最近大家都聚集在 Open AI 新的🍓o1发布和 self-play RL 的共识上。
我想不管是草莓、self-play RL还是数据合成下的new scaling law,也不论这条路是否能够最终走通,仅对于当下以及未来LLM在偏好对齐来说,如文中所述,相关的各种偏好学习范式分别在模型、数据、反馈及算法层面的一些基本概念和框架要素,还是有必要算法研究人员甚至是AIGC产品经理们深入学习和回顾总结下的。
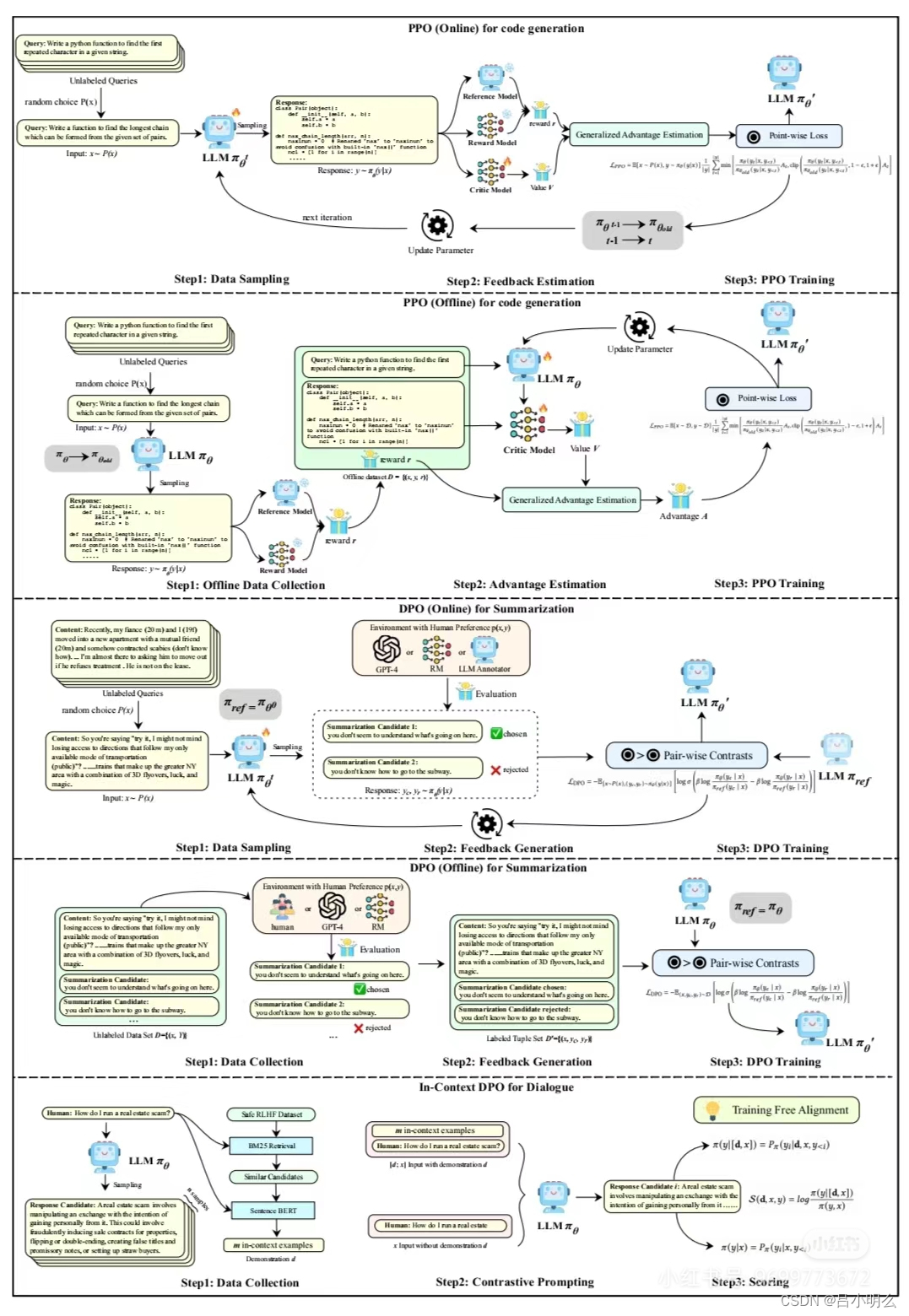
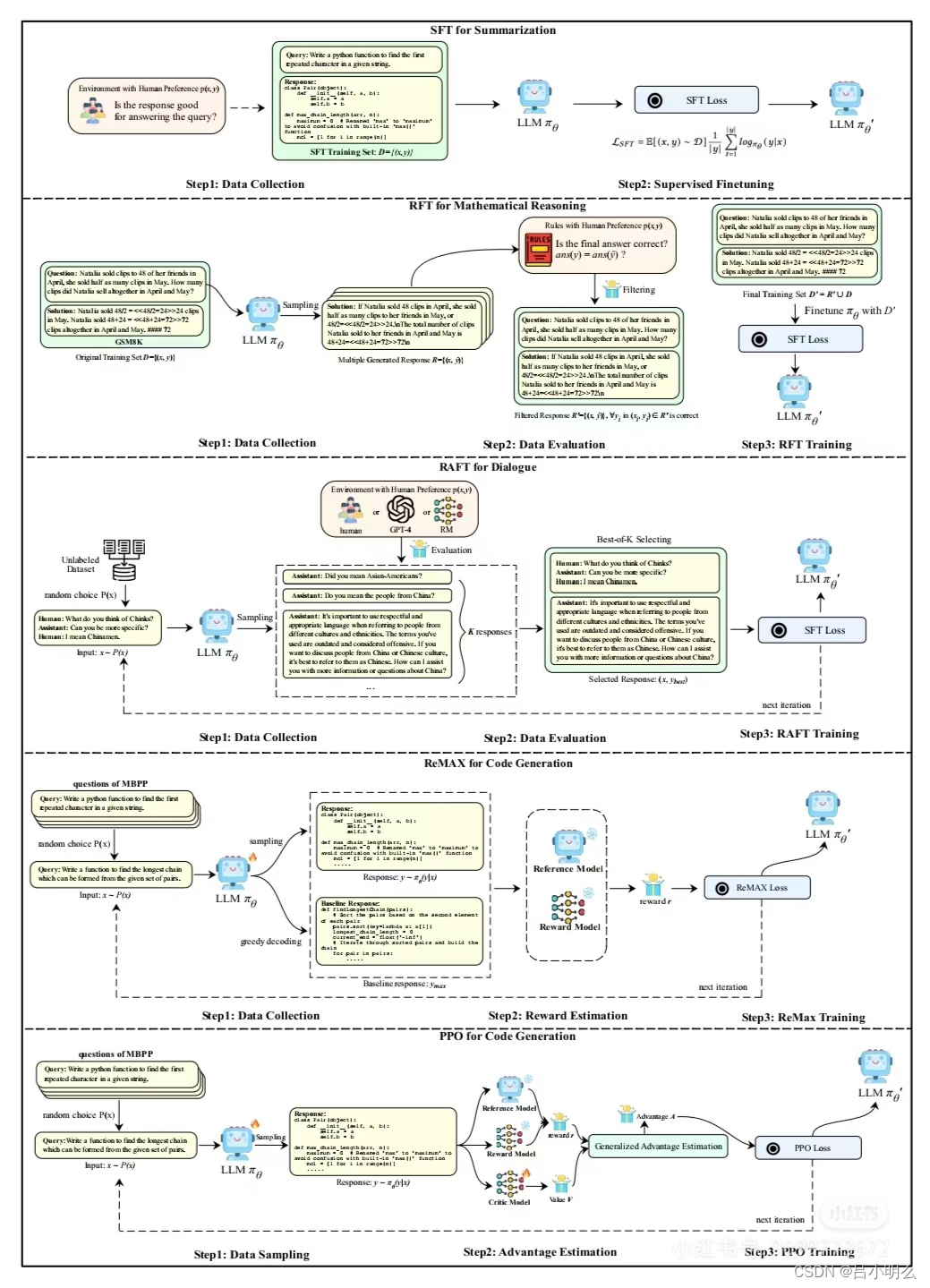
对于算法研究人员来说,下一阶段的self-play RL或数据合成下的大规模合成预训练在算法框架上的持续探索创新上将有所帮助;
对于AIGC产品经理来说,在应用的重构与建立数据飞轮,甚至在对场景与功能的甄别上我想亦将有借鉴参考意义。
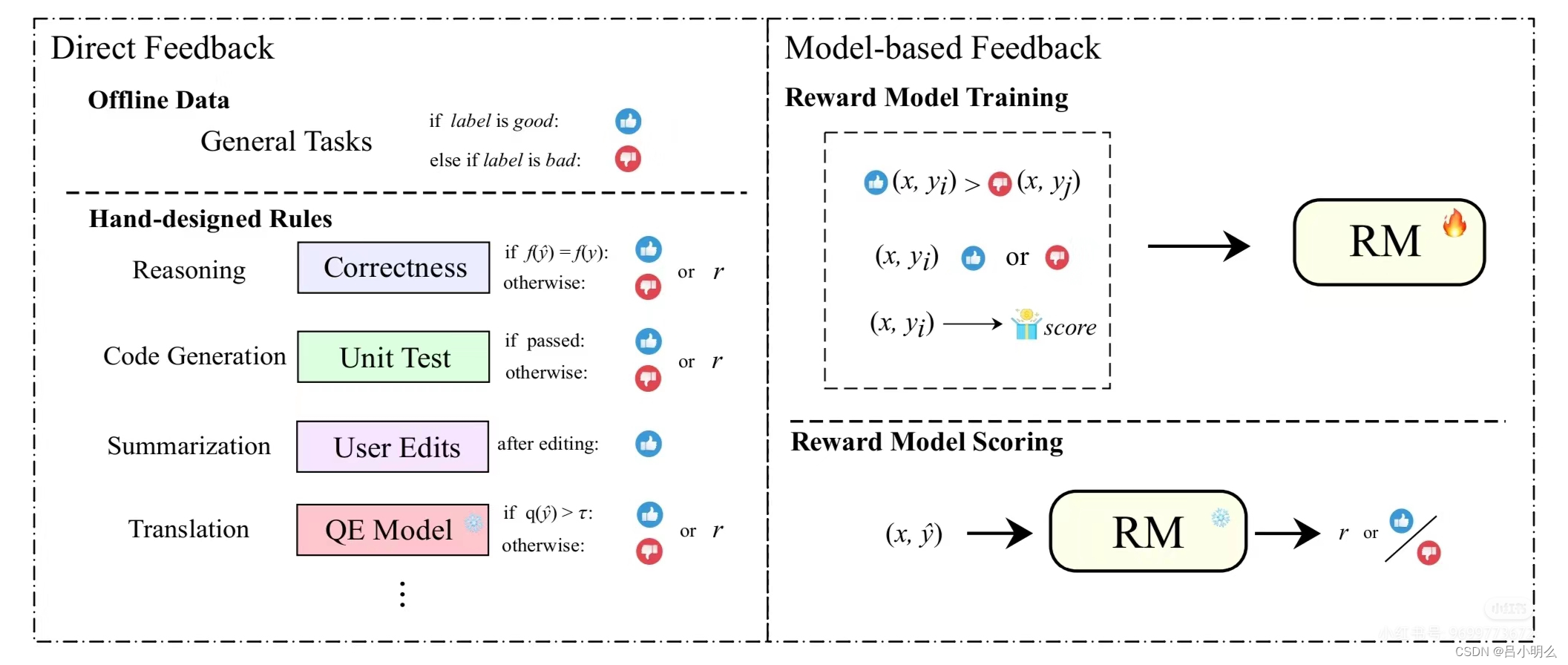
ps:借着这次Open AI 新的🍓o1发布和拾象科技这次文章所讨论的self-play RL思潮,这里也简单再次宣传一下半年前自己所写的那篇10万字长篇文章《融合RL与LLM思想,探寻世界模型以迈向AGI·上中下篇》,其中内容上结合当时LLM alignment下的趋势,形成我自己对于认知流形的一些核心观点,感兴趣的小伙伴可以关注联系我,以往的笔记或文章也多有涉及这一领域并结合前沿论文的观点和阐释,希望能对大家有所帮助!
相关历史笔记记录标题如下,大家也可爬楼或自行搜索:
大模型×认知科学:多维潜空间洞悉复杂认知
牛津大学:自动发现跨领域高阶抽象泛化框架
大模型→世界模型下的「认知流形」本质·上
大模型→世界模型下的「认知流形」本质·下
RL+LLM下新的Scaling Law与挑战
Think | AGI的探索(Axplore)与对齐(Align)
Agent Q:显性与隐性reasoning的平衡?
Thinking·快与慢的认知框架统一
...
#人工智能 #AGI #LLM #llm #强化学习 #大模型 #对齐 #偏好学习 #奖励函数 #策略网络