每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

大型语言模型现在在自然语言处理和理解领域占据了主导地位,凭借其高效性和多功能性脱颖而出。像Llama 3.1 405B和NVIDIA Nemotron-4 340B这样的大型语言模型在许多具有挑战性的任务中表现出色,包括编程、推理和数学。然而,这些模型的部署需要大量资源。因此,业界也在兴起另一种趋势,即开发小型语言模型。这些小型语言模型在许多语言任务中同样表现出色,但部署成本更低,更适合大规模应用。
最近,NVIDIA的研究人员表明,结合结构化权重剪枝和知识蒸馏是一种从大型模型逐渐获得小型模型的有效策略。NVIDIA Minitron 8B和4B就是通过剪枝和蒸馏其15B的"大型兄弟"NVIDIA Nemotron系列模型而得来的。
剪枝和蒸馏带来了多种好处:
- 与从头训练相比,MMLU评分提高了16%。
- 每个额外模型所需的训练数据token数量减少了约1000亿个,缩减比例高达40倍。
- 训练一系列模型的计算成本节省了1.8倍。
- 性能可与训练了更多token(高达15万亿)的Mistral 7B、Gemma 7B和Llama-3 8B模型相媲美。
该论文还提出了一套实用且有效的结构化压缩最佳实践,这些实践结合了深度、宽度、注意力和多层感知器剪枝,并通过基于知识蒸馏的再训练实现。
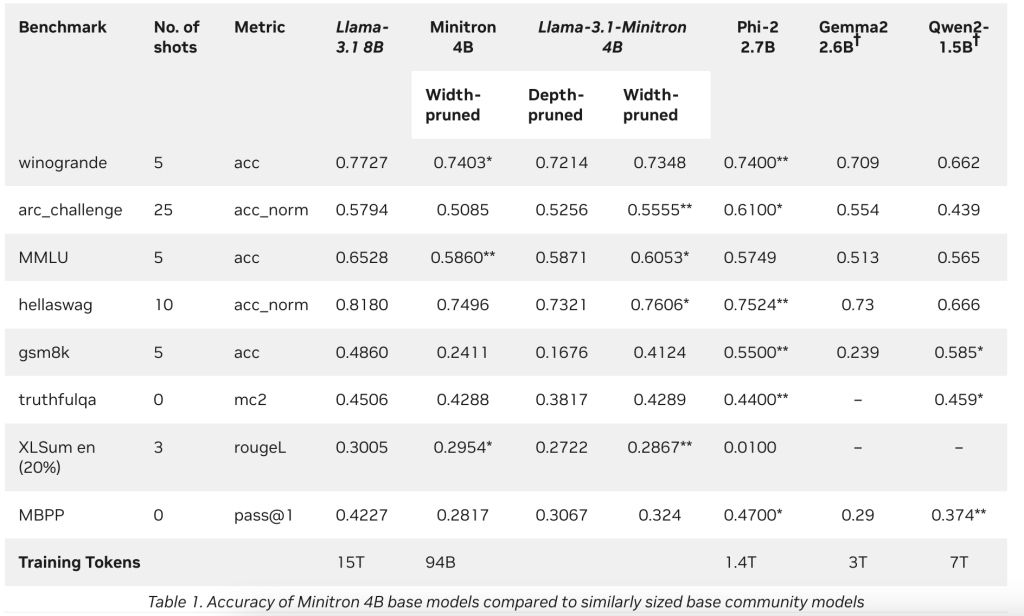
NVIDIA首先讨论这些最佳实践,然后展示它们在Llama 3.1 8B模型上的应用效果,得出Llama-3.1-Minitron 4B模型。Llama-3.1-Minitron 4B在与同类大小的开源模型(包括Minitron 4B、Phi-2 2.7B、Gemma2 2.6B和Qwen2-1.5B)的对比中表现优异。Llama-3.1-Minitron 4B即将发布到NVIDIA HuggingFace集合中,等待审批。
剪枝与蒸馏
剪枝是使模型变得更小、更精简的过程,方法包括丢弃层或丢弃神经元、注意力头和嵌入通道。剪枝通常伴随一定量的再训练以恢复准确性。
模型蒸馏是一种技术,用于将大型复杂模型中的知识转移到较小、较简单的学生模型中。其目标是在保持原始大型模型大部分预测能力的同时,创建一个运行速度更快、资源消耗更少的高效模型。
经典知识蒸馏与SDG微调
蒸馏主要有两种方式:
- SDG微调:使用从较大教师模型生成的合成数据进一步微调预训练的小型学生模型。在这种方式中,学生模型仅模仿教师模型最终预测的token。这在Llama 3.1 Azure Distillation和AWS使用Llama 3.1 405B生成合成数据并蒸馏以微调小型模型的教程中得到了体现。
- 经典知识蒸馏:学生模型模仿教师模型在训练数据集上的logits和其他中间状态,而不仅仅是学习要预测的token。这可以视为提供了更好的标签(一个分布与单个标签相比)。即使使用相同的数据,梯度也包含更丰富的反馈,从而提高了训练的准确性和效率。然而,经典蒸馏的这种方式需要训练框架支持,因为logits过大无法存储。
这两种蒸馏方式是互补的,而非互斥的。NVIDIA主要关注经典知识蒸馏方法。
剪枝与蒸馏过程
NVIDIA提出了一种结合剪枝与经典知识蒸馏的资源高效再训练技术。
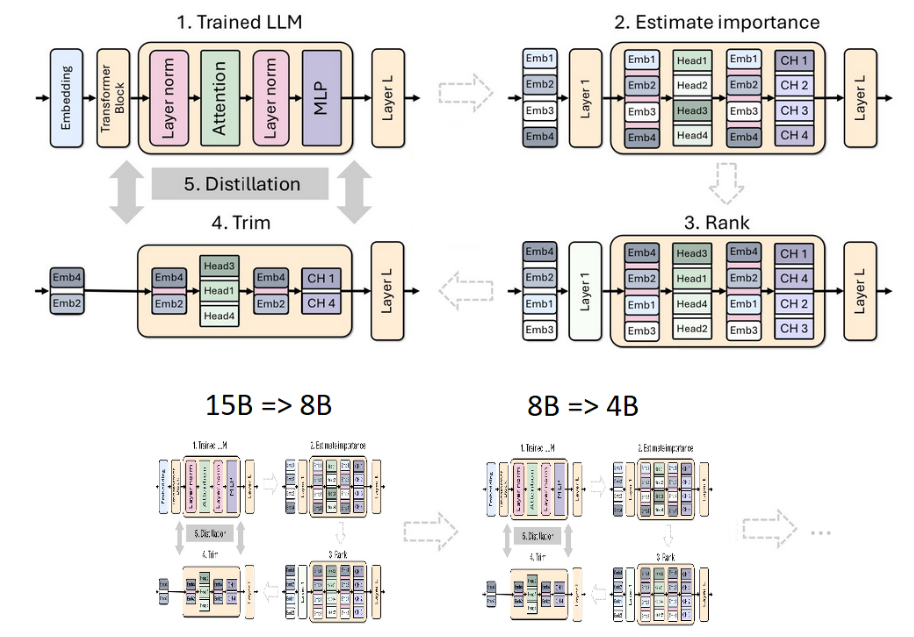
NVIDIA从一个15B的模型开始,评估每个组件的重要性(层、神经元、注意力头和嵌入通道),然后将模型修剪到目标大小:8B模型。
NVIDIA使用教师模型作为学生模型的教师,通过模型蒸馏执行轻量再训练过程。
训练完成后,小型模型(8B)作为起点进一步修剪和蒸馏到更小的4B模型。
图1显示了逐步剪枝和蒸馏模型的过程,从15B到8B,再从8B到4B。
重要性分析
要对模型进行剪枝,关键是要了解模型的哪些部分是重要的。NVIDIA建议使用一种基于激活的纯粹重要性估算策略,该策略通过使用小型校准数据集和仅前向传播计算,同时计算所有考虑轴(深度、神经元、头和嵌入通道)的敏感度信息。与依赖梯度信息且需要后向传播的策略相比,这种策略更加简单且具成本效益。
虽然可以针对给定的轴或轴的组合在剪枝和重要性估算之间反复交替进行,但NVIDIA的实验证明,使用单次重要性估算已经足够,迭代估算并没有带来任何好处。
经典知识蒸馏再训练
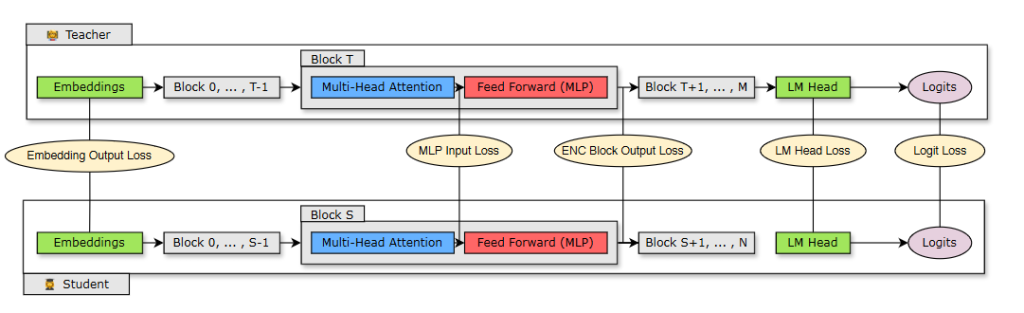
图2展示了学生模型从教师模型蒸馏的过程。学生通过最小化嵌入输出损失、logit损失和变压器编码器特定损失的组合进行学习,这些损失映射在学生模型的S块和教师模型的T块之间。
剪枝与蒸馏最佳实践
基于在《通过剪枝和知识蒸馏压缩语言模型》中进行的广泛消融研究,NVIDIA总结了几个结构化压缩的最佳实践:
尺寸:
- 要训练一系列大型语言模型,首先训练最大的模型,然后通过剪枝和蒸馏逐步获得较小的模型。
- 如果最大的模型使用多阶段训练策略,则最好剪枝并再训练最后阶段的模型。
- 剪枝时,优先选择接近目标大小的模型进行剪枝。
剪枝:
- 更倾向于进行宽度剪枝。这在考虑的模型规模(≤15B)中表现良好。
- 使用单次重要性估算。迭代重要性估算没有提供任何额外收益。
再训练:
- 专门使用蒸馏损失进行再训练,而不是传统训练。
- 当深度显著减少时,使用logit加中间状态加嵌入蒸馏。
- 当深度没有显著减少时,只使用logit蒸馏。
Llama-3.1-Minitron:实践最佳实践
Meta最近推出了功能强大的Llama 3.1模型系列,这是首批在许多基准测试中可与闭源模型相媲美的开源模型。Llama 3.1的规模从巨大的405B模型到70B和8B不等。
NVIDIA借鉴了Nemotron蒸馏的经验,开始将Llama 3.1 8B模型蒸馏为更小、更高效的4B模型:
- 教师微调
- 仅深度剪枝
- 仅宽度剪枝
- 准确性基准测试
- 性能基准测试
教师微调
为了纠正模型在原始数据集上的分布偏移,NVIDIA首先在数据集上对未剪枝的8B模型进行了微调。实验表明,如果不纠正分布偏移,教师模型在蒸馏过程中对数据集的指导效果会欠佳。
仅深度剪枝
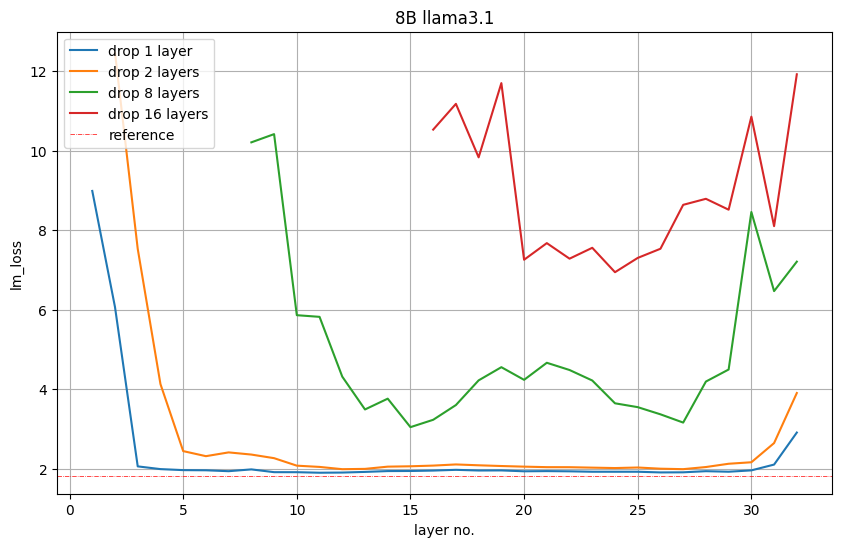
为了将模型从8B缩减到4B,NVIDIA剪去了16层。通过移除模型中的某些层,观察语言模型损失或在下游任务中的准确性降低,来评估每一层或连续层组的重要性。
图5显示了在验证集上移除1层、2层、8层或16层后的语言模型损失值。NVIDIA发现,模型开头和结尾的层最为重要。
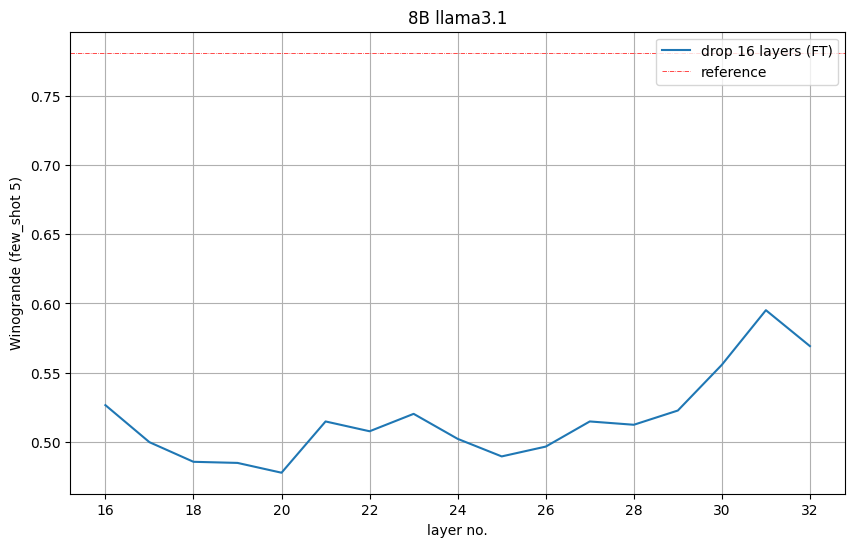
然而,NVIDIA注意到语言模型损失与下游性能之间并不直接相关。图6展示了每个剪枝模型在Winogrande任务上的准确性,表明移除16到31层(即倒数第二层)效果最佳。NVIDIA据此洞见,移除了16到31层。
仅宽度剪枝
NVIDIA通过宽度剪枝压缩了Llama 3.1 8B模型,主要剪掉了嵌入和MLP中间维度。具体而言,NVIDIA使用前面提到的基于激活的策略,计算每个注意力头、嵌入通道和MLP隐藏维度的重要性分数。随后:
- 将MLP中间维度从14336剪至9216。
- 将隐藏尺寸从409
6剪至3072。
- 重新训练了注意力头数和层数。
值得注意的是,宽度剪枝后的一次性剪枝的语言模型损失高于深度剪枝,但经过短暂的再训练后,趋势发生了逆转。
准确性基准测试
NVIDIA在以下参数下对模型进行了蒸馏:
- 最大学习率=1e-4
- 最小学习率=1e-5
- 线性热身40步
- 余弦衰减计划
- 全局批量大小=1152
表1展示了Llama-3.1-Minitron 4B模型(宽度剪枝和深度剪枝变体)与原始Llama 3.1 8B模型及其他类似大小模型在多个领域基准测试中的比较结果。整体上,NVIDIA再次确认宽度剪枝策略相比深度剪枝的有效性,这符合最佳实践。
性能基准测试
NVIDIA使用NVIDIA TensorRT-LLM(一个用于优化大型语言模型推理的开源工具包)优化了Llama 3.1 8B和Llama-3.1-Minitron 4B模型。

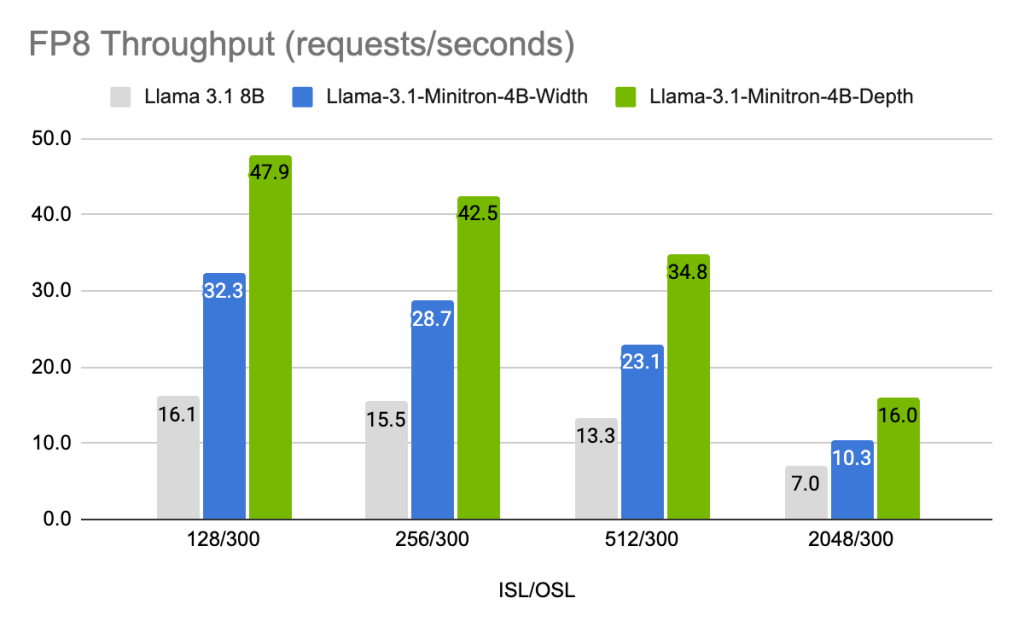
图7和图8显示了不同模型在不同精度(FP8和FP16)下的每秒请求吞吐量。在不同用例中,使用的输入序列长度/输出序列长度组合,批次大小为32(8B模型)和64(4B模型)。Llama-3.1-Minitron-4B-Depth-Base变体的平均吞吐量是Llama 3.1 8B的约2.7倍,而Llama-3.1-Minitron-4B-Width-Base变体的平均吞吐量是Llama 3.1 8B的约1.8倍。在FP8中部署所有三个模型还带来了约1.3倍的性能提升。
总结
剪枝与经典知识蒸馏是一种非常具成本效益的方法,能够逐步获得更小的大型语言模型,且在各个领域中的准确性优于从头训练。这比使用合成数据风格的微调或从头预训练更有效且数据更高效。
Llama-3.1-Minitron 4B是NVIDIA在开源Llama 3.1系列中的首次尝试。想要使用NVIDIA NeMo中Llama-3.1的SDG微调,请参见GitHub上的/sdg-law-title-generation笔记本。https://github.com/NVIDIA/NeMo/tree/main/tutorials/llm/llama-3/sdg-law-title-generation