前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2023年文章合集发布了!在这里:又添十万字-CS的陋室2023年文章合集来袭
往期回顾
上周手上不太方便,即使后续好了也没有搞定(不过说实话,这篇文章的量似乎没读完也不好搞定)。
最近是有3篇prompt的综述非常出名:
-
The Prompt Report: A Systematic Survey of Prompting Techniques
-
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
-
A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
每篇综述的内容都比较丰富,尤其是第一篇,已经到了76页,然而从综述角度,需要把尽可能完善地把研究领域内的关键文章都给说明白,然而从应用角度或者学习角度,从中能找到适合自己的部分,快速过滤和筛选则更为重要,今天这篇文章,是综合上述3篇综述的内容以及个人在实际应用中的经验,从中抽取可靠的方案和思路总结。
此处描述的prompt限定在文本的、不经过模型参数更新的prompt系列方案,涉及多模态方面的,暂时不展开。本文的核心行文主要依照上述第一篇的思路来进行,中间会补充另外两篇的内容。
目录:
-
prompt的概念和组成成分
-
类目和场景的划分
-
比较推荐的Prompt方案
prompt的概念和组成成分
首先还是明确一下这里prompt的定义,用的是1的解释:
A prompt is an input to a Generative AI model, that is used to guide its output.
同样是在1中,也给出了prompt常见的组成成分,这里非常建议大家在写prompt的时候按照这4个要素来设计,内容表示的越清楚,最终效果就会越好。
-
指令,即核心目标,如"请判断这句话是积极还是消极"。
-
示例,给出一些案例供参考和比对,如"请参考下面几个案例"。
-
输出格式,对最终输出的结果要求,例如分点、json格式之类的。
-
角色。已经有大量实验证明,给大模型赋予角色,能很大程度提升大模型的输出结果。
-
附加信息。其他需要配合任务进行输出的结果,如要做翻译,那就得提供原文,或者是RAG需要提供reference等。
类目和场景的划分
prompt现阶段的方案已经有很多了,但在了解prompt下的具体方案之前,还是想先和大家讲一下,这些方案如何归类,具体的倾向性和使用场景是啥样的。
在2中,论文按照主要功能对prompt中的常用方案进行了划分,基本结构是这样的:
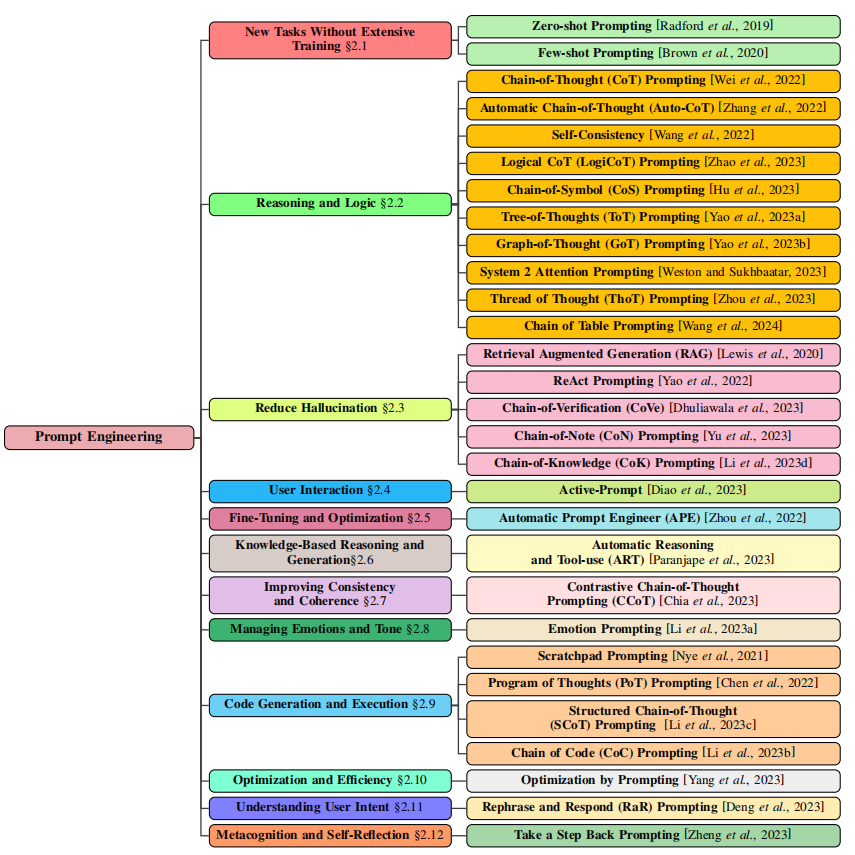
从这里可以看到,作者是按照核心功能来给各种promp方案进行方案的划分,可以看到在reasoning and logic上有积累大量的工作,类似大家比较熟悉的CoT就被划分在这里面,除此之外,降低幻觉、APE、代码生成、一致性、优化效率等问题也是大家所关注的焦点。
而在1这篇论文里,则把各种方案总结为了6个核心类别:
-
上下文学习(in-context learning)。通俗而言,举例子,换个角度,few shot之类的也属于这个范畴。
-
零样本学习。类似CoT、Role-Play(角色)、风格、情感的提示,都属于这个范畴。
-
思想生成。常见的就是CoT及其变体。
-
分解。把问题进行拆解然后逐步完成的思想,论文似乎都不太出名,不过日常工作挺经常用到的,核心难点在于如何拆解,论文里类似"Least-to-Most Prompting"之类的都有提及。
-
集成。这个严格来说不算分解的反义,这里指的是通过多次或者多种方式对统一方案进行验证来实现最终效果的可靠性,比较典型常用的就是self-consistancy,通过重复让大模型生成自己的答案来加强对最终结果的验证,配合CoT和非0的temperature即可实现多次的结果生成,而Prompt Paraphrasing则是通过改写prompt来确认最终效果,也是类似的思想。
-
自我批评。集成强调的是生成结果的多次,而自我批评则是强调对生成结果的验证,让大模型自己判断内容是否正确。Self-Calibration就是非常典型的,在原有生成的基础上,把问题+回复重新输入大模型让大模型来判断是否正确。
这6个类型虽不互斥,但基本就是我们常见的比较直接调优prompt的核心思路,在面对大模型的bad case想要通过prompt来优化时,非常建议通过这个思路来考虑调优。
这里补充说一下3,这篇论文是NLP任务项,在第二章内讲解了39种Prompt的方法,倒是没有进行归类式的讨论,基本都是摘要级的描述,大家有兴趣还是可以展开找到对应论文来阅读,这个挺耗费时间不过还是会有些价值。
Prompt方案
论文里提供的方法很多,也比较杂,这里提供几个比较常用或者好用的方案,大家可以在日常尝试。
in-context learning
来看看1中给的定义:
ICL refers to the ability of GenAIs to learn skills and tasks by providing them with exemplars and or relevant instructions within the prompt, without the need for weight updates/retraining.
这里强调的是exemplars和relevant instructions。前者,简单地说,就是在prompt提供例子,供模型参考,这点其实和人也比较类似,很多事情说不明白的时候,给例子能大幅度降低描述成本,告诉模型"你就照着做就好了",而在实践过程中,通常要注意这几个方面:
-
示例的个数。由于长文本等原因,个数并非多多益善,合适的个数对模型的接受程度有提升,多了反而不合适,可以筛选(例如用相似度来晒,之前的文章有提到:心法利器114 | 通用大模型文本分类实践(含代码)),也可以直接就开始训练吧。
-
示例的排序。实验表明,示例的排序对最终结果是有影响的,合理的排序有利于最终效果的提升。
-
标签的分布。即示例内每个标签的个数,某个类目的标签过多也会导致模型的误判。
-
标签的质量。即标注准确性,这个无论在哪都挺重要的,但大模型下似乎有一定容忍度,不想一般的模型训练那么敏感。
-
示例的格式。因为一般会给多条,示例需要一定的标准格式,这个格式会约束模型最终输出的正确性和规范性。
-
示例的相似度。一般而言,例子给得越贴切,模型预测会越准。
除了例子外,relevant instructions也是有用的,在例子可能并不好举,或者用文字描述可能更清楚的时候,这时候直接用描述会更方便,当然这个的收益很大程度以来模型自己本身的能力,尤其是指令的遵循能力,此时可以考虑的角度,参考如下:
-
角色。制定对应任务的角色,会让模型带入,能提升效果,甚至加一些夸奖的褒义词,如"优秀的",也会有收益。
-
情感提示。加一些类似"这对我的职业生涯很重要"的情感提示,会有效果收益。前段时间的类似"给你10美元"的梗,也是实践中多少有些效的。
-
类System 2 Attention方法。先让大模型重写自己写好的prompt,删除、补充特定的内容,然后再请求大模型处理得到新的内容。这里的处理可以是删除多余、误导、错误内容(System 2 Attention),可以是调整得到的事实内容(SimToM),也可以是对prompt进行重新调整(Rephrase and Respond)之类的,包括Re-reading这种灵活的重写prompt。
Chain-of-Thought(CoT)
CoT相信大家都比较熟悉了,思维链是一种引导大模型自己思考然后生成的方法,通过引导大模型逐步思考,能让模型解决更复杂的问题的能力,同时对于简单问题的回复也会更稳定。我理解其核心机理是,大模型提供的思考过程能让最终解码时要考虑的全局最优信息更加稳定可靠。
最简单的方案就是直接加一句指令"让我们一步一步来思考这个问题",当然在此技术上,可以结合问题的内容,提供诸如"从XX角度逐步思考"、"请按照XX步骤思考"来进行强化,类似的方案在基础能力比较强(逻辑推理能力)的模型里,都会有比较大的收益。
这种方案的优点就是修改成本会比较低,但缺点是大模型最终生成答案内容会比较长,伴随的问题就是解析难度变高、耗时变长等。
解析分解
我自己的理解,解析分解是一种CoT的升级思路,把一个任务分解为多个任务,逐步完成,一方面能更好控制整个过程,另一方面准确率会有提升。这是主要的思想吧,而在实际操作中,拆解的方式可能会有所不同,这里从论文中抽几个作为例子,供大家实际情况选择和判断。
-
Least-to-Most Prompting:考虑分步,依次解决每个问题,然后最终推导出最终结果。
-
Decomposed Prompting:用few-shot配合大模型决策调用什么函数来解决特定问题,函数对应的是解决特定问题的方案,这个看起来在agent领域已经被广泛使用,当然了这个也跟搜索对话里的意图识别+特定意图的处理有异曲同工之妙。
-
Plan-and-Solve Prompting:让模型自己设计计划,然后按照这个计划自己执行。
这里可以看到,在任务拆解后,请求大模型的次数会变多,次数的增加对耗时的压力无疑是巨大的,在实际应用中,这个需要被纳入考虑,另外还需要注意两个点:
-
拆解后的每一步,最好都能监控到其效果,避免出现显著明显短板从而影响最终效果。
-
拆解后的部分步骤都可以仔细评估,反思是否每个步骤都刚需大模型,类似Decomposed Prompting中的决策,在数据比较多的场景,可能小模型或者规则也能做好这种决策,此时可以有效提升效率而降低成本。
集成
集成的思想在原来深度学习、机器学习的早期就已经有考虑到,其核心思想就是构造多个类似的结果然后合并,类似Self-Consistency通过CoT产生多个结果然后综合评估, Demonstration Ensembling通过多种few-shot结果来判断,Mixture of Reasoning Experts是用MoE多专家系统提供不同的推理思路。
Self-Criticism
自我批评旨在利用大模型回溯,验证自己生成的结果是否正确,最简单的方式就是直接把问题+大模型答案通过prompt拼接让模型进行结果验证(Self-Calibration),更进一步则有Self-Refine进一步提供修改建议或者完成修改。
prompt并非局限在自己的编辑,研究上还会有很多细分的场景和思路。
其他prompt的研究方向和思路
Prompt工程
Prompt工程根据1中的定义,是指在Prompt工程是"automatically optimize prompts",即自动优化prompt。
-
Meta Prompting是通过大模型直接生成一个比较基础的baseline,同时能通过数据反复调优这个prompt,内部人工的干预会大幅减少。
-
AutoPrompt利用已有样本,通过推理反馈自动化逐步调优原有的prompt。
-
Automatic Prompt Engineer利用一组样本生成zero-shot的prompt,从而选择最优的结果。
-
Prompt Optimization with Textual Gradients看起来是前面的升级版,会通过Self-Criticism的手段进一步调优最终的效果。
prompt工程强调的是自动化调优,实践上能很大程度给调出一个不错的结果,但是从实践经验上看,上限可能并不会很高,在自动化调优过程中,如果数据集弄得不好,会出现prompt可能会被往错误的方向带偏的错误,因此在使用过程中注意监控prompt后续修改后的结果。
答案工程
答案工程旨在解决我们在实践的过程中经常会遇到的一个问题------答案内容不符合我们预期的格式,一般地会有两种方案,通过prompt进行约束,另一种是进行答案的后处理,无论是何种方式,基本不会逃离下面几个关键要素:
-
答案形式,文字图片还是视频,文字的字数和格式限制,或者是用json、xml格式来处理。
-
答案空间,类似分类问题,是在给定空间内进行有限的选择。
-
答案提取器,例如json结构,我们需要借助正则之类的方式来识别大括号来划定json的范围进行转化。
这方面在1内,除了在答案工程里提到,另外在大模型的output format里面也提到了类似的东西,此处我把他们放一起说了。
Agent
Agent相信很多人都有了解甚至在做这个方向,prompt无疑在这个方向也有很大的发挥空间。
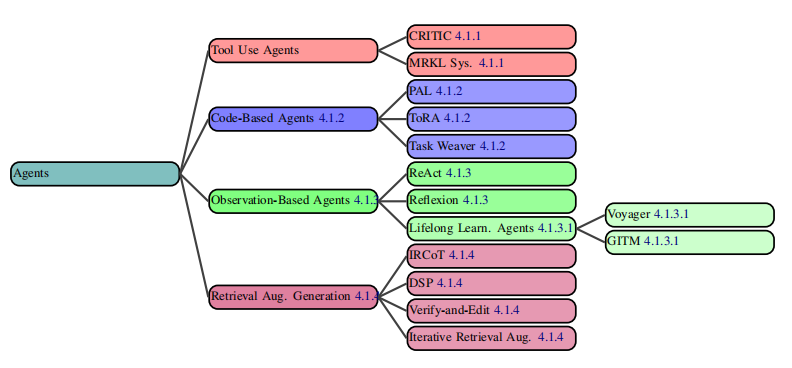
这里作者把tool use(function call)、基于代码的生成、Observation-Based(有点像RL)、RAG之类的方法放里面,这块的总结说实话相比专门做对应领域的,例如我所比较熟悉的RAG,前段时间在这块我已经写了很多文章了(心法利器111 | 近期RAG技术总结和串讲(4w字RAG文章纪念)),prompt内讲的还是比较粗的,此处就不展开了,大家可以结合自己的需要去阅读自己的综述,这里就是抛砖引玉了。
prompt的评估
综述文总避不开对研究对象的评估方法,文章中讲了很多,但全文看下来基本把常见的NLP指标都覆盖了进去,从综述的角度确实是有必要的,但从实践角度,我个人认为还是应该从任务本身的目标出发,看具体要做的是什么任务,分类、评分、实体抽取、回复生成还是什么方面,然后结合实际情况设计合适的指标才是正解,做研究要求相对规范,但是实践是肯定要因地制宜的。
安全和对齐问题
这里的安全是指需要应对设计恶意prompt来诱导生成式AI产生错误或者有害信息的安全问题。常见的是通过诱导来注入或者诱导输出有害信息,造成信息的泄露或者破坏系统的可靠性和完整性,常见的防御手段是对prompt内容进行质检校验,使用对抗性策略增强模型的鲁棒性,同时定期进行安全性评估和监控,及时发现和应对提示攻击。
至于对齐,此处考虑的是人和大模型之间理解的对齐,我们很容易会想到RLHF之类的手段来优化,而在1中,作者把对齐问题拆解成了prompt敏感性、过度自信的矫正、偏见刻板和文化差异、歧义这几个问题,论文中给出了一些解决方案,当然这里也提到了一些上面说到的方法,例如few-shot等。
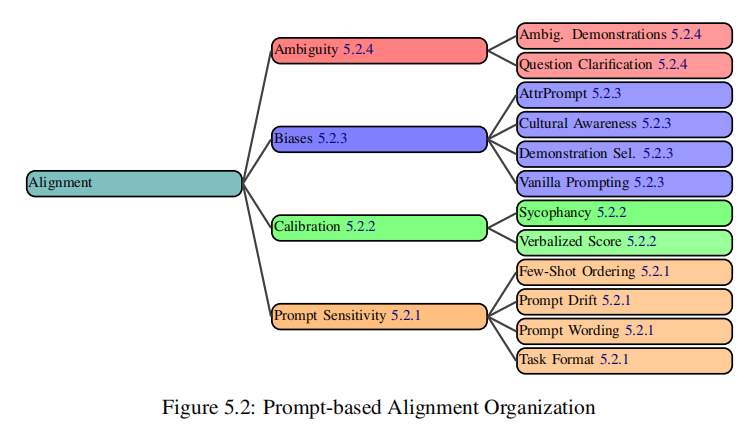
一些选型的建议
prompt上的技巧还是很多的,这里列举几个可能比较有用而且性价比还不错的角度,供大家选择和使用。
首先是从prompt的组成成分而言,尽量把各个组分给准备清楚,即前面章节提到的指令、示例、格式、角色、附加信息,在尽可能完整的情况下,一般会有还可以的效果。尤其要关注附加信息,对特定任务,合理、完整、严谨描述是最终效果的必要保证。
in-context learning,简单的说就是例子,在例子的辅助下,大模型的生成能更加符合我们的预期,无论是格式上还是结果的准确率上。
CoT,我是指最简单的CoT,复杂的CoT变体对任务的特异型还是比较高的,但是基础的CoT其实已经一定程度能为大模型提供支持,但因为大模型自己还要做思维链推理,所以耗时的提升还是会很明显的。
Self-Criticism对最终效果的提升还是有的,而且还挺明显,但问题是需要再用一次大模型,本身自我批评的prompt还得写,稍微有些麻烦,但在最终效果上收益还挺大的。
分解稍微有些推荐吧,对复杂的任务,无论是横向的多个相同然后集成,还是纵向的把任务分步做,都会有一定收益,但是着实增加大模型请求次数了。
对于一些性能压力比较大的情况,CoT、Self-Criticism、分解、集成之类的思路其实也能做,可以用来做一个比较高的baseline,然后对大模型进行进一步微调,调成更简单的模式,也是一个思路,相当于预标注+微调的蒸馏模式了。
小结
说实话,prompt工程这块的诸多论文和结论,本质都挺实验科学地,通过不断的实验来得出效果的好坏结论,本期是文章是结合论文的阅读和自己的经验总结的文章,有需要的同学还是很推荐大家看完的。
参考文献
首先是本文重点关注的3篇论文。
1 The Prompt Report: A Systematic Survey of Prompting Techniques
2 A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
3 A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
