现在市面上关于基于 LLM 大模型的开源 AI 知识库有很多,比如,Dify、FastGPT、MaxKB等。其中,体验下来,觉得MaxKB整体页面使用起来比较流畅,简单易操作,不仅支持国内外主流的大模型对接,还支持流程编排,虽然目前还不支持函数库,但它的更新速度是很快的,1个月一个版本,从官网可知在8月底就会出函数库功能。如果有个性化需求调用的,可以期待一下。
好了,话不多说,开始正文。
一、MaxKB 是什么?
从官网可知,MaxKB = Max Knowledge Base,是一款基于 LLM 大语言模型的开源知识库问答系统,旨在成为企业的最强大脑。
产品优势:
- 开箱即用
支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好; - 无缝嵌入
支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力,提高用户满意度; - 灵活编排
内置强大的工作流引擎,支持编排 AI 工作流程,满足复杂业务场景下的需求; - 模型中立
支持对接各种大语言模型,包括本地私有大模型(Llama 3 / Qwen 2 等)、国内公共大模型(通义千问 / 智谱 AI / 百度千帆 / Kimi / DeepSeek 等)和国外公共大模型(OpenAI / Azure OpenAI / Gemini 等)。
二、开始部署
查看官网文档,这里的部署方式也很简单,在这里不做过多的介绍了,如果不会的小伙伴可以去参考一下官网。
https://maxkb.cn/docs/installation/offline_installtion/
三、对接 Xinference 平台
3.1 在MaxKB找到模型设置
因为MakKB本身不支持Xinference平台接入,但提供了OpenAI的接入方式,恰好 Xinference 也是支持 OpenAI接口的,所以刚好也可以对接。
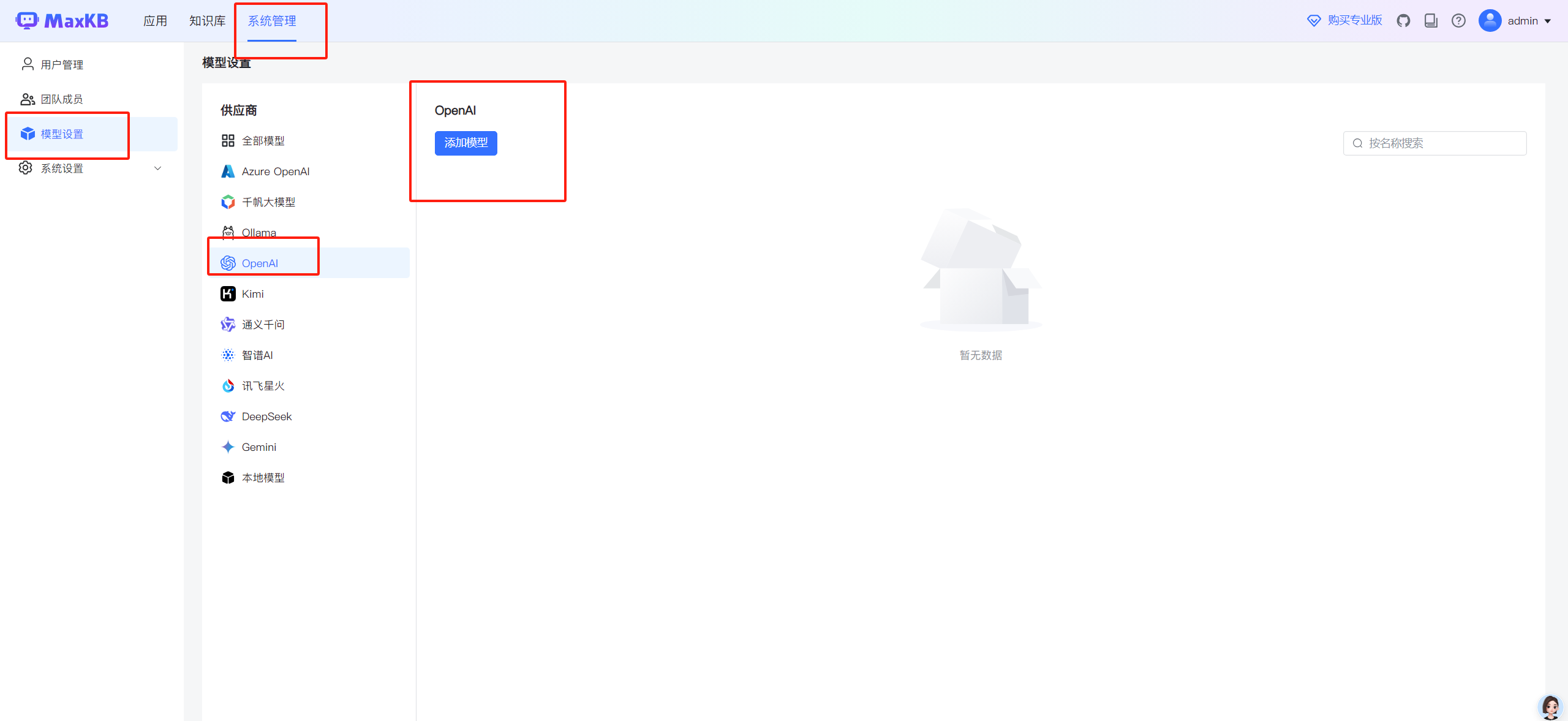
3.2 添加模型
点击"添加模型",这里参数注意。
API 域名:http://192.168.1.2:9997/v1/ (v1不能省略)
如果没有部署好xinference平台的,参考:如何部署xinference
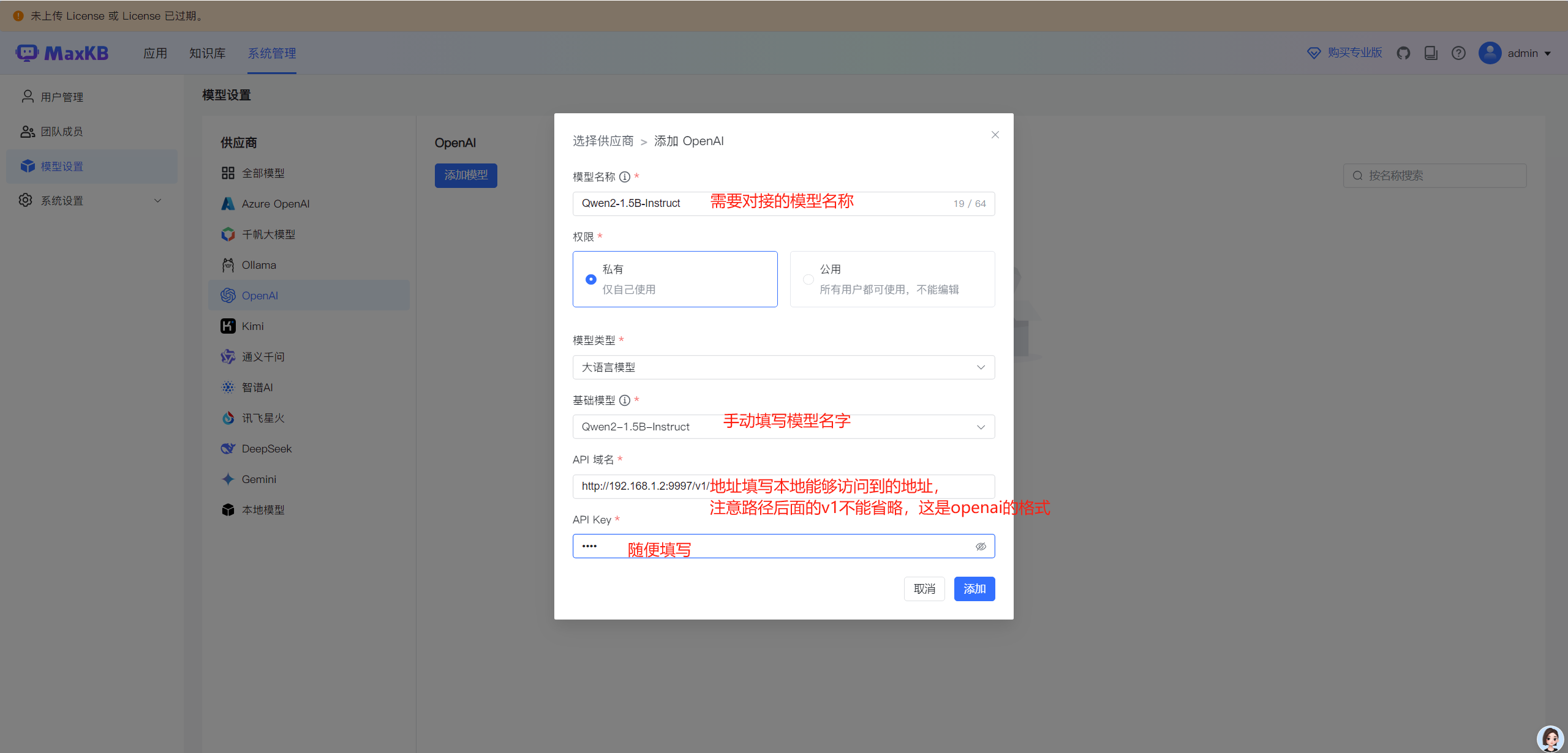
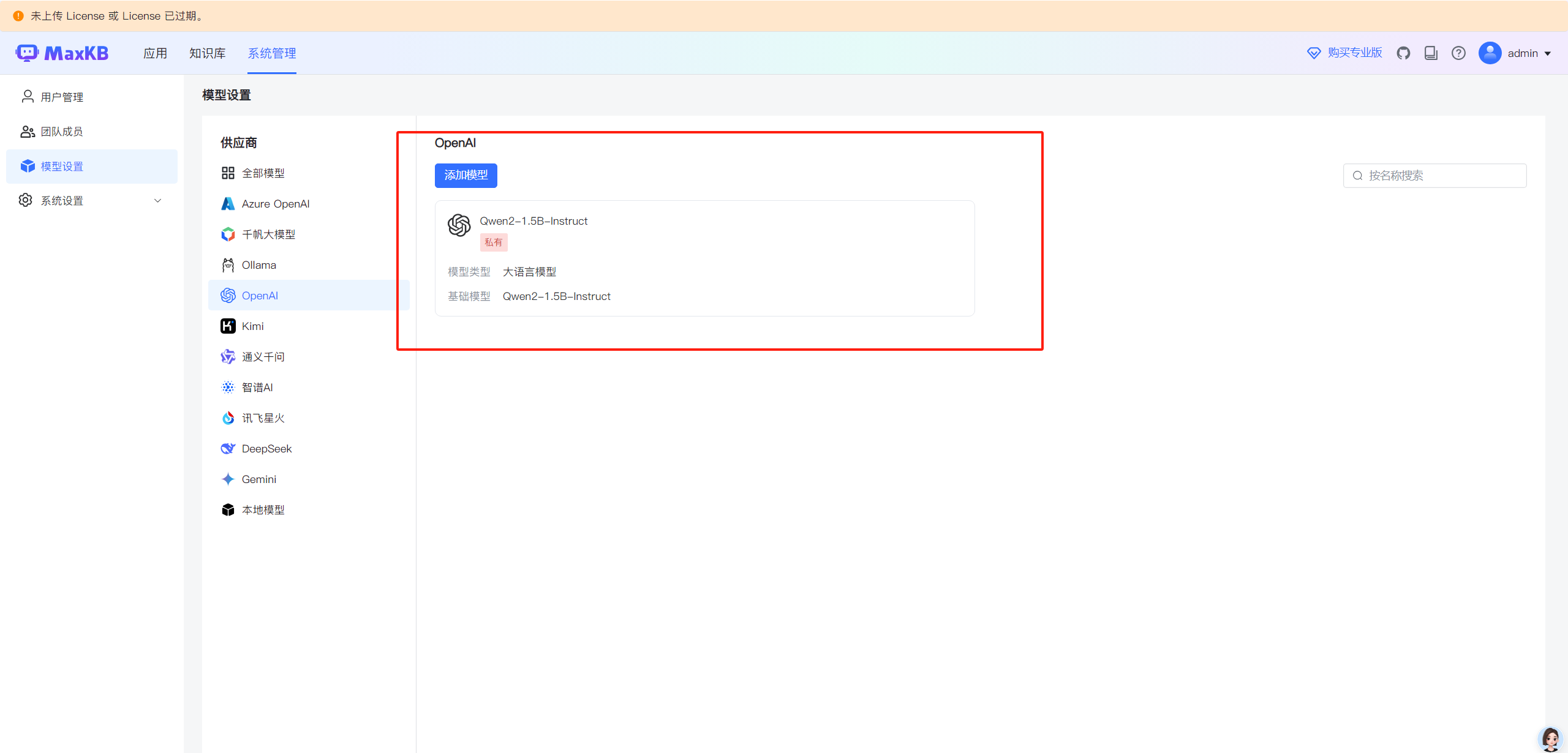
填写完参数,点击"添加"按钮,即可添加成功。如果报错,检查网络或者所填写地址是否能否访问。
四、创建应用
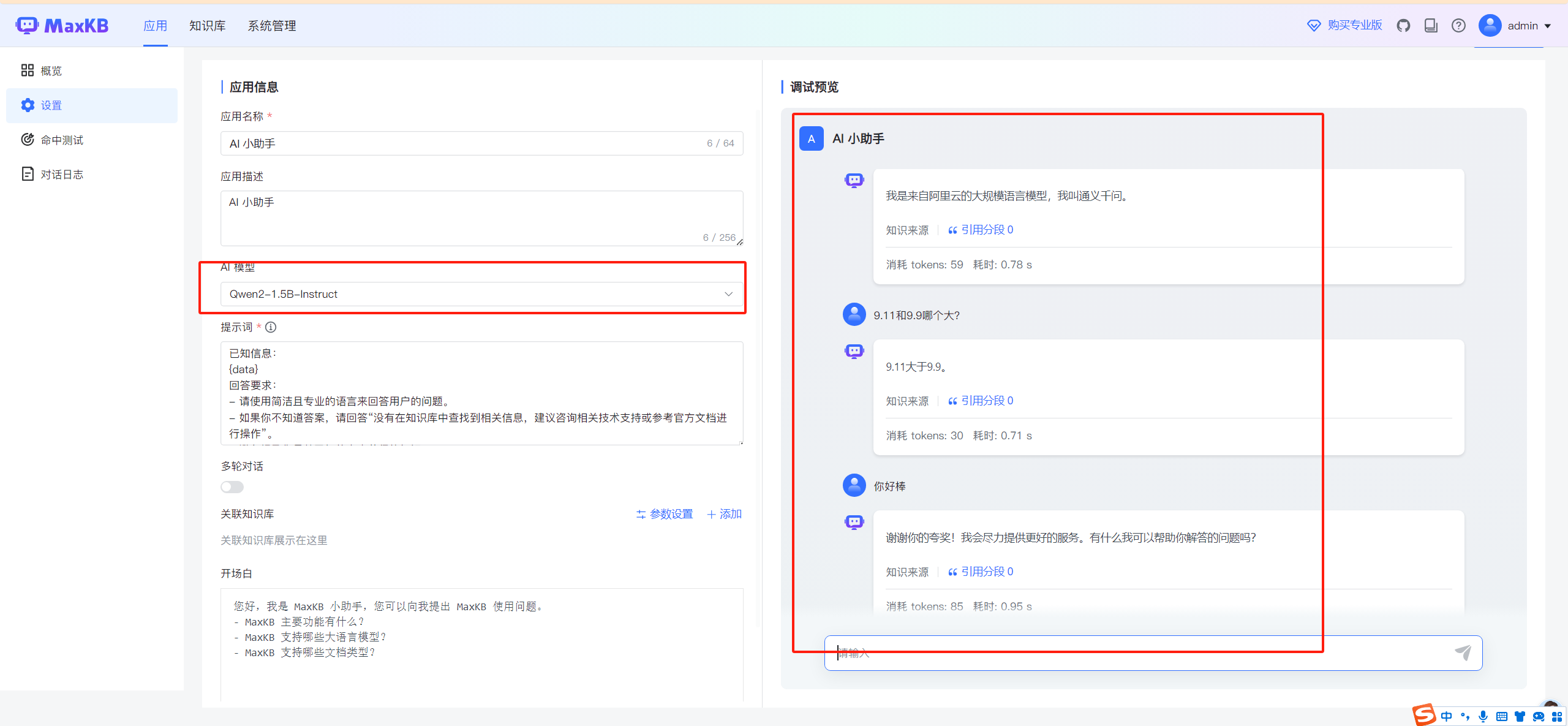
添加好了模型,直接创建应用即可。
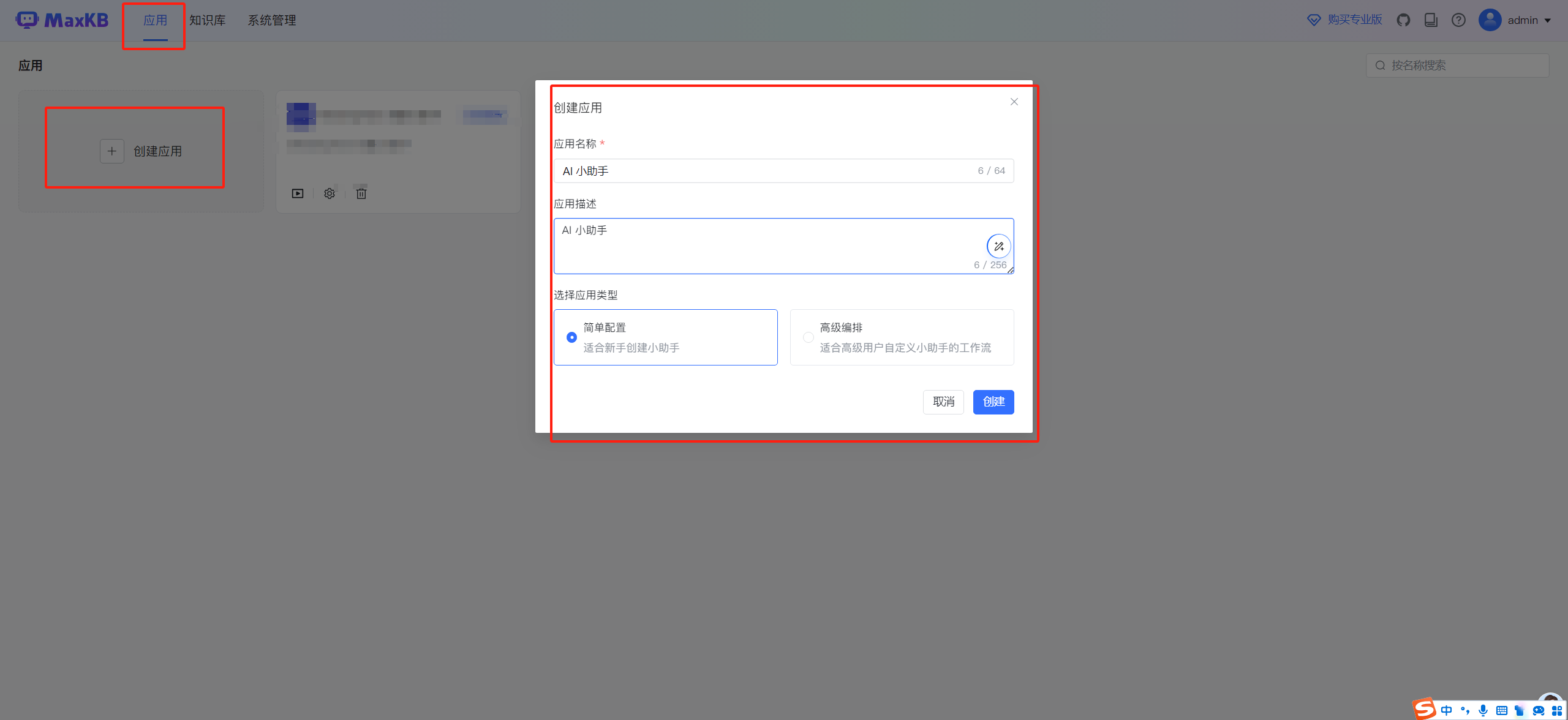
这里选择对应的模型即可使用。
五、总结
MaxKB作为国内开源私有化知识库搭建平台,有非常美观的操作页面和简单易懂的流程配置,还支持主流的模型对接,有着很大的潜力。
以上就是对接 Xinference 平台的操作步骤,欢迎讨论交流。