点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
点击阅读原文观看作者直播讲解回放!
作者简介
孙洲浩,哈尔滨工业大学SCIR实验室博士生
概述
尽管大语言模型(LLMs)展现出了非常强大的能力,但它们仍然面临与各种偏见相关的挑战。传统的自动去偏见方法主要针对判别式模型,在应对生成式LLMs固有的复杂偏见方面存在困难。为了解决这些局限性,作者设计了因果指导的主动学习方法来自动自主地识别LLMs的偏见模式并减轻LLMs的偏见。具体来说,首先通过因果不变理论揭示了语义信息和偏见信息的本质区别,然后据此自动识别有偏数据并归纳可解释的偏见模式,最终利用这些识别出的有偏数据和偏见模式通过上下文学习的方法来减轻LLMs的偏见。实验结果表明,所提出的因果主动学习方法能够有效地识别有偏数据并归纳可解释的偏见模式,并利用有偏数据和偏见模式对LLMs进行去偏。
**论文地址:**https://www.arxiv.org/abs/2408.12942
**代码地址:**https://github.com/spirit-moon-fly/CAL
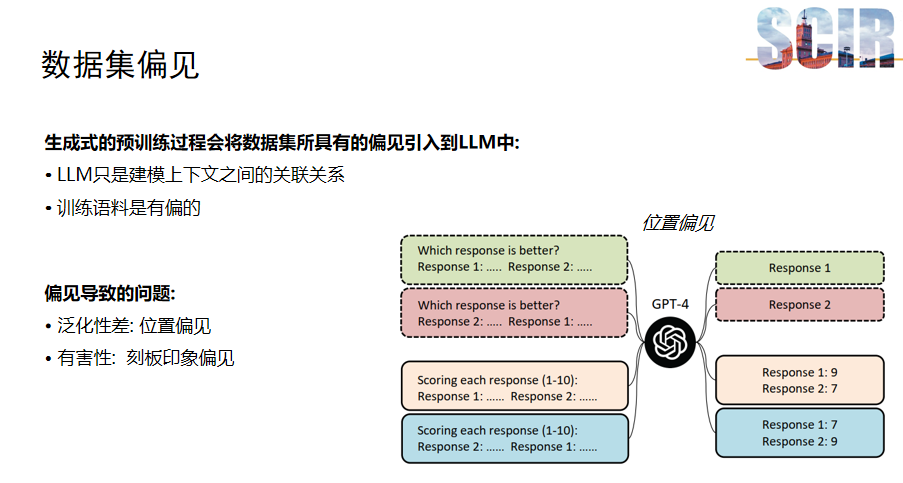
数据集偏见
生成式大模型近年来因其强大的能力而广受欢迎。然而,这些模型在预训练过程中可能会吸收数据集中的偏见。由于生成式大模型通过预测上下文中下一个词的概率来进行训练,因此大模型仅仅被动地捕捉上下文之间的关联性。如果训练数据存在偏见,这种关联性也会被模型所学习,从而导致模型泛化能力下降,并可能对社会造成负面影响。
例如,如果模型存在位置偏见,它可能会错误地认为问题中的第一个选项总是正确的,即使在某个数据集中正确答案通常位于第二个位置。这种偏见会影响模型的泛化能力。此外,刻板印象偏见,如性别或种族偏见,也可能通过模型的输出反映出来,对社会造成潜在的负面影响。
前人工作与动机
去偏化研究主要分为两大类方法:基于先验知识的去偏方法和自动去偏方法。基于先验知识的去偏方法依赖于人工识别数据集中的偏见,并通过上下文学习或对齐技术来消除这些偏见。然而,由于偏见的多样性,人工逐一识别大模型中所有的偏见类型是不切实际的。与此同时,前人的自动去偏方法通常为判别式模型设计,难以直接应用于生成式模型,这促使研究者寻求适合生成式大模型的自动去偏技术。

针对这一挑战,本文提出了一种因果指导的主动学习方法。通过引入因果不变性理论,这种方法可以利用大模型自身来自动识别有偏数据,并归纳出可解释的偏见模式。在因果不变性理论框架下,偏见与语义信息具有本质区别。问题的答案由文本的语义信息决定,这种关系在所有数据上都成立(因果),而偏见虽然可能与答案相关,但这种关系在不同数据集上不一定成立,因此它是一种相关关系而非因果关系。
此外,本文对主动学习的概念在去偏场景下进行了扩展。在传统主动学习中,首先选择最有信息量的样本,然后利用外部工具进行标注。而在去偏场景中,作者选择对归纳偏见模式最有帮助的有偏数据,然后利用大模型进行偏见模式的归纳,这种方法的关键在于识别那些能够显著改进模型对偏见理解与归纳的数据点。
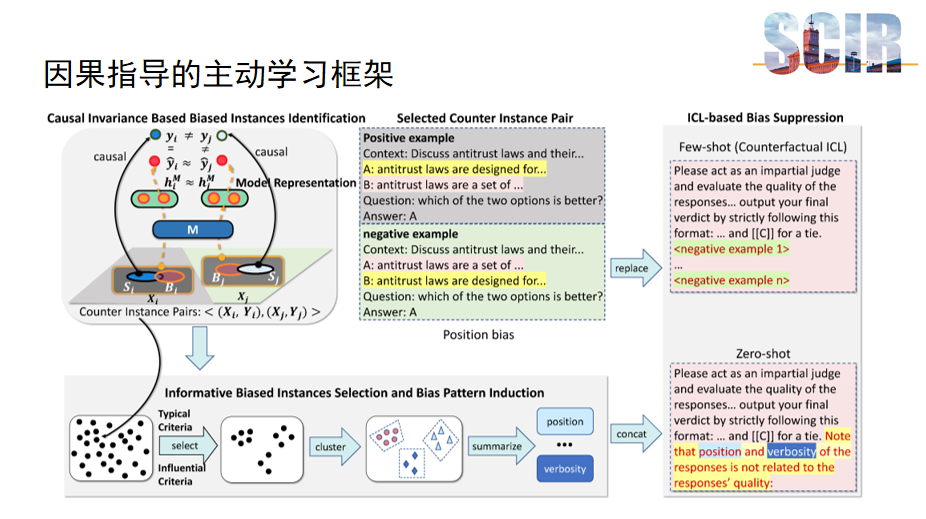
因果指导的主动学习框架
本文提出的主要框架旨在有效识别和抑制模型偏差,它由三个关键部分组成。首先,第一部分专注于基于因果不变性的有偏数据识别,这一步骤利用因果不变理论来区分数据中的偏见和语义信息,确保识别出的偏差实例具有代表性和准确性。其次,第二部分进一步分析这些偏差实例,通过识别出更具信息量的偏差实例,进行深入的偏差模式归纳,从而揭示数据中的潜在偏见结构。最后,第三部分引入了基于情景学习的模型偏差抑制方法。
基于因果不变性的有偏数据识别
本项工作的核心部分:基于因果不变性的有偏数据识别。识别过程利用了偏见信息与语义信息在因果不变性上的本质差异。具体地,通过判断模型捕获的信息是否违背了因果不变性原则,来识别出有偏数据。在数据集中,存在成对数据,它们的偏见信息相同而语义信息不同,导致标准答案不一致,这类数据对被称为反例对,识别它们是本部分的主要目标。
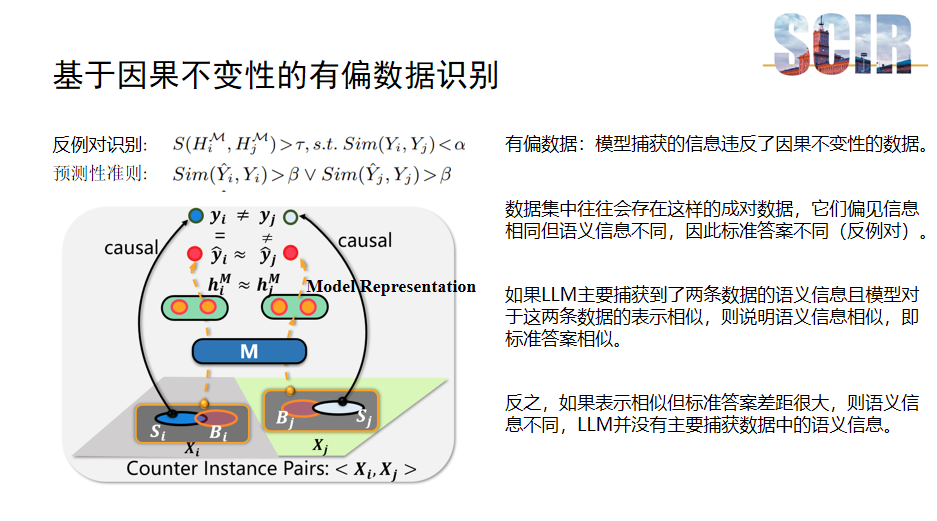
如果大模型主要捕获了数据的语义信息,并且对两条数据的表示相似,这表明它们的语义信息相近,标准答案也应相似。相反,如果两条数据的表示相似但标准答案差异显著,则表明模型并未主要捕获语义信息,而是包含了偏见信息。反例对的识别标准基于两个方面:一是大模型表示的相似性,用符号S表示;二是它们的标准答案不同。此外,为了排除模型仅捕获无关信息这一特殊情况,作者引入了一个预测性准则。该准则要求模型在处理两条数据时至少有一条是正确的。如果模型在这两条数据上至少有一条是正确的,那么可以推断模型并非仅捕获了无关信息。
信息性偏见实例选择与偏见模式归纳
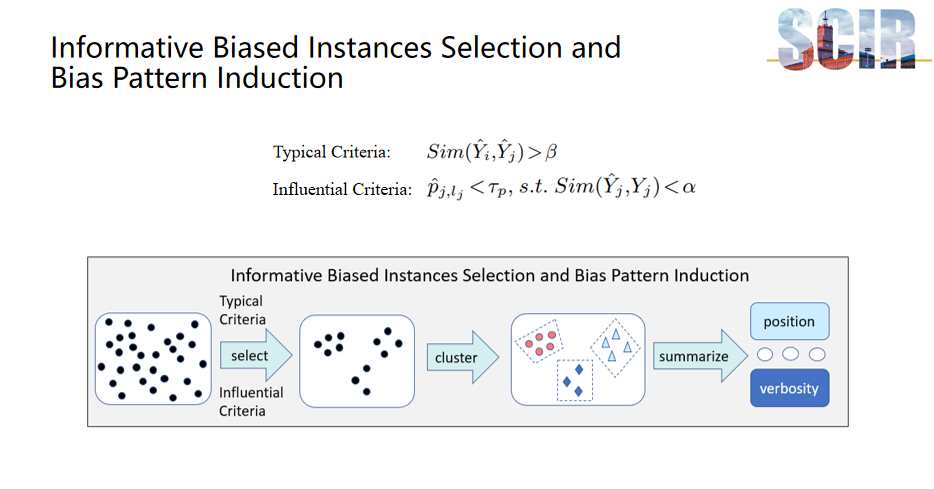
第二部分是关于信息性偏见实例选择和偏见模式归纳。在这一部分,该研究采用了"Typical Criteria"和"Influential Criteria"两种策略来选择信息性强的有偏数据。"Typical Criteria"通过比较模型对两条数据输出的相似度来进行选择。如果两条数据的输出差异显著,说明偏见信息对这两条数据产生了不同的影响,在这种情况下,即使是人类分析者也可能难以直接从这些数据中识别出偏见模式,即哪些偏见因素导致了什么样的结果。因此,我们利用"Typical Criteria"来排除模型对两条数据的输出相似度低的有偏数据(反例对)。此外,研究还引入了" Influential Criteria ",特别关注那些模型预测错误且偏见信息对模型影响较大的样本,这些样本通常具有较高的信息价值。
在筛选出信息性强的有偏数据后,本研究进行了聚类处理,将具有相似偏见模式的数据归为一类。聚类完成后,利用大模型对这些数据进行总结和归纳,以识别和总结出多种偏见模式,例如选项位置偏见和偏见等。
基于情境学习的偏见抑制方法
最后一个部分介绍了基于情境学习的偏见抑制方法,该方法针对的是零样本(zero-shot)和少样本(few-shot)两种场景。在零样本场景中,该方法的核心是通过明确告知模型,偏见信息与任务目标无关,促使模型忽略这些偏见信息,从而减少偏见对模型预测的影响。这种方法直接指导模型识别和忽略与任务无关的偏见因素,有助于提高模型在未知类别上的泛化能力。
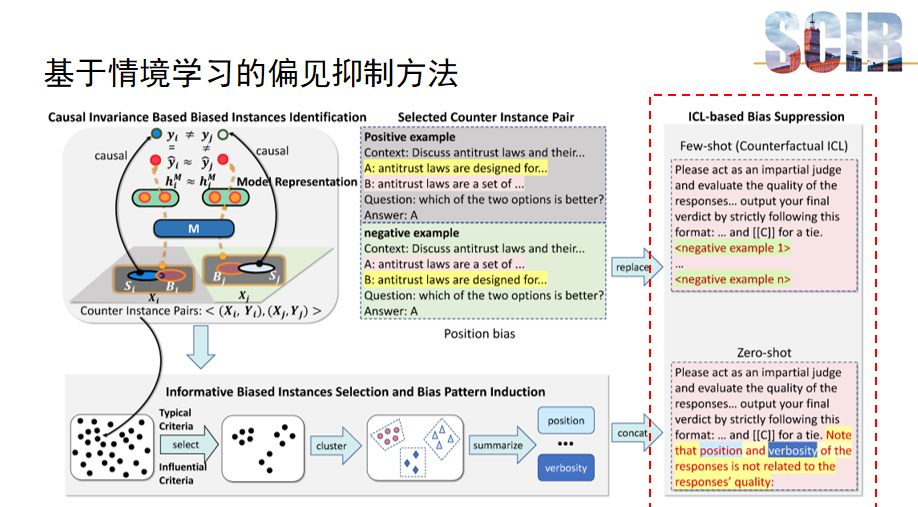
对于少样本场景,作者设计了反事实情境学习方法来对大模型进行去偏。具体地,之前筛选出的反例对中的预测错误的样例(反例),可以看作对正例(预测正确的样例)的语义信息进行干预后生成的反事实样例。因此,可以通过利用这些反事实样例通过情境学习的方法来对大模型进行去偏。具体的实施细节和效果评估,建议参考原论文。
实验结果
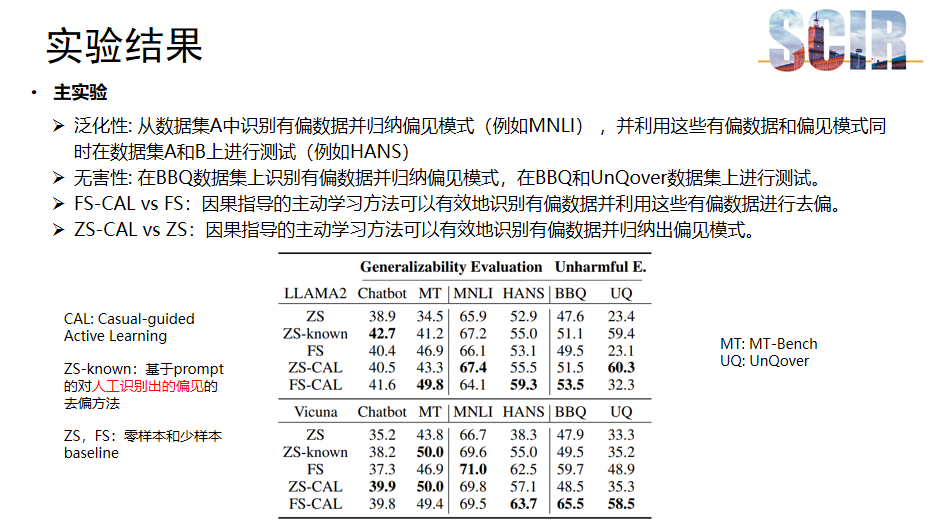
主实验
主实验旨在验证所提方法对提升模型泛化性和降低危害性的效果。通过从MNLI和Chatbot数据集中识别有偏数据并归纳偏见模式,然后在HANS和MTBench数据集上进行测试,可以验证方法对于提升模型泛化性的效果。此外,为了评估模型的无害性,研究者在BBQ数据集上识别有偏数据并归纳偏见模式然后在UnQover数据集上进行测试,这两个数据集专门被设计来探究刻板印象偏见的。
实验结果中,CAL代表本研究提出的因果指导的主动学习方法。ZS-known是基于prompt对人工识别偏见进行去偏的方法,而ZS和FS分别代表零样本和少样本的基线方法。对比结果显示,因果引导的主动学习方法在多个数据集上均优于基线方法,这说明本方法能够有效识别有偏数据并归纳偏见模式,进而可以利用这些有偏数据和偏见模式进行模型去偏。
同时,与ZS-known方法相比,本方法在某些数据集上展现出更优的性能,这一方面证明了本方法的有效性,另一方面也表明自动识别所有的偏见模式是十分具有挑战性的。这些结果表明,本研究所提出的方法在提升模型泛化性和减少危害性方面具有显著潜力。
BBQ数据集上的实例分析
在BBQ数据集上的实例分析表明,根据不同聚类类别的有偏数据可以归纳出不同的偏见模式,如图中所示,包括外貌(physical appearance)、年龄(age)、国籍(nationality)等。这些模式反映了数据集中存在的各种刻板印象偏见。
另一张图展示了归纳出职业状态这一偏见模式的反例对。在这个例子中,无论模型是否被告知Roberto的贫困状况,它都会受到职业偏见的影响,即错误地认为农民比药剂师更可能贫穷,从而预测农民更应得到政府的援助。这表明模型在预测时,可能会基于职业等偏见因素做出判断,而非仅仅基于文本中的语义信息。这种分析有助于我们理解模型如何受到偏见的影响,并指导我们如何改进模型以减少这种偏见。

归纳出的偏见模式的通用性
最后,研究探讨了偏见模式的通用性问题。由于大模型训练时使用的语料可能存在重叠,这可能导致它们共享相似的偏见模式。例如,在Llama2-13B大模型上识别出的某些偏见模式可能同样存在于GPT-4等其他大模型中。
为了验证这一点,研究尝试利用从Llama2模型中总结的偏见模式来对GPT-4进行去偏。实验在Zero-Shot场景下进行,即在没有额外训练数据的情况下,直接利用已识别的偏见模式通过上下文学习的方式对模型进行去偏。结果显示,在Zero-Shot场景下对这些偏见模式进行去偏后,GPT-4的泛化能力和无害性有所提升。
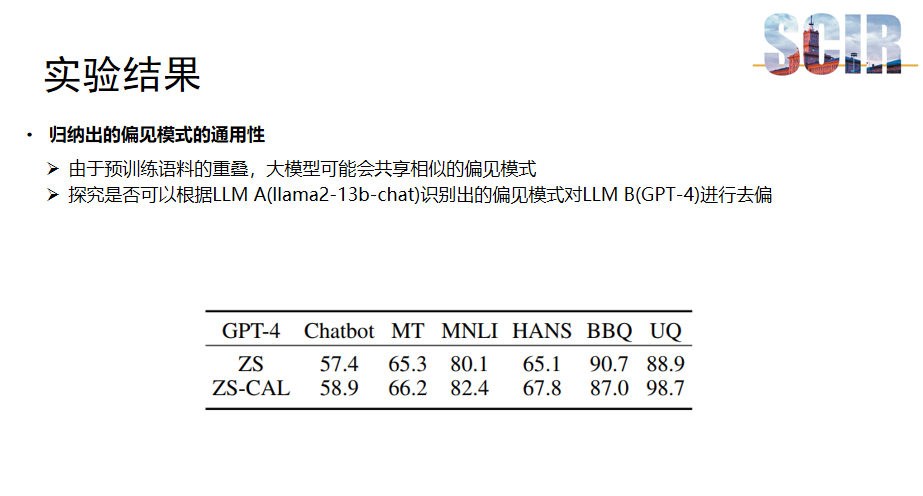
这一发现进一步证明大模型之间存在共享的偏见模式,并表明通过识别和应用这些共享的模式,可以在不同的模型间进行有效的去偏化处理。
本篇文章由陈研整理

点击 阅读原文 观看作者直播讲解回放!
往期精彩文章推荐
<>
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者直播讲解回放!