绪论
"少年没有乌托邦 心向远方自明朗",本章是应用层常用且重要的协议htttp,没看过应用层建议一定先看那一篇后再看本章才能更好的去从上到下的理解应用层。
话不多说安全带系好,发车啦(建议电脑观看)。

1.Http协议
Http:协议超文本传送协议(Hypertext Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。
2.1URL:

在WWW上(在网络中),每一信息资源都有统一的且在网上的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是WWW的统一资源定位标志(每一个网页会有一个确定的网址,通过网址就能进入),就是指网络地址(俗称网址)。
具体内容(看标注):

其中URL包括了:
- ip + port(上网本质就是进行进程间通信)
- 上网行为:获取的资源(网页、图片、视频、音频等资源本质也都是文件->存在Linux中)、上传的数据(也就是IO)
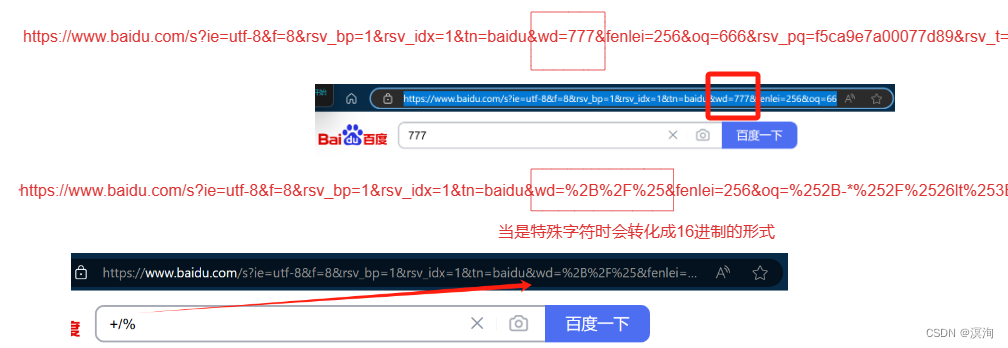
其中还有参数是通过urlencode和urldecode来实现:
对特殊的字符进行处理,像/*?这样的字符在URL中是有特殊意义的,所以就会把用户输进行转译避免冲突,将其转换成16进制的形式来代替将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
2.2http格式
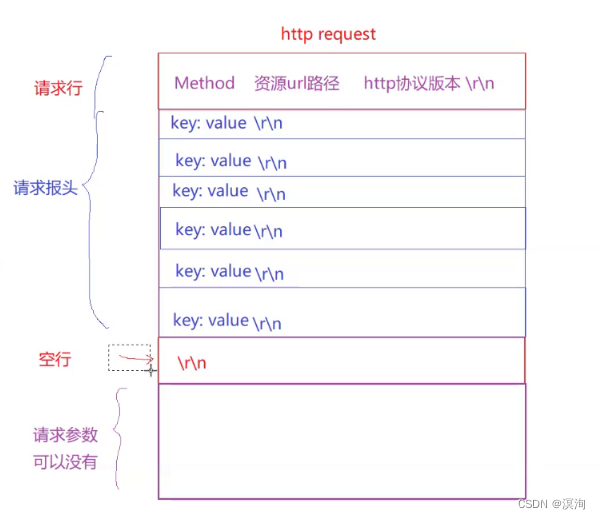
在http中分为请求协议和应答协议:
- http请求协议:
格式为:
如:
其中格式的元素的意义:
-
请求行如(首行:方法 + url + 版本):

- Method方法:Http的方法:
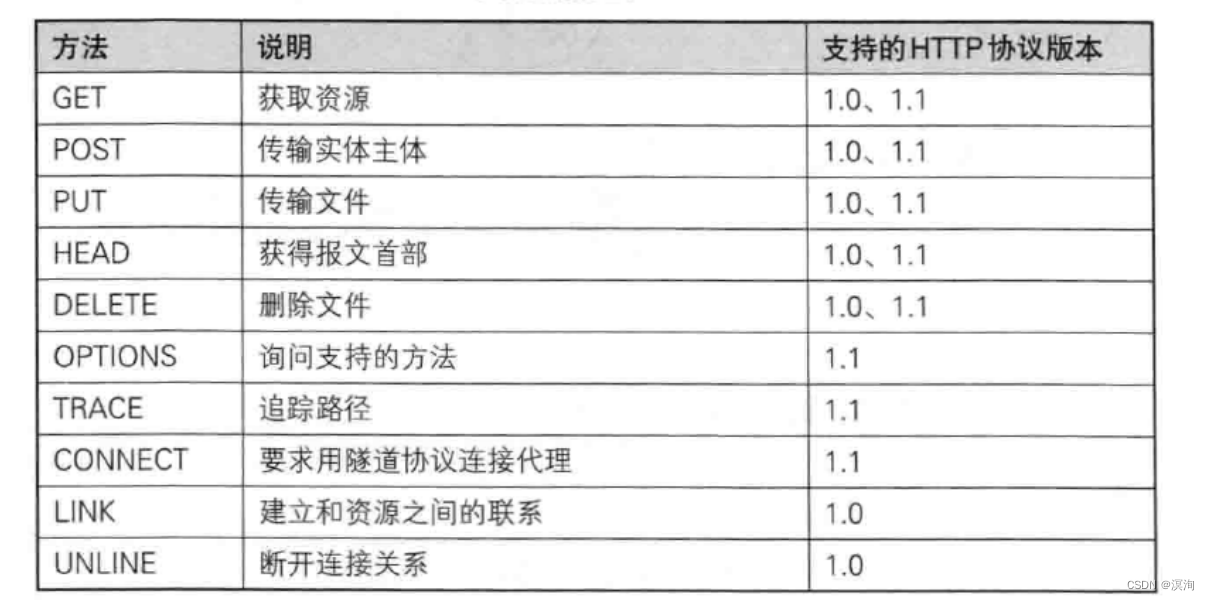
最长用的方法:- GET:通常用来获取资源,也可以用来传递参数
- POST:上传数据
- 资源url路径:
- 网页、图片资源的路径(默认访问web根目录(/),也表示根目录放着该网站的首页)
- http协议版本
- http/1.0(适合学习,短连接(仅进行一次的请求与回复))
- http/1.1(主流,长连接)
- http/2.0
- Method方法:Http的方法:
-
Header(也就是上图的请求报文中很多的 K:V 部分)请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔,遇到空行表示Header部分结束

HTTP常见Header(咱们通过实际的协议后面理解记忆即可):
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
- Content-Length: Body的长度
- Content-Type: 数据类型(text/html等)
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
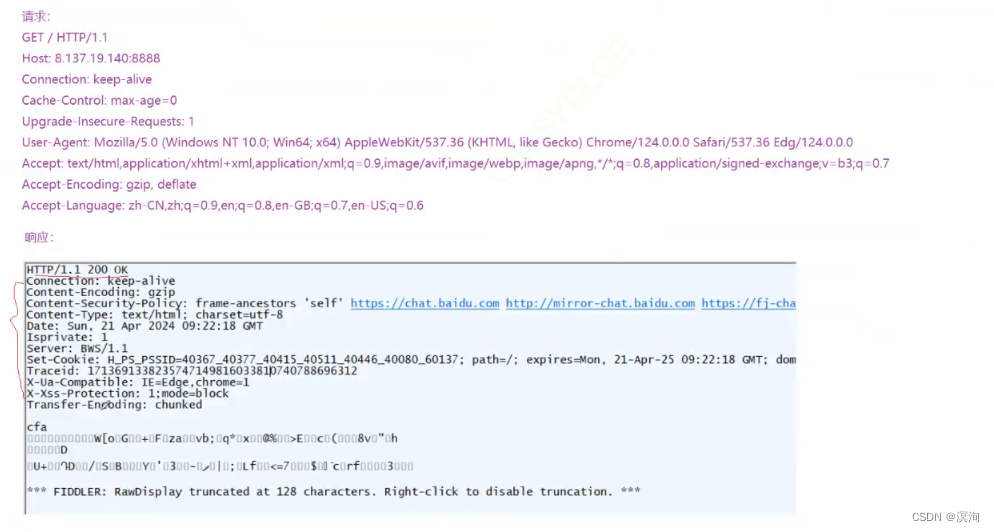
http的报头中的关键字段
Content-Type: 数据类型(text/html等)
-
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个==Content-Length(上图是36byte)==属性来标识Body消息体(即实体数据)的长度

http协议需要处理的问题:
- 报头和有效载荷如何分离
- 空行区分 (格式的红色标记处)
- 有效载荷如何交付
- 通过缓冲区和对应的函数
- http如何读到完整报文
- 一直读取,直到读到空行
- 其中空行(红色\r\n)是用来区分报头和有效载荷的
- 请求报头中会有存着 K:V = Content-Length : XXX,表示着正文(有效载荷)的长度
- http如何进行反序列化
- 直接根据\r\n进行区分出报头和数据然后反序列化即可
-
http响应协议:
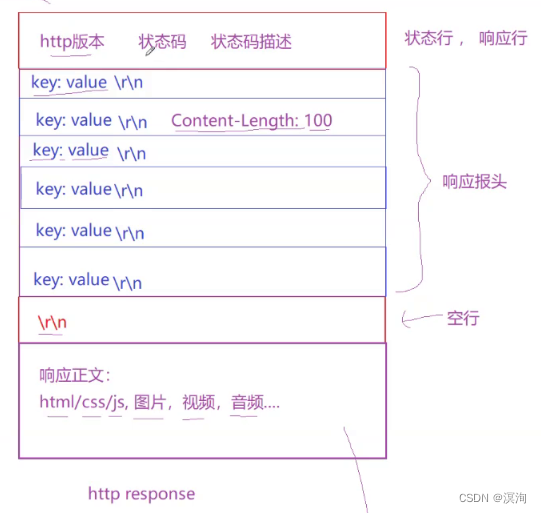
-
http协议版本(上方已经描述了就省略了)
-
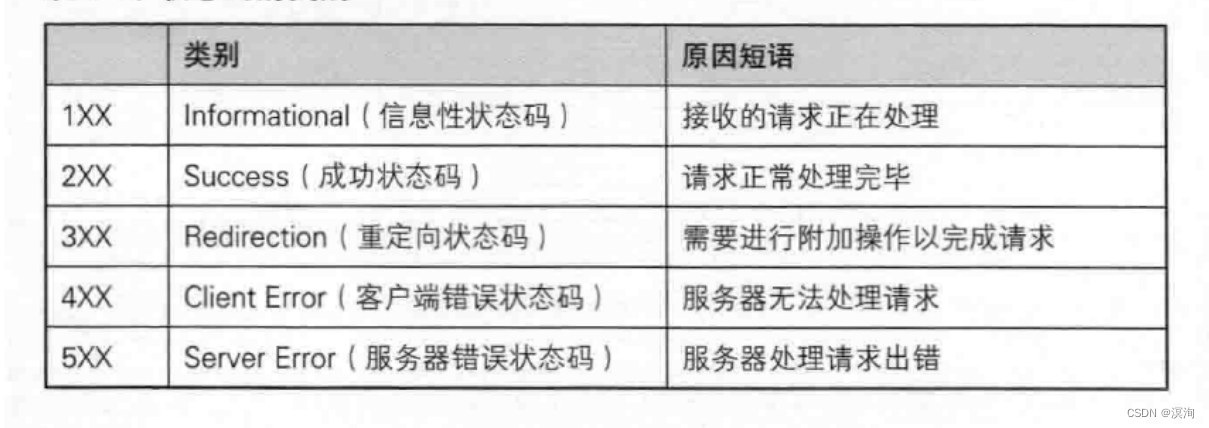
状态码:

如常见的:
200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
-
状态码描述:ok
-
现在有了请求协议和应答协议
对于用户端和服务端就有:
当用户发送请求后,服务器就会响应回来(如下图)
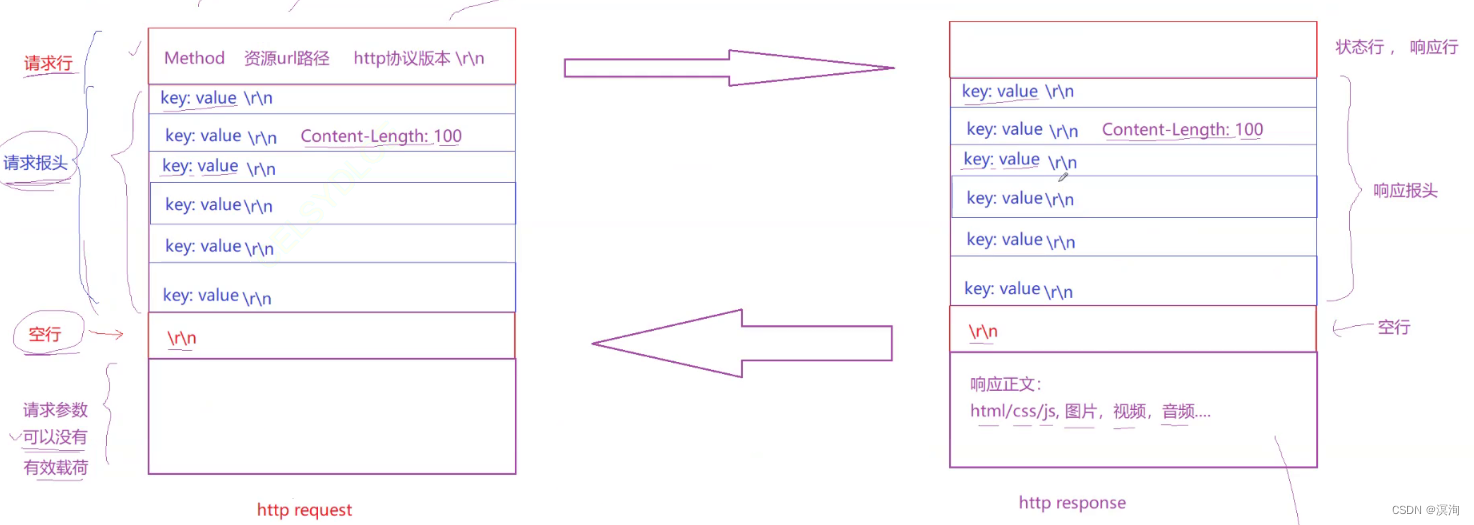
其中两边协议都是有http协议版本的:
客户端中表示的是:浏览器支持的http版本(用户一般是使用浏览器来发送请求报文)、服务端中表示的是:server支持的http版本
- 灰度上线:版本更新先给一定用户,确定软件稳定好用后再推广给更多用户更新使用,所以版本不同就有不同的功能。
- telnet:远程登录服务命令
如果网页中包含了图片,那么该图片也需要再发送请求
因为HTTP协议是基于请求-响应模型的,即客户端(如浏览器)向服务器发送请求,服务器处理请求后返回响应。在网页中,每张图片都是通过HTML中的标签引入的,而浏览器在解析到这个标签时,会识别出图片资源的URL,并针对该URL发送一个新的HTTP GET请求到服务器,以获取图片数据。
你要请求的所有的资源都有后缀,后缀决定了文件的类型,在http response 给浏览器响应的时候,正文部分是什么类型,是通过文件后缀和Content-Type的映射表来判定!
所以总结:http超文本传输协议,可以支持很多内容的发送,根据请求资源的后缀,判定Content-Type是什么
用户如何请求方法(实现上网行为):
- 用户获取资源,发送请求报文,接收服务端返回的应答资源
- 向服务器进行传参,要把的数据上传到服务器(登录,注册,搜索等等),下面使用GET/POST再结合 HTML表单来实现一个登录界面底层
GET方法:
下图的HTML代码是用到了HTML表单不会可看看w3wschool的HTML对表单的使用教学
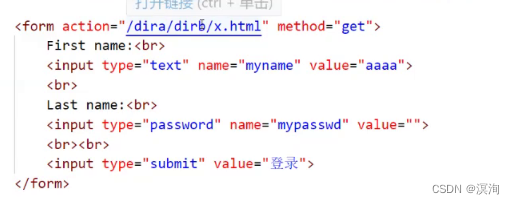
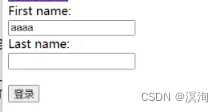
当在输入框中输入后:helloworld、123456789
url将会变成:

其中包含了
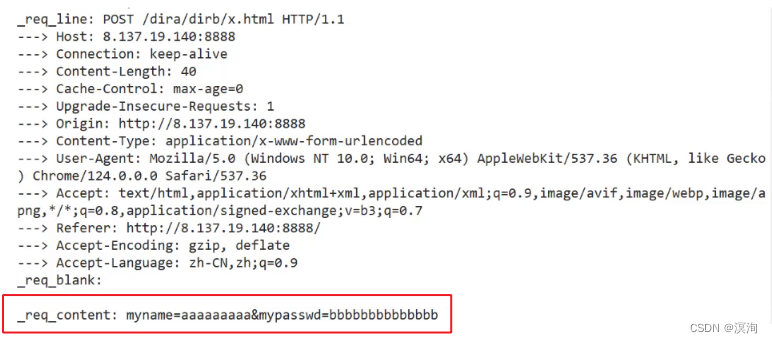
- 所打开的目录(之前表单中设置的action):"/dira/dirb/x.html"
- 输入的参数(对应的名称和输入的参数):myname = helloworld、...
所以GET可以通过form表单提交参数,参数提交的方式,是通过url提参的,其实输入的数据是给了浏览器
当不起指定写的时候:默认是GET方法
POST方法:
如果我们用POST方法传递参数,是通过请求正文进行参数传递

GET方法 vs POST方法
总结:
GET方法将参数拼接在url中、POST方法将参数写在正文,是在有效载荷中。
所以:
1. url传参:字节个数有限制(有些浏览器会限制url长度),POST方法:参数长度没有限制。
2. GET 私密性更差一些(直接就是在url上),POST方法能好一些(GET和POST方法都不安全,POST也能被抓包)
Http的状态码(响应码)补充:
-
当状态码是307(temporary Redirect 临时重定向):重定向可以用来进行页面的跳转。
客户端会在服务器发来的报头中找到location报头信息(一般是一个网址)然后通过这个网址就能重定向跳转到location存的网页

-
301 永久性重定向,搜索引擎 -- 获取网页(url、关键字:无数个网络链接进行对应)
如果一个网站过期了(之前的域名、url等改变了),当返回301 Location它就会-更新一下老的链接
2.3cookie和session
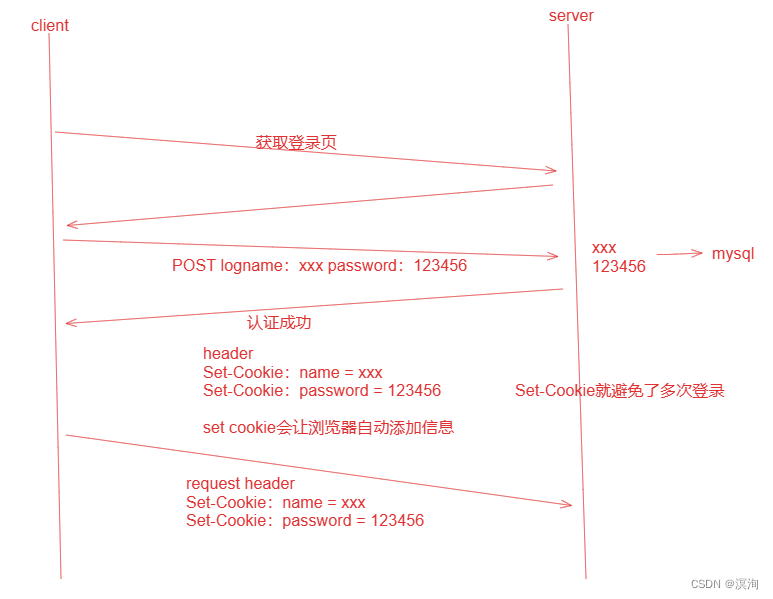
Http是无连接、无状态(http不会记录历史发送过的请求)的。
但不难发现http虽然是无状态的但,对于许多网站在登录后就会一直认识我,因为要根据身份区分我的权限(会员/非会员),这就是通过cookie技术实现的!
cookie:分为文件级(较长时间有效)、内存级(短时间有效) ,cookie方法又称会话管理。
浏览器保存数据Set Cookie,这样在后面用的时候就无需再次输入相关信息(具体如下图),浏览器就会自动的去帮你发送请求登录上你的账号(如下图set-cookie会自动添加你之前使用的信息)
像微软的Edge浏览器它就会存cookie信息
当我们把Cookie信息删除后就无法自动登录了就得重新登录:
可能存在的问题:
当别人拿着你的cookie文件岂不是就能直接用你身份去登录某些网站了。
解决方法:
通过sessionid(仅仅只是个标记)来代替cookie信息(存的就是用户的账号和密码),通过sessionid去服务端找到对应的cookie认证,也就是将cookie信息存在服务端。

这样我们就能再通过管理session来防止被别人盗用账号
session:可以通过用户的时间(一段时间后cookie失效)、地址(ip地址突然跳转到外地)来判断是否需要更新cookie认证是否是本人
所以说服务器上就会有大量session、session在服务器上就需要被管理
本章完。预知后事如何,暂听下回分解。
如果有任何问题欢迎讨论哈!
如果觉得这篇文章对你有所帮助的话点点赞吧!
持续更新大量计算机网络细致内容,早关注不迷路。