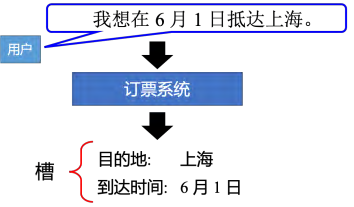
循环神经网络(Recurrent Neural Network, RNN) 是一种经典的深度学习网络结构,具有广泛的应用。其中,槽填充(Slot Filling)(即识别自然语言中的特定信息) 是其中一个应用场景,例如订票系统需要识别用户的出发地、到达时间和航班等信息。为了实现这一功能,可以使用前馈神经网络(feedforward neural network)将每个单词转换成向量 ,并通过训练模型来预测每个单词所属的槽。具体来说,我们可以使用词嵌入技术将单词映射到低维空间中的向量表示,然后将其输入到前馈神经网络中进行处理。例如,对于句子"I want to book a flight from Beijing to New York on June 1st",我们可以将"Beijing"、"New York"和"June 1st"分别映射到对应的向量表示,然后输入到前馈神经网络中进行处理,最终得出用户想要预订从北京到纽约的机票,日期为6月1日的结果。

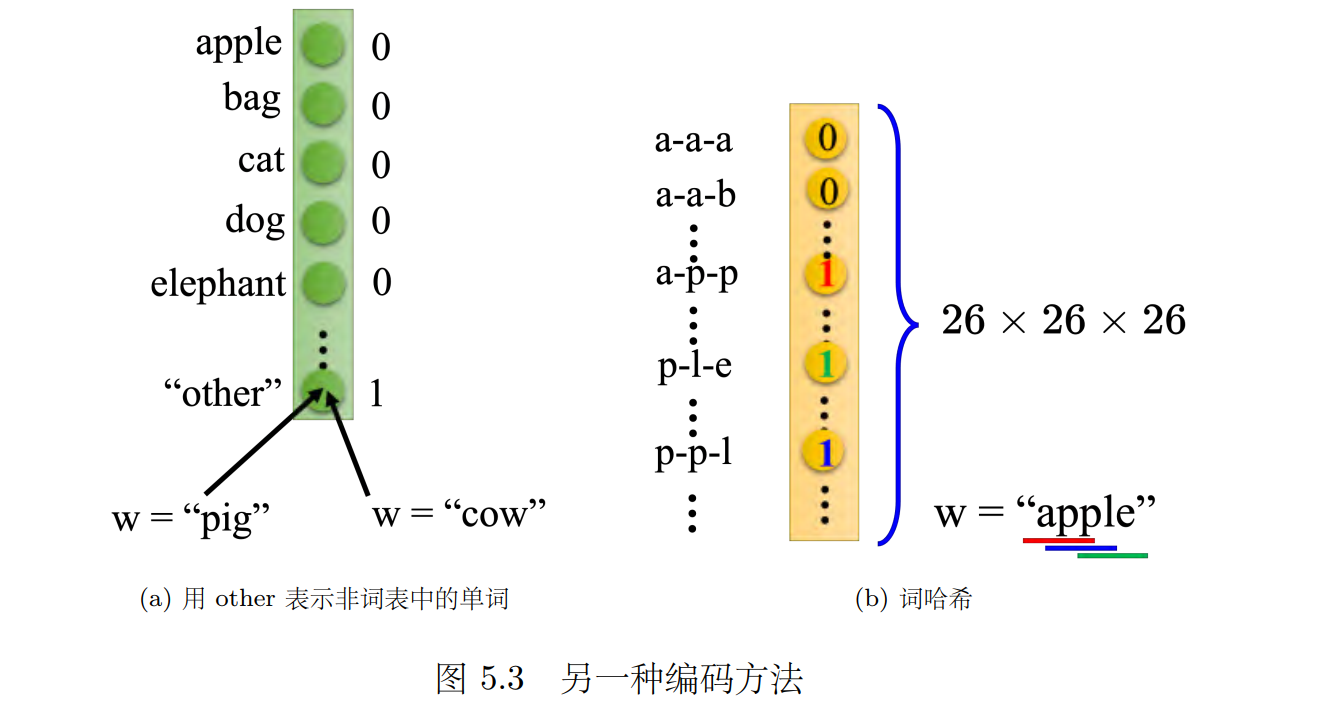
5.1 独热编码
独热编码是一种常见的表示方式,但它需要为每个单词添加额外的维度 ,以便处理未知单词。另外一种方法是词哈希图 ,它可以将单词转换成向量,并将其用于前馈神经网络中。
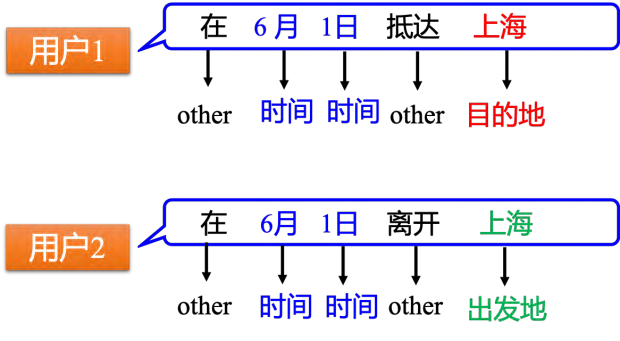
然而,这种方法也存在一些问题,例如无法处理上下文信息。比如:假设用户 1 说:"在 6 月 1 号抵达上海"。用户 2 说:"在 6 月 1 号离开上海",这时候"上海"就变成了出发地。但是对于神经网络,输入一样的东西,输出就应该是一样的东西。在例子中,输入"上海",输出要么让目的地概率最高,要么让出发地概率最高。不能一会让出发地的概率最高,一会让目的地概率最高。在这种情况下,如果神经网络有记忆力的,它记得它看过"抵达",在看到"上海"之前;或者它记得它已经看过"离开",在看到"上海"之前。通过记忆力,它可以根据上下文产生不同的输出。如果让神经网络是有记忆力,其就可以解决输入不同的单词,输出不同的问题。
5.2 什么是 RNN?
在 RNN 里面,每一次隐藏层的神经元产生输出的时候,该输出会被存到记忆元(memory cell) 。当下一次有输入时,这些神经元不仅会考虑输入,还会考虑之前存入的记忆元中的值。因此,循环神经网络可以考虑到序列的顺序,即使输入相同,输出也可能不同。
记忆元,即单元或隐状态。记忆元的作用是在循环神经网络中保存信息,以便于后续的计算。记忆元的值也可以称为隐状态,因为它代表了神经网络在某一时刻的状态。在循环神经网络中,隐状态的计算是循环的,也就是说,每一时刻的隐状态都依赖于前一时刻的隐状态。
记忆元可简称为单元(cell),记忆元的值也可称为**隐状态(hidden state)。 **
一个可能的示例(就只是简单的加法,但是考虑了之前的输出)
5.3 RNN 架构
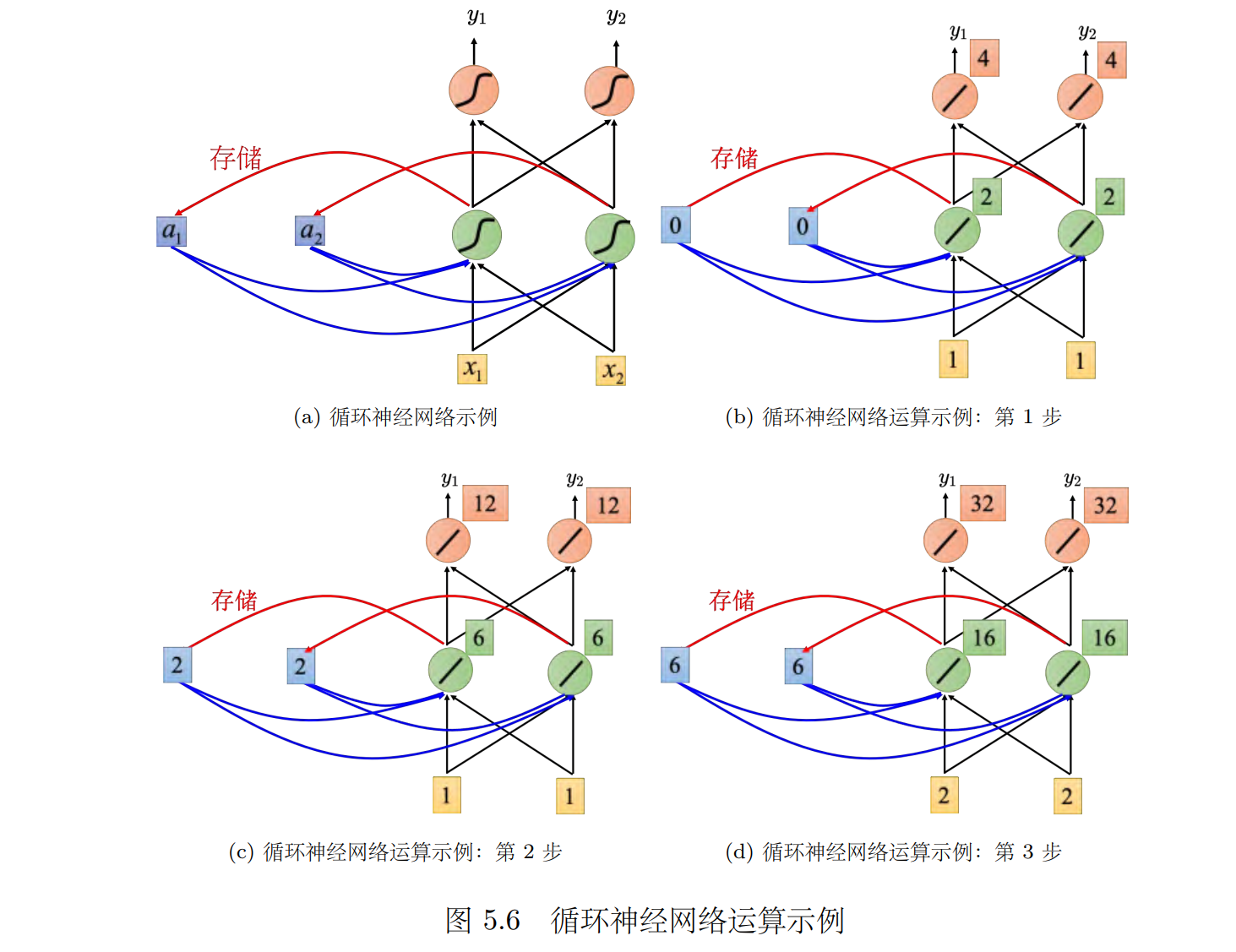
使用循环神经网络处理槽填充这件事,如图 5.7 所示。用户说:"我想在 6 月 1 日抵达上海","抵达"就变成了一个向量"丢"到神经网络里面去,神经网络的隐藏层的输出为向量 _a _1, _a _1产生"抵达"属于每一个槽填充的概率 _y _1。接下来 _a _1 会被存到记忆元里面去,"上海"会变为输入,这个隐藏层会同时考虑"上海"这个输入和存在记忆元里面的 _a _1,得到 _a _2。根据 _a 2 得到 y _2, _y_2 是属于每一个槽填充的概率。
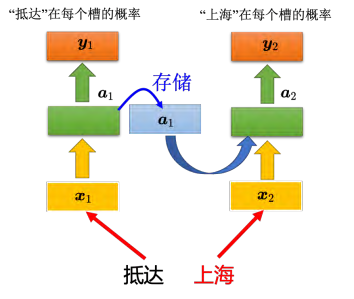
这个不是三个网络,这是同一个网络在三个不同的时间点被使用了三次,用同样的权重用同样的颜色表示
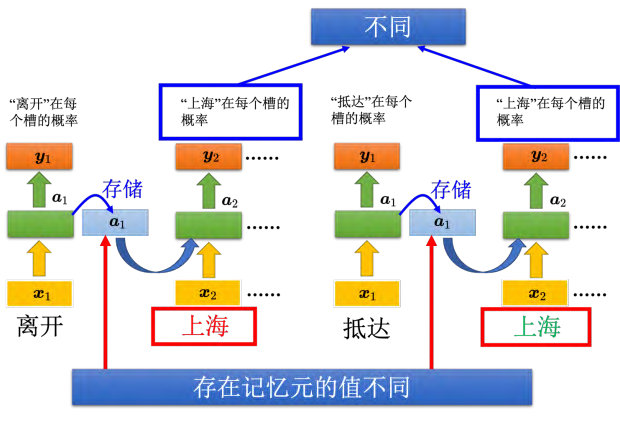
有了记忆元以后,输入同一个单词,希望输出不同的问题就有可能被解决。如图 5.8 所示,同样是输入"上海"这个单词,但是因为红色"上海"前接了"离开",绿色"上海"前接了"抵达","离开"和"抵达"的向量不一样,隐藏层的输出会不同,所以存在记忆元里面的值会不同。虽然 _x _2的值是一样的,因为存在记忆元里面的值不同,所以隐藏层的输出会不同,所以最后的输出也就会不一样
5.4 其他 RNN
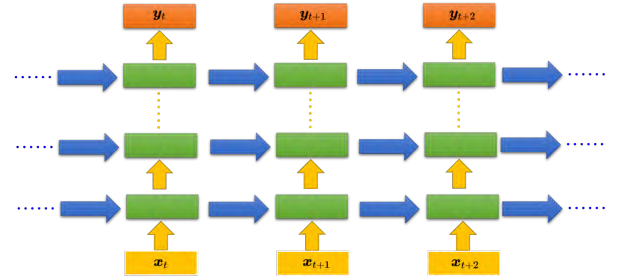
RNN 也可以是深层的。比如把 _x t _丢进去之后,它可以通过一个隐藏层,再通过第二个隐藏层,以此类推 (通过很多的隐藏层) 才得到最后的输出。
相比于只有一个隐藏层的设计,深层循环神经网络可以经过多个隐藏层处理输入数据,从而获得更加准确的输出结果。每个隐藏层的输出会被存储在记忆元中,在下一个时间点读取并传递给下一层,如此反复直至最终输出。这种设计可以有效地提高模型的表现力和预测精度,适用于许多自然语言处理和语音识别等任务。
5.4.1 Elman 网络 &Jordan 网络
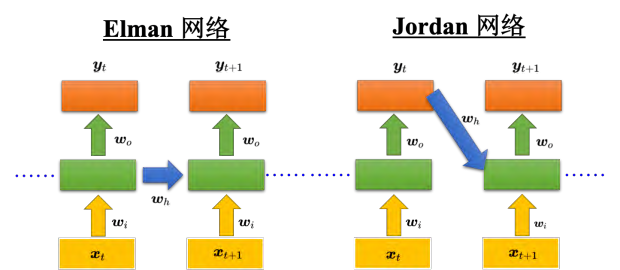
刚才讲的是简单循环网络(Simple Recurrent Network, SRN)(简单循环网络也称为 Elman 网络。) ,即把隐藏层的值存起来,在下一个时间点在读出来。还有另外一种叫做 Jordan 网络 , Jordan 网络存的是整个网络输出的值,它把输出值 在下一个时间点在读进来,把输出存到记忆元里。 Elman 网络没有目标,很难控制说它能学到什么隐藏层信息(学到什么放到记忆元里),但是 Jordan 网络是有目标,比较很清楚记忆元存储的东西。
5.4.2 双向循环神经网络
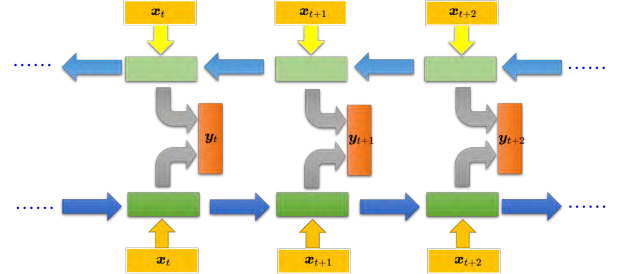
传统的循环神经网络只能从左往右或从右往左读取输入序列,而双向循环神经网络则能够同时考虑输入序列的前后两个方向的信息 。具体来说,双向循环神经网络包括一个正向 的循环神经网络和一个逆向 的循环神经网络,它们分别从左往右和从右往左读取输入序列,并将各自的隐藏状态传递给一个输出层来产生最终的输出结果。相比于单向循环神经网络,双向循环神经网络具有更广泛的视野,因为它不仅可以看到输入序列的前面部分,还能看到后面的部分,从而更好地捕捉上下文信息。这种能力使得双向循环神经网络在自然语言处理等任务中表现出了更好的性能。例如,在槽填充任务中,双向循环神经网络能够看到整个句子,从而更好地确定每个单词的槽位,获得更好的效果。
5.4.3 长短期记忆网络
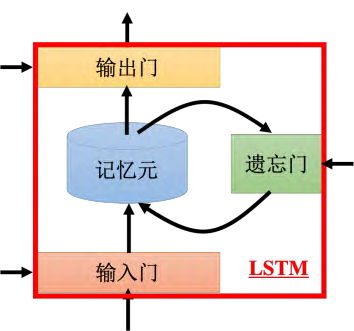
长短期记忆网络(LSTM)的工作原理:相比于普通的循环神经网络,LSTM能够更好地处理长期依赖关系,因为它具有三个门:输入门、输出门和遗忘门。这些门能够控制信息的流入和流出,从而使得LSTM能够有效地存储和检索信息。
具体来说,输入门控制着新信息的加入,输出门则决定了何时将信息传递给下一个状态,而遗忘门则负责清除不必要的信息。这三个门的开闭是由网络自身学习得到的,而不是由人工设定的规则。 这种自适应的学习方式使得LSTM能够更好地适应不同的任务和数据集。
为了实现这些功能,LSTM引入了一个称为"记忆元"的概念。记忆元是一个包含当前状态信息的向量,它可以被更新并用于后续的计算。 每个门都与记忆元有关联,它们的作用是在不同的情况下选择性地修改或保留记忆元中的信息。
注意是:long short-term memory (LSTM),不是long-short term memory
"-"应该在 short-term 中间,是长时间的短期记忆。之前的循环神经网络,它的记忆元在每一个时间点都会被洗掉,只要有新的输入进来,每一个时间点都会把记忆元洗掉,所以的短期是非常短的,但如果是长时间的短期记忆元,它记得会比较久一点,只要遗忘门不要决定要忘记,它的值就会被存起来。
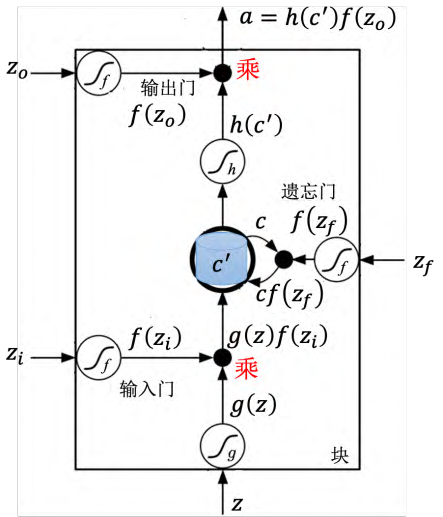
记忆元对应的计算公式为_c′ _= g (z )_f _(zi ) + _cf _(zf )
当新的输入 z 与控制输入门的信号 zi 组合时,会产生一个新的内部状态 c' = g(z) * f(zi) + c * f(zf),其中 g(z) 是激活函数,f(zi) 控制输入门的开关程度,zf 控制遗忘门的开关程度。如果输入 f(zi) 等于,则相当于没有输入;如果 f(zf) 等于,则会清空内部状态 c。最后,通过 h(c') 和控制输出门的信号 zo,可以产生输出 a = h(c') * f(zo)。输出门的开关程度由 zo 控制,如果 zo 等于,则可以读取内部状态 c;否则无法读取。
如果不理解,还是看栗子吧!😚
5.4.4 LSTM 举例
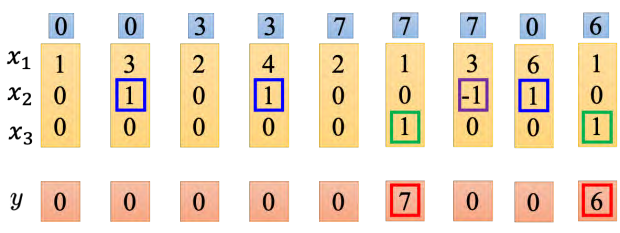
网络里面只有一个 LSTM 的单元,输入都是三维的向量,输出都是一维的输出。这三维的向量跟输出还有记忆元的关系是这样的。假设 x2 的值是 1 时, x1 的值就会被写到记忆元里;假设 x2 的值是-1 时,就会重置这个记忆元;假设 x3 的值为 1 时,才会把输出打开,才能看到输出,看到记忆元的数字(记住!!!)
假设原来存到记忆元里面的值是 0,当第二个维度 x2 的值是 1 时, 3 会被存到记忆元里面去。第四个维度的 x2 等于,所以 4 会被存到记忆元里面去,所以会得到 7。第六个维度的x3 等于 1,这时候 7 会被输出。第七个维度的 x2 的值为-1,记忆元里面的值会被洗掉变为 0。第八个维度的 x2 的值为 1,所以把 6 存进去,因为 x3 的值为 1,所以把 6 输出。
下篇链接:在这里啦