代码已经上传至github,欢迎使用,不是为了研究人脸识别,而是为了实现Tensorrt部署Arcface模型,推理耗时33ms左右~
一、概述
很久没有写博客了,近期帮一个网友,半(关)夜(系)三(到)更(位),实现了一下2D人脸识别中特征提取算法,并且用C++部署至nx板卡上,感觉效果还不错,于是决定分享出来,让大家一起来学习指正。
鉴于很多朋友还是初学者,我们还是稍微介绍一下人脸识别~
人脸识别技术,作为生物识别的一种形式,已经在安全验证、访问控制和个性化体验等多个领域得到应用。深度学习算法的引入极大地推动了人脸识别技术的发展,提高了识别的准确性和鲁棒性。
人脸识别算法通常包括以下步骤(语言组织能力有限,以下采用kimi助手生成 Kimi.ai - 帮你看更大的世界):
1、首先是图像的预处理,包括调整大小、亮度标准化等。接着是人脸检测,使用深度学习模型来定位图像中的人脸区域。然后进行关键点定位,确定面部特征点。
2、接下来是特征提取,深度学习在这里发挥关键作用,通过卷积神经网络(CNN)提取人脸特征。特征向量随后用于训练或匹配,深度学习模型通过学习不同人脸的特征表示来提高识别准确性。
3、最后,通过相似度度量确定待识别人脸的身份。深度学习在特征提取和表示学习阶段尤为重要,它使得算法能够从原始图像中自动学习复杂的人脸特征。
步骤一可以使用的方法很多,例如ssd、mtcnn、libfacedetection、retinaface等等,还有延版的yolo算法,下面给几个连接,自己去看噢,想用哪个用哪个~
步骤二就是本次文章要实现的算法,当时准备用python部署的,但是想了一下简(没)单(意)了(思),后面还是用C++整一波吧。
主要用到的是https://github.com/deepinsight/insightface,把insigthface工程git下来后,就可以进入到arcface_torch工程目录下,实现模型的移植工作了。
这里给出模型下载链接https://pan.baidu.com/share/init?surl=CL-l4zWqsI1oDuEEYVhj-g :e8pw,使用其中的r50模型,从官方给出的测试效果看,r50模型效果还不错,用的nx板卡上性能能也能够接受。
二、重点(模型结构)
1、iresnet50模型结构
如下所示:
IResNet(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=64)
(layer1): Sequential(
(0): IBasicBlock(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IBasicBlock(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): IBasicBlock(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): IBasicBlock(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IBasicBlock(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): IBasicBlock(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): IBasicBlock(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): IBasicBlock(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(6): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(7): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(8): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(9): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(10): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(11): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(12): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(13): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): IBasicBlock(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IBasicBlock(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): IBasicBlock(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(prelu): PReLU(num_parameters=512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout(p=0, inplace=True)
(fc): Linear(in_features=25088, out_features=512, bias=True)
(features): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)iresnet50转成Tensorrt的wts模型结构如下所示:
Keys: odict_keys(['conv1.weight', 'bn1.weight', 'bn1.bias', 'bn1.running_mean', 'bn1.running_var', 'bn1.num_batches_tracked', 'prelu.weight', 'layer1.0.bn1.weight', 'layer1.0.bn1.bias', 'layer1.0.bn1.running_mean', 'layer1.0.bn1.running_var', 'layer1.0.bn1.num_batches_tracked', 'layer1.0.conv1.weight', 'layer1.0.bn2.weight', 'layer1.0.bn2.bias', 'layer1.0.bn2.running_mean', 'layer1.0.bn2.running_var', 'layer1.0.bn2.num_batches_tracked', 'layer1.0.prelu.weight', 'layer1.0.conv2.weight', 'layer1.0.bn3.weight', 'layer1.0.bn3.bias', 'layer1.0.bn3.running_mean', 'layer1.0.bn3.running_var', 'layer1.0.bn3.num_batches_tracked', 'layer1.0.downsample.0.weight', 'layer1.0.downsample.1.weight', 'layer1.0.downsample.1.bias', 'layer1.0.downsample.1.running_mean', 'layer1.0.downsample.1.running_var', 'layer1.0.downsample.1.num_batches_tracked', 'layer1.1.bn1.weight', 'layer1.1.bn1.bias', 'layer1.1.bn1.running_mean', 'layer1.1.bn1.running_var', 'layer1.1.bn1.num_batches_tracked', 'layer1.1.conv1.weight', 'layer1.1.bn2.weight', 'layer1.1.bn2.bias', 'layer1.1.bn2.running_mean', 'layer1.1.bn2.running_var', 'layer1.1.bn2.num_batches_tracked', 'layer1.1.prelu.weight', 'layer1.1.conv2.weight', 'layer1.1.bn3.weight', 'layer1.1.bn3.bias', 'layer1.1.bn3.running_mean', 'layer1.1.bn3.running_var', 'layer1.1.bn3.num_batches_tracked', 'layer1.2.bn1.weight', 'layer1.2.bn1.bias', 'layer1.2.bn1.running_mean', 'layer1.2.bn1.running_var', 'layer1.2.bn1.num_batches_tracked', 'layer1.2.conv1.weight', 'layer1.2.bn2.weight', 'layer1.2.bn2.bias', 'layer1.2.bn2.running_mean', 'layer1.2.bn2.running_var', 'layer1.2.bn2.num_batches_tracked', 'layer1.2.prelu.weight', 'layer1.2.conv2.weight', 'layer1.2.bn3.weight', 'layer1.2.bn3.bias', 'layer1.2.bn3.running_mean', 'layer1.2.bn3.running_var', 'layer1.2.bn3.num_batches_tracked', 'layer2.0.bn1.weight', 'layer2.0.bn1.bias', 'layer2.0.bn1.running_mean', 'layer2.0.bn1.running_var', 'layer2.0.bn1.num_batches_tracked', 'layer2.0.conv1.weight', 'layer2.0.bn2.weight', 'layer2.0.bn2.bias', 'layer2.0.bn2.running_mean', 'layer2.0.bn2.running_var', 'layer2.0.bn2.num_batches_tracked', 'layer2.0.prelu.weight', 'layer2.0.conv2.weight', 'layer2.0.bn3.weight', 'layer2.0.bn3.bias', 'layer2.0.bn3.running_mean', 'layer2.0.bn3.running_var', 'layer2.0.bn3.num_batches_tracked', 'layer2.0.downsample.0.weight', 'layer2.0.downsample.1.weight', 'layer2.0.downsample.1.bias', 'layer2.0.downsample.1.running_mean', 'layer2.0.downsample.1.running_var', 'layer2.0.downsample.1.num_batches_tracked', 'layer2.1.bn1.weight', 'layer2.1.bn1.bias', 'layer2.1.bn1.running_mean', 'layer2.1.bn1.running_var', 'layer2.1.bn1.num_batches_tracked', 'layer2.1.conv1.weight', 'layer2.1.bn2.weight', 'layer2.1.bn2.bias', 'layer2.1.bn2.running_mean', 'layer2.1.bn2.running_var', 'layer2.1.bn2.num_batches_tracked', 'layer2.1.prelu.weight', 'layer2.1.conv2.weight', 'layer2.1.bn3.weight', 'layer2.1.bn3.bias', 'layer2.1.bn3.running_mean', 'layer2.1.bn3.running_var', 'layer2.1.bn3.num_batches_tracked', 'layer2.2.bn1.weight', 'layer2.2.bn1.bias', 'layer2.2.bn1.running_mean', 'layer2.2.bn1.running_var', 'layer2.2.bn1.num_batches_tracked', 'layer2.2.conv1.weight', 'layer2.2.bn2.weight', 'layer2.2.bn2.bias', 'layer2.2.bn2.running_mean', 'layer2.2.bn2.running_var', 'layer2.2.bn2.num_batches_tracked', 'layer2.2.prelu.weight', 'layer2.2.conv2.weight', 'layer2.2.bn3.weight', 'layer2.2.bn3.bias', 'layer2.2.bn3.running_mean', 'layer2.2.bn3.running_var', 'layer2.2.bn3.num_batches_tracked', 'layer2.3.bn1.weight', 'layer2.3.bn1.bias', 'layer2.3.bn1.running_mean', 'layer2.3.bn1.running_var', 'layer2.3.bn1.num_batches_tracked', 'layer2.3.conv1.weight', 'layer2.3.bn2.weight', 'layer2.3.bn2.bias', 'layer2.3.bn2.running_mean', 'layer2.3.bn2.running_var', 'layer2.3.bn2.num_batches_tracked', 'layer2.3.prelu.weight', 'layer2.3.conv2.weight', 'layer2.3.bn3.weight', 'layer2.3.bn3.bias', 'layer2.3.bn3.running_mean', 'layer2.3.bn3.running_var', 'layer2.3.bn3.num_batches_tracked', 'layer3.0.bn1.weight', 'layer3.0.bn1.bias', 'layer3.0.bn1.running_mean', 'layer3.0.bn1.running_var', 'layer3.0.bn1.num_batches_tracked', 'layer3.0.conv1.weight', 'layer3.0.bn2.weight', 'layer3.0.bn2.bias', 'layer3.0.bn2.running_mean', 'layer3.0.bn2.running_var', 'layer3.0.bn2.num_batches_tracked', 'layer3.0.prelu.weight', 'layer3.0.conv2.weight', 'layer3.0.bn3.weight', 'layer3.0.bn3.bias', 'layer3.0.bn3.running_mean', 'layer3.0.bn3.running_var', 'layer3.0.bn3.num_batches_tracked', 'layer3.0.downsample.0.weight', 'layer3.0.downsample.1.weight', 'layer3.0.downsample.1.bias', 'layer3.0.downsample.1.running_mean', 'layer3.0.downsample.1.running_var', 'layer3.0.downsample.1.num_batches_tracked', 'layer3.1.bn1.weight', 'layer3.1.bn1.bias', 'layer3.1.bn1.running_mean', 'layer3.1.bn1.running_var', 'layer3.1.bn1.num_batches_tracked', 'layer3.1.conv1.weight', 'layer3.1.bn2.weight', 'layer3.1.bn2.bias', 'layer3.1.bn2.running_mean', 'layer3.1.bn2.running_var', 'layer3.1.bn2.num_batches_tracked', 'layer3.1.prelu.weight', 'layer3.1.conv2.weight', 'layer3.1.bn3.weight', 'layer3.1.bn3.bias', 'layer3.1.bn3.running_mean', 'layer3.1.bn3.running_var', 'layer3.1.bn3.num_batches_tracked', 'layer3.2.bn1.weight', 'layer3.2.bn1.bias', 'layer3.2.bn1.running_mean', 'layer3.2.bn1.running_var', 'layer3.2.bn1.num_batches_tracked', 'layer3.2.conv1.weight', 'layer3.2.bn2.weight', 'layer3.2.bn2.bias', 'layer3.2.bn2.running_mean', 'layer3.2.bn2.running_var', 'layer3.2.bn2.num_batches_tracked', 'layer3.2.prelu.weight', 'layer3.2.conv2.weight', 'layer3.2.bn3.weight', 'layer3.2.bn3.bias', 'layer3.2.bn3.running_mean', 'layer3.2.bn3.running_var', 'layer3.2.bn3.num_batches_tracked', 'layer3.3.bn1.weight', 'layer3.3.bn1.bias', 'layer3.3.bn1.running_mean', 'layer3.3.bn1.running_var', 'layer3.3.bn1.num_batches_tracked', 'layer3.3.conv1.weight', 'layer3.3.bn2.weight', 'layer3.3.bn2.bias', 'layer3.3.bn2.running_mean', 'layer3.3.bn2.running_var', 'layer3.3.bn2.num_batches_tracked', 'layer3.3.prelu.weight', 'layer3.3.conv2.weight', 'layer3.3.bn3.weight', 'layer3.3.bn3.bias', 'layer3.3.bn3.running_mean', 'layer3.3.bn3.running_var', 'layer3.3.bn3.num_batches_tracked', 'layer3.4.bn1.weight', 'layer3.4.bn1.bias', 'layer3.4.bn1.running_mean', 'layer3.4.bn1.running_var', 'layer3.4.bn1.num_batches_tracked', 'layer3.4.conv1.weight', 'layer3.4.bn2.weight', 'layer3.4.bn2.bias', 'layer3.4.bn2.running_mean', 'layer3.4.bn2.running_var', 'layer3.4.bn2.num_batches_tracked', 'layer3.4.prelu.weight', 'layer3.4.conv2.weight', 'layer3.4.bn3.weight', 'layer3.4.bn3.bias', 'layer3.4.bn3.running_mean', 'layer3.4.bn3.running_var', 'layer3.4.bn3.num_batches_tracked', 'layer3.5.bn1.weight', 'layer3.5.bn1.bias', 'layer3.5.bn1.running_mean', 'layer3.5.bn1.running_var', 'layer3.5.bn1.num_batches_tracked', 'layer3.5.conv1.weight', 'layer3.5.bn2.weight', 'layer3.5.bn2.bias', 'layer3.5.bn2.running_mean', 'layer3.5.bn2.running_var', 'layer3.5.bn2.num_batches_tracked', 'layer3.5.prelu.weight', 'layer3.5.conv2.weight', 'layer3.5.bn3.weight', 'layer3.5.bn3.bias', 'layer3.5.bn3.running_mean', 'layer3.5.bn3.running_var', 'layer3.5.bn3.num_batches_tracked', 'layer3.6.bn1.weight', 'layer3.6.bn1.bias', 'layer3.6.bn1.running_mean', 'layer3.6.bn1.running_var', 'layer3.6.bn1.num_batches_tracked', 'layer3.6.conv1.weight', 'layer3.6.bn2.weight', 'layer3.6.bn2.bias', 'layer3.6.bn2.running_mean', 'layer3.6.bn2.running_var', 'layer3.6.bn2.num_batches_tracked', 'layer3.6.prelu.weight', 'layer3.6.conv2.weight', 'layer3.6.bn3.weight', 'layer3.6.bn3.bias', 'layer3.6.bn3.running_mean', 'layer3.6.bn3.running_var', 'layer3.6.bn3.num_batches_tracked', 'layer3.7.bn1.weight', 'layer3.7.bn1.bias', 'layer3.7.bn1.running_mean', 'layer3.7.bn1.running_var', 'layer3.7.bn1.num_batches_tracked', 'layer3.7.conv1.weight', 'layer3.7.bn2.weight', 'layer3.7.bn2.bias', 'layer3.7.bn2.running_mean', 'layer3.7.bn2.running_var', 'layer3.7.bn2.num_batches_tracked', 'layer3.7.prelu.weight', 'layer3.7.conv2.weight', 'layer3.7.bn3.weight', 'layer3.7.bn3.bias', 'layer3.7.bn3.running_mean', 'layer3.7.bn3.running_var', 'layer3.7.bn3.num_batches_tracked', 'layer3.8.bn1.weight', 'layer3.8.bn1.bias', 'layer3.8.bn1.running_mean', 'layer3.8.bn1.running_var', 'layer3.8.bn1.num_batches_tracked', 'layer3.8.conv1.weight', 'layer3.8.bn2.weight', 'layer3.8.bn2.bias', 'layer3.8.bn2.running_mean', 'layer3.8.bn2.running_var', 'layer3.8.bn2.num_batches_tracked', 'layer3.8.prelu.weight', 'layer3.8.conv2.weight', 'layer3.8.bn3.weight', 'layer3.8.bn3.bias', 'layer3.8.bn3.running_mean', 'layer3.8.bn3.running_var', 'layer3.8.bn3.num_batches_tracked', 'layer3.9.bn1.weight', 'layer3.9.bn1.bias', 'layer3.9.bn1.running_mean', 'layer3.9.bn1.running_var', 'layer3.9.bn1.num_batches_tracked', 'layer3.9.conv1.weight', 'layer3.9.bn2.weight', 'layer3.9.bn2.bias', 'layer3.9.bn2.running_mean', 'layer3.9.bn2.running_var', 'layer3.9.bn2.num_batches_tracked', 'layer3.9.prelu.weight', 'layer3.9.conv2.weight', 'layer3.9.bn3.weight', 'layer3.9.bn3.bias', 'layer3.9.bn3.running_mean', 'layer3.9.bn3.running_var', 'layer3.9.bn3.num_batches_tracked', 'layer3.10.bn1.weight', 'layer3.10.bn1.bias', 'layer3.10.bn1.running_mean', 'layer3.10.bn1.running_var', 'layer3.10.bn1.num_batches_tracked', 'layer3.10.conv1.weight', 'layer3.10.bn2.weight', 'layer3.10.bn2.bias', 'layer3.10.bn2.running_mean', 'layer3.10.bn2.running_var', 'layer3.10.bn2.num_batches_tracked', 'layer3.10.prelu.weight', 'layer3.10.conv2.weight', 'layer3.10.bn3.weight', 'layer3.10.bn3.bias', 'layer3.10.bn3.running_mean', 'layer3.10.bn3.running_var', 'layer3.10.bn3.num_batches_tracked', 'layer3.11.bn1.weight', 'layer3.11.bn1.bias', 'layer3.11.bn1.running_mean', 'layer3.11.bn1.running_var', 'layer3.11.bn1.num_batches_tracked', 'layer3.11.conv1.weight', 'layer3.11.bn2.weight', 'layer3.11.bn2.bias', 'layer3.11.bn2.running_mean', 'layer3.11.bn2.running_var', 'layer3.11.bn2.num_batches_tracked', 'layer3.11.prelu.weight', 'layer3.11.conv2.weight', 'layer3.11.bn3.weight', 'layer3.11.bn3.bias', 'layer3.11.bn3.running_mean', 'layer3.11.bn3.running_var', 'layer3.11.bn3.num_batches_tracked', 'layer3.12.bn1.weight', 'layer3.12.bn1.bias', 'layer3.12.bn1.running_mean', 'layer3.12.bn1.running_var', 'layer3.12.bn1.num_batches_tracked', 'layer3.12.conv1.weight', 'layer3.12.bn2.weight', 'layer3.12.bn2.bias', 'layer3.12.bn2.running_mean', 'layer3.12.bn2.running_var', 'layer3.12.bn2.num_batches_tracked', 'layer3.12.prelu.weight', 'layer3.12.conv2.weight', 'layer3.12.bn3.weight', 'layer3.12.bn3.bias', 'layer3.12.bn3.running_mean', 'layer3.12.bn3.running_var', 'layer3.12.bn3.num_batches_tracked', 'layer3.13.bn1.weight', 'layer3.13.bn1.bias', 'layer3.13.bn1.running_mean', 'layer3.13.bn1.running_var', 'layer3.13.bn1.num_batches_tracked', 'layer3.13.conv1.weight', 'layer3.13.bn2.weight', 'layer3.13.bn2.bias', 'layer3.13.bn2.running_mean', 'layer3.13.bn2.running_var', 'layer3.13.bn2.num_batches_tracked', 'layer3.13.prelu.weight', 'layer3.13.conv2.weight', 'layer3.13.bn3.weight', 'layer3.13.bn3.bias', 'layer3.13.bn3.running_mean', 'layer3.13.bn3.running_var', 'layer3.13.bn3.num_batches_tracked', 'layer4.0.bn1.weight', 'layer4.0.bn1.bias', 'layer4.0.bn1.running_mean', 'layer4.0.bn1.running_var', 'layer4.0.bn1.num_batches_tracked', 'layer4.0.conv1.weight', 'layer4.0.bn2.weight', 'layer4.0.bn2.bias', 'layer4.0.bn2.running_mean', 'layer4.0.bn2.running_var', 'layer4.0.bn2.num_batches_tracked', 'layer4.0.prelu.weight', 'layer4.0.conv2.weight', 'layer4.0.bn3.weight', 'layer4.0.bn3.bias', 'layer4.0.bn3.running_mean', 'layer4.0.bn3.running_var', 'layer4.0.bn3.num_batches_tracked', 'layer4.0.downsample.0.weight', 'layer4.0.downsample.1.weight', 'layer4.0.downsample.1.bias', 'layer4.0.downsample.1.running_mean', 'layer4.0.downsample.1.running_var', 'layer4.0.downsample.1.num_batches_tracked', 'layer4.1.bn1.weight', 'layer4.1.bn1.bias', 'layer4.1.bn1.running_mean', 'layer4.1.bn1.running_var', 'layer4.1.bn1.num_batches_tracked', 'layer4.1.conv1.weight', 'layer4.1.bn2.weight', 'layer4.1.bn2.bias', 'layer4.1.bn2.running_mean', 'layer4.1.bn2.running_var', 'layer4.1.bn2.num_batches_tracked', 'layer4.1.prelu.weight', 'layer4.1.conv2.weight', 'layer4.1.bn3.weight', 'layer4.1.bn3.bias', 'layer4.1.bn3.running_mean', 'layer4.1.bn3.running_var', 'layer4.1.bn3.num_batches_tracked', 'layer4.2.bn1.weight', 'layer4.2.bn1.bias', 'layer4.2.bn1.running_mean', 'layer4.2.bn1.running_var', 'layer4.2.bn1.num_batches_tracked', 'layer4.2.conv1.weight', 'layer4.2.bn2.weight', 'layer4.2.bn2.bias', 'layer4.2.bn2.running_mean', 'layer4.2.bn2.running_var', 'layer4.2.bn2.num_batches_tracked', 'layer4.2.prelu.weight', 'layer4.2.conv2.weight', 'layer4.2.bn3.weight', 'layer4.2.bn3.bias', 'layer4.2.bn3.running_mean', 'layer4.2.bn3.running_var', 'layer4.2.bn3.num_batches_tracked', 'bn2.weight', 'bn2.bias', 'bn2.running_mean', 'bn2.running_var', 'bn2.num_batches_tracked', 'fc.weight', 'fc.bias', 'features.weight', 'features.bias', 'features.running_mean', 'features.running_var', 'features.num_batches_tracked'])
Key: conv1.weight, Val: torch.Size([64, 3, 3, 3])
Key: bn1.weight, Val: torch.Size([64])
Key: bn1.bias, Val: torch.Size([64])
Key: bn1.running_mean, Val: torch.Size([64])
Key: bn1.running_var, Val: torch.Size([64])
Key: bn1.num_batches_tracked, Val: torch.Size([])
Key: prelu.weight, Val: torch.Size([64])
Key: layer1.0.bn1.weight, Val: torch.Size([64])
Key: layer1.0.bn1.bias, Val: torch.Size([64])
Key: layer1.0.bn1.running_mean, Val: torch.Size([64])
Key: layer1.0.bn1.running_var, Val: torch.Size([64])
Key: layer1.0.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer1.0.conv1.weight, Val: torch.Size([64, 64, 3, 3])
Key: layer1.0.bn2.weight, Val: torch.Size([64])
Key: layer1.0.bn2.bias, Val: torch.Size([64])
Key: layer1.0.bn2.running_mean, Val: torch.Size([64])
Key: layer1.0.bn2.running_var, Val: torch.Size([64])
Key: layer1.0.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer1.0.prelu.weight, Val: torch.Size([64])
Key: layer1.0.conv2.weight, Val: torch.Size([64, 64, 3, 3])
Key: layer1.0.bn3.weight, Val: torch.Size([64])
Key: layer1.0.bn3.bias, Val: torch.Size([64])
Key: layer1.0.bn3.running_mean, Val: torch.Size([64])
Key: layer1.0.bn3.running_var, Val: torch.Size([64])
Key: layer1.0.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer1.0.downsample.0.weight, Val: torch.Size([64, 64, 1, 1])
Key: layer1.0.downsample.1.weight, Val: torch.Size([64])
Key: layer1.0.downsample.1.bias, Val: torch.Size([64])
Key: layer1.0.downsample.1.running_mean, Val: torch.Size([64])
Key: layer1.0.downsample.1.running_var, Val: torch.Size([64])
Key: layer1.0.downsample.1.num_batches_tracked, Val: torch.Size([])
Key: layer1.1.bn1.weight, Val: torch.Size([64])
Key: layer1.1.bn1.bias, Val: torch.Size([64])
Key: layer1.1.bn1.running_mean, Val: torch.Size([64])
Key: layer1.1.bn1.running_var, Val: torch.Size([64])
Key: layer1.1.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer1.1.conv1.weight, Val: torch.Size([64, 64, 3, 3])
Key: layer1.1.bn2.weight, Val: torch.Size([64])
Key: layer1.1.bn2.bias, Val: torch.Size([64])
Key: layer1.1.bn2.running_mean, Val: torch.Size([64])
Key: layer1.1.bn2.running_var, Val: torch.Size([64])
Key: layer1.1.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer1.1.prelu.weight, Val: torch.Size([64])
Key: layer1.1.conv2.weight, Val: torch.Size([64, 64, 3, 3])
Key: layer1.1.bn3.weight, Val: torch.Size([64])
Key: layer1.1.bn3.bias, Val: torch.Size([64])
Key: layer1.1.bn3.running_mean, Val: torch.Size([64])
Key: layer1.1.bn3.running_var, Val: torch.Size([64])
Key: layer1.1.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer1.2.bn1.weight, Val: torch.Size([64])
Key: layer1.2.bn1.bias, Val: torch.Size([64])
Key: layer1.2.bn1.running_mean, Val: torch.Size([64])
Key: layer1.2.bn1.running_var, Val: torch.Size([64])
Key: layer1.2.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer1.2.conv1.weight, Val: torch.Size([64, 64, 3, 3])
Key: layer1.2.bn2.weight, Val: torch.Size([64])
Key: layer1.2.bn2.bias, Val: torch.Size([64])
Key: layer1.2.bn2.running_mean, Val: torch.Size([64])
Key: layer1.2.bn2.running_var, Val: torch.Size([64])
Key: layer1.2.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer1.2.prelu.weight, Val: torch.Size([64])
Key: layer1.2.conv2.weight, Val: torch.Size([64, 64, 3, 3])
Key: layer1.2.bn3.weight, Val: torch.Size([64])
Key: layer1.2.bn3.bias, Val: torch.Size([64])
Key: layer1.2.bn3.running_mean, Val: torch.Size([64])
Key: layer1.2.bn3.running_var, Val: torch.Size([64])
Key: layer1.2.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer2.0.bn1.weight, Val: torch.Size([64])
Key: layer2.0.bn1.bias, Val: torch.Size([64])
Key: layer2.0.bn1.running_mean, Val: torch.Size([64])
Key: layer2.0.bn1.running_var, Val: torch.Size([64])
Key: layer2.0.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer2.0.conv1.weight, Val: torch.Size([128, 64, 3, 3])
Key: layer2.0.bn2.weight, Val: torch.Size([128])
Key: layer2.0.bn2.bias, Val: torch.Size([128])
Key: layer2.0.bn2.running_mean, Val: torch.Size([128])
Key: layer2.0.bn2.running_var, Val: torch.Size([128])
Key: layer2.0.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer2.0.prelu.weight, Val: torch.Size([128])
Key: layer2.0.conv2.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.0.bn3.weight, Val: torch.Size([128])
Key: layer2.0.bn3.bias, Val: torch.Size([128])
Key: layer2.0.bn3.running_mean, Val: torch.Size([128])
Key: layer2.0.bn3.running_var, Val: torch.Size([128])
Key: layer2.0.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer2.0.downsample.0.weight, Val: torch.Size([128, 64, 1, 1])
Key: layer2.0.downsample.1.weight, Val: torch.Size([128])
Key: layer2.0.downsample.1.bias, Val: torch.Size([128])
Key: layer2.0.downsample.1.running_mean, Val: torch.Size([128])
Key: layer2.0.downsample.1.running_var, Val: torch.Size([128])
Key: layer2.0.downsample.1.num_batches_tracked, Val: torch.Size([])
Key: layer2.1.bn1.weight, Val: torch.Size([128])
Key: layer2.1.bn1.bias, Val: torch.Size([128])
Key: layer2.1.bn1.running_mean, Val: torch.Size([128])
Key: layer2.1.bn1.running_var, Val: torch.Size([128])
Key: layer2.1.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer2.1.conv1.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.1.bn2.weight, Val: torch.Size([128])
Key: layer2.1.bn2.bias, Val: torch.Size([128])
Key: layer2.1.bn2.running_mean, Val: torch.Size([128])
Key: layer2.1.bn2.running_var, Val: torch.Size([128])
Key: layer2.1.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer2.1.prelu.weight, Val: torch.Size([128])
Key: layer2.1.conv2.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.1.bn3.weight, Val: torch.Size([128])
Key: layer2.1.bn3.bias, Val: torch.Size([128])
Key: layer2.1.bn3.running_mean, Val: torch.Size([128])
Key: layer2.1.bn3.running_var, Val: torch.Size([128])
Key: layer2.1.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer2.2.bn1.weight, Val: torch.Size([128])
Key: layer2.2.bn1.bias, Val: torch.Size([128])
Key: layer2.2.bn1.running_mean, Val: torch.Size([128])
Key: layer2.2.bn1.running_var, Val: torch.Size([128])
Key: layer2.2.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer2.2.conv1.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.2.bn2.weight, Val: torch.Size([128])
Key: layer2.2.bn2.bias, Val: torch.Size([128])
Key: layer2.2.bn2.running_mean, Val: torch.Size([128])
Key: layer2.2.bn2.running_var, Val: torch.Size([128])
Key: layer2.2.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer2.2.prelu.weight, Val: torch.Size([128])
Key: layer2.2.conv2.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.2.bn3.weight, Val: torch.Size([128])
Key: layer2.2.bn3.bias, Val: torch.Size([128])
Key: layer2.2.bn3.running_mean, Val: torch.Size([128])
Key: layer2.2.bn3.running_var, Val: torch.Size([128])
Key: layer2.2.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer2.3.bn1.weight, Val: torch.Size([128])
Key: layer2.3.bn1.bias, Val: torch.Size([128])
Key: layer2.3.bn1.running_mean, Val: torch.Size([128])
Key: layer2.3.bn1.running_var, Val: torch.Size([128])
Key: layer2.3.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer2.3.conv1.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.3.bn2.weight, Val: torch.Size([128])
Key: layer2.3.bn2.bias, Val: torch.Size([128])
Key: layer2.3.bn2.running_mean, Val: torch.Size([128])
Key: layer2.3.bn2.running_var, Val: torch.Size([128])
Key: layer2.3.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer2.3.prelu.weight, Val: torch.Size([128])
Key: layer2.3.conv2.weight, Val: torch.Size([128, 128, 3, 3])
Key: layer2.3.bn3.weight, Val: torch.Size([128])
Key: layer2.3.bn3.bias, Val: torch.Size([128])
Key: layer2.3.bn3.running_mean, Val: torch.Size([128])
Key: layer2.3.bn3.running_var, Val: torch.Size([128])
Key: layer2.3.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.0.bn1.weight, Val: torch.Size([128])
Key: layer3.0.bn1.bias, Val: torch.Size([128])
Key: layer3.0.bn1.running_mean, Val: torch.Size([128])
Key: layer3.0.bn1.running_var, Val: torch.Size([128])
Key: layer3.0.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.0.conv1.weight, Val: torch.Size([256, 128, 3, 3])
Key: layer3.0.bn2.weight, Val: torch.Size([256])
Key: layer3.0.bn2.bias, Val: torch.Size([256])
Key: layer3.0.bn2.running_mean, Val: torch.Size([256])
Key: layer3.0.bn2.running_var, Val: torch.Size([256])
Key: layer3.0.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.0.prelu.weight, Val: torch.Size([256])
Key: layer3.0.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.0.bn3.weight, Val: torch.Size([256])
Key: layer3.0.bn3.bias, Val: torch.Size([256])
Key: layer3.0.bn3.running_mean, Val: torch.Size([256])
Key: layer3.0.bn3.running_var, Val: torch.Size([256])
Key: layer3.0.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.0.downsample.0.weight, Val: torch.Size([256, 128, 1, 1])
Key: layer3.0.downsample.1.weight, Val: torch.Size([256])
Key: layer3.0.downsample.1.bias, Val: torch.Size([256])
Key: layer3.0.downsample.1.running_mean, Val: torch.Size([256])
Key: layer3.0.downsample.1.running_var, Val: torch.Size([256])
Key: layer3.0.downsample.1.num_batches_tracked, Val: torch.Size([])
Key: layer3.1.bn1.weight, Val: torch.Size([256])
Key: layer3.1.bn1.bias, Val: torch.Size([256])
Key: layer3.1.bn1.running_mean, Val: torch.Size([256])
Key: layer3.1.bn1.running_var, Val: torch.Size([256])
Key: layer3.1.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.1.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.1.bn2.weight, Val: torch.Size([256])
Key: layer3.1.bn2.bias, Val: torch.Size([256])
Key: layer3.1.bn2.running_mean, Val: torch.Size([256])
Key: layer3.1.bn2.running_var, Val: torch.Size([256])
Key: layer3.1.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.1.prelu.weight, Val: torch.Size([256])
Key: layer3.1.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.1.bn3.weight, Val: torch.Size([256])
Key: layer3.1.bn3.bias, Val: torch.Size([256])
Key: layer3.1.bn3.running_mean, Val: torch.Size([256])
Key: layer3.1.bn3.running_var, Val: torch.Size([256])
Key: layer3.1.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.2.bn1.weight, Val: torch.Size([256])
Key: layer3.2.bn1.bias, Val: torch.Size([256])
Key: layer3.2.bn1.running_mean, Val: torch.Size([256])
Key: layer3.2.bn1.running_var, Val: torch.Size([256])
Key: layer3.2.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.2.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.2.bn2.weight, Val: torch.Size([256])
Key: layer3.2.bn2.bias, Val: torch.Size([256])
Key: layer3.2.bn2.running_mean, Val: torch.Size([256])
Key: layer3.2.bn2.running_var, Val: torch.Size([256])
Key: layer3.2.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.2.prelu.weight, Val: torch.Size([256])
Key: layer3.2.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.2.bn3.weight, Val: torch.Size([256])
Key: layer3.2.bn3.bias, Val: torch.Size([256])
Key: layer3.2.bn3.running_mean, Val: torch.Size([256])
Key: layer3.2.bn3.running_var, Val: torch.Size([256])
Key: layer3.2.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.3.bn1.weight, Val: torch.Size([256])
Key: layer3.3.bn1.bias, Val: torch.Size([256])
Key: layer3.3.bn1.running_mean, Val: torch.Size([256])
Key: layer3.3.bn1.running_var, Val: torch.Size([256])
Key: layer3.3.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.3.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.3.bn2.weight, Val: torch.Size([256])
Key: layer3.3.bn2.bias, Val: torch.Size([256])
Key: layer3.3.bn2.running_mean, Val: torch.Size([256])
Key: layer3.3.bn2.running_var, Val: torch.Size([256])
Key: layer3.3.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.3.prelu.weight, Val: torch.Size([256])
Key: layer3.3.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.3.bn3.weight, Val: torch.Size([256])
Key: layer3.3.bn3.bias, Val: torch.Size([256])
Key: layer3.3.bn3.running_mean, Val: torch.Size([256])
Key: layer3.3.bn3.running_var, Val: torch.Size([256])
Key: layer3.3.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.4.bn1.weight, Val: torch.Size([256])
Key: layer3.4.bn1.bias, Val: torch.Size([256])
Key: layer3.4.bn1.running_mean, Val: torch.Size([256])
Key: layer3.4.bn1.running_var, Val: torch.Size([256])
Key: layer3.4.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.4.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.4.bn2.weight, Val: torch.Size([256])
Key: layer3.4.bn2.bias, Val: torch.Size([256])
Key: layer3.4.bn2.running_mean, Val: torch.Size([256])
Key: layer3.4.bn2.running_var, Val: torch.Size([256])
Key: layer3.4.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.4.prelu.weight, Val: torch.Size([256])
Key: layer3.4.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.4.bn3.weight, Val: torch.Size([256])
Key: layer3.4.bn3.bias, Val: torch.Size([256])
Key: layer3.4.bn3.running_mean, Val: torch.Size([256])
Key: layer3.4.bn3.running_var, Val: torch.Size([256])
Key: layer3.4.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.5.bn1.weight, Val: torch.Size([256])
Key: layer3.5.bn1.bias, Val: torch.Size([256])
Key: layer3.5.bn1.running_mean, Val: torch.Size([256])
Key: layer3.5.bn1.running_var, Val: torch.Size([256])
Key: layer3.5.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.5.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.5.bn2.weight, Val: torch.Size([256])
Key: layer3.5.bn2.bias, Val: torch.Size([256])
Key: layer3.5.bn2.running_mean, Val: torch.Size([256])
Key: layer3.5.bn2.running_var, Val: torch.Size([256])
Key: layer3.5.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.5.prelu.weight, Val: torch.Size([256])
Key: layer3.5.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.5.bn3.weight, Val: torch.Size([256])
Key: layer3.5.bn3.bias, Val: torch.Size([256])
Key: layer3.5.bn3.running_mean, Val: torch.Size([256])
Key: layer3.5.bn3.running_var, Val: torch.Size([256])
Key: layer3.5.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.6.bn1.weight, Val: torch.Size([256])
Key: layer3.6.bn1.bias, Val: torch.Size([256])
Key: layer3.6.bn1.running_mean, Val: torch.Size([256])
Key: layer3.6.bn1.running_var, Val: torch.Size([256])
Key: layer3.6.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.6.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.6.bn2.weight, Val: torch.Size([256])
Key: layer3.6.bn2.bias, Val: torch.Size([256])
Key: layer3.6.bn2.running_mean, Val: torch.Size([256])
Key: layer3.6.bn2.running_var, Val: torch.Size([256])
Key: layer3.6.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.6.prelu.weight, Val: torch.Size([256])
Key: layer3.6.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.6.bn3.weight, Val: torch.Size([256])
Key: layer3.6.bn3.bias, Val: torch.Size([256])
Key: layer3.6.bn3.running_mean, Val: torch.Size([256])
Key: layer3.6.bn3.running_var, Val: torch.Size([256])
Key: layer3.6.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.7.bn1.weight, Val: torch.Size([256])
Key: layer3.7.bn1.bias, Val: torch.Size([256])
Key: layer3.7.bn1.running_mean, Val: torch.Size([256])
Key: layer3.7.bn1.running_var, Val: torch.Size([256])
Key: layer3.7.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.7.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.7.bn2.weight, Val: torch.Size([256])
Key: layer3.7.bn2.bias, Val: torch.Size([256])
Key: layer3.7.bn2.running_mean, Val: torch.Size([256])
Key: layer3.7.bn2.running_var, Val: torch.Size([256])
Key: layer3.7.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.7.prelu.weight, Val: torch.Size([256])
Key: layer3.7.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.7.bn3.weight, Val: torch.Size([256])
Key: layer3.7.bn3.bias, Val: torch.Size([256])
Key: layer3.7.bn3.running_mean, Val: torch.Size([256])
Key: layer3.7.bn3.running_var, Val: torch.Size([256])
Key: layer3.7.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.8.bn1.weight, Val: torch.Size([256])
Key: layer3.8.bn1.bias, Val: torch.Size([256])
Key: layer3.8.bn1.running_mean, Val: torch.Size([256])
Key: layer3.8.bn1.running_var, Val: torch.Size([256])
Key: layer3.8.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.8.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.8.bn2.weight, Val: torch.Size([256])
Key: layer3.8.bn2.bias, Val: torch.Size([256])
Key: layer3.8.bn2.running_mean, Val: torch.Size([256])
Key: layer3.8.bn2.running_var, Val: torch.Size([256])
Key: layer3.8.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.8.prelu.weight, Val: torch.Size([256])
Key: layer3.8.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.8.bn3.weight, Val: torch.Size([256])
Key: layer3.8.bn3.bias, Val: torch.Size([256])
Key: layer3.8.bn3.running_mean, Val: torch.Size([256])
Key: layer3.8.bn3.running_var, Val: torch.Size([256])
Key: layer3.8.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.9.bn1.weight, Val: torch.Size([256])
Key: layer3.9.bn1.bias, Val: torch.Size([256])
Key: layer3.9.bn1.running_mean, Val: torch.Size([256])
Key: layer3.9.bn1.running_var, Val: torch.Size([256])
Key: layer3.9.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.9.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.9.bn2.weight, Val: torch.Size([256])
Key: layer3.9.bn2.bias, Val: torch.Size([256])
Key: layer3.9.bn2.running_mean, Val: torch.Size([256])
Key: layer3.9.bn2.running_var, Val: torch.Size([256])
Key: layer3.9.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.9.prelu.weight, Val: torch.Size([256])
Key: layer3.9.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.9.bn3.weight, Val: torch.Size([256])
Key: layer3.9.bn3.bias, Val: torch.Size([256])
Key: layer3.9.bn3.running_mean, Val: torch.Size([256])
Key: layer3.9.bn3.running_var, Val: torch.Size([256])
Key: layer3.9.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.10.bn1.weight, Val: torch.Size([256])
Key: layer3.10.bn1.bias, Val: torch.Size([256])
Key: layer3.10.bn1.running_mean, Val: torch.Size([256])
Key: layer3.10.bn1.running_var, Val: torch.Size([256])
Key: layer3.10.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.10.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.10.bn2.weight, Val: torch.Size([256])
Key: layer3.10.bn2.bias, Val: torch.Size([256])
Key: layer3.10.bn2.running_mean, Val: torch.Size([256])
Key: layer3.10.bn2.running_var, Val: torch.Size([256])
Key: layer3.10.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.10.prelu.weight, Val: torch.Size([256])
Key: layer3.10.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.10.bn3.weight, Val: torch.Size([256])
Key: layer3.10.bn3.bias, Val: torch.Size([256])
Key: layer3.10.bn3.running_mean, Val: torch.Size([256])
Key: layer3.10.bn3.running_var, Val: torch.Size([256])
Key: layer3.10.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.11.bn1.weight, Val: torch.Size([256])
Key: layer3.11.bn1.bias, Val: torch.Size([256])
Key: layer3.11.bn1.running_mean, Val: torch.Size([256])
Key: layer3.11.bn1.running_var, Val: torch.Size([256])
Key: layer3.11.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.11.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.11.bn2.weight, Val: torch.Size([256])
Key: layer3.11.bn2.bias, Val: torch.Size([256])
Key: layer3.11.bn2.running_mean, Val: torch.Size([256])
Key: layer3.11.bn2.running_var, Val: torch.Size([256])
Key: layer3.11.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.11.prelu.weight, Val: torch.Size([256])
Key: layer3.11.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.11.bn3.weight, Val: torch.Size([256])
Key: layer3.11.bn3.bias, Val: torch.Size([256])
Key: layer3.11.bn3.running_mean, Val: torch.Size([256])
Key: layer3.11.bn3.running_var, Val: torch.Size([256])
Key: layer3.11.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.12.bn1.weight, Val: torch.Size([256])
Key: layer3.12.bn1.bias, Val: torch.Size([256])
Key: layer3.12.bn1.running_mean, Val: torch.Size([256])
Key: layer3.12.bn1.running_var, Val: torch.Size([256])
Key: layer3.12.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.12.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.12.bn2.weight, Val: torch.Size([256])
Key: layer3.12.bn2.bias, Val: torch.Size([256])
Key: layer3.12.bn2.running_mean, Val: torch.Size([256])
Key: layer3.12.bn2.running_var, Val: torch.Size([256])
Key: layer3.12.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.12.prelu.weight, Val: torch.Size([256])
Key: layer3.12.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.12.bn3.weight, Val: torch.Size([256])
Key: layer3.12.bn3.bias, Val: torch.Size([256])
Key: layer3.12.bn3.running_mean, Val: torch.Size([256])
Key: layer3.12.bn3.running_var, Val: torch.Size([256])
Key: layer3.12.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer3.13.bn1.weight, Val: torch.Size([256])
Key: layer3.13.bn1.bias, Val: torch.Size([256])
Key: layer3.13.bn1.running_mean, Val: torch.Size([256])
Key: layer3.13.bn1.running_var, Val: torch.Size([256])
Key: layer3.13.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer3.13.conv1.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.13.bn2.weight, Val: torch.Size([256])
Key: layer3.13.bn2.bias, Val: torch.Size([256])
Key: layer3.13.bn2.running_mean, Val: torch.Size([256])
Key: layer3.13.bn2.running_var, Val: torch.Size([256])
Key: layer3.13.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer3.13.prelu.weight, Val: torch.Size([256])
Key: layer3.13.conv2.weight, Val: torch.Size([256, 256, 3, 3])
Key: layer3.13.bn3.weight, Val: torch.Size([256])
Key: layer3.13.bn3.bias, Val: torch.Size([256])
Key: layer3.13.bn3.running_mean, Val: torch.Size([256])
Key: layer3.13.bn3.running_var, Val: torch.Size([256])
Key: layer3.13.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer4.0.bn1.weight, Val: torch.Size([256])
Key: layer4.0.bn1.bias, Val: torch.Size([256])
Key: layer4.0.bn1.running_mean, Val: torch.Size([256])
Key: layer4.0.bn1.running_var, Val: torch.Size([256])
Key: layer4.0.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer4.0.conv1.weight, Val: torch.Size([512, 256, 3, 3])
Key: layer4.0.bn2.weight, Val: torch.Size([512])
Key: layer4.0.bn2.bias, Val: torch.Size([512])
Key: layer4.0.bn2.running_mean, Val: torch.Size([512])
Key: layer4.0.bn2.running_var, Val: torch.Size([512])
Key: layer4.0.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer4.0.prelu.weight, Val: torch.Size([512])
Key: layer4.0.conv2.weight, Val: torch.Size([512, 512, 3, 3])
Key: layer4.0.bn3.weight, Val: torch.Size([512])
Key: layer4.0.bn3.bias, Val: torch.Size([512])
Key: layer4.0.bn3.running_mean, Val: torch.Size([512])
Key: layer4.0.bn3.running_var, Val: torch.Size([512])
Key: layer4.0.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer4.0.downsample.0.weight, Val: torch.Size([512, 256, 1, 1])
Key: layer4.0.downsample.1.weight, Val: torch.Size([512])
Key: layer4.0.downsample.1.bias, Val: torch.Size([512])
Key: layer4.0.downsample.1.running_mean, Val: torch.Size([512])
Key: layer4.0.downsample.1.running_var, Val: torch.Size([512])
Key: layer4.0.downsample.1.num_batches_tracked, Val: torch.Size([])
Key: layer4.1.bn1.weight, Val: torch.Size([512])
Key: layer4.1.bn1.bias, Val: torch.Size([512])
Key: layer4.1.bn1.running_mean, Val: torch.Size([512])
Key: layer4.1.bn1.running_var, Val: torch.Size([512])
Key: layer4.1.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer4.1.conv1.weight, Val: torch.Size([512, 512, 3, 3])
Key: layer4.1.bn2.weight, Val: torch.Size([512])
Key: layer4.1.bn2.bias, Val: torch.Size([512])
Key: layer4.1.bn2.running_mean, Val: torch.Size([512])
Key: layer4.1.bn2.running_var, Val: torch.Size([512])
Key: layer4.1.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer4.1.prelu.weight, Val: torch.Size([512])
Key: layer4.1.conv2.weight, Val: torch.Size([512, 512, 3, 3])
Key: layer4.1.bn3.weight, Val: torch.Size([512])
Key: layer4.1.bn3.bias, Val: torch.Size([512])
Key: layer4.1.bn3.running_mean, Val: torch.Size([512])
Key: layer4.1.bn3.running_var, Val: torch.Size([512])
Key: layer4.1.bn3.num_batches_tracked, Val: torch.Size([])
Key: layer4.2.bn1.weight, Val: torch.Size([512])
Key: layer4.2.bn1.bias, Val: torch.Size([512])
Key: layer4.2.bn1.running_mean, Val: torch.Size([512])
Key: layer4.2.bn1.running_var, Val: torch.Size([512])
Key: layer4.2.bn1.num_batches_tracked, Val: torch.Size([])
Key: layer4.2.conv1.weight, Val: torch.Size([512, 512, 3, 3])
Key: layer4.2.bn2.weight, Val: torch.Size([512])
Key: layer4.2.bn2.bias, Val: torch.Size([512])
Key: layer4.2.bn2.running_mean, Val: torch.Size([512])
Key: layer4.2.bn2.running_var, Val: torch.Size([512])
Key: layer4.2.bn2.num_batches_tracked, Val: torch.Size([])
Key: layer4.2.prelu.weight, Val: torch.Size([512])
Key: layer4.2.conv2.weight, Val: torch.Size([512, 512, 3, 3])
Key: layer4.2.bn3.weight, Val: torch.Size([512])
Key: layer4.2.bn3.bias, Val: torch.Size([512])
Key: layer4.2.bn3.running_mean, Val: torch.Size([512])
Key: layer4.2.bn3.running_var, Val: torch.Size([512])
Key: layer4.2.bn3.num_batches_tracked, Val: torch.Size([])
Key: bn2.weight, Val: torch.Size([512])
Key: bn2.bias, Val: torch.Size([512])
Key: bn2.running_mean, Val: torch.Size([512])
Key: bn2.running_var, Val: torch.Size([512])
Key: bn2.num_batches_tracked, Val: torch.Size([])
Key: fc.weight, Val: torch.Size([512, 25088])
Key: fc.bias, Val: torch.Size([512])
Key: features.weight, Val: torch.Size([512])
Key: features.bias, Val: torch.Size([512])
Key: features.running_mean, Val: torch.Size([512])
Key: features.running_var, Val: torch.Size([512])
Key: features.num_batches_tracked, Val: torch.Size([])存储完成后的.wts文件如下,其中475,表示有这么多条权重数据,conv1.weight表示该层名称,1728权重数据个数, 20ef0c72 20f46cc8 20f714f0 206f1fed 这些是权重数据用十六进制进行存储。
475
conv1.weight 1728 20ef0c72 20f46cc8 20f714f0 206f1fed 2078e689 208d6c0d 20562efd 2017dd3c 202d0cdb 20755dad 204b726c 20af9431 1ed31810 1e832d16 1ff26962 9ed859c8 a0125abe 1f278d81 2063a689 206f8950 2084d557 1c621abf 9fefb9f5 1ec943e9 1e9db78d 9f5d6403 9ec0ca56 24c62a4e 249b30e2 248f9aaa 24cf396e 24c0e60f 24c963c9 24d78ee1
bn1.weight 64 20babdb1 a516b6ed 349d4837 3d9f15af 22493330 3e6943e5 3db2cb0d 3d900bbb a020b774 a6c605e3 3e084482 2432c23c 3db02e43 221a167a af58d433 3d1f0ac5 a1e5b55b ac98f344 1e6d4d26 3e22db0b 21a5b0a0 a0a27003 3ddf2fde b26e99bb a157eee2 3decfb12 3e12428d 2e3bfc4e a787dfd4 a523787b 9f5f0b12 3e284481 3e02e331 be0f25e1 31886dc6 be527e52 a30be012 3e320102 240f1c4b 2eab8aa7 3e19efd1 3df862d4 3df2a44b 9f932dea 216c0f6e 27e1a1b3 206a37f3 ac0dc29a 3e137d23 3808016d a284b5a0 28b68194 3dea9faa a3507731 31a6f7bd 25d6332b 3ddfd723 3ec64bb5 a07ecfe4 3a7a069f 3db52885 3e26c5a5 22d82e1a 21816b3d
bn1.bias 64 a18d6cfb a62de94b b5496e7e 3e356ff8 a31026e6 bea55b20 3d2155a7 3dfc9833 a3a24567 a789973d 3e7d0fad a4fa270e 3e020f55 a3759bb3 b087bc69 3dcb7f4e a26c6cf0 ae10c2d2 a50b3e4f bd3e22bc a31e6944 a3fe2ac5 3d80e7b4 b340a0ec a1fc4414 3d987d01 bbc4d721 afaf8207 a80a9b1a a5d3ad19 a1bd69d9 bd746de2 3d8f9506 bd93c203 b242cb2c be8290c0 a380c257 be02ec47 a51416a2 b029a132 3dd4270f 3d9b502f be094cde a2f97cf1 a290f128 a8831363 a1595ac5 ad44ff36 be2c8bf4 b898f8b6 a2ec3a74 abf53ab5 3dbbc20d a44126b0 b25dd238 a697bd13 3dccdaac beb8a428 a15e6172 bb9a233f 3e865888 3e8020c6 a36c8032 a41026c6
bn1.running_mean 64 00000004 80000004 338dd37e bb58f0fc 00000004 3dc09111 bde1d388 3ab5963b 00000004 00000004 bde8ba55 00000004 3bd323d4 80000004 00000004 bcd12a40 00000004 00000004 80000004 be44c85f 00000004 00000004 3bb0f592 00000004 80000004 3ba80fa9 3dd82a0d 00000004 80000004 80000004 80000004 bb62049a 3b43285f 3d0aaa23 80000004 bc16fdca 00000004 3d892466 00000004 00000004 3ba6e989 bb064eb8 3bb59f30 00000004 80000004 00000004 80000004 00000004 bca789c6 3876a2ab 80000004 80000004 39c86bbb 00000004 80000004 00000004 3b6dfbf8 bda99172 80000004 3b366427 3d2e533c 3e84e1ac 80000004 00000004
bn1.running_var 64 00000004 00000004 2b1060e9 3bd0c542 00000004 3dd128d6 3c4b3551 3baa0619 00000004 00000004 3ceccd3f 00000004 3c581e9e 00000004 00000004 3ca13e3c 00000004 00000004 00000004 3d1c57e8 00000004 00000004 3d4970ad 00000004 00000004 3d516c33 3d42ecc1 00000004 00000004 00000004 00000004 3db196c7 3d45ec2b 3cd6874d 00000004 3dbc2684 00000004 3d212688 00000004 00000004 3d8ad07e 3d5f7186 3c034f78 00000004 00000004 00000004 00000004 00000004 3cef5305 32a71857 00000004 00000004 3d299a71 00000004 00000004 00000004 3d1aa2e6 3ee607b4 00000004 36e98c48 3c4b22ac 3da75fbc 00000004 00000004
bn1.num_batches_tracked 1 47f6f900
prelu.weight 64 208e3e5a a55bd311 349c19ef 3edef8a0 a2707ab9 3bdabd42 bc2d8c4f bd5c65c7 232b0a40 271bff98 3d1a7356 24263ddd bd428d00 2298ec26 af7ff790 3b481ffa 22161c95 aca41739 21fd89b2 be1acec9 a11f983b 2330616c bdfc37ca b283f30b 2176bf17 be36a7f1 bd927041 2e1f3267 a8019bf2 251de32d a11d96d2 bd780fb1 be14979c bd381ab3 ae087529 bd388adf a3598e7c bd7f4ddb a40efed9 aec40891 bdc20924 bda56eee be2eb95d 22592f6c 219b81f1 a7e99ead 9e6cd811 2c43c26f 3c223359 b852b838 229cd03b a7f29953 be3e0af4 23b10087 b1e33ddd a61fa1f8 bdc60cba 3f57a1a9 9f835b2b 3b069e70 3e35f7bb bcc71aae 231176e3 a33ca9a0
layer1.0.bn1.weight 64 2081042c 250d79e4 b4fba1f6 3e887c4f 22b63514 3ddcad3d 3d366e5f 3df27f5c 20067eff 27055485 3d7505e8 a4213c0f 3dbb528c 22980d8b 2ff7b454 3da65b30 21ec2c14 acc83a7f 248c1246 3d78f3a5 22100ba0 23110fa0 3dd4cd8e 330b320b 21814d0a 3ded1f69 3d7f4296 2e39a2a9 a7fe44ac a5174a33 1e0cfae5 3d8abad4 3df1d02a bd975a38 31295778 3d9aa1f8 2355fb6c 3dbee7a6 23804e3e 2f4307ed 3e0ccf1c 3ddde867 3e17bb44 9ea8ff5a 2158d901 2814af8a 1efd1b89 2c910384 3dab8941 37bd04d3 229f755c 2b36ac07 3dec428e a330dae5 31d73eb1 255ec7e4 3dd6d4fb 3d576cd1 1ee1f7a7 3b1411c1 3d9fec99 3d4d5498 a312a722 228c4480
layer1.0.bn1.bias 64 bd6bc332 3d4e0be3 3c15963e 3d529200 3b1f9b4c bd77a378 3cd9ef26 3bf00968 bc8a369c bd3f791b 3df0909e bdb24811 bcf66211 bd4088db be33558e 3c9688df ba943e54 bdbbc1d5 3d104fe0 3c3fd916 bd110a85 bdb3652b 3d19dec5 bd2c5bde 3b28ddf1 3d4a10ad bddcce26 be2655a2 3cb695a1 3bf9819e 3d586bd0 bdced507 3c4c84a8 3da892a2 3c3118ff 3cb66154 bca259e3 bddddf3b be12f972 bd89e61e 3da9d4f2 3de69277 3da5a089 be92520f bd220c2a bdddb0ab bd00fcb1 bbe75695 bcee2f14 3db430ad bd032d32 bd80ec54 bcb77abb be209c3c be12ff15 bd2d5274 bbde7195 3b7d93da bd5c58f5 3c83a29c bbffbf81 3c0537cc bca5c9ea bd32d3ba
layer1.0.bn1.running_mean 64 80000004 00000004 80000004 3e373f63 00000004 3a232c52 3d725ae3 3e016abb 80000004 80000004 3e7d5101 80000004 3e066f64 80000004 00000004 3dcbf710 80000004 00000004 80000004 3d6a1bf2 00000004 80000004 3da10d96 00000004 80000004 3dbb6b7a 3d773d55 80000004 00000004 80000004 00000004 3d45f2da 3db59e44 3d14a288 00000004 3c8c4414 00000004 3d0448fe 00000004 00000004 3df98694 3dbbf5b6 3d0ae372 80000004 80000004 00000004 00000004 80000004 3bf249f4 00000004 80000004 80000004 3dd9bae0 80000004 00000004 00000004 3de32119 be98c8da 00000004 b7221df6 3e86ca9f 3e816012 80000004 00000004
layer1.0.bn1.running_var 64 00000004 00000004 00000004 3ba0dfba 00000004 390ed613 3b6c18da 3b7265af 00000004 00000004 3c8fc9f3 00000004 3bb2e127 00000004 00000004 3abdf04c 00000004 00000004 00000004 3b6e9b74 00000004 00000004 3bceed6a 00000004 00000004 3beb0991 3b96f7fd 00000004 00000004 00000004 00000004 3b7a56cf 3c0e569a 3b3ee4e1 00000004 3999c795 00000004 3ad833f6 00000004 00000004 3c4adbff 3c00f22b 3b3ca731 00000004 00000004 00000004 00000004 00000004 3a1e9791 00000004 00000004 00000004 3bee6b89 00000004 00000004 00000004 3bef33ac 3de586c2 00000004 2bdd72f5 3be88d81 3ccac01d 00000004 00000004
layer1.0.bn1.num_batches_tracked 1 47f6f9002、prelu实现
prelu转relu实现原理原理可参考,pytorch推理时将prelu转成relu实现_prelu换成relu nad-CSDN博客![]() https://link.zhihu.com/?target=https%3A//blog.csdn.net/zsf10220208/article/details/107457820,github可参考GitHub - PKUZHOU/MTCNN_FaceDetection_TensorRT: MTCNN C++ implementation with NVIDIA TensorRT Inference accelerator SDK
https://link.zhihu.com/?target=https%3A//blog.csdn.net/zsf10220208/article/details/107457820,github可参考GitHub - PKUZHOU/MTCNN_FaceDetection_TensorRT: MTCNN C++ implementation with NVIDIA TensorRT Inference accelerator SDK![]() https://link.zhihu.com/?target=https%3A//github.com/PKUZHOU/MTCNN_FaceDetection_TensorRT
https://link.zhihu.com/?target=https%3A//github.com/PKUZHOU/MTCNN_FaceDetection_TensorRT
由于Tensorrt还不支持prelu,因此需利用relu、add_scale、eltwise-sum等操作函数来实现prelu的功能,如下图所示:
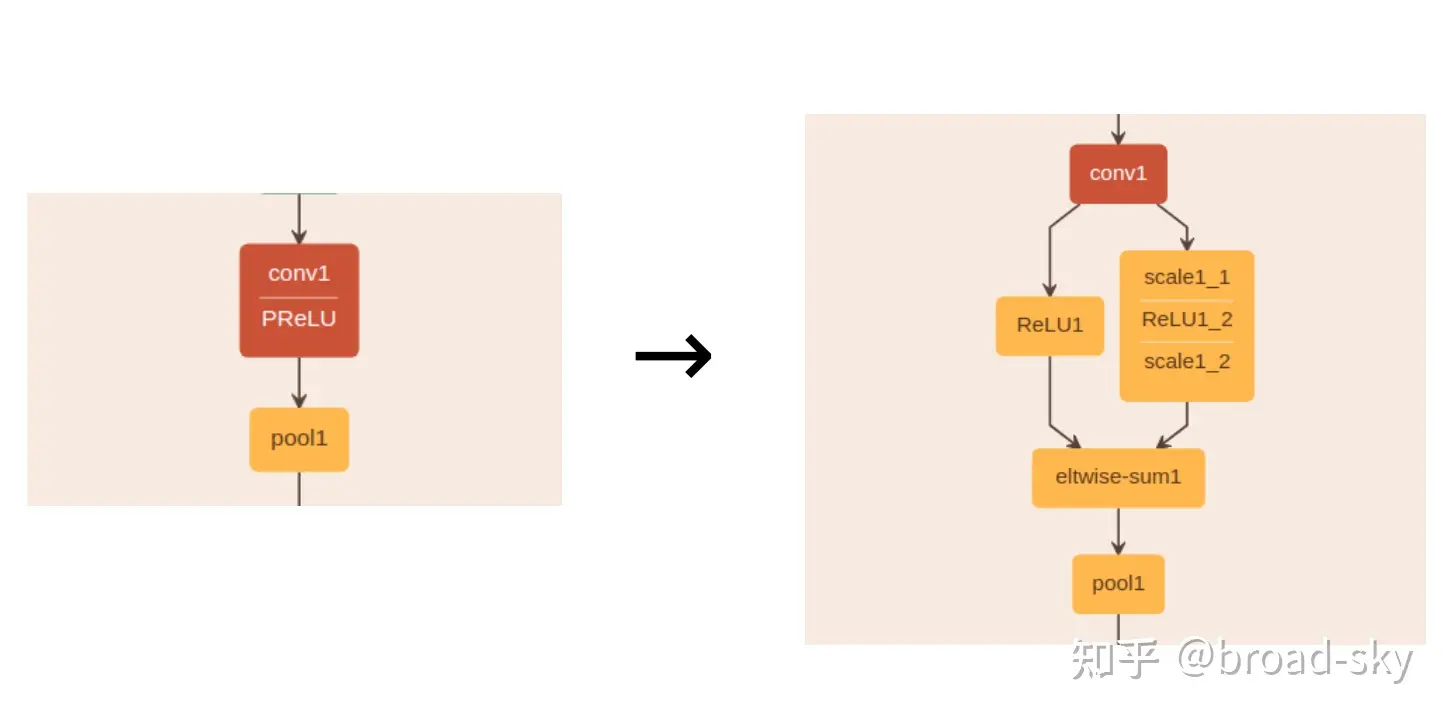
详细逻辑为:1、通过ReLU1得到大于0的值,2、对小于0的输入值取反(scale1_1操作),3、大于0的保留,小于等于0的置为0(ReLU1_2操作,即原有<0的保留,大于0的置为0),4、把大于0的值乘上-α(scale1_2,即得到小于0的值),5、把第一步的输出和第4步的输出,对应元素相加,则得到prelu结果(即eltwise-sum1操作)。具体实现看代码即可,需注意,其中addScale = (shift + scale * x) ^ power。
三、效果展示
