预训练(Pretraining)是一个非常消耗资源的工作,尤其在 LLM 时代。随着LLama2的开源,越来越多人都开始尝试在这个强大的英文基座模型上进行中文增强。但,我们如何才能保证模型在既学到「中文知识」的情况下,又不丢掉原有的「英文知识」
写在前面
预训练(Pretraining)是一个非常消耗资源的工作,尤其在 LLM 时代。随着LLama2的开源,越来越多人都开始尝试在这个强大的英文基座模型上进行中文增强。但,我们如何才能保证模型在既学到「中文知识」的情况下,又不丢掉原有的「英文知识」呢?
今天给大家带来一篇 Continue Pretraining 的论文(来自何枝大佬,知乎@何枝),Continual Pre-Training of Large Language Models: How to (re)warm your model?
知乎:https://zhuanlan.zhihu.com/p/654463331paper:https://arxiv.org/pdf/2308.04014.pdf1.实验设定
作者使用一个 410M 大小的模型 Pythia,已经在 Pile数据上进行过预训练,然后在下游数据集 SlimPajama 上进行微调。
论文中直接使用 Loss 作为评估指标,即 Loss 越小,说明在上游(或下游)任务中的效果越强。
Pythia: https://huggingface.co/EleutherAI/pythia-410m-v0
Pile: https://huggingface.co/datasets/EleutherAI/pile
SlimPajama: https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama2. 关键结论
2.1 warmup 的步数不会影响最终性能
warmup 是一种 finetune 中常用的策略,指学习率从一个很小的值慢慢上升到最大值。那么,这个「慢慢上升」的阶段持续多久是最好的呢?
作者分别使用训练步数的:0%, 0.5%, 1%, 2% 这 4 种不同预热步数来进行实验: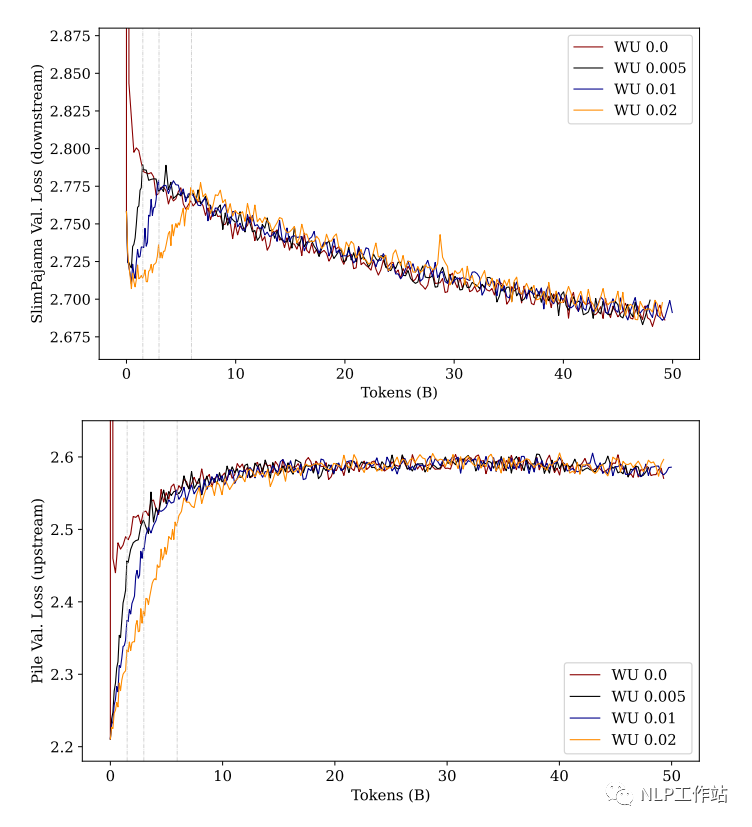
从上图中可以看到:当模型经过「充分」训练后,不管多长的预热步数最后的性能都差不多。
但,这种前提是「充分训练」,如果只看训练前期的话,使用更长的预热步数(黄色的线)。无论是「上游任务」还是「下游任务」,模型的 Loss 都要比其他预热步数要低(下游学的快,上游忘的慢)。
2.2 学习率越大,下游任务越好,上游任务越差
为了探究学习率对学习效果的影响,作者使用了 4 种不同的最大学习率进行对比实验,
此外,还比对了和从头训练(from scratch)模型的效果: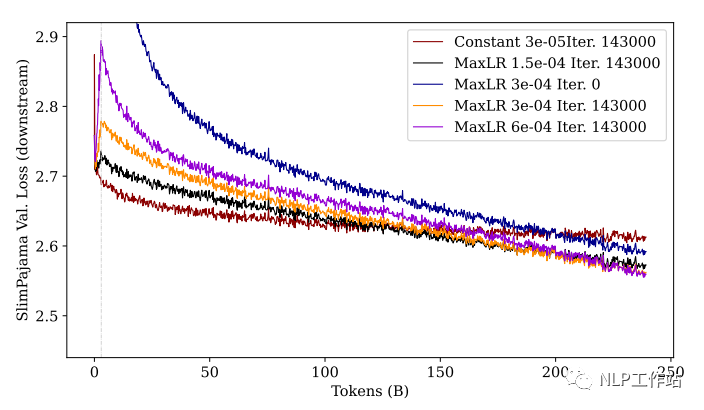
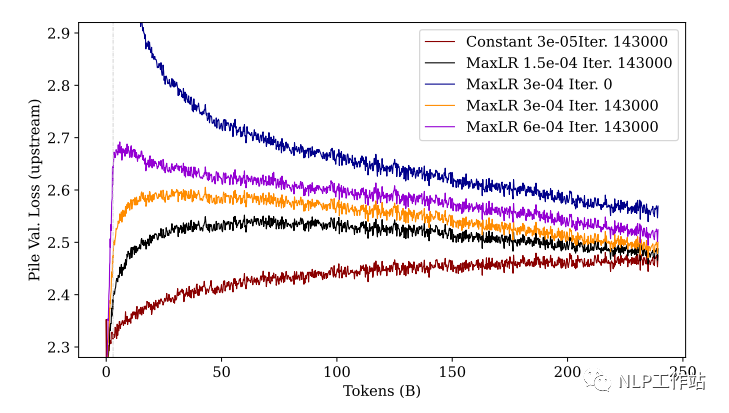
从图中可以看到:经过充分训练后,学习率越大(紫色),下游性能最好,上游性能最差(忘得最多)。同样,我们看前期训练,尽管紫色线条在最后的 loss 是最低的,但在前期 loss 会增加的非常大,随后下降。
PS:解释一下这里为什么这么关注训练前期,是因为在真实训练中,我们可能不一定会增强图中所示的 250B 这么多的 tokens,尤其是在模型参数很大的情况中。所以,当资源不允许充分训练的情况下,较小的学习率和较长的 warmup 步数可能是一个不错的选择。
此外,图中还能看出:未经过预训练的模型(蓝色)无论是上游任务还是下游任务,都不如预训练过的模型效果。
这鼓励我们今天在进行训练任务时,最好选择一个已经过预训练的模型上继续训练(以利用其中的先验知识)。
2.3 在初始预训练中使用 Rewarmup 会损伤性能
尽管 warmup 策略在 Finetune 和 Continue Pretraining 中都起到了更好的效果(相较于常量学习率),但是,这建立在「切换了训练数据集(数据分布)」的前提下。
作者做了一个实验,不切换数据集,而是继续在之前的「预训练数据集(The Pile)」上继续训练: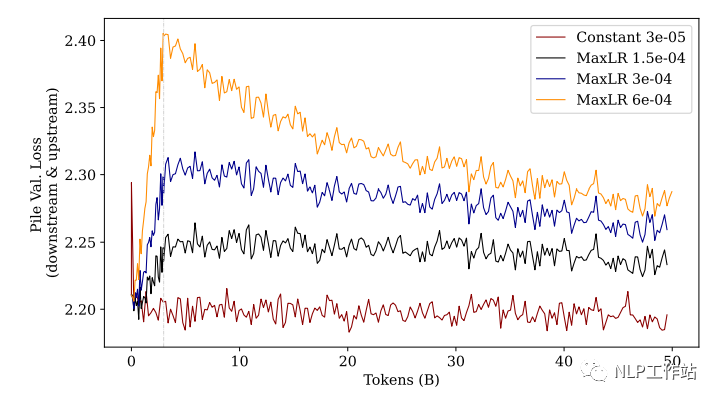
从图中结果可以发现:无论使用多大学习率的 warmup 策略,效果都不如使用常量学习率。
这进一步证明,在原数据集上使用 warmup 接着训练会造成性能损伤,学习率越大则损伤越大,且这种损伤是无法在后续的训练中被找回的。
PS:这里提示我们,当预训练中遇到了训练中断需要继续训练时,我们应该在重新开始训练时将学习率恢复到中断之前的状态(无论是数值还是衰减率)。
3. 实验限制
作者在论文的最后贴出了得出上述结论的一些局限性。
3.1 上下游数据分布类似
因为实验中选用的上游数据集 Pile 和下游数据集 SlimPajama 中存在一部分的数据重叠,
所以导致上下游数据的分布是比较相似的,但在我们真实的训练任务中,上下游数据的差异可能会比这大的多。
3.2 模型规模较小
论文中所使用的模型规模为 410M,这和今天人们 7B 起步的 LLM 规模相差甚远。
不过该团队打算在接下来的工作中继续在 3B 和 7B 的规模下进行尝试,期待他们最后的实验结论。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。