pandas.DataFrame.notnull()或pandas.notnull(obj) | 参数为DataFrame或pandas的Series对象,返回的是一个布尔类型的DataFrame或Series |
count |
非空元素计算 | Pandas | pandas.DataFrame.count(axis=0, level=None, numeric_only=False) | 参数为DataFrame或pandas的Series对象,返回的是DataFrame中每一列非空值个数或Series对象的非空值个数 |
(三)异常值分析
异常值是指样本中的个别值,其数值明显偏离它(或它们)所属样本的其余观测值。
假设数据服从正态分布,一组数据中若与平均值的偏差超过两倍标准差的数据成为异常值,称为四分位距准则(IQR);与平均值的偏差超过3倍标准差的数据成为高度异常的异常值,称为3б原则。
在实际测量中,异常值的产生一般是由疏忽、失误或突然发生的不该发生的原因造成,如读错、记错、仪器示值突然跳动、突然震动、操作失误等。因为异常值的存在会歪曲测量结果,所以有必要检测数据中是否存在异常值。
1. 简单统计质量分析
在Python中可以利用如表所示的函数检测异常值。
| 函数名 | 函数功能 | 所属扩展库 | 格式 | 参数说明 |
|---|---|---|---|---|
percentile |
计算百分位数 | NumPy | numpy.percentile(a, q, axis=None, out=None, overwrite_input=False, interpolation='linear', keepdims=False) | 参数a接收array或类似arrary的对象,无默认值;参数q接收float或类似arrary的对象,必须介于0~100;参数axis表示计算百分位数的轴,可选0或1 |
mean |
计算平均值 | Pandas | pandas.DataFrame.mean(axis=None, skipna=None, level=None, numeric_only=None, **kwargs) | 参数axis接收int,表示所要应用的功能的轴,可选0和1,默认为None;参数skipna接收bool,表示排除空值,默认为None;参数level接收int或级别名称,表示标签所在级别,默认为None |
std |
计算标准差 | Pandas | pandas.DataFrame.std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs) | 参数axis接收int,表示所要应用的功能的轴,可选0和1,默认为None;参数skipna 接收bool,表示排除NA或空值,默认为None;参数level接收int或级别名称,表示标签所在级别,默认为None;参数ddof接收int,表示Delta的自由度,默认为1 |
2. 3σ原则
如果数据服从正态分布,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。
如果数据不服从正态分布,则与平均值的偏差超过两倍标准差的数据为异常值,称为四分位距准则(IQR)。使用IQR准则和3σ原则可以检测ary = (19, 57, 68, 52, 79, 43, 55, 94, 376, 4581, 3648, 70, 51, 38)中的异常值,返回为异常值的元素,并计算元组ary异常值所占的比例:

3. 箱型图分析
箱型图提供了识别异常值的一个标准:异常值通常被定义为小于 Q L − 1.5 Q_L−1.5 QL−1.5 IQR或大于 Q U + 1.5 Q_U+1.5 QU+1.5 IQR的值。绘制箱型图检测便利店销售额数据中的异常值:

Matplotlib提供boxplot()函数,plt.boxplot()函数用于绘制箱线图,其常用参数及解释如下:
| 参数名称 | 参数说明 |
|---|---|
x |
指定绘制箱线图的数据,可以是一个数组或者列表,表示每个箱线图的数据。 |
notch |
指定是否绘制盒形图的缺口,True表示绘制缺口,False表示不绘制,默认为False。 |
sym |
指定异常值的标记符号,可以是一个字符,例如'+'、'o'等。 |
vert |
指定箱线图的方向,True表示纵向绘制,False表示横向绘制,默认为True。 |
widths |
指定箱线图的宽度,可以是一个标量或者与x相同长度的数组。 |
patch_artist |
指定是否使用Patch对象来绘制箱线图,默认为False。 |
labels |
指定每个箱线图的标签,可以是一个数组或者列表,用于标记每个箱线图所代表的含义。 |
showmeans |
指定是否显示均值,True表示显示均值,False表示不显示,默认为False。 |
meanline |
指定是否显示均值的线段,True表示显示,False表示不显示,默认为False。 |
whiskerprops |
指定须线的属性,可以是一个字典,用于设置须线的样式,如颜色、线型等。 |
medianprops |
指定中位数线的属性,可以是一个字典,用于设置中位数线的样式,如颜色、线型等。 |
flierprops |
指定异常值的属性,可以是一个字典,用于设置异常值的样式,如颜色、标记符号等。 |
boxprops |
指定箱体的属性,可以是一个字典,用于设置箱体的样式,如颜色、填充等。 |
capprops |
指定顶端和底端的界限线的属性,可以是一个字典,用于设置界限线的样式,如颜色、线型等。 |
whiskers |
指定须的长度,可以是一个标量或者数组,用于设置须的长度。 |
caps |
指定顶端和底端的界限线的长度,可以是一个标量或者数组,用于设置界限线的长度。 |
showfliers |
指定是否显示异常值,True表示显示异常值,False表示不显示,默认为True。 |
bootstrap |
指定是否使用自助法计算置信区间,可以是一个整数,表示自助采样的次数,默认为None。 |
usermedians |
指定中位数的位置,可以是一个数组或者列表,用于指定每个箱线图的中位数位置。 |
conf_intervals |
指定置信区间的范围,可以是一个数组或者列表,用于指定每个箱线图的置信区间。 |
二、数据分布与趋势探查
(一)分布分析
数据质量校验之后,可以通过计算特征量、绘制图表等方式对数据进行特征分析。对数据进行分布分析,能够揭示数据的分布特征和分布类型,显示其分布情况。分布分析主要分为两种:对定量数据和对定性数据的分布分析。对于定量数据,可以通过绘制频率分布表、频率分布直方表、茎叶图等进行分布分析,这些图可以直观地分析数据是对称分布或是非对称分布,也可以发现某些特大或特小的可疑值;对于定性数据,可以通过绘制饼图或柱形图对其分布情况进行直观地分析。
1. 定量数据分布分析
定量数据的分布分析,一般按照以下步骤进行。
- 求极差
- 决定组距与组数
- 决定分点
- 列出频率分布表
- 绘制频率分布直方图
进行定量数据分布分析时,分组需要遵循的主要原则如下。
- 组与组之间必须互斥
- 所有分组必须将所有数据包含在内
- 各组的组宽尽可能相等
2. 定性数据分布分析
对于定性变量进行分布分析,通常根据变量的分类来分组,然后统计分组的频数或频率,可以采用饼图和柱形图来描述定性变量的分布。
饼图的每一个扇形部分的面积代表一个类型在总体中所占的比例,根据定性变量的类型数目把饼图分成几个部分,每一部分的大小与每一类型的频数成正比;柱形图的高度表示每一类型的频率或频数,与直方图不同的是柱形图的宽度没有任何意义。
(二)对比分析
对比分析法也称为比较分析法,是把客观的事物加以比较,以达到认识事物的本质和规律并做出正确的评价的目的。对比分析法通常是将两个相互联系的指标数据进行比较,从数量上展示和说明研究对象规模的大小、水平的高低、速度的快慢以及各种关系是否协调。在对比分析中,选择合适的对比标准是十分关键的步骤,对比标准的选择决定了是否能够得到可靠的评价结果。
1. 对比分析的形式
(1)绝对数比较
绝对数比较是利用绝对数进行对比,从而寻找差异的一种方法。
(2)相对数比较
相对数比较是将两个有联系的指标进行对比计算的,用以反映客观现象之间数量联系程度的综合指标,其数值表现为相对数。由于研究目的和对比基础不同,相对数可以分为以下几种。
① 动态相对数。将同一现象在不同时期的指标数值对比,用以说明发展方向和变化的速度。
② 强度相对数。将两个性质不同但有一定联系的总量指标对比,用以说明现象的强度、密度和普遍程度。
③ 比例相对数。将同一总体内不同部分的数值对比,表明总体内各部分的比例关系。
④ 比较相对数。将同一时期两个性质相同的指标数值对比,说明同类现象在不同空间条件下的数量对比关系。
⑤ 计划完成程度相对数。某一时期实际完成数与计划数对比,用以说明计划完成程度。
⑥ 结构相对数。将同一总体内的部分数值与全部数值对比求得比重,用以说明事物的性质、结构或质量。
相联系的两个指标对比,表明现象的强度、密度和普遍程度。按说明对象的不同,对比分析可分为单指标对比(简单评价)和多指标评价(综合评价)。对比分析在实际操作过程中需要遵循如下原则。
① 指标的内涵和外延可比。
② 指标的时间范围可比。
③ 指标的计算方法可比。
④ 总体性质可比。
若两个完全不具有可比性的对象,摆在一起进行对比分析,则会是徒劳无功。
2. 对比分析的标准
(1)计划标准
计划标准即将指定的数据与对应的计划数、定额数和目标数对比。
(2)经验或理论标准
经验标准是通过对大量历史资料的归纳总结而得到的标准,如衡量生活质量的恩格尔系数。理论标准是将已知理论经过推理后得出的一个标准和依据。
(3)时间标准
时间标准即选择不同时间的指标数值作为对比标准,最常用到的是与上年同期比较即"同比",也可以与前一时期比较,此外还可以与达到历史最好水平的时期或历史上一些关键时期进行比较。
(4)空间标准
空间标准即选择不同空间指标数据进行比较,主要包括与相似的空间比较、与先进空间比较和与扩大的空间比较三种。
(三)描述性统计分析
描述性统计分析是对一组数据的各种特征进行分析,以便于描述测量样本的各种特征及其所代表的总体的特征。利用统计指标对定量数据进行统计描述,通常从数据的集中趋势和离散程度两个方面进行分析。集中趋势是指一组数据向着一个中心靠拢的程度,也体现了数据中心所在的位置,集中趋势的度量使用比较广泛的是均值、中位数。离散程度的度量常用的是极差、四分位差、方差、标准差和变异系数。
1. 集中趋势度量
(1)均值
均值是指所有数据的平均值。假设原始数据为 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,⋯,x_n\} {x1,x2,⋯,xn},如果求 n n n个原始观察数据的平均数,那么计算公式如下:
m e a n ( x ) = x ‾ = ∑ x i n mean(x)=\overline{x}=\frac{\sum x_i}{n} mean(x)=x=n∑xi 为了反映在均值中不同成分所占的不同重要程度,为数据集中的每一个 x i x_i xi赋予 w i w_i wi,这就得到了加权均值的计算公式,如下:
m e a n ( x ) = x ‾ = ∑ w i x i ∑ w i mean(x)=\overline{x}=\frac{\sum w_ix_i}{\sum w_i} mean(x)=x=∑wi∑wixi 类似地,频率分布表的平均数可以使用如下式计算: m e a n ( x ) = x ‾ = ∑ f i x i mean(x)=\overline{x}=\sum f_ix_i mean(x)=x=∑fixi 在上方的公式中, x i x_i xi为第 i i i个组段的组中值, f i f_i fi为 i i i个组段的频率。这里的 f i f_i fi起了权重的作用。
作为一个统计量,均值的主要问题是对极端值很敏感。如果数据中存在极端值或数据是偏态分布的,那么均值就不能很好地度量数据的集中趋势。为了消除少数极端值的影响,可以使用截断均值或者中位数来度量数据的集中趋势。截断均值是去掉高、低极端值之后的平均数。
(2)中位数
中位数是将一组观察值从小到大按顺序排列,如果原始数据个数为奇数,那么位于中间的那个数据即中位数,如果原始数据个数为偶数,那么中间两个数的均值为中位数。在全部数据中,小于和大于中位数的数据个数相等。
将某一数据集 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,⋯,x_n\} {x1,x2,⋯,xn} 从小到大排序: { x ( 1 ) , x ( 2 ) , ⋯ , x ( n ) } \{x_{(1)},x_{(2)},⋯,x_{(n)}\} {x(1),x(2),⋯,x(n)}。
当 n n n为奇数时,中位数计算公式如下: M = x n + 1 2 M=x_{\frac{n+1}{2}} M=x2n+1 当 n n n为偶数时,中位数计算公式如下: M = 1 2 x ( n 2 ) + x ( n 2 + 1 ) M=\frac{1}{2}\leftx_{(\\frac{n}{2})}+x_{(\\frac{n}{2}+1)}\\right M=21x(2n)+x(2n+1)
(3)众数
众数是指数据集中出现最频繁的值。众数并不经常用来度量定性变量的中心位置,更适用于定量变量。众数不具有唯一性。当然,众数一般用于离散型变量而非连续型变量。
2. 离散程度度量
(1)极差
利用极值计算极差,计算公式如下: 极差 = 最大值 − 最小值 极差=最大值-最小值 极差=最大值−最小值 极差对数据集的极端值非常敏感,并且忽略了位于最大值与最小值之间的数据是如何分布的。
(2)四分位差
四分位差是指上四分位数和下四分位数之差。四分位差反映了中间50%数据的离散程度,其数值越小,说明数据越集中,即数据的变异程度越小;反之,说明数据越离散,数据的变异程度越大。
(3)方差(标准差)
方差是各样本相对均值的偏差平方和的平均值,如左式,而标准差是方差的开平方值,如右式。方差和标准差是描述数据离散程度最常用的指标,它们利用了样本的全部信息去描述数据取值的分散性。 s 2 = ∑ ( x i − x ‾ ) 2 n , s = ∑ ( x i − x ‾ ) 2 n s^2=\frac{\sum{(x_i-\overline{x})^2}}{n}, s=\sqrt{\frac{\sum{(x_i-\overline{x})^2}}{n}} s2=n∑(xi−x)2,s=n∑(xi−x)2
(4)变异系数
变异系数度量标准差相对于均值的离中趋势,它是刻画数据相对分散性的一种度量,记为CV,计算公式如下: C V = s x ‾ × 100 % CV=\frac{s}{\overline{x}}\times 100\% CV=xs×100% 变异系数主要用来比较两个或多个具有不同单位或不同波动幅度的数据集的离中趋势,即数据偏离其中心(平均数)的趋势。
Pandas库的describe()方法可以给出一些基本的统计量,包括均值、标准差、最大值、最小值、分位数等。describe()方法的基本使用格式及参数说明如下:
pandas.DataFrame.describe(percentiles=None, include=None, exclude=None, datetime_is_numeric=False)
| 参数名称 | 参数说明 |
|---|---|
percentiles |
接收int。表示要包含在输出中的百分比,须介于0~1。默认为None |
include |
接收类似dtype的列表。表示包括在结果中的数据类型的白名单。默认为None |
exclude |
接收类似dtype的列表型。表示从结果中忽略的数据类型黑名单。默认为None |
datetime_is_numeric |
接收bool。表示是否将datetime dtypes视为数字。默认为False |
(四)周期性分析
周期性分析(Cyclical Analysis)对具有周期性变动的数据进行的分析,可以探索某个变量是否随着时间的变化而呈现出某种周期性变化趋势。周期性趋势按时间粒度的常用划分方式分为年度周期性趋势、季周期性趋势、月度周期性趋势、周度周期性趋势和天、小时周期性趋势。对数据进行周期性数据分析,能达到掌握数据周期性变动规律的目的。
利用某车站2016年1月1日--2016年3月20日每天客流量部分数据,对该数据进行周期性数据分析,观察该车站客流量规律,如图所示。由图可看出,该车站客流量以假期日为周期呈现周期性。客流量在工作日期间较为平稳,小长假期间明显增多,出现这种情况的原因是假期为人们出游的高峰期。

(五)贡献度分析
贡献度分析又称帕累托分析,它的原理是帕累托法则又称二八定律。同样的投入放在不同的地方会产生不同的效益。对一个公司来说,80%的利润常常来自于20%最畅销的产品,而其他80%的产品只产生了20%的利润。
贡献度分析需要绘制帕累托图,帕累托图又称排列图、主次图,是按照发生频率大小顺序绘制的直方图,表示有多少结果是由已确认类型或范畴的原因造成,可以用来分析质量问题,确定产生质量问题的主要因素。帕累托图用双直角坐标系表示,左边纵坐标表示频数,右边纵坐标表示频率,分析线表示累积频率,横坐标表示影响质量的各项因素,按影响程度的大小(既出现的频数多少)从左到右排列,该图可以判断影响质量的主要因素。
应用贡献度分析对某餐饮企业的10种菜品某月的盈利数据进行分析,找出盈利排在前80%的菜品,如图所示。由图可看出,菜品A1~A7总盈利额达到了该月盈利额的85%,在这种情况下,应该加大菜品A1~A7的成本投入,减少A8~A10的成本投入,这样可以获得更高的盈利额。

(六)相关性分析
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。相关性不等于因果性,也不是简单的个性化,相关性涵盖的范围和领域非常广泛,而且相关性在不同的学科里面定义也有很大的差异。相关性分析的方法有很多,可以直接通过数据可视化进行判断,也可以通过计算变量之间的相关系数进行判断。
1. 散点图和相关性热力图
判断两个变量是否具有线性相关关系的最直观的方法是绘制散点图,如图所示。

有时需要考察多个变量之间的相关关系,如果利用散点图进行相关性分析,那么需要对变量两两绘制散点图,这样会让工作变得很麻烦,相关性热力图是解决这个麻烦的好办法,相关性热力图可以快速发现多个变量之间的两两间相关性,相关性热力图如图所示。

以鸢尾花数据集为例:
python
#使用数据集时,以鸢尾花数据集为例
from sklearn.datasets import load_iris
iris=load_iris()
import pandas as pd
iris_data=pd.DataFrame(iris.data,columns=iris.feature_names) #将数据集转换为DataFrame格式
iris_data['target']=iris.target_names[iris.target] #将数据集的标签转换为DataFrame格式
import seaborn as sns
sns.pairplot(iris_data,hue='target',palette='husl') #根据目标类别着色绘制散点图矩阵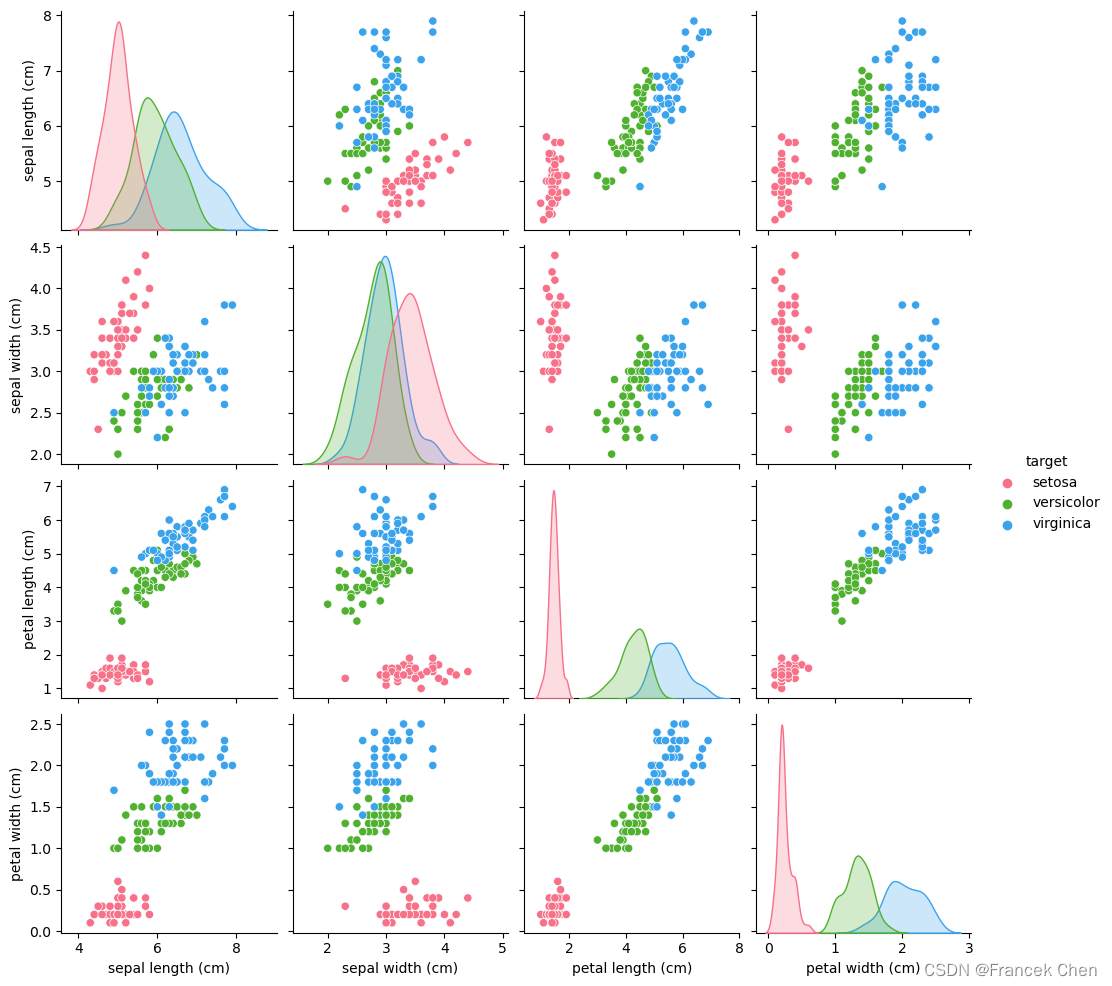
2. 相关系数
相关系数最早是由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 表示。由于研究对象的不同,相关系数有多种定义方式,比较常见的有Pearson相关系数、Spearman相关系数和Kendall等级相关系数。
(1)Pearson相关系数
Pearson相关系数是衡量两个数据集合是否在一条线上面,用于衡量定距变量间的线性关系。假设变量 x x x和 y y y分别可以表示为 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,⋯,x_n\} {x1,x2,⋯,xn} 和 { y 1 , y 2 , ⋯ , y n } \{y_1,y_2,⋯,y_n\} {y1,y2,⋯,yn}, x x x和 y y y之间的Pearson相关系数如下。 r = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 n ( x i − x ‾ ) 2 ( y i − y ‾ ) 2 r=\frac{\begin{aligned}\sum_{i=1}^n(x_i-\overline{x})(y_i-\overline{y})\end{aligned}}{\begin{aligned}\sqrt{\sum_{i=1}^n(x_i-\overline{x})^2(y_i-\overline{y})^2}\end{aligned}} r=i=1∑n(xi−x)2(yi−y)2 i=1∑n(xi−x)(yi−y) Pearson相关系数 r r r的取值范围及变量相关强度判断规则如表所示。

(2)Spearman相关系数
Spearman相关系数适用于不服从正态分布或者总体分布类型未知的数据,Spearman相关系数也称等级相关系数或秩相关系数,用于描述两个变量之间关联的程度与方向。假设变量 x x x和 y y y分别可以表示为 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,⋯,x_n\} {x1,x2,⋯,xn} 和 { y 1 , y 2 , ⋯ , y n } \{y_1,y_2,⋯,y_n\} {y1,y2,⋯,yn}, x x x和 y y y之间的Spearman相关系数如下。 r s = 1 − 6 ∑ i = 1 n ( R i − Q i ) 2 n ( n 2 − 1 ) r_s=1-\frac{\begin{aligned}6\sum_{i=1}^n(R_i-Q_i)^2\end{aligned}}{n(n^2-1)} rs=1−n(n2−1)6i=1∑n(Ri−Qi)2 将两个变量的值按照由小到大(或由大到小)的顺序排列,得到两个变量对应的秩, R i R_i Ri表示 x i x_i xi的秩次, Q i Q_i Qi表示 y i y_i yi的秩次。假设变量 x x x取值已由小到大排序,秩次的计算如表所示。

如果遇到相同的取值,那么计算秩次时需要取它们排序后所在位置的平均值。根据Spearman相关系数的计算公式可以看出,如果两个变量具有严格单调的函数关系,那么这两个变量的Spearman相关系数值就为1或--1,此时称这两个变量完全Spearman相关。
研究表明,在正态分布假定下,Spearman相关系数与Pearson相关系数在效率上是等价的,而对于连续测量数据,更适合用Pearson相关系数来进行分析。
(3)Kendall等级相关系数
Kendall等级相关系数是用于反映分类相关变量的相关指标,适用于两个变量均为有序分类的情况,对相关的有序变量进行非参数性相关检验,取值范围为-1,1。Kendall等级相关系数又称和谐系数,是表示多列等级变量相关程度的一种方法,该方法的数据通常采用等级评定的方法收集。
(4)判定系数
判定系数是相关系数的平方,表示为 r 2 r^2 r2,用于衡量回归方程对被解释变量 y y y的解释程度,与相关系数一致,判定系数也假定数据服从正态分布。判定系数的取值范围是0~1。 r 2 r^2 r2越接近1,说明两个变量之间的相关性越强; r 2 r^2 r2越接近0,说明两个变量之间几乎不存在直线相关关系。
Pandas库的corr()方法可计算出列与列、变量与变量之间的成对相关系数,但不包括空值。corr()方法的基本使用格式和参数说明如下:
pandas.DataFrame.corr(method = 'pearson', min_periods = 1)
| 参数名称 | 参数说明 |
|---|---|
method |
接收方法的名称。表示计算相关系数所要使用的方法,可选pearson、kendall、spearman。默认为pearson |
min_periods |
接收int。表示每对列必须具有有效结果的最小观察数。默认为1 |
三、数据清洗
数据清洗是数据预处理中的过程,是发现并改正数据中可识别的错误的最后一道程序,目的是过滤或修改不符合要求的数据,主要包括删除原始数据中的无关数据、重复数据,平滑噪声数据,处理缺失值、异常值等。
(一)重复值处理
1. 记录重复
记录重复是指数据中某条记录的一个或多个属性的值完全相同。
在某企业的母婴发货记录表中,利用列表(list)对用品名称去重,查看所有的品牌名称:
python
def delRep(list1):
list2 = []
for i in list1:
if i not in list2:
list2.append(i)
return list2
names = list(data['品牌名称']) # 提取品牌名称
name = delRep(names) # 使用自定义的去重函数去重除了利用列表去重之外,还可以利用集合(set)元素为唯一的特性去重:
python
print('去重前品牌总数为:', len(names))
name_set = set(names) # 利用set的特性去重
print('去重后品牌总数为:', len(name_set)) Pandas提供了一个名为drop_duplicates的去重方法。该方法只对DataFrame或Series类型有效。drop_duplicates()方法的基本使用格式和参数说明如下:
pandas.DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
| 参数名称 | 参数说明 |
|---|---|
subset |
接收str或sequence。表示进行去重的列。默认为None |
keep |
接收特定str。表示重复时保留第几个数据。first:保留第一个。last:保留最后一个。false:只要有重复都不保留。默认为first |
inplace |
接收bool。表示是否在原表上进行操作。默认为False |
2. 属性内容重复
属性内容重复是指数据中存在一个或多个属性名称不同,但数据完全相同。当需要去除连续型属性重复时,可以利用属性间的相似度,去除两个相似度为1的属性的其中一个:
python
corr_ = data[['品牌标签', '仓库标签']].corr(method='kendall')
print('kendall相似度为:\n', corr_) 除了使用相似度矩阵进行属性去重之外,可以通过Pandas库的DataFrame.equals()方法进行属性去重。DataFrame.equals()方法的基本使用格式和参数说明如下:
pandas.DataFrame.equals(other)
| 参数名称 | 参数说明 |
|---|---|
other |
接收Series或DataFrame。表示要与第一个进行比较的另一个Series或DataFrame。无默认值 |
(二)缺失值处理
缺失值处理的方法可以分为3种,删除、数据插补和不处理。
1. 删除
删除即删除存在缺失值的个案、删除存在缺失数据的样本、删除有过多缺失数据的变量,如果通过简单的删除一小部分数据能够达到既定目标,那么删除是处理缺失值最有效的方法,如果缺失的数据属于完全随机缺失,使用删除法处理的后果仅仅是减少了样本量,尽管会导致信息量减少,但是利用删除法处理这种缺失数据也是有效的。
删除法有较大的局限性,该方法通过减少历史数据换取数据的完备,这样会造成资源的大量浪费,丢弃了大量隐藏在这些数据中的信息,如果原始数据集包含的样本比较少,那么删除少量的样本就可能会导致分析结果的客观性和正确性受到影响。
2. 数据插补
数据插补即利用某种方法将缺失数据补齐,常用的数据插补方法如表所示。

数据插补即利用某种方法将缺失数据补齐,常用的数据插补方法如表所示。

(1)分段线性插值
分段线性插值即将给定样本区间分成多个不同的区间,记为 x i , x i + 1 x_i,x_{i+1} xi,xi+1,在每个区间上的线性方程如下,函数值即插补值。
y = y i + 1 − y i x i + 1 − x i ( x − x i ) + y i = x − x i + 1 x i − x i + 1 y i + x − x i x i + 1 − x i y i + 1 \begin{aligned} y&=\frac{y_{i+1}-y_i}{x_{i+1}-x_i}(x-x_i)+y_i \\2ex &=\frac{x-x_{i+1}}{x_i-x_{i+1}}y_i+\frac{x-x_i}{x_{i+1}-x_i}y_{i+1} \end{aligned} y=xi+1−xiyi+1−yi(x−xi)+yi=xi−xi+1x−xi+1yi+xi+1−xix−xiyi+1 分段线性插值在插补速度和误差方面取得了很好的平衡,插值函数具有连续性,然而由于在已知点的斜率是不变的,因此插值结果并不光滑。
(2)拉格朗日插值
根据数学知识可知,对于空间上已知的 n n n个点可以找到一个 n − 1 n−1 n−1 次多项式 y = a 0 + a 1 x + a 2 x 2 + ⋯ + a n − 1 x n − 1 y=a_0+a_1x+a_2x^2+⋯+a_{n−1}x^{n−1} y=a0+a1x+a2x2+⋯+an−1xn−1,使此多项式曲线过这 n n n个点。
a . 求已知的过 n n n个点的 n − 1 n−1 n−1 次多项式如下。 y = a 0 + a 1 x + a 2 x 2 + ⋯ + a n − 1 x n − 1 y=a_0+a_1x+a_2x^2+\cdots+a_{n-1}x^{n-1} y=a0+a1x+a2x2+⋯+an−1xn−1 将 n n n个点的坐标 ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) (x_1,y_1),(x_2,y_2),⋯,(x_n,y_n) (x1,y1),(x2,y2),⋯,(xn,yn) 代入多项式函数,得到的公式如下。 { y 1 = a 0 + a 1 x 1 + a 2 x 1 2 + ⋯ + a n − 1 x 1 n − 1 y 2 = a 0 + a 1 x 2 + a 2 x 2 2 + ⋯ + a n − 1 x 2 n − 1 . . . . . . y n = a 0 + a 1 x n + a 2 x n 2 + ⋯ + a n − 1 x n n − 1 \left\{ \begin{array}{l} y_1=a_0+a_1x_1+a_2x_1^2+\cdots+a_{n-1}x_1^{n-1} \\1ex y_2=a_0+a_1x_2+a_2x_2^2+\cdots+a_{n-1}x_2^{n-1} \\1ex ...... \\1ex y_n=a_0+a_1x_n+a_2x_n^2+\cdots+a_{n-1}x_n^{n-1} \end{array} \right. ⎩ ⎨ ⎧y1=a0+a1x1+a2x12+⋯+an−1x1n−1y2=a0+a1x2+a2x22+⋯+an−1x2n−1......yn=a0+a1xn+a2xn2+⋯+an−1xnn−1 解出拉格朗日插值多项式如下。 y = y 1 ( x − x 2 ) ( x − x 3 ) ⋯ ( x − x n ) ( x 1 − x 2 ) ( x 1 − x 3 ) ⋯ ( x 1 − x n ) + y 2 ( x − x 1 ) ( x − x 3 ) ⋯ ( x − x n ) ( x 2 − x 1 ) ( x 2 − x 3 ) ⋯ ( x 2 − x n ) + . . . . . . + y n ( x − x 1 ) ( x − x 3 ) ⋯ ( x − x n − 1 ) ( x n − x 1 ) ( x n − x 3 ) ⋯ ( x n − x n − 1 ) = ∑ i = 0 n y i ( ∏ j = 0 , j ≠ i n x − x j x i − x j ) \begin{aligned} y&=y_1\frac{(x-x_2)(x-x_3)\cdots(x-x_n)}{(x_1-x_2)(x_1-x_3)\cdots(x_1-x_n)}+y_2\frac{(x-x_1)(x-x_3)\cdots(x-x_n)}{(x_2-x_1)(x_2-x_3)\cdots(x_2-x_n)}+......+y_n\frac{(x-x_1)(x-x_3)\cdots(x-x_{n-1})}{(x_n-x_1)(x_n-x_3)\cdots(x_n-x_{n-1})}\\2ex &=\sum_{i=0}^n y_i\left(\prod_{j=0,j≠i}^n\frac{x-x_j}{x_i-x_j}\right) \end{aligned} y=y1(x1−x2)(x1−x3)⋯(x1−xn)(x−x2)(x−x3)⋯(x−xn)+y2(x2−x1)(x2−x3)⋯(x2−xn)(x−x1)(x−x3)⋯(x−xn)+......+yn(xn−x1)(xn−x3)⋯(xn−xn−1)(x−x1)(x−x3)⋯(x−xn−1)=i=0∑nyi j=0,j=i∏nxi−xjx−xj b . 将缺失的函数值对应的点 代入插值多项式得到缺失值的近似值 y y y。
拉格朗日插值公式结构紧凑,在理论分析中很方便,但是当插值节点增减时,插值多项式就会随之变化,这在实际计算中是很不方便的,为了克服这一缺点,提出了牛顿插值法。
(3)牛顿插值
在区间 a , b a,b a,b 上,函数 f ( x ) f(x) f(x)于一个节点 x i x_i xi的零阶差商定义如下。 f x i = f ( x i ) fx_i=f(x_i) fxi=f(xi) f ( x ) f(x) f(x)关于两个节点 x i x_i xi和 x j x_j xj的一阶差商定义如下。 f x i , x j = f ( x j ) − f ( x i ) x j − x i fx_i,x_j=\frac{f(x_j)-f(x_i)}{x_j-x_i} fxi,xj=xj−xif(xj)−f(xi) 一般地, k k k阶差商就是 k − 1 k−1 k−1 阶差商的差商,称如下公式为 f ( x ) f(x) f(x)关于 k + 1 k+1 k+1 个节点 x 1 , x 2 , ⋯ , x k x_1,x_2,\cdots,x_k x1,x2,⋯,xk 的 k k k阶差商。 f x 0 , x 1 , ⋯ , x k = f x 1 , x 2 , ⋯ , x k − f x 0 , x 1 , ⋯ , x k − 1 x k − x 0 fx_0,x_1,\\cdots,x_k=\frac{fx_1,x_2,\\cdots,x_k-fx_0,x_1,\\cdots,x_{k-1}}{x_k-x_0} fx0,x1,⋯,xk=xk−x0fx1,x2,⋯,xk−fx0,x1,⋯,xk−1 具体可以按照如表所示的格式有规律地计算差商。

借助差商的定义,牛顿插值多项式可以表示为如下。 N n ( x ) = f x 0 w 0 ( x ) + f x 0 , x 1 w 1 ( x ) + f x 0 , x 1 , x 2 w 2 ( x ) + ⋯ + f x 0 , x 1 , ⋯ , x n w n ( x ) N_n(x)=fx_0w_0(x)+fx_0,x_1w_1(x)+fx_0,x_1,x_2w_2(x)+\cdots+fx_0,x_1,\\cdots,x_nw_n(x) Nn(x)=fx0w0(x)+fx0,x1w1(x)+fx0,x1,x2w2(x)+⋯+fx0,x1,⋯,xnwn(x) 牛顿插值多项式的余项公式可以表示为如下。 R n ( x ) = f x , x 0 , x 1 , ⋯ , x n w n + 1 ( x ) R_n(x)=fx,x_0,x_1,\\cdots,x_nw_{n+1}(x) Rn(x)=fx,x0,x1,⋯,xnwn+1(x) 其中, w 0 ( x ) = 1 w_0(x)=1 w0(x)=1, w k ( x ) = ( x − x 0 ) ( x − x 1 ) ⋯ ( x − x k − 1 ) ( k = 1 , 2 , ⋯ , n + 1 ) w_k(x)=(x-x_0)(x-x_1)\cdots(x-x_{k-1}) (k=1,2,\cdots,n+1) wk(x)=(x−x0)(x−x1)⋯(x−xk−1)(k=1,2,⋯,n+1),对于区间 a , b a,b a,b 中的任一点 x x x,则有 f ( x ) = N n ( x ) + R n ( x ) f(x)=N_n(x)+R_n(x) f(x)=Nn(x)+Rn(x)。
牛顿插值法也是多项式插值,但采用了另一种构造插值多项式的方法,与拉格朗日插值相比,具有承袭性和易于变动节点的特点。本质上来说,两者给出的结果是一样的(相同次数、相同系数的多项式),只不过表示的形式不同。
3. 不处理
若缺失的特征不重要,不会进入后续的建模步骤,或者算法自身能够处理数据缺失的情况。如随机森林,在这种情况下不需要对缺失数据做任何的处理,这种做法的缺点是在算法的选择上有局限。
在Python中,可以利用如表所示的缺失值插补函数和方法插补缺失值。
| 名称 | 功能 | 所属扩展库 | 格式 | 参数 |
|---|---|---|---|---|
fillna |
将所有空值使用指定值替换 | Pandas | D.fillna(value=None, inplace=False) | value表示用于填补空值的scalar、dict、Series或者DataFrame对象,inplace表示是否用填补空值后的DataFrame替换原对象,默认为False |
interpolate |
使用指定方法插补空值 | Pandas | DataFrame.interpolate(method='linear', inplace=False) | method表示用于插补的方法,默认为linear;inplace表示是否用填补空值后的DataFrame替换原对象,默认为False |
dropna |
删除对象中的空值 | Pandas | DataFrame.dropna(how='any', inplace=False) | how参数为删除空值的方式,默认为any,表示删除全部空值 |
(三)异常值处理
在数据预处理时,异常值是否剔除,需视具体情况而定,因为有些异常值可能蕴含着有用的信息。异常值处理常用方法如表所示。

将含有异常值的记录直接删除这种方法简单易行,但缺点也很明显,在观测值很少的情况下,这种处理方式会造成样本量不足,可能会改变变量的原有分布,从而造成分析结果的不准确。
视为缺失值处理的好处是可以利用现有变量的信息,对异常值(缺失值)进行填补。很多情况下,要先分析异常值出现的可能原因,再判断异常值是否应该舍弃,如果是正确的数据,可以直接在具有异常值的数据集上进行建模。
四、数据合并
数据合并即通过多表合并、分组聚合等方式将不同的有关联性的数据信息合并在同一张表中。
(一)多表合并
1. 堆叠合并数据
数据堆叠就是简单地把两个表拼在一起,也可以称为轴向连接、绑定或连接。根据连接轴不同的方向,数据堆叠可以分为横向堆叠和纵向堆叠。
横向堆叠:

纵向堆叠:

横向堆叠即将两个表在X轴向连接到一起,纵向堆叠是将两个数据表在Y轴向上拼接,可以利用Python中Pandas库的concat函数对两个表进行横向或者纵向堆叠,其基本语法格式如下。
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
concat函数常用的参数及其说明如表所示。
| 参数名称 | 说明 |
|---|---|
objs |
接收多个Series,DataFrame,Panel的组合,无默认 |
axis |
接收0或1,表示连接的轴向,默认为0 |
join |
接收inner或outer,表示其他轴向上的索引是按交集(inner)还是并集(outer)进行合并,默认为outer |
join_axes |
接收Index对象,表示用于其他n-1条轴的索引,不执行并∕交集运算,默认为None |
ignore_index |
接收bool,表示是否不保留连接轴上的索引,产生一组新索引range(total_length),默认为False |
keys |
接收sequence,表示与连接对象有关的值,用于形成连接轴向上的层次化索引,默认为None |
levels |
接收包含多个sequence的list,在指定keys参数后,指定用作层次化索引时各级别中的索引,默认为None |
names |
接收list,在设置了keys和levels参数后,用于创建分层级别的名称,默认为None |
verify_integrity |
接收bool,表示是否检查结果对象新轴上的重复情况,如果发现重复则引发异常,默认为False |
使用concat函数时,当axis=1时将不同表中数据做行对齐,而在默认情况下,即axis=0时将不同表中数据做列对齐,将不同行索引的两张或多张表纵向合并。
当需要合并的表索引或列名不完全一样时,可以使用join参数选择是内连接还是外连接,在内连接的情况下,仅仅返回索引或列名的重叠部分;在外连接的情况下,则显示索引或列名的并集部分数据,不足的地方则使用空值填补。当需要合并的表含有的主键或列名完全一样时,不论join参数取值是inner或者outer,结果都是将表格完全按照X轴或Y轴拼接起来。
如果要实现纵向堆叠的两张表列名称完全一致,也可以利用append方法实现堆叠的目标,其基本语法格式如下。
pandas.DataFrame.append(self, other, ignore_index=False, verify_integrity=False)
append函数常用的参数及其说明如表所示。
| 参数名称 | 说明 |
|---|---|
other |
接收DataFrame或Series。表示要添加的新数据。无默认 |
ignore_index |
接收bool。如果输入True,会对新生成的DataFrame使用新的索引(自动产生)而忽略原来数据的索引。默认为False |
verify_integrity |
接收bool。如果输入True,那么当ignore_index为False时,会检查添加的数据索引是否冲突,如果冲突,则会添加失败。默认为False |
2. 主键合并数据
主键合并即一个或多个键将两个数据集的行连接起来,如果两张包含不同字段的表含有同一个主键,那么可以根据相同的主键将两张表拼接起来,结果集列数为两张标的列数和减去连接键的数量,如图所示。

Python中Pandas库的merge函数和join方法均可以实现主键合并,merge函数的基本语法格式如下。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False)
merge函数常用的参数及其说明如表所示。
| 参数名称 | 说明 |
|---|---|
left |
接收DataFrame或Series。表示要添加的新数据。无默认 |
right |
接收DataFrame或Series。表示要添加的新数据。无默认 |
how |
接收inner,outer,left,right。表示数据的连接方式。默认为inner |
on |
接收str或sequence。表示两个数据合并的主键(必须一致)。默认为None |
left_on |
接收str或sequence。表示left参数接收数据用于合并的主键。默认为None |
right_on |
接收str或sequence。表示right参数接收数据用于合并的主键。默认为None |
left_index |
接收bool。表示是否将left参数接收数据的index作为连接主键。默认为False |
right_index |
接收bool。表示是否将right参数接收数据的index作为连接主键。默认为False |
sort |
接收bool。表示是否根据连接键对合并后的数据进行排序。默认为False |
suffixes |
接收tuple。表示用于追加到left和right参数接收数据重叠列名的尾缀。默认为('_x', '_y') |
join方法实现主键合并的方式不同于merge函数,join方法实现主键合并时要求不同表中的主键名称必须相同,其基本语法格式如下。
pandas.DataFrame.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
join方法常用的参数及其说明如表所示。
| 参数名称 | 说明 |
|---|---|
other |
接收DataFrame、Series或者包含了多个DataFrame的list。表示参与连接的其他DataFrame。无默认值 |
on |
接收列名或者包含列名的list或tuple。表示用于连接的列名。默认为None |
how |
接收特定str。inner代表内连接,outer代表外连接,left和right分别代表左连接和右连接。默认为inner |
lsuffix |
接收str。表示用于追加到左侧重叠列名的末尾。无默认值 |
rsuffix |
接收str。表示用于追加到右侧重叠列名的末尾。无默认值 |
sort |
根据连接键对合并后的数据进行排序,默认为True |
3. 重叠合并数据
数据分析和处理过程中偶尔会出现两份数据的内容几乎一致的情况,但是某些属性在其中一张表上是完整的,而在另外一张表上的数据则是缺失的。这时除了使用将数据一对一比较,然后进行填充的方法外,还有一种方法就是重叠合并。

(二)分组聚合
分组是使用特定的条件将元数据进行划分为多个组。聚合是对每个分组中的数据执行某些操作,最后将计算结果进行整合。

1. 使用groupby()方法拆分数据
groupby()方法提供的是分组聚合步骤中的拆分功能,能够根据索引或字段对数据进行分组。其基本使用格式和常用参数说明如下:
pandas.DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
| 参数名称 | 参数说明 |
|---|---|
by |
接收list、str、mapping或generator。用于确定进行分组的依据。如果传入的是一个函数,那么对索引进行计算并分组;如果传入的是一个字典或Series,那么字典或Series的值用来作为分组依据;如果传入一个NumPy数组,那么数据的元素作为分组依据;如果传入的是字符串或字符串列表,那么使用这些字符串所代表的字段作为分组依据。无默认值 |
axis |
接收int。表示操作的轴向,默认对列进行操作。默认为0 |
level |
接收int或索引名。表示标签所在级别。默认为None |
as_index |
接收bool。表示聚合后的聚合标签是否以DataFrame索引形式输出。默认为True |
sort |
接收bool。表示是否对分组依据、分组标签进行排序。默认为True |
2. 使用agg()方法聚合数据
agg()方法和aggregate()方法都支持对每个分组应用某函数,包括Python内置函数或自定义函数。针对DataFrame的agg()方法与aggregate()方法的基本使用格式和常用参数说明如下:
pandas.DataFrame.agg(func, axis=0, *args, **kwargs)
pandas.DataFrame.aggregate(func, axis=0, *args, **kwargs)
| 参数名称 | 参数说明 |
|---|---|
func |
接收list、dict、function。表示应用于每行或每列的函数。无默认值 |
axis |
接收0或1。代表操作的轴向。默认为0 |
3. 使用apply()方法聚合数据
apply()方法类似于agg()方法,能够将函数应用于每一列。不同之处在于,与agg()方法相比,apply()方法传入的函数只能够作用于整个DataFrame或Series,而无法像agg()方法一样能够对不同字段应用不同函数来获取不同结果。apply()方法的基本使用格式和常用参数说明如下:
pandas.DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
| 参数名称 | 参数说明 |
|---|---|
func |
接收functions。表示应用于每行或每列的函数。无默认值 |
axis |
接收0或1。表示操作的轴向。默认为0 |
broadcast |
接收bool。表示是否进行广播。默认为False |
raw |
接收bool。表示是否直接将ndarray对象传递给函数。默认为False |
reduce |
接收bool或None。表示返回值的格式。默认为None |
4. 使用transform()方法聚合数据
transform()方法能够对整个DataFrame的所有元素进行操作。transform()方法只有一个参数"func",表示对DataFrame操作的函数。
以菜品详情表为例,对销量和售价使用Pandas库的transform()方法进行翻倍:
python
detail[['counts', 'amounts']].transform(lambda x: x * 2).head(4)
第二部分 特征工程
五、特征变换
通常情况下,使用原始数据直接建模的效果往往不好,为了使建立的模型简单精确,需要对原始数据进行特征变换,把原始的特征转化为更为有效的特征。常用的特征变换方法有特征缩放、独热编码和特征离散化等。
(一)特征缩放
不同特征之间往往具有不同的量纲,由此所造成的数值间的分布差异可能会很大,在涉及空间距离计算或梯度下降法等情况时,不对量纲差异进行处理会影响数据分析结果的准确性。为了消除特征之间量纲和取值范围造成的影响,需要对数据进行标准化处理。常用数据标准化方法有离差标准化、标准差标准化、小数定标标准化和函数转换等。
1. 离差标准化(归一化)
离差标准化是对原始数据的一种线性变换,结果是将原始数据的数值映射到 0 , 1 0,1 0,1 区间内,转换公式如下。 X ∗ = x − min ( x ) max ( x ) − min ( x ) X^*=\frac{x-\min(x)}{\max(x)-\min(x)} X∗=max(x)−min(x)x−min(x) 其中, max ( x ) \max(x) max(x)为样本数据的最大值, min ( x ) \min(x) min(x)为样本数据的最小值, max ( x ) − min ( x ) \max(x)-\min(x) max(x)−min(x) 为极差。离差标准化保留了原始数据值之间的联系,是消除量纲和数据取值范围影响最简单的方法,但受离群点影响较大,适用于分布较为均匀的数据。
2. 标准差标准化
标准差标准化也叫零均值标准化或z分数标准化,是当前使用最广泛的数据标准化方法。经过该方法处理的数据均值为0,标准差为1,转化公式如下。 X ∗ = x − x ‾ δ X^*=\frac{x-\overline{x}}{\delta} X∗=δx−x 其中, x ‾ \overline{x} x为原始数据的均值, δ \delta δ为原始数据的标准差。标准差标准化适用于数据的最大值和最小值未知的情况,或数据中包含超出取值范围的离群点的情况。
3. 小数定标标准化
通过移动数据的小数位数,将数据映射到区间 − 1 , 1 -1,1 −1,1 区间,移动的小数位数取决于数据绝对值的最大值。转化公式如下,在下方公式中, k k k表示数据整数位个数。 X ∗ = x 1 0 k X^*=\frac{x}{10^k} X∗=10kx
4. 函数转换
函数变换是使用数学函数对原始数据进行转换,改变原始数据的特征,使特征变得更适合建模,常用的包括平方、开方、取对数、差分运算等。
平方运算如下 X ∗ = x 2 X^*=x^2 X∗=x2 开方运算如下 X ∗ = x X^*=\sqrt{x} X∗=x 取对数运算如下 X ∗ = log ( x ) X^*=\log(x) X∗=log(x) 差分运算如下 ∇ f ( x k ) = f ( x k + 1 ) − f ( x k ) \nabla f(x_k)=f(x_{k+1})-f(x_k) ∇f(xk)=f(xk+1)−f(xk)
函数变换常用来将不具有正态分布的数据变换成具有正态分布的数据。在时间序列分析中,简单的对数变换或者差分运算常常就可以将非平稳序列转换成平稳序列。还可以使用对数函数转换和反正切函数转换等函数转换方法对数据进行标准化。
对数函数转换是指利用以10为底的对数函数对数据进行转换,即 X ∗ = log 10 ( x ) X^*=\log_{10}(x) X∗=log10(x);反正切函数转换即 X ∗ = 2 × arctan ( x ) π \begin{aligned}X^*=\frac{2\times \arctan(x)}{\pi}\end{aligned} X∗=π2×arctan(x),如果要求反正切函数转换的结果全部落入 0 , 1 0,1 0,1 区间,那么要求原始数据全部大于等于0,否则小于0的数据会被映射到 − 1 , 0 -1,0 −1,0 区间。
(二)独热编码
在机器学习中,经常会遇到类型数据,如性别分为男、女,手机运营商分为移动、联通和电信,这种情况下,通常会选择将其转化为数值代入模型,如0、1和--1、0、1,这个时候往往默认为连续型数值进行处理,然而这样会影响模型的效果。
独热编码便即One-Hot编码,又称一位有效编码,是处理类型数据较好的方法,主要是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候都只有一个编码位有效。
对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征,并且这些特征之间是互斥的,每一次都只有一个被激活,这时原来的数据经过独热编码后会变成稀疏矩阵。对于性别男和女,利用独热编码后可以表示为10和01。

独热编码有以下优点。将离散型特征的取值扩展到欧氏空间,离散型特征的某个取值就对应欧氏空间的某个点;对离散型特征使用独热编码,可以让特征之间的距离计算更为合理。
在Python中使用Scikit-learn库中preprocessing模块的OneHotEncoder函数进行独热编码,该函数的基本使用格式如下:
class sklearn.preprocessing.OneHotEncoder(n_values='auto', categorical_features='all', dtype=<class 'numpy.float64'>, sparse=True, handle_unknown='error')
| 参数名称 | 参数说明 |
|---|---|
n_values |
接收int或array of ints。表示每个功能的值数。默认为auto |
categorical_features |
接收all或array of indices或mask。表示将哪些功能视为分类功能。默认为all |
spares |
接收boolean。表示返回是稀疏矩阵还是数组。默认为True |
handle_unknown |
接收str。表示在转换过程中引发错误还是忽略是否存在未知的分类特征。默认为error |
(三)离散化
离散化是指将连续型特征(数值型)变换成离散型特征(类别型)的过程,需要在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一系列区间,最后用不同的符号或标签代表落在每个子区间。例如,将年龄离散化为年龄段,如图所示。

部分只能接收离散型数据的算法,需要将数据离散化后才能正常运行,如ID3、Apriori算法等。而使用离散化搭配独热编码的方法,还能够降低数据的复杂度,将其变得稀疏,增加算法运行速度。
常用的离散化方法主要有3种。等宽法、等频法和通过聚类分析离散化(一维)。
1. 等宽法
等宽法是将数据的值域分成具有相同宽度的区间的离散化方法,区间的个数由数据本身的特点决定或者用户指定,与制作频率分布表类似。
Pandas提供了cut函数,可以进行连续型数据的等宽离散化,其基础语法格式如下。
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
cut函数常用参数及其说明如表所示。
| 参数名称 | 说明 |
|---|---|
x |
接收数组或Series。表示需要进行离散化处理的数据,无默认值 |
bins |
接收int,list,array,tuple。表示若为int,代表离散化后的类别数目;若为序列类型的数据,则表示进行切分的区间,每两个数间隔为一个区间,无默认值 |
right |
接收boolean。表示右侧是否为闭区间,默认为True |
labels |
接收list,array。表示离散化后各个类别的名称,默认为空 |
retbins |
接收boolean。表示是否返回区间标签,默认为False |
precision |
接收int。表示显示的标签的精度,默认为3 |
2. 等频法
等频法将相同数量的记录放在每个区间的离散化方法,能够保证每个区间的数量基本一致。cut函数虽然不能直接实现等频法离散化,但是可以通过定义将相同数量的记录放进每个区间。
3. 基于聚类分析的方法
基于聚类的离散化方法是将连续型数据用聚类算法(如K-Means算法等)进行聚类,然后利用通过聚类得到的簇对数据进行离散化的方法,将合并到一个簇的连续型数据作为一个区间。聚类分析的离散化方法需要用户指定簇的个数,用来决定产生的区间数。
K-Means聚类分析的离散化方法可以很好地根据现有特征的数据分布状况进行聚类。基于聚类的离散化不会出现一部分区间的记录极多或极少的情况,也不会将记录平均的分配到各个区间,能够保留数据原本的分布情况,但是使用该方法进行离散化时依旧需要指定离散化后类别的数目。
使用Scikit-learn的库中preprocessing模块进行数据特征变换:
- Z-Score标准化:
StandardScaler - 最小最大标准化:
MinMaxScaler - One-Hot编码:
OneHotEncoder - 归一化:
Normalizer - 二值化(单个特征转换):
Binarizer - 标签编码:
LabelEncoder - 缺失值填补:
Imputer - 多项式特征生成:
PolynomialFeatures
六、特征选择
特征选择是特征工程中的一个重要的组成部分,其目标是寻找到最优的特征子集。特征选择能够将不相关或者冗余的特征从原本的特征集合中剔除出去,从而有效地缩减特征集合的规模,进一步地减少模型的运行时间,同时也能提高模型的精确度和有效性。
特征选择作为提高机器学习算法性能的一种重要手段,在一定程度上也能规避机器学习经常面临过拟合的问题。过拟合问题表现为模型参数过于贴合训练数据,导致泛化能力不佳,而通过特征选择削减特征的数量能在一定程度上解决过拟合的问题。
特征选择的过程主要由4个环节组成,包括生成子集、评估子集、停止准则和验证结果,如图所示。

在生成子集的步骤中,算法会通过一定的搜索策略从原始特征集合中生成候选的特征子集。
在评估子集的步骤中会针对每个候选子集依据评价准则进行评价,如果新生成的子集的评价比之前的子集要高,则新的子集会成为当前的最优候选子集。
当满足停止准则时输出当前的最优候选子集作为最优子集进行结果验证,验证选取的最优特征子集的有效性。不满足停止准则时则继续生成新的候选子集进行评估。
在特征选择过程中,每一个生成的候选特征子集都需要按照一定的评价准则进行评估。根据评价准则是否独立于学习算法对特征选择方法进行分类,可大致分为3大类:过滤式选择、包裹式选择和嵌入式选择。
(一)过滤式选择
过滤式特征选择方法中的评价准则与学习算法没有关联,可以快速排除不相关的特征,计算效率较高。过滤式特征选择的基本思想为:针对每个特征,分别计算该特征对应于不同类别标签的信息量,得到一组结果;将这组结果按由大到小的顺序进行排列,输出排在前面的指定数量的结果所对应的特征。过滤式选择的运作流程如图所示。

过滤式选择中常用的度量信息量的方法有相关系数、卡方检验、互信息等,如表所示。

还存在一种方差选择法,该方法不需要度量信息量,仅通过计算各个特征的方差进行特征选择,方差大于设定的阈值的特征将会保留。
(二)包裹式选择
与过滤式选择方法不同,包裹式选择选择一个目标函数来一步步地筛选特征。最常用的包裹式特征选择方法为递归消除特征法(recursive feature elimination,RFE)。
递归消除特征法使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干权值系数的对应的特征,再基于新的特征集进行下一轮训练,直到特征个数达到预设的值,停止训练,输出当前的特征子集。RFE算法运作过程如图所示。

(三)嵌入式选择
嵌入式选择方法也使用机器学习方法进行特征选择,与包裹式选择不同之处在于,包裹式选择不停地筛选掉一部分特征来进行迭代训练,而嵌入式选择训练时使用的都是特征全集。
嵌入式选择通常使用L1正则化和L2正则化进行特征筛选,当正则化惩罚项越大时,对应的模型的系数就会越小。当正则化惩罚项大到一定的程度时,部分特征系数会变成0,当正则化惩罚项继续增大到一定程度时,所有的特征系数都会趋于0。但是一部分特征系数在整体趋于0的过程中会先变成0,这部分系数就是可以筛掉的,因此,最终特征系数较大的特征会被保留下来。嵌入式选择的流程如图所示。

python
from sklearn import feature_selection as fs- 过滤式(Filter),保留得分排名前k的特征(top k方式)。
fs.SelectKBest(score_func, k) - 封装式(Wrap- per),结合交叉验证的递归特征消除法,自动选择最优特征个数。
fs.RFECV(estimator, scoring="r2") - 嵌入式(Embedded),从模型中自动选择特征,任何具有
coef_或者feature_importances_的基模型都可以作为estimator参数传入。fs.SelectFromModel(estimator)
(四)字典学习
除了过滤式、包裹式和嵌入式特征选择,还有一种特征选择方法考虑的是特征的"稀疏性",这种特征选择方法的核心是稀疏编码。
稀疏编码(Sparse Coding)将一个信号表示为一组基的线性组合,而且要求只需要较少的几个基就可以将信号表示出来。稀疏编码算法是一种无监督学习方法,通常用来寻找一组"超完备"基向量来更高效地表示样本数据。
稀疏编码算法中的字典学习(Dictionary Learning)是一个矩阵因式分解问题,旨在从原始数据中找到一组特殊的稀疏信号,在机器视觉中称为视觉单词(visual words),这一组稀疏信号能够线性表示所有的原始信号。字典学习的运作过程如图所示。

在字典学习的过程中,首先需要从样本集合中生成字典,生成字典的过程实际是提取事物最本质的特征,类似于从一篇文章中提取其中的字词从而生成一本专门用于表达该文章的字典。
生成字典获得了样本集合所对应的字典集合后,通过稀疏表示的过程可以得到样本集合的字典表示,类似于使用字典中的字词对文章进行表达。
字典学习对于噪声的鲁棒性强,对大量数据处理速度问题有很大的改进和突破。但字典会带有很多原始数据中的噪声等污染,且字典冗余,当训练数据的位数增加时,计算速度和事件都将遇到瓶颈问题。