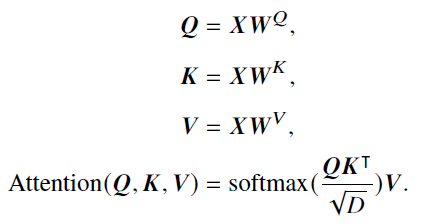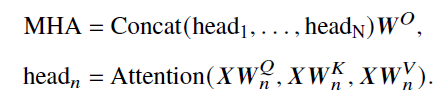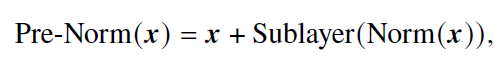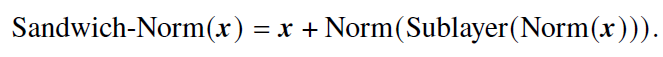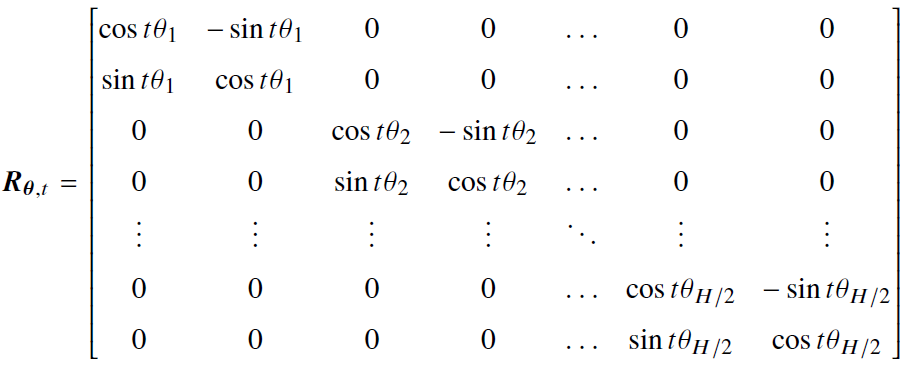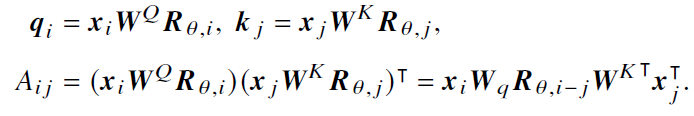第五章 模型架构
5.1.1 输入编码
- 词元序列变成固定维度的词向量 ,加上固定维度的绝对位置编码
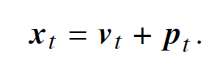
5.1.2 多头自注意力机制(Multi-head Self-attention)
- 单头 :对于输入的词元序列,将其映射为相应的**查询(Query, 𝑸)、键(Key, 𝑲)和值(Value, 𝑽)**三个矩阵,然后,对于每个查询,将和所有没有被掩盖的键之间计算点积,缩放后softmax计算权重,加权乘V
- 多头 :先通过不同的权重矩阵被映射为一组查询、键和值,每组映射构成一个"头"并独立地计算自注意力的输出。最后不同头的输出被拼接在一起,并通过一个权重矩阵𝑾𝑂 ∈ R𝐻×𝐻进行映射,产生最终的输出
- 优势:能够直接建模序列中任意两个位置之间的关系,进而有效捕获长程依赖关系,具有更强的序列建模能力,自注意力的计算过程对于基于硬件的并行优化(如GPU、TPU 等)非常友好
5.1.3 前馈网络层(Feed Forward Netwok)
- 结构:两个线性变换和一个非线性激活函数组成
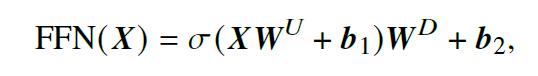
- 优势:引入了非线性映射变换,提升了模型的表达能力,从而更好地捕获复杂的交互关系
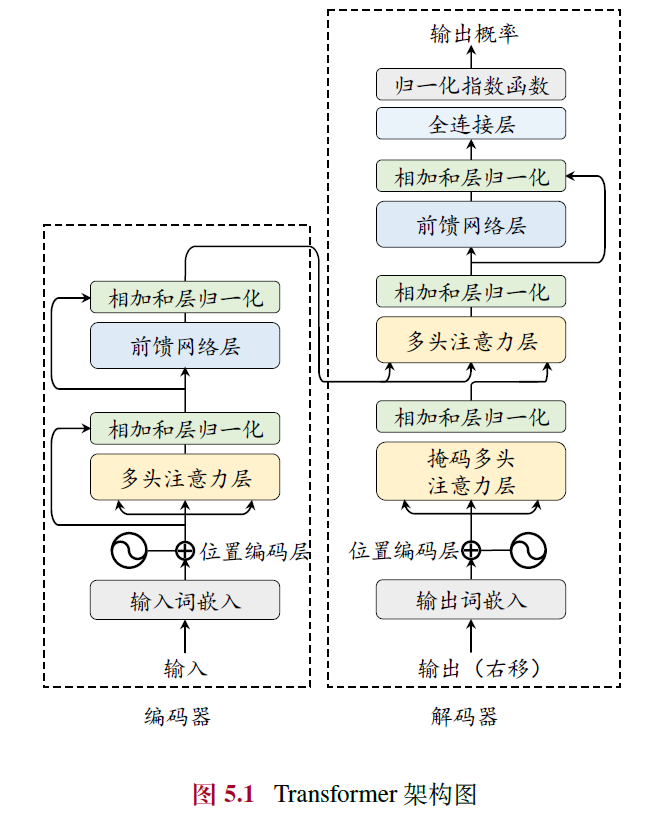
5.1.4 编码器
- 作用:将每个输入词元都编码成一个上下文语义相关的表示向量
- 残差连接(Residual Connection):将输入与该层的输出相加,实现了信息在不同层的跳跃传递,从而缓解梯度爆炸和消失的问题
- 层归一化(LayerNorm):对数据进行重新放缩,提升模型的训练稳定性
- 双向注意力:使用原因为输入数据完全可见,每个位置的词元表示能够有效融合上下文的语义关系

5.1.5 解码器
- 作用:基于来自编码器编码后的最后一层的输出表示以及已经由模型生成的词元序列,执行序列生成任务
- 掩码自注意力(Masked Self-attention):在计算注意力分数的时候掩盖当前位置之后的词,以保证生成目标序列时不依赖于未来的信息
- 交叉注意力层:关注编码器输出的上下文信息𝑿𝐿
- 全连接层:将输出映射到大小为 𝑉 的目标词汇表的概率分布,并基于某种解码策略生成对应的词元

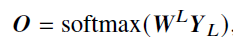
5.2 详细配置
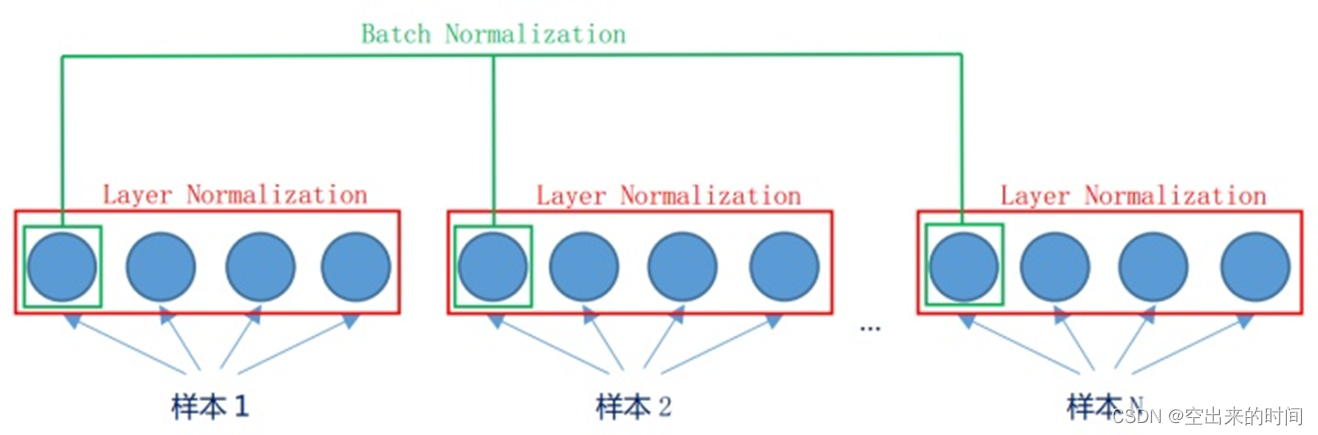
5.2.1 归一化方法
- 层归一化方法(Layer Normalization, LN)
- 原因:**批次归一化(Batch Normalization, BN)**难以处理可变长度的序列数据和小批次数据
- 计算每一层中所有激活值的均值𝝁 和方差𝝈,从而重新调整激活值的中心和缩放比例
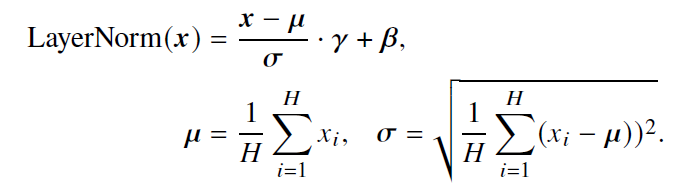
- 均方根层归一化(Root Mean Square Layer Normalization, RMSNorm)
- 改进:仅利用激活值总和的均方根RMS(𝒙) 对激活值进行重新缩放
- 作用:训练速度和性能上均具有一定优势
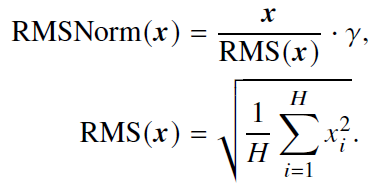
import torch
import torch.nn as nn
class LlamaRMSNorm(nn.Module):
# 定义一个继承自nn.Module的类,用于实现自定义的RMSNorm归一化层
def __init__(self, normalized_shape, eps=1e-6):
super().__init__() # 调用基类的构造函数
self.weight = nn.Parameter(torch.ones(normalized_shape)) # 初始化权重参数,为1的张量
self.variance_epsilon = eps # 定义一个很小的数值,用于数值稳定性
def forward(self, hidden_states):
# 前向传播函数,用于定义归一化操作
input_dtype = hidden_states.dtype # 记录原始输入数据的类型
hidden_states = hidden_states.to(torch.float32) # 将输入转换为浮点数,以进行数学运算
variance = hidden_states.pow(2).mean(-1, keepdim=True) # 计算输入的方差,保留维度以进行广播
# 计算隐状态的均方根
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon) # 计算RMS并除以方差,增加数值稳定性,torch.rsqrt是取平方根的倒数
# 将隐状态除以其均方根后重新缩放
return self.weight * hidden_states # 将权重参数乘以归一化后的输入,得到最终输出
- DeepNorm
- 改进:在LayerNorm 的基础上,在残差连接中对之前的激活值𝒙 按照一定比例𝛼 进行放缩
- 作用:扩展更深的Transformer,进而有效提升模型性能与训练稳定性

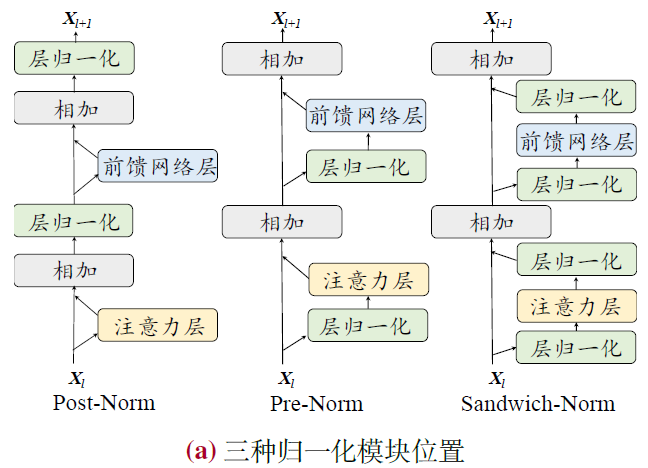
5.2.2 归一化模块位置
- 层后归一化(Post-Layer Normalization, Post-Norm)
- 公式
- 优势
- 加快训练收敛速度,更有效地传播梯度,减少训练时间
- 降低神经网络对于超参数(如学习率、初始化参数等)的敏感性,更容易调优
- 劣势
- 层前归一化(Pre-LayerNormalization, Pre-Norm)
- 夹心归一化(Sandwich-Layer Normalization, Sandwich-Norm)
- 公式
- 优势
- 劣势
- 有时仍然无法保证大语言模型的稳定训练,甚至会引发训练崩溃的问题
5.2.3 激活函数
- 作用
- 为神经网络中引入非线性变化,从而提升神经网络的模型能力
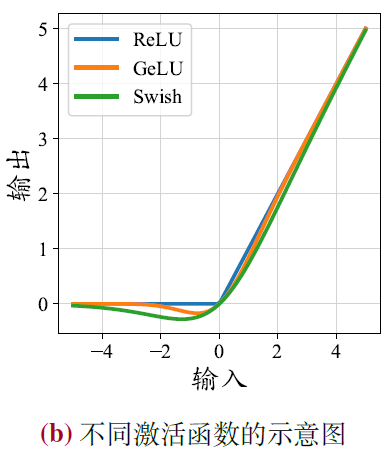
- RELU

- 可能会产生神经元失效的问题,被置为0 的神经元将学习不到有用的信息
- Swish、GELU
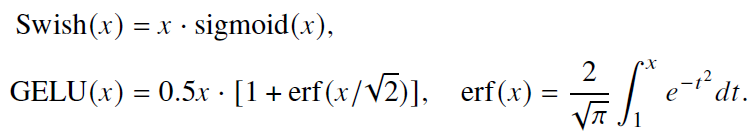
- 能够带来更好的性能并且收敛性更好,但是计算过程更为复杂
- GLU(Gated Linear Unit)及变种:SwiGLU、GeGLU
- 引入了两个可学习的线性层,一个层的输出被激活,再和另一个层的输出逐元素相乘
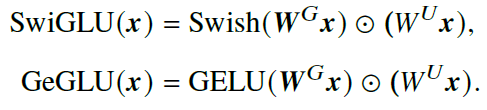
- 能够带来更佳的性能表现
5.2.4 位置编码
- 绝对位置编码
- 预先定义好的编码
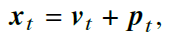
- 𝒑𝑡 表示位置 𝑡 的位置嵌入,𝒗𝑡 是该位置词元对应的词向量
- Bert、GPT用可学习的绝对位置编码,Transformer用以下直接算得的
- 正余弦位置编码,维度大小为H,第 i 维的值为
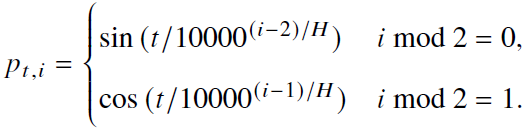
- 相对位置编码
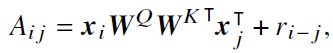
- 𝑟 𝑖− 𝑗 表示基于查询和键之间偏移的可学习标量
- 相对位置编码可以对更长的序列进行建模,具备一定外推能力
- 旋转位置编码(Rotary Position Embedding, RoPE)
def rotate_half(x):
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
# 将向量每两个元素视为一个子空间
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
cos = cos[position_ids].unsqueeze(1)
sin = sin[position_ids].unsqueeze(1)
# 获得各个子空间旋转的正余弦值
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
# 将每个子空间按照特定角度进行旋转
return q_embed, k_embed
- 优势:具有良好的性能和长期衰减的特性,扩展外推性好,被PaLM和LLAMA等使用
- ALiBi 位置编码
- 通过在键和查询之间的距离上施加相对距离相关的惩罚来调整注意力分数
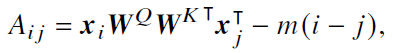
- 𝑖 − 𝑗 是查询和键之间的位置偏移量,𝑚 是每个注意力头独有的惩罚系数(预先定义)
- 优势:具有优秀的外推性能,能够对于超过上下文窗口更远距离的词元进行有效建模
import math
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
batch_size, seq_length = attention_mask.shape
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
base = torch.tensor(2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32)
powers = torch.arange(1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32)
slopes = torch.pow(base, powers)
# 计算各个头的惩罚系数
if closest_power_of_2 != num_heads:
# 如果头数不是2 的幂次方,修改惩罚系数
extra_base = torch.tensor(2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32)
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, device=attention_mask.device, dtype=torch.int32)
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
arange_tensor = ((attention_mask.cumsum(dim=-1) - 1) * attention_mask)[:, None, :]
# 计算相对距离
alibi = slopes[..., None] * arange_tensor
# 计算ALiBi 施加的注意力偏置
return alibi.reshape(batch_size * num_heads, 1, seq_length).to(dtype)
5.2.5 注意力机制
- 完整自注意力机制
- 对于序列长度为𝑇 的序列需要𝑂(𝑇2) 的计算复杂度,参考5.1.2
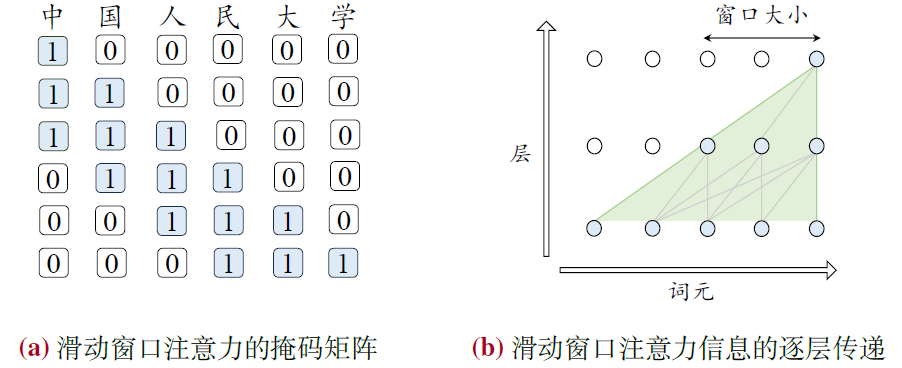
- 稀疏注意力机制
- 滑动窗口注意力机制(Sliding Window Attention, SWA)
- 只对固定窗口大小内进行注意力计算
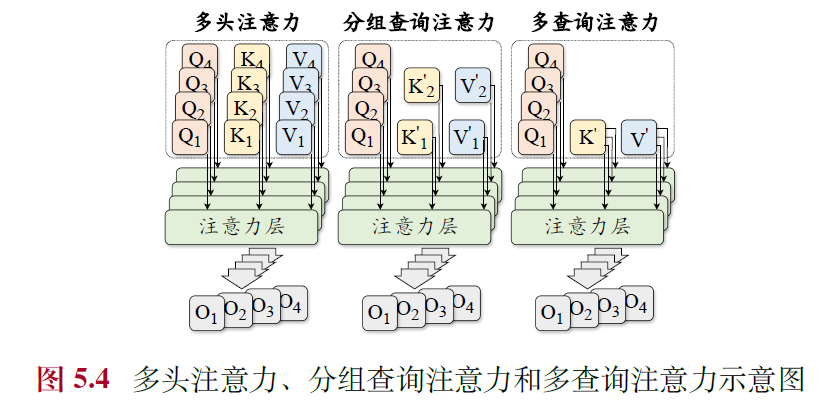
- 多查询/分组查询注意力
- 多查询注意力(Multi-Query Attention, MQA)
- 针对不同的头共享相同的键和值变换矩阵
- 减少了访存量,提高了计算强度,从而实现了更快的解码速度,对性能影响小
- 分组查询注意力机制(Grouped-Query Attention, GQA)
- 将全部的头划分为若干组,并且针对同一组内的头共享相同的变换矩阵。
- 有效地平衡了效率和性能,LLaMA-2使用
- 硬件优化的注意力机制
- FlashAttention:通过矩阵分块计算以及减少内存读写次数的方式,提高注意力分数的计算效率
- PagedAttention:针对增量解码阶段,对于KV缓存进行分块存储,优化了计算方式,增大了并行计算度,从而提高了计算效率
5.2.6 混合专家模型
- 基于稀疏激活的混合专家架构(Mixture-of-Experts, MoE)
- 目的:在不显著提升计算成本的同时实现对于模型参数的拓展
- 过程:线性层映射为专家得分,选topk个专家计算权重,混合输出
- 公式
- 路由网络

- 最终输出
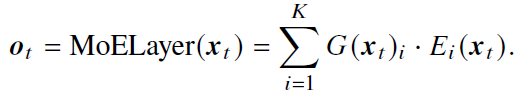
- 代表:Mixtral (8×7B),每层8个专家激活2个,总数只激活13B的情况下超过LLaMA-2 (70B)
from typing import List
import torch.nn as nn
import torch.nn.functional as F
class MoeLayer(nn.Module):
def __init__(self, experts: List[nn.Module], gate: nn.Module, num_experts_per_tok: int):
super().__init__()
assert len(experts) > 0
self.experts = nn.ModuleList(experts) # 所有专家的列表
self.gate = gate # 路由网络
self.num_experts_per_tok = num_experts_per_tok # 每个词元选择的专家数目
def forward(self, inputs: torch.Tensor):
gate_logits = self.gate(inputs)
weights, selected_experts = torch.topk(gate_logits,
self.num_experts_per_tok)
# 使用路由网络选择出top-k 个专家
weights = F.softmax(weights, dim=1, dtype=torch.float).to(inputs.dtype)
# 计算出选择的专家的权重
results = torch.zeros_like(inputs)
for i, expert in enumerate(self.experts):
batch_idx, nth_expert = torch.where(selected_experts == i)
results[batch_idx] += weights[batch_idx, nth_expert, None] * expert(inputs[batch_idx])
# 将每个专家的输出加权相加作为最终的输出
return results
5.2.7 LLaMA 的详细配置
- **归一化:**前置的RMSNorm
- **激活函数:**优先考虑使用SwiGLU或GeGLU
- **位置编码:**优先选择RoPE 或者ALiBi
- **LLaMA模型:**首先将输入的词元序列通过词嵌入矩阵转化为词向量序列。之后,词向量序列作为隐状态因此通过𝐿 个解码器层,并在最后使用RMSNorm 进行归一化。归一化后的最后一层隐状态将作为输出。
class LlamaModel(LlamaPreTrainedModel):
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.vocab_size = config.vocab_size
# LLaMA 的词表大小
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
# LLaMA 的词嵌入矩阵,将输入的id 序列转化为词向量序列
self.layers = nn.ModuleList([LlamaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)] )
# 所有的Transformer 解码器层
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
causal_mask = torch.full((config.max_position_embeddings, config.max_position_embeddings), fill_value=True, dtype=torch.bool)
@add_start_docstrings_to_model_forward(Llama_INPUTS_DOCSTRING)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
**kwargs,
) -> Union[Tuple, BaseModelOutputWithPast]:
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
# 将输入的input id 序列转化为词向量序列
causal_mask = self._update_causal_mask(attention_mask, inputs_embeds)
# 创建单向注意力的注意力掩盖矩阵
hidden_states = inputs_embeds
for decoder_layer in self.layers:
hidden_states = decoder_layer(hidden_states, attention_mask=causal_mask, position_ids=position_ids)[0]
# 用每个LLaMA 解码器层对词元的隐状态进行映射
hidden_states = self.norm(hidden_states)
# 对每个词元的隐状态使用RMSNorm 归一化
return BaseModelOutputWithPast(last_hidden_state=hidden_states)
- **LLaMA层:**在每个解码器层中,隐状态首先通过层前的RMSNorm 归一化并被送入注意力模块。注意力模块的输出将和归一化前的隐状态做残差连接。之后,新的隐状态进行RMSNorm 归一化,并送入前馈网络层。前馈网络层的输出同样做残差连接,并作为解码器层的输出
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = LlamaAttention(config=config, layer_idx=layer_idx) # 注意力层
self.mlp = LlamaMLP(config) # 前馈网络层
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 注意力层和前馈网络层前的RMSNorm
def forward(self,hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, **kwargs,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
# 注意力层前使用RMSNorm 进行归一化
hidden_states, self_attn_weights, present_key_value =
self.self_attn(hidden_states=hidden_states, attention_mask=attention_mask, position_ids=position_ids, **kwargs,)
# 进行注意力模块的计算
hidden_states = residual + hidden_states
# 残差连接
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
# 前馈网络层前使用RMSNorm 进行归一化
hidden_states = self.mlp(hidden_states)
# 进行前馈网络层的计算
hidden_states = residual + hidden_states
# 残差连接
outputs = (hidden_states,)
return outputs
5.3 主流架构
5.3.1 编码器-解码器架构
5.3.2 因果解码器架构
- 单向的掩码注意力机制:每个输入的词元只关注序列中位于它前面的词元和它本身
- 删除了交叉注意力模块:经过自注意力模块后的词元表示将直接送入到前馈神经网络中
- GPT系列、BLOOM、LLaMA 和Mistral 等
5.3.3 前缀解码器架构
- 双向+单向注意力编码:输入前缀比分使用双向,输出自回归部分用单向
- GLM-130B、U-PaLM
5.4 长上下文模型
5.4.1 扩展位置编码
- 拓展方法
- 在RoPE 的每个子空间𝑖上,对于相对位置𝑡,旋转角度𝑓(𝑡, 𝑖)=𝑡 · 𝜃𝑖的修改可以分解为对距离𝑡的修改𝑔(𝑡)和 对基𝜃𝑖的修改ℎ(𝑖),表现为以下公式
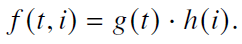
- 直接微调
- 使用相应的长文本数据对于模型进行微调
- 优势:无需修改RoPE,还是
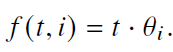
- 劣势:旋转角度增大,注意力爆炸,收敛缓慢
- 位置索引修改:g(t)
- 位置内插
- 对于位置索引进行特定比例的缩放,以保证旋转角度不会超过原始上下文窗口的最大值
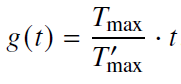
- 优势:少量微调后即可扩展
- 劣势:处理较短文本可能有负面影响
- 位置截断
- 对模型中近距离敏感的位置索引进行保留,同时截断或插值处理远距离的位置索引,确保其不超出预设的最大旋转角度
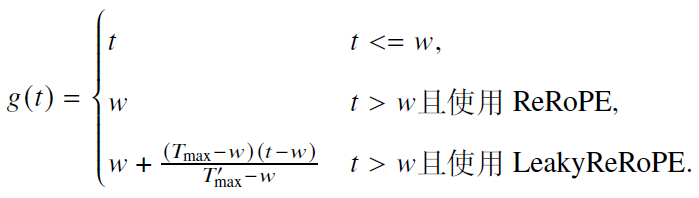
- 优势:修改后模型能够直接应用于更长的上下文无需重新训练,并且依然保持对短文本的建模能力
- 劣势:需要对注意力矩阵进行二次计算,进而增加了额外的计算开销
- 基修改:h(i)
- 调整子空间的旋转角度分布,针对基h(i)进行缩放
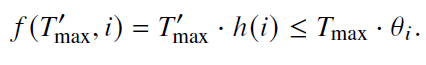
- 底数调整
- 通过调整底数可以改变旋转的角度
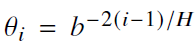 变成
变成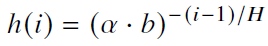 ,𝛼 是一个大于等于放缩比例的数
,𝛼 是一个大于等于放缩比例的数- 可以不用额外训练,也可以在长文本上微调
- 基截断
- 通过修改关键子空间来避免产生过大的旋转角度,设定a、c两个阈值限定角度
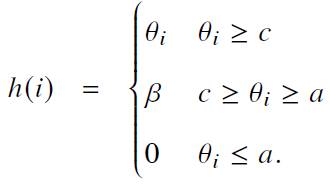
- 有较好模型外推性能,但是也削弱了某些子空间对不同位置索引的区分能力,性能下降
5.4.2 调整上下文窗口
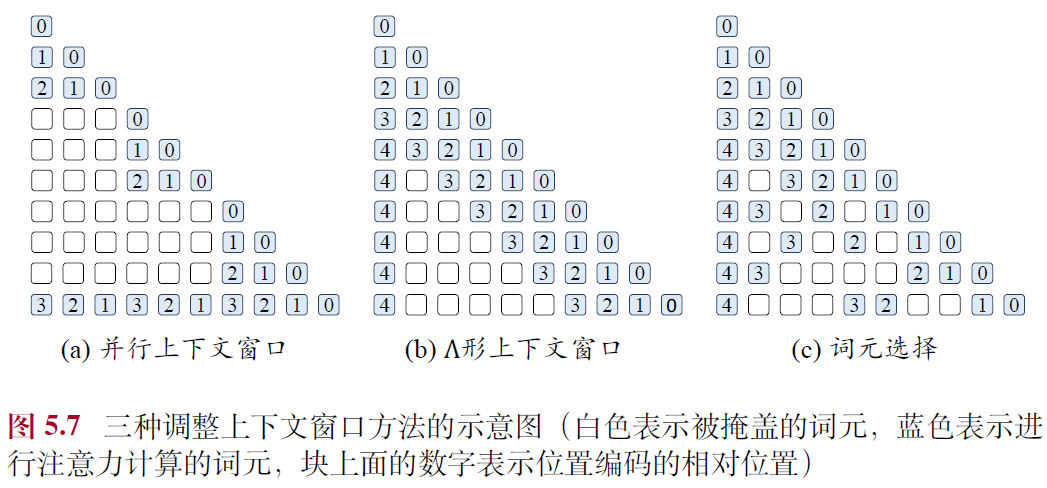
- 并行上下文窗口
- 将输入文本划分为若干个片段,每个片段都进行独立的编码处理,并共享相同的位置编码信息
- 生成阶段,通过调整注意力掩码,使得后续生成的词元能够访问到前序的所有词元
- 缺点:无法有效地区分不同段落之间的顺序关系,在某些特定任务上可能会限制模型的表现能力
- Λ 形上下文窗口
- 能够有选择性地关注每个查询的邻近词元以及序列起始的词元,同时忽略超出这一范围的其他词元
- 缺点:无法有效利用被忽略的词元信息,无法充分利用所有的上下文信息
- 词元选择
- **查询与词元相似度:**在某些层中使用最相关的外部存储的键值对,远距离使用
- **查询与分块相似度:**选最相似的分块计算注意力,更加灵活
5.4.3 长文本数据
- 长文本数据量:需要预训练阶段已学会利用远程词元信息能力,1B执行数百步,即可扩展至100K以上
- 长文本数据混合:领域分布尽量和预训练一致,去除杂乱型,保留整体型和聚合型文本效果更好
5.5 新型模型架构
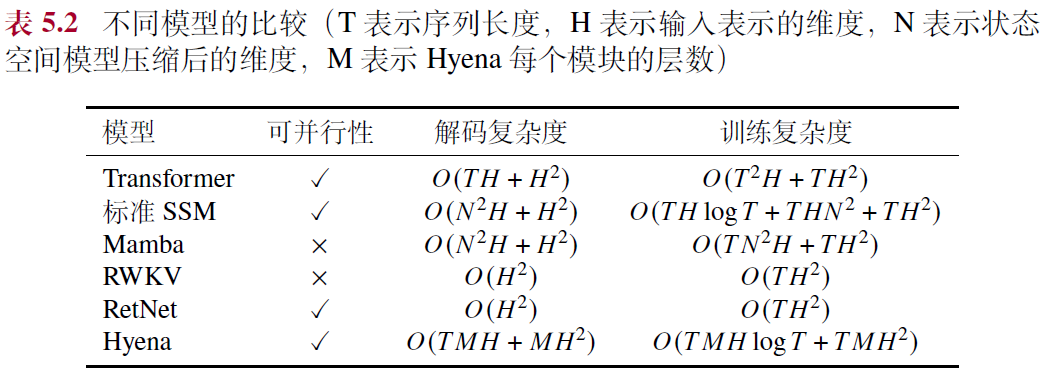
5.5.1 参数化状态空间模型(State Space Model, SSM)
- 优势 :循环神经网络和卷积神经网络的"结合体",有较高的计算效率
- 该模型可以利用卷积计算对输入进行并行化编码
- 该模型在计算中不需要访问前序的所有词元,仅仅利用前一个词元就可以自回归地进行预测
- 公式
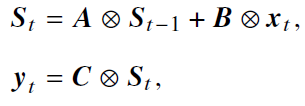
- A、B、C为可学习参数,可分解为以下,且抽象出卷积核K
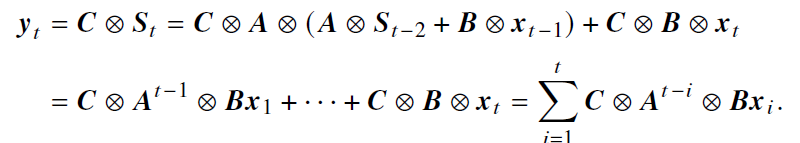
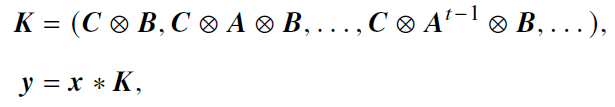
5.5.2 状态空间模型变种
- Mamba
- 改进:将(𝑨, 𝑩, 𝑪) 表示成输入𝒙𝑡 的非线性函数
- 优势:能够对状态和输入信息进行选择性过滤,有更好的文本建模性能
- 劣势:引入非线性关系,无法利用快速傅里叶变换实现高效卷积计算
- RWKV
- 改进
- 使用**词元偏移(Token Shift)**来代替词元表示,插值两个相邻的词元𝒙𝑡 和𝒙𝑡−1输入
- 时间混合模块:类似于门控的RNN 的网络,使用词元偏移对状态进行更新,代替多头注意力模块
- 频道混合模块:在前馈网络的基础上引入了词元偏移进行映射
- 优势:解码过程中可以像RNN一样只参考前一时刻的状态
- 劣势:在训练过程中缺乏并行计算的能力
- RetNet
- 改进
- **多尺度保留(Multi-scale Retention, MSR)**机制:保留q、k、v的机制,融合SSM,
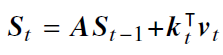
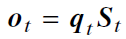 ,代替多头注意力模块
,代替多头注意力模块
- 优势:可以通过类似注意力操作的矩阵乘法,对所有词元的状态进行并行化计算,同时保留了循环计算和并行计算的优点
- Hyena
- 改进
- **长卷积模块(Long Convolution)**模块:使用M个滤波器组合成卷积核
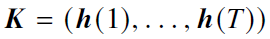 ,得到中间表示后用门控进行加权输出,替换注意力模块
,得到中间表示后用门控进行加权输出,替换注意力模块
- 训练可以加速,但是解码每次必须对前面所有的词元进行卷积