今天想和大家分享一下我最近在arXiv.org上看到苹果发表的一篇技术论文 Apple Intelligence Foundation Language Models (https://arxiv.org/abs/2407.21075),概述了他们的模型训练。这虽然出乎意料,但绝对是一个积极的惊喜!

这篇论文有那么多作者参与,就知道这模型不简单。研究团队在这篇论文里给我们展示了两个超厉害的模型,它们是专门为苹果设备上的智能环境设计的。咱们就叫它们AFM,也就是"苹果基础模型"的简称。
具体来说,他们介绍了两个版本的AFM。一个是有30亿参数的,打算用在手机、平板或者笔记本上;另一个是服务器版的,更强大,但具体细节还没透露。
这些模型不光是用来聊天的,还能帮我们解决数学问题和编程难题。虽然论文里没细说编程训练的细节,但已经够让人期待了。
另外,AFM是密集型大型语言模型(LLM),不使用专家混合方法。
AFM预训练
首先,他们不仅用了公开的数据和得到授权的数据,还特别尊重了网站上的robots.txt文件,没去爬那些不让爬的数据,这就很讲究。再来,他们还提到了对基准数据做了净化处理,这可真是太用心了。
而且,他们还强调了一个关键点:数据的质量比数量要重要得多。你看,他们的设备模型词汇量是49k个token,服务器模型是100k个token,虽然都比Qwen 2的150k个token要少,但这说明他们更注重数据的精而不是多。
最有意思的是,他们的预训练过程不是简单的两步走,而是有三步呢!
-
先是核心的常规预训练。
-
然后是继续预训练,这时候他们把那些网络爬取的、质量不太高的数据权重降低了,而把数学和代码相关的数据权重提高了。
-
最后,他们还用了更长的序列数据和合成数据来扩展模型的上下文理解能力。

AFM模型经历的三步预训练过程概述。
让我们更详细地看看这三个步骤。
预训练I:核心预训练
这一步就是苹果预训练流程的起点,跟我们平时说的常规预训练差不多。他们的AFM服务器模型训练用了6.3万亿个token,批量大小和序列长度都是4096个token,这和Qwen 2模型的7万亿个token训练量挺接近的。
但是,AFM设备模型的来头可不小,它是从一个更大的6.4亿参数模型里面蒸馏和修剪出来的。这个过程有点像是用一个超级学霸(教师模型)来辅导一个普通学生(设备模型),让它变得更聪明。具体来说,就是用了一个叫做"蒸馏损失"的东西,把目标标签换成了真实标签和教师模型预测的最高概率标签的混合体,其中教师标签占90%的权重。
知识蒸馏现在在大型语言模型预训练中越来越流行了,Gemma-2也在用这个技术。以后我会详细介绍这个,现在咱们先简单说说。就是说,学生模型不仅学习原始数据集,还学习教师模型的输出,这样就能从教师那里得到更多的信息,比单打独斗学得多。
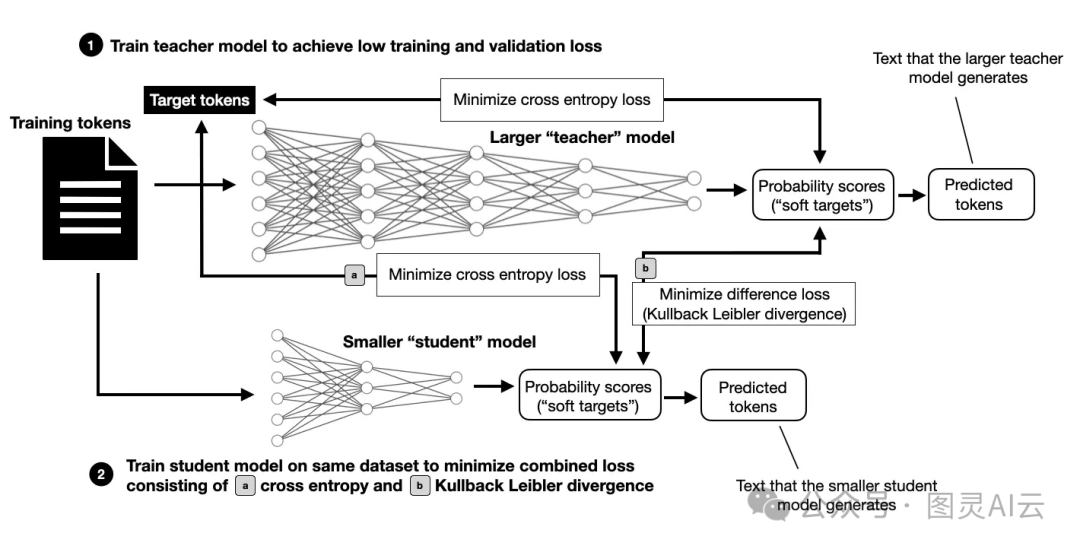
知识蒸馏的概述,其中一个小模型(这里,AFM设备3B模型)在原始训练token上以及来自一个更大的教师模型(这里,一个6.4B模型)的输出上进行训练。请注意,a)中的交叉熵损失是用于预训练LLMs的常规训练损失。
不过,这种方法也有缺点。首先,你得先训练出一个大的教师模型;然后,还得用这个大模型来预测所有训练数据的结果。这些预测可以提前算好存起来,但这需要很多存储空间;或者也可以在训练过程中实时计算,但这可能会让训练速度变慢。
预训练II:继续预训练
这个阶段有点小变化,就是把处理的数据量从4096个token增加到了8192个token,这就像是让模型能看得更远,理解更长的句子和段落。虽然这个数据集的token数量只有1万亿,但是比起核心预训练的数据量来说,那可是五倍的缩减,这就像是从海量信息中提炼出精华。
关键是,这一步特别强调用高质量的数据来训练,尤其是数学和编程相关的内容,这可真是下了功夫,要让模型在这些领域里更上一层楼。
不过,这里有个挺有意思的发现,就是之前提到的那个知识蒸馏方法,在这个阶段好像不太管用,研究人员发现它并没有带来什么好处。这可能说明,不同的训练阶段,可能需要不同的策略和方法。
预训练III:上下文扩展
咱们再来看看预训练的第三步,这个阶段虽然只涉及1000亿个token,跟第二步比起来,这数量只有10%,但这一步的重点在于扩大模型的视野,让它能处理更长的上下文,达到了32768个token。这就好比是给模型装了个望远镜,让它能看得更远,理解更长、更复杂的信息。
为了做到这一点,研究人员可是下了一番功夫,他们用合成的长上下文问答数据来丰富训练集。这就像是给模型提供了更多的练习题,让它通过解决这些问题来提高自己的能力。
这种做法不仅能让模型在处理长文本时更加得心应手,还能帮助它更好地理解和生成连贯、逻辑性强的长段落内容。这对于提升模型在各种复杂任务中的表现,比如写文章、编故事或者进行长篇对话等,都是非常有帮助的。
总的来说,这三个预训练步骤,每一步都有它的独特之处和重点,共同为打造一个强大、灵活、多才多艺的模型打下了坚实的基础。
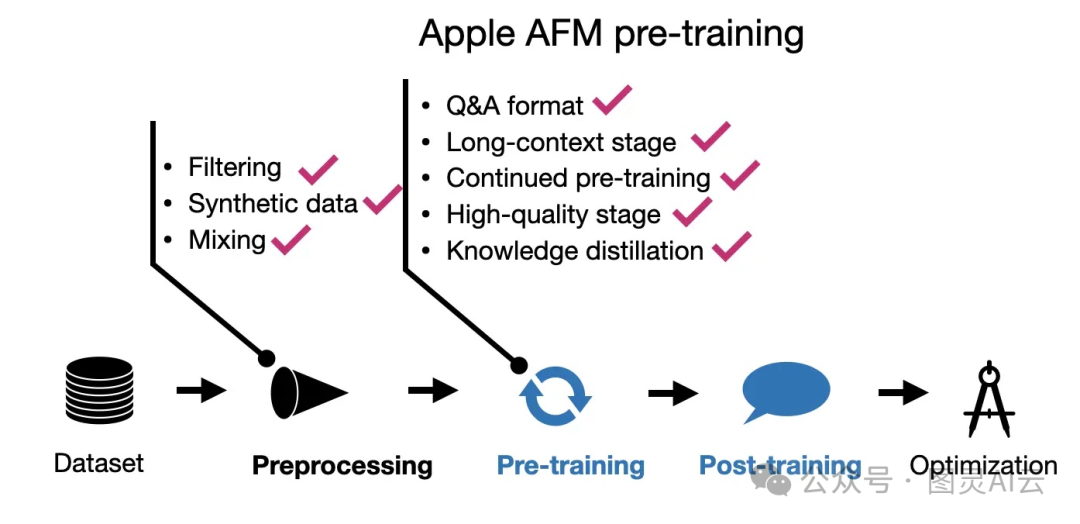
AFM预训练技术总结。
AFM后训练:精益求精
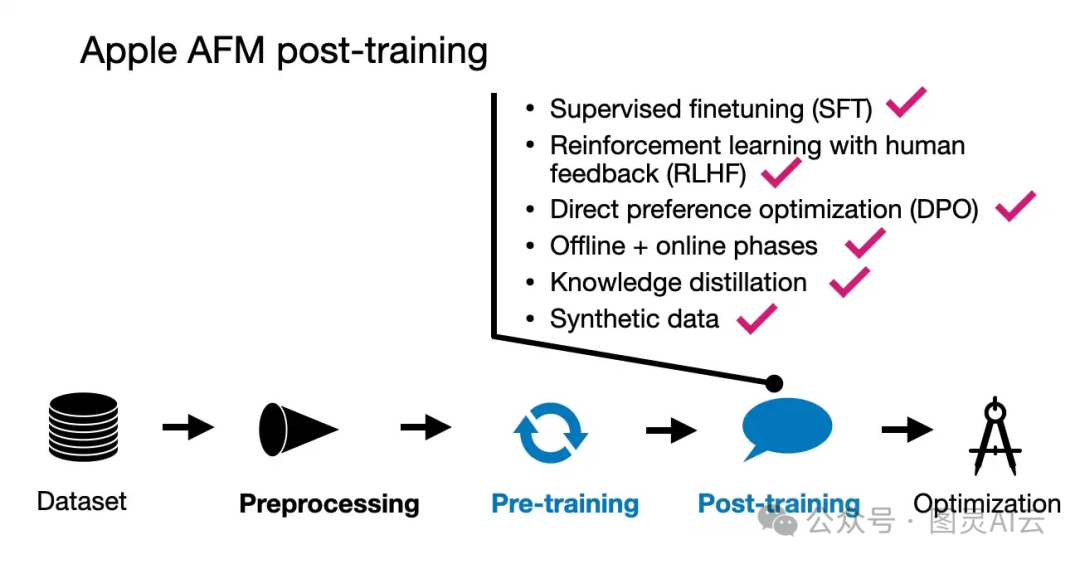
苹果在模型的后训练阶段也是下了一番苦功,他们的方法和预训练一样全面。他们用了人工标注的数据和合成数据,而且特别强调质量比数量重要。这就像是在说,我们不追求数据的堆砌,而是要数据的精挑细选。他们没有固定死板地按照某个比例来混合数据,而是通过多次实验来调整,找到那个最佳的平衡点。
后训练分为两个主要步骤:首先是监督指令的微调,然后是多轮的人类反馈强化学习(RLHF)。
这里特别值得一提的是,苹果在这个RLHF阶段引入了两个新算法:
-
带有教师委员会的拒绝采样微调(iTeC):这个算法就像是有个智囊团,它结合了拒绝采样和多种偏好调整技术,比如SFT、DPO、IPO和在线RL。苹果没有只依赖一种算法,而是每种方法都单独训练模型,然后让这些模型产生响应,由人类来评估和打标签。这些标签数据再用来迭代训练奖励模型。在拒绝采样阶段,模型委员会会给出多个响应,然后奖励模型挑出最好的那个。
-
带有镜像下降策略优化的RLHF:这个算法被选中是因为它比常用的PPO(近端策略优化)更有效。
这种基于委员会的方法虽然复杂,但对于相对较小的模型(大约30亿参数)来说是可行的。如果是更大的模型,比如Llama 3.1中的70B或405B参数模型,那挑战性就大了。
总的来说,苹果在后训练阶段的这些操作,都是为了进一步提升模型的性能,让模型在实际应用中能表现得更加出色。
结论
苹果在预训练和后训练上的策略相对全面的,这可能是因为他们面临的风险确实很大------毕竟,这些模型是要部署在数以百万计,甚至数十亿的设备上的。不过,也正是因为这些模型的规模相对较小(3B模型的规模还不到最小的Llama 3.1模型的一半),他们才能够尝试这么多的技术手段。
他们的一大亮点是,并没有简单地在RLHF和DPO之间做选择,而是通过委员会的形式,综合使用了多种偏好调整算法。
另外,他们还明确地将问答数据纳入了预训练的一部分,这一点我在之前的文章《指令预训练LLMs》中也有讨论过。
总的来说,这份技术报告给人带来了清新的感觉,也让人对苹果的模型训练方法充满了期待。
