引言
今天来看一下上篇论文笔记中反复介绍的 ChatQA: Surpassing GPT-4 on Conversational QA and RAG。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
我们介绍了 ChatQA,这是一个模型套件,一种两阶段指令微调方法,这大大提高了 RAG 的表现。为了实现有效的检索,我们引入了一种针对对话 QA 优化的密集检索器,其结果与现有最先进的查询重写模型相当,同时显著降低了部署成本。我们还推出了 CHATRAG BENCH,该基准涵盖了十个数据集,涉及 RAG、表格相关 QA、算术计算以及无法回答的问题的全面评估。
模型权重、指令调优数据、CHATRAG BENCH 和检索器开源: https://chatqa-project.github.io/。
1. 总体介绍
最近,ChatGPT引领了在生产和研究社区中建立问答和检索增强生成系统的范式转变。特别地,这些模型的以下几个方面受到青睐:
- 用户可以以对话的方式与 QA 模型进行互动,从而可以轻松提出后续问题。
- 这些模型能够在开放域或长文档设置中整合检索到的证据块,其中提供的上下文远长于 LLM 的上下文窗口。
- 这些通用模型能够以0-shot 方式回答有关表格和算术计算的任何问题,而无需针对特定数据集进行微调,同时匹配微调模型的准确性。
在这项工作中,我们介绍了 ChatQA,这是一个开源模型家族,能够在利用相对较弱的开源基础模型的情况下超越 GPT-4。
贡献包括:
- 提出了一种两阶段指令微调方法,并设计了一种数据集策划方案,这可以大大增强 LLM 在对话 QA 和 RAG 任务中整合用户提供或检索的上下文的能力。
- 在检索方面,展示了对人类标注数据或合成的多轮 QA 数据集进行微调的单轮 QA 检索器,其效果与使用最先进的 LLM 基础的查询重写模型相当。结果还突出了利用合成数据生成来训练定制检索器的有前途方向。
- 介绍了 CHATRAG BENCH,这是一个全面的基准,包括十个对话 QA 数据集,其中包括五个需要检索的长文档数据集和三个包含表格数据和算术计算的数据集。
- 研究了无法回答的场景,在这种场景中,LLM 需要生成"无法回答"以避免虚假回答。
2. 相关工作
2.1 对话 QA 和 RAG
以对话方式进行的问答自然改善了用户体验,因为它能够处理后续问题。如果需要,模型还可以向用户提出澄清问题,这可以减少虚假回答。因此,它已成为生产中部署 QA 模型的默认格式。与最新的 LLM 基础通用解决方案相比,大多数早期研究集中在针对特定领域或数据集的微调专家模型。
近年来,许多对话式 QA 数据集被引入。这些模型被要求根据提供的上下文或文档回答问题,如果提供的文档比 LLM 的上下文窗口长,就涉及检索增强生成(RAG)。提供的上下文或文档可以是:i)来自各种领域的纯文本文档;或 ii)包括纯文本和表格的文档。
2.2 多轮 QA 的检索
RAG 对于开放域环境中的对话式 QA 至关重要,例如,利用来自搜索引擎的最新信息,或当专有文档比 LLM 的上下文窗口长时。密集检索器通常被训练以在给定单个问题的情况下检索 top-k 相关块。在对话式 QA 中,后续问题(例如,使用指代在前一对话中提到的实体的代词)可能缺乏检索所需的信息,而将这些问题与所有对话历史一起输入可能是冗余的,从而导致次优结果。
对话查询重写:大多数早期解决方案是查询重写方法。最新的提问被重写为独立的查询,而不包括来自先前对话历史的额外信息,因此可以直接用于检索模型以检索相关上下文。许多数据集被收集以促进这一研究方向,以及多种提议的查询重写方法。
多轮 QA 的检索器微调:一些早期工作在领域内对话查询和上下文对上对单轮查询检索器进行了微调,使其能够直接接受对话历史和当前查询的连接作为输入。
在这项工作中,我们专注于0-shot 评估。我们在高质量的多轮数据集上对单轮查询检索器进行了微调。然后,我们评估了微调检索器在五个基准数据集上的零-shot 能力。
2.3 指令微调
指令微调的目标是使 LLM 能够遵循自然语言指令。在高质量指令微调数据集的发展中出现了激增,包括 FLAN、Self-Instruct、unnatural Instructions、Dolly和 OpenAssistant。
尽管对指令微调的研究众多,但只有少数工作集中在改进 RAG 或上下文感知生成以用于 QA 上。Lin介绍了一种检索增强的指令调优方法,该方法在 LLM 微调中附加了 top-k 检索到的块。Wang在检索增强预训练后应用了指令微调。
相比之下,我们提出了一种两阶段指令微调方法,以改进利用检索或提供上下文的生成。我们发现,附加 top-k 检索到的块进行 LLM 微调对广泛的对话 QA 任务并没有帮助。
我们展示了在指令调优中添加少量"无法回答"样本可以引导模型在必要时生成"无法回答"的输出,从而显著减少虚假回答。
3. ChatQA
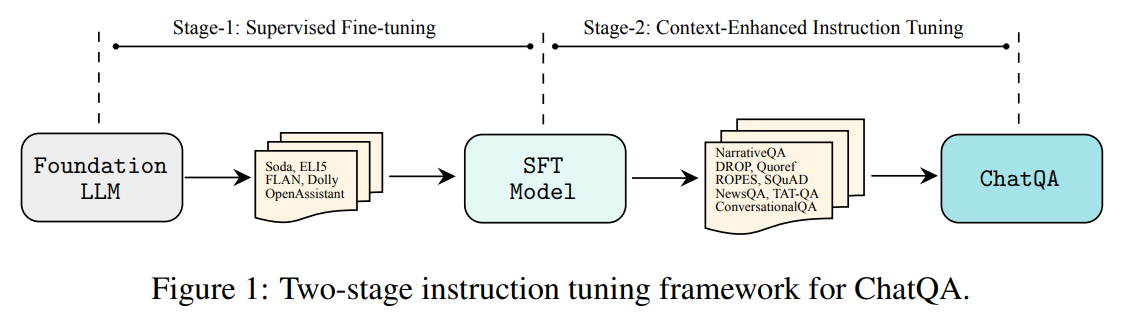
在本节中,我们提出了一种针对 ChatQA 的两阶段指令调优方法。有关示意图,请参见图 1。我们的方法以一个预训练的 LLM 基础模型为起点。在第一阶段,我们对结合了指令跟随和对话数据集的混合数据集应用监督微调(SFT),方法如 Ouyang et al.(2022)所述。之后,我们的模型在作为对话代理时展现出了良好的指令跟随能力。然而,其在上下文感知或 RAG 基础的 QA 方面的能力仍然有限。因此,我们引入了一个后续阶段,称为上下文增强指令调优,专门设计用于提升模型在对话 QA 中的上下文感知或检索增强生成的能力。
3.1 第一阶段:监督微调
为了构建一个大规模且全面的监督微调(SFT)数据集,从高质量的指令微调数据集中收集了 128K 个 SFT 样本。这些数据集包括:1)社会对话数据集 Soda,2)包含详细回答的长篇 QA 数据集 ELI5,3)FLAN 和思维链数据集,4)LLM 合成指令微调数据集,包括 Self-Instruct和 Unnatural Instructions,以及 5)一个私有众包对话数据集,以及两个公开的人类编写对话数据集:OpenAssistant和 Dolly。
将所有 SFT 数据的结构统一为对话格式。首先在开始时添加一个"System"角色,以设置一个通用指令,引导 LLM 提供礼貌和有帮助的回答。我们还添加了"User"和"Assistant"角色,以纳入来自指令微调数据集的指令和响应对。使用这种统一格式对 LLM 基础模型进行微调。
3.2 第二阶段:上下文增强指令微调
为了进一步提升模型在给定上下文下的对话 QA 能力,进行第二阶段的指令微调,该阶段将上下文化的 QA 数据集整合到指令问题混合数据集中。具体而言,第二阶段的指令微调数据集包括上下文化的单轮 QA 和对话 QA 数据集的混合。
3.2.1 人工标注数据
除了公开可用的数据集之外,第二阶段的关键元素之一是获得高质量的基于文档的对话 QA 数据集。我们创建了一个仅包含 7000 个对话的人工标注对话 QA 数据集(HumanAnnotatedConvQA)。为了构建这个数据集,首先从互联网收集了 7000 个涵盖各种主题的文档。接着,我们指示标注员同时扮演好奇的用户(提出问题和跟进问题)和回答者的角色。我们为每个文档创建了多轮对话,总共形成了 7000 个对话 QA 对话,每个对话平均包含 5 次用户-助手轮次。
为了减少无法回答情况中的虚假回答,我们旨在使模型在无法在给定上下文中找到答案时能够明确指示。为了获得这些无法回答的数据样本,我们要求标注员标识所有与用户问题相关的上下文部分。因此,我们能够通过删除上下文中相关位置的文本来构造无法回答的场景。在删除与问题相关的文本后,我们使用句子"对不起,我无法根据上下文找到答案"作为无法回答问题的响应。最后,我们构建了另外 1500 个用户-助手轮次的无法回答注释,这提供了可回答和无法回答情况的良好平衡。
3.2.2 合成数据生成
为了验证 HumanAnnotatedConvQA 的质量,利用 GPT-3.5-Turbo 生成合成对话 QA 数据集,利用其强大的指令跟随和文本生成能力。在这项工作中,我们关注于中型高质量的合成数据用于 LLM 微调。
GPT-3.5-Turbo 的指令包括三个部分:1)指导模型提供有用回答的系统角色,2)说明所需数据类型的对话 QA 示例,3)指导模型根据文档内容生成对话 QA 的文档。从 Common Crawl 收集了 7000 个文档(每个文档平均约 1000 个词),涵盖了广泛的领域。每个文档用于生成一个对话 QA 样本,总共形成了 7000 个多轮 QA 对话,每个对话平均包含 4.4 次用户-助手轮次(称为 SyntheticConvQA)。
与 HumanAnnotatedConvQA 类似,我们在这个合成数据集中构建了另外 1500 个用户-助手轮次的无法回答注释。由于没有对上下文位置的标注,我们从 SyntheticConvQA 中构建合成的无法回答样本。具体而言,我们首先将文档(每个对话)切分成不同的块。然后,只有在存在与助手回答"高度重叠"的块需要删除,而其余的块与助手回答显示"低重叠"时,我们才将其视为有效的无法回答样本。我们使用每个块和助手回答之间的 4-gram 召回率(测量回答的 4-gram 短语在每个块中的比例)作为衡量它们重叠的指标,并将其高于 0.5 视为"高度重叠",低于 0.1 视为"低重叠"。
3.2.3 训练混合数据
为了增强模型处理表格文档和算术计算的能力,加入了包含这两个元素的 TAT-QA 数据集。此外,还整合了上下文化的单轮 QA 数据集,以进一步增强模型的 QA 能力。我们还保留了第一阶段 SFT 数据集在训练混合数据中,以保持模型的指令跟随能力。
最终,第二阶段的训练混合数据包括:
- 对话 QA 数据集:HumanAnnotatedConvQA 或 SyntheticConvQA
- 单轮 QA 数据集:DROP、NarrativeQA、Quoref、ROPES、SQuAD1.1、SQuAD2.0、NewsQA、TATQA
- 第一阶段的所有 SFT 数据集。
对于 Llama3-ChatQA1.5 的训练,额外纳入了 HybriDial和我们收集的约 2000 个金融领域的 QA 对,以进一步提高模型在表格理解和算术计算方面的能力。
遵循第一阶段的类似模板来统一所有单轮 QA 和对话 QA 数据集。不同之处在于两部分:1)在系统角色之后,我们为单轮问题或多轮对话添加相关上下文;2)在单轮问题或多轮对话之前,我们根据不同 QA 数据集的答案类型(例如,简短回答、长答案、算术计算)整合进一步的指令。我们使用第一阶段的 SFT 数据集格式。
4. 多轮 QA 的检索
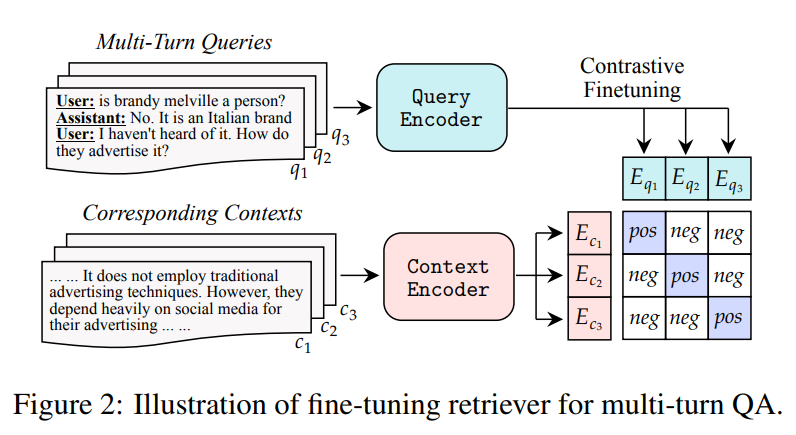
在对话 QA 任务中,当文档变得过长,无法直接输入到 LLM 时,能够处理对话查询的检索器变得至关重要。这种对话检索器会对话历史和当前查询进行拼接编码,然后从文档中检索相关上下文。之后,只有相关的上下文会被用作 LLM 的输入。当前的最先进的检索器,例如 Dragon,经过优化处理单轮查询,因此在处理多轮对话查询时,通用性较差。图 2 展示了我们用来缓解这个问题的检索器微调方法。我们建议使用对话查询和上下文对来进一步微调单轮检索器,以更好地处理对话输入。
另一种解决方案是对话查询重写方法,它使用查询重写器根据对话历史重写当前问题。重写后的查询直接作为输入提供给单轮查询检索器,以检索相关上下文。除了嵌入和搜索成本,查询重写模型还会引入大量额外的计算开销来生成重写后的查询。
4.1 多轮 QA 的检索器微调
为了构建高质量的微调数据集,我们利用来自 HumanAnnotatedConvQA 或 SyntheticConvQA 的对话 QA 数据集来构造对话查询和上下文对。
对于 HumanAnnotatedConvQA,我们直接使用对话查询和上下文对的标注,并利用这些数据进一步微调单轮查询检索器。对于 SyntheticConvQA,我们首先将对话 QA 数据集中的每个文档切分成不同的块。然后,我们计算助手回答与每个块之间的 4-gram 召回率。之后,我们将具有最高召回率的块视为当前用户问题的golden chunk。最终,构造出的对话查询和上下文对用于微调单轮查询检索器。
4.2 对话查询重写
为了构建强大的对话查询重写模型,我们选择 GPT-3.5-Turbo 作为重写器,我们不仅提供了 GPT-3.5-Turbo 的重写任务指令,还提供了一些重写示例,以提高重写结果的质量。
## 4.3 比较
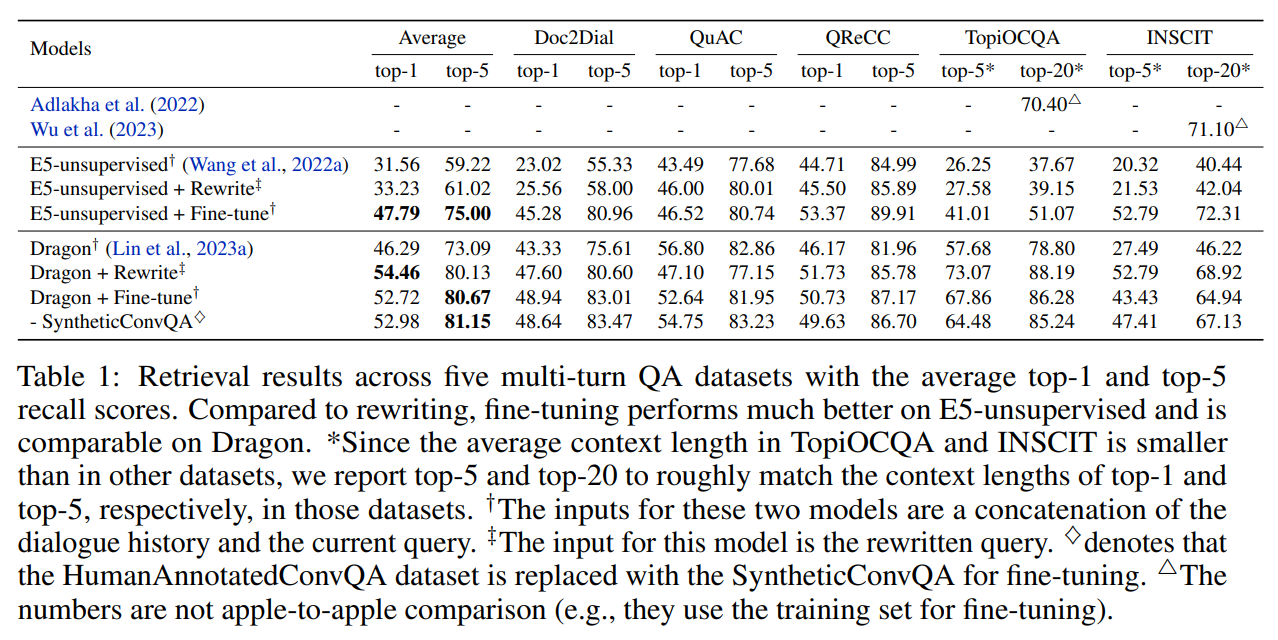
在表 1 中,我们比较了在五个数据集上使用查询重写和微调方法的0-shot 设置。在最先进的检索器 Dragon和一个强大的无监督检索器 E5-unsupervised上进行实验,后者没有在 MS MARCO上进行微调。
在 Dragon 实验中,我们发现微调在平均 top-1 召回率上比查询重写差了 1.74%,但在平均 top-5 召回率上却表现更好,提升了 0.54%。这表明微调方法在对话检索中具有一定的有效性。
此外,我们观察到,在微调过程中,使用 HumanAnnotatedConvQA 和 SyntheticConvQA 的结果是相当的。这突显了我们的人类标注数据集具有高质量,并且我们不依赖 ChatGPT 模型来构建最先进的多轮查询检索器。
令人惊讶的是,微调在 E5-unsupervised 上的表现显著优于重写。我们推测,由于 E5-unsupervised 在预训练阶段没有使用人类标注的查询和上下文对,这导致了对高质量重写查询的泛化能力较弱。相比之下,使用高质量数据集微调 E5-unsupervised 能显著提升性能,在平均 top-1 和 top-5 召回率上均提高了 15% 以上。
因此,在高质量对话查询上下文对上微调一个良好的单轮检索器,其性能可与使用最先进的重写器相媲美。然而,重写方法需要额外的计算时间来进行自回归生成,并且可能还需要 API 成本来使用像 GPT-3.5-Turbo 这样的强大模型。相比之下,我们提出的多轮微调方法绕过了这些问题。对于这五个数据集的 QA 评估,我们始终使用微调方法中检索的 top-5 结果来评估所有 QA 模型。
5. 实验设置
5.1 基准
基于内部开发的 GPT-{8B, 22B} 基础模型(使用 3.5 万亿个 token 进行预训练)、Llama2-{7B, 13B, 70B} 基础模型和 Llama3-{8B, 70B} 基础模型开发了 ChatQA 模型。将 ChatQA 模型与 Llama2-Chat-{7B, 13B, 70B} 和 Llama3-Instruct-{8B, 70B} 进行比较,这些模型在指令跟随和对话 QA 能力方面表现出色。此外,我们还与强大的 RAG 模型 Command R+进行比较,该模型具有 1040 亿个参数,以及三款非常强大的 OpenAI 模型:GPT-3.5-Turbo-0613、GPT-4-0613 和 GPT-4-Turbo-2024-04-09。为了公平比较,当需要检索时,使用来自最佳检索器的相同 top-k 检索块作为所有基准模型和 ChatQA 模型的上下文。
5.2 CHATRAG BENCH:评估基准
为了评估模型在对话 QA 和 RAG 上的能力,我们构建了 CHATRAG BENCH,这是一个涵盖 10 个数据集的集合,涉及各种文档和问题类型。这些数据集要求模型从检索到的上下文中生成响应,理解和推理表格,进行算术计算,并指出问题在上下文中找不到的情况。
5.2.1 长文档数据集
收集了五个对话 QA 数据集,这些数据集包含长文档,无法直接适应具有 4K 或 8K token 的 LLM。因此,运行了最佳的多轮查询检索器,以获取 top-n 相关块作为输入。
-
Doc2Dial (D2D):这是一个基于文档的对话 QA 数据集,涵盖四个领域:DMV、SSA、VA 和学生援助。每个样本包括一个对话,用户提出关于文档的问题,代理则回应这些问题。平均文档长度约为 101K 个词。
-
QuAC:基于维基百科文档。最初文档较短。由于每个对话与多个维基百科 URL 相关联,我们从这些链接中提取文本,将文档大小增加到大约平均 15K 个词。它包含了无法回答的案例,其中答案无法在给定的上下文中找到。
-
QReCC:这是一个开放领域的对话 QA 数据集,来源于多个来源。与 QuAC 类似,每个对话也有相应的 URL。我们从这些 URL 中提取文本以构建文档。最终,平均文档大小约为 5K 个词,最大文档大小为 20K 个词。
-
TopiOCQA (TCQA):基于整个维基百科。它涉及主题切换,要求代理在整个维基百科中搜索用户问题的答案。
-
INSCIT:同样基于整个维基百科。它研究了用户问题不明确且需要澄清的情况。
对于 Doc2Dial、QuAC 和 QReCC,将文档分割成大约 300 个词的块,并为每个用户问题检索 top-5 相关块作为上下文。对于 TopiOCQA 和 INSCIT,我们遵循原始分割,结果是较小的块。因此,我们检索了 top-20 块,以获得与前三个数据集类似的上下文长度。
5.2.2 短文档数据集
为了增加文档长度的多样性,我们收集了五个包含短文档(少于 1.5K 个词)的对话 QA 数据集。平均而言,1 个词会被分解成 1.5 个 token。因此,这些文档可以直接适应具有 4K token 序列长度的 LLM。
-
CoQA:这是一个对话 QA 数据集,每个对话都基于一段短文。答案通常较短,文段涵盖了广泛的领域,如儿童故事、文学、中高考试、新闻、维基百科。
-
DoQA:涵盖三个领域:烹饪、旅行和电影,这些数据来自活跃的 Stack Exchange 论坛。数据集中包含无法回答的案例,其中答案无法在给定的文档中找到。
-
ConvFinQA (CFQA):基于金融领域。每个文档包含一个金融报告表格以及围绕表格的相关文本。这个数据集涉及算术计算和复杂的数字推理。
-
SQA:基于仅包含单个表格而没有任何附带文本的文档。文档来自维基百科,问题高度组合,要求模型具备强大的表格理解能力以提供正确的答案。
-
HybriDial (HDial):这是一个对话 QA 数据集,基于包含维基百科表格和文本数据的文档。问题复杂,需要在文档中进行推理。
在所有 10 个数据集中,ConvFinQA、SQA 和 HybriDial 数据集包含文档中的表格数据,而其他数据集的文档仅包含文本。
5.3 评估指标
鉴于 F1 分数是评估 QA 模型最常用的自动化指标,我们对所有数据集使用 F1 分数,除了 ConvFinQA。在 ConvFinQA 中,使用精确匹配指标,因为 ConvFinQA 中的答案涉及从文档中提取数字以及算术计算。因此,答案只有在与黄金答案完全一致时才有意义。当模型生成算术公式时,我们将使用计算器计算其最终结果,并与黄金答案进行比较。此外,还进行人工评估,以评估我们的模型与 GPT-4-0613 生成答案的正确性。
6 结果
6.1 主要结果
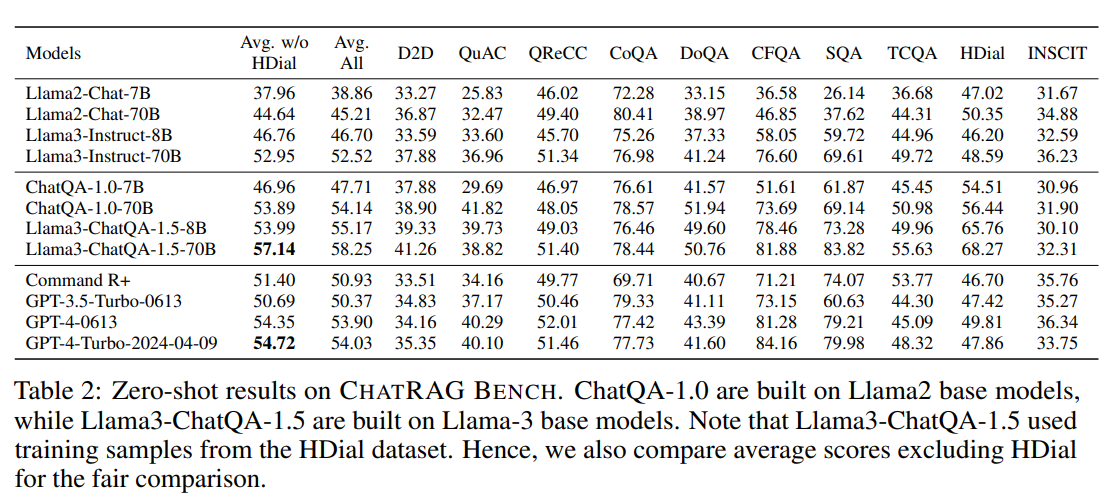
概述 在表 2 中,比较了不同模型变体和 OpenAI 模型在 10 个对话 QA 数据集上的表现。ChatQA-1.0-7B/70B 显著超越了 Llama2-Chat 对应模型,而 Llama3-ChatQA-1.5-8B/70B 显著超越了 Llama3-Instruct 对应模型。
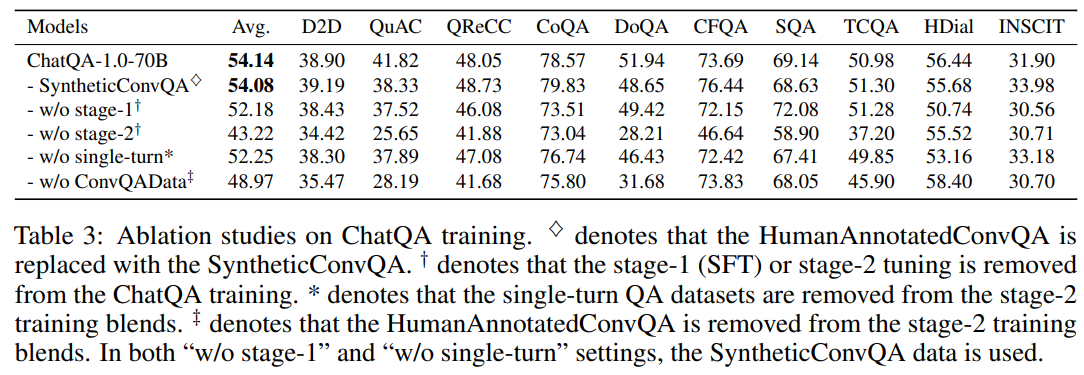
阶段 1 SFT 和阶段 2 调优的重要性 在表 3 中,我们发现去除 ChatQA 训练中的阶段 1 SFT 导致平均得分下降了 1.9。除了 SQA 外,去除阶段 1 会使模型在其他数据集上的表现普遍变差。结果表明,阶段 1 仍然扮演着重要角色。它提升了 ChatQA 的指令跟随能力,这对阶段 2 调优是有利的。此外,我们发现去除 ChatQA 阶段 2 调优会使平均得分大幅下降 10.92。这是因为阶段 2 调优(即上下文增强的指令微调)使模型能够更有效地利用从检索或相关上下文中获取的信息。
单轮数据的有效性 为了研究单轮 QA 数据集如何影响模型的多轮 QA 能力,我们进行了一项消融研究,通过从 ChatQA-1.0-70B 的阶段 2 训练混合中移除这些数据集。表 3 显示,将单轮 QA 数据集纳入阶段 2 训练混合通常会使所有基准数据集的得分提高,平均提升了 1.83 分。添加单轮 QA 数据集改善了模型有效利用相关上下文回答问题的能力,从而在 CHATRAG BENCH 上取得了更好的成绩。
对话 QA 数据的有效性 我们进一步探讨了对话 QA 数据如何影响模型的多轮 QA 能力,通过从 ChatQA 阶段 2 训练混合中移除 HumanAnnotatedConvQA 数据。表 3 中的数据显示,"无 ConvQAData"使结果显著低于 ChatQA-1.0-70B。
人工标注数据与 GPT-3.5-Turbo 合成数据的对比 在表 3 中,我们还比较了使用 7k GPT-3.5-Turbo 合成数据集SyntheticConvQA和我们收集的 7k 人工标注数据集HumanAnnotatedConvQA的 ChatQA 模型。首先,我们发现这两者在平均得分方面表现相当,这表明我们不需要依赖 OpenAI 模型的合成数据来构建最先进的对话 QA 模型。其次,我们发现使用人工标注数据在 QuAC 和 DoQA 数据集上取得了显著的改进。这可以归因于人工标注数据在 QuAC 和 DoQA 数据集中存在更高质量的无法回答的案例。最终,这导致了这两个数据集的整体改进。
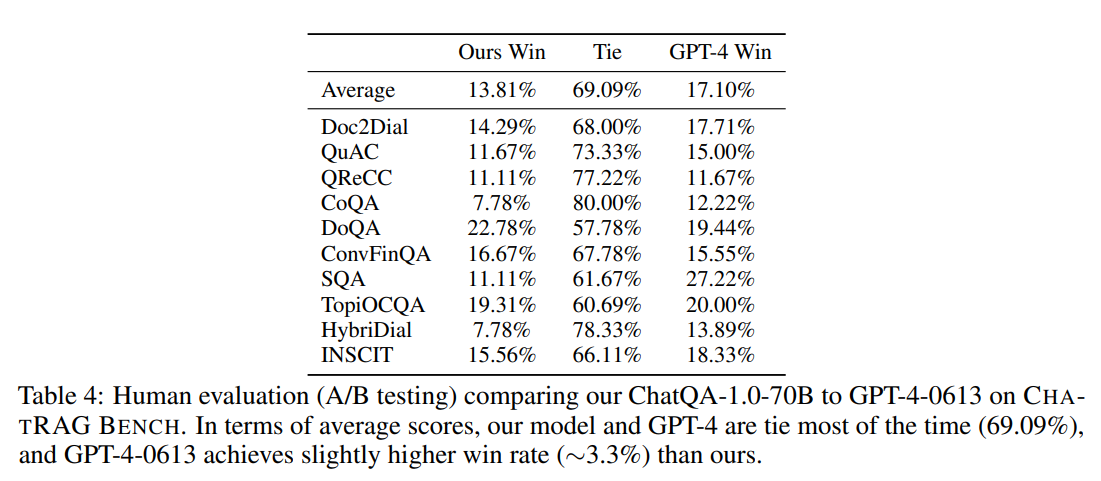
人工评估 尽管 F1 分数是评估 QA 模型质量的最常用指标,但回答问题通常有多种方式,这使得自动化指标不够完美。因此,我们使用人工评估进一步比较了 ChatQA-1.0-70B 和 GPT-4。在这项人工评估中,我们要求标注员验证 ChatQA-1.0-70B 和 GPT-4 输出中的事实,并确定哪个模型提供了更准确的回答。人工评估结果见表 4。我们首先发现 ChatQA-1.0-70B 和 GPT-4 大多数时候表现相当,而 GPT-4 的胜率比我们高出约 3.3%。这进一步确认了我们的模型具备强大的提供正确答案的能力。其次,我们发现我们的模型在 ConvFinQA 中的胜率略高于 GPT-4,这表明我们的模型具有较强的算术计算能力。第三,我们发现 GPT-4 在 SQA 任务中的胜率显著高于我们,这表明我们的模型在表格推理任务上与 GPT-4 之间仍存在差距。
6.2 细粒度分析
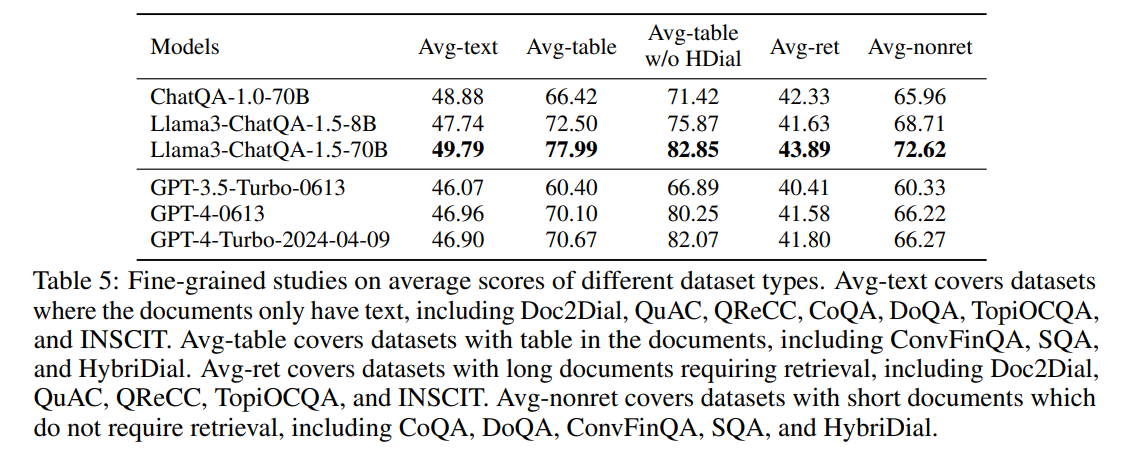
在表 5 中,我们进一步比较了我们的模型与 OpenAI 模型在不同数据集类型中的表现。ChatQA-1.0-70B 在仅包含文本的文档中取得了更好的结果,而 GPT-4-0613 在表格数据中展现了更好的 QA 能力。对于需要或不需要检索的数据集,ChatQA-1.0-70B 和 GPT-4-0613 的表现相当。此外,Llama3-ChatQA-1.5-70B 在所有类别中都超越了 GPT-4-0613 和 GPT-4-Turbo。
6.3 阶段 2 指令微调的 Top-k 块
在阶段 2 调优中,所有数据集的上下文以连续段落或文档的形式提供,这些上下文包含了答案。与此不同的是,模型在推理过程中需要处理长文档的 top-k 检索块。为了应对这种训练/测试不匹配,我们研究了将某些连续段落替换为检索的 top-k 块是否能增强模型的鲁棒性。
我们使用 NarrativeQA 进行这项研究,因为每个问题都有一个对应的长文档。最初,我们使用长文档的摘要作为上下文,其中包含了答案。为了整合不连续的上下文,我们首先将长文档切割成 300 字的块。然后,我们使用 Dragon 检索器检索与问题相关的 top-4 块作为额外的上下文。最后,我们将检索到的四个块与长文档的摘要一起考虑为"top-5"块。我们使用这个重建的 NarrativeQA 数据集替换原始数据集进行阶段 2 指令调优。
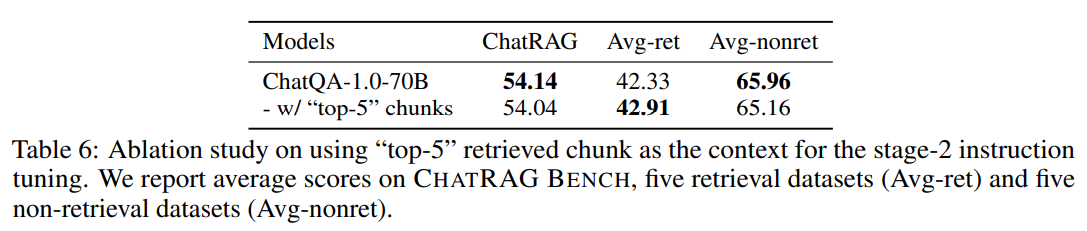
在表 6 中,我们观察到,使用"top-5"块作为训练上下文可以改善需要检索的数据集的表现,但会降低在非检索数据集上的表现。总体而言,这两种模型的表现相当。这是因为将"top-5"检索块纳入阶段 2 调优与需要检索的推理阶段相一致,从而提高了 Avg-ret 分数。然而,混合连续和不连续的文档可能使阶段 2 调优变得不够稳定,导致在非检索数据集上的结果不理想。
6.4 推理阶段的消融研究
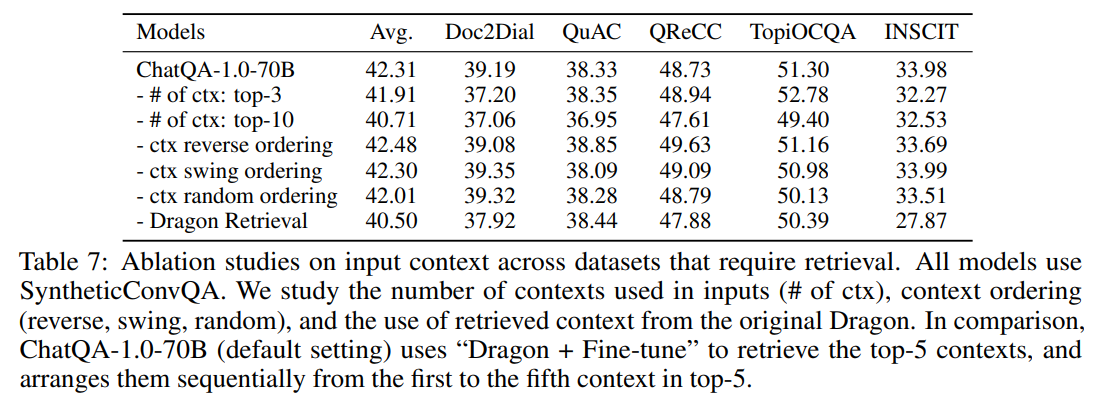
在表 7 中,我们展示了检索上下文/块的数量、上下文排序以及不同检索器如何影响对话 QA 和 RAG 结果的消融研究。
首先,我们发现使用更多上下文作为输入并不总是能改善结果。使用 top-5 上下文作为输入相比使用 top-3 或 top-10 上下文能取得更好的结果。直观上,更多的上下文有更高的可能性包含正确答案(更好的召回分数)。因此,使用 top-5 上下文的结果优于使用 top-3。然而,当上下文数量进一步增加时,模型可能会遭遇"lost in the middle"现象,并且从提供的上下文中提取答案的难度也可能增加,这会导致使用 top-10 上下文的结果较差。
其次,我们研究了不同的 top-5 上下文排序如何影响结果。我们比较了顺序排序(从第 1 个上下文到第 5 个上下文)、反向排序(从第 5 个到第 1 个上下文)、摆动排序(考虑到lost in the middle现象,我们将最相关的上下文安排在输入上下文的开始和结束位置,因此排序为 {第 1 个,第 3 个,第 5 个,第 4 个,第 2 个})以及随机排序(随机打乱 top-5 上下文)。我们发现,使用顺序排序与使用反向和摆动排序的表现相当,而随机打乱稍逊一筹。结果表明,我们的模型在从长上下文中提取正确答案的能力上表现出色,无论答案的位置在哪里。这是因为在 ChatQA 微调期间,答案的位置在上下文中是随机分布的。
第三,我们观察到,当将"Dragon + Fine-tune"替换为原始的未微调 Dragon 检索器时,平均得分下降了 1.81。基本上,当检索质量提高时,会直接增强问题回答的性能。
6.5 无法回答情况的评估
6.5.1 评估设置
我们研究了模型的另一种能力,即判断一个问题是否可以在提供的上下文中得到回答。在无法回答的情况下生成答案会导致虚假信息。为了进行这种评估,我们要求模型在无法在给定上下文中找到答案时进行指示。
我们使用了具有无法回答情况的 QuAC 和 DoQA 数据集来评估这种能力。具体而言,对于无法回答的情况,我们认为模型指示问题无法回答是正确的;而对于可以回答的情况,我们认为模型没有指示问题无法回答是正确的(即模型给出答案)。
最终,我们计算了无法回答和可回答情况的平均准确率作为最终指标。我们认为这一平均准确率作为可靠的指标,因为它与 F1 指标的精神相同,F1 指标衡量的是精确率和召回率的调和均值。
6.5.2 结果
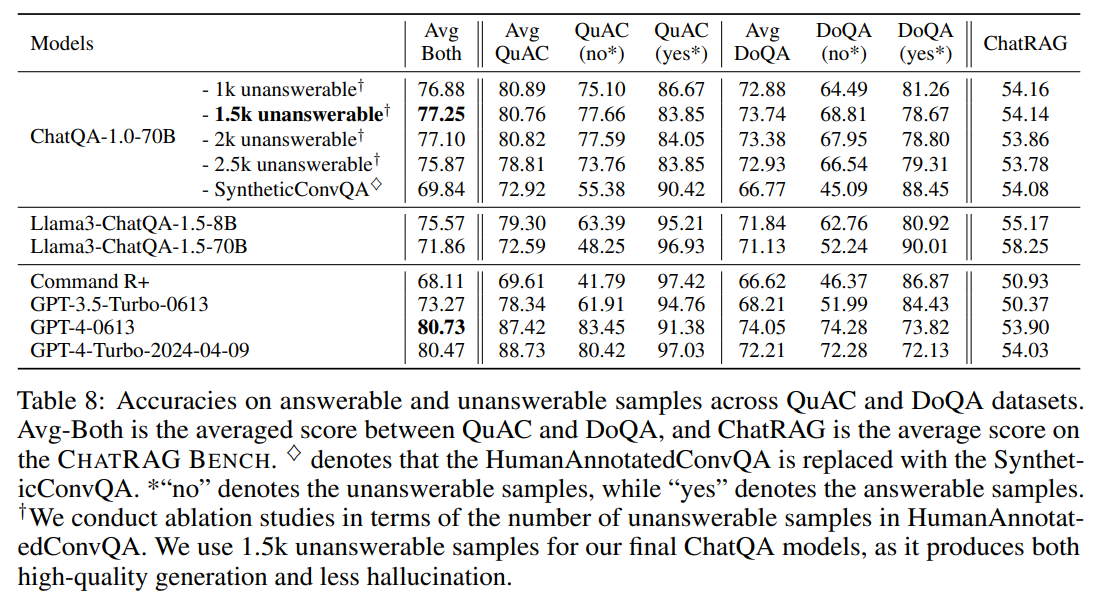
在表 8 中,我们比较了我们模型与 OpenAI 模型在 QuAC 和 DoQA 数据集上的表现。首先,我们发现,与使用 SyntheticConvQA 相比,使用 HumanAnnotatedConvQA 显著提高了 QuAC 和 DoQA 上的平均准确率。这是因为人类标注的数据中的无法回答标注质量更高,这显著提高了无法回答情况的准确率。其次,OpenAI 模型在此任务中表现出强大的能力。第三,我们发现 Llama3-ChatQA-1.5-8B/70B 的准确率通常低于 ChatQA-1.0-70B。这是因为这些模型在上下文中找不到答案时倾向于根据自己的知识给出回应,从而导致在无法回答情况下准确率较低。
此外,我们进行了关于 HumanAnnotatedConvQA 中无法回答样本数量的消融研究。我们发现,使用少量无法回答样本(例如 1.5k)能够在无法回答评估中取得显著结果,以及整体 CHATRAG BENCH 得分。值得注意的是,增加无法回答样本的数量并不一定会导致无法回答评估中的准确率提升。
6.6 单轮 QA 和 RAG 基准测试评估
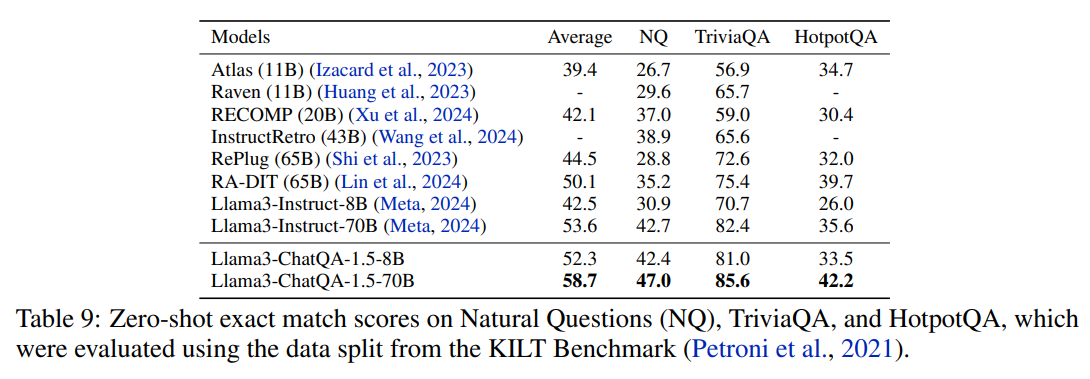
除了 CHATRAG BENCH 外,我们还进一步评估了 Llama3-ChatQA-1.5 模型在知识密集型单轮 QA 数据集上的表现,包括 Natural Questions、TriviaQA和 HotpotQA,并将其与前沿 RAG 模型进行比较。我们使用 Dragon 检索器来提取最相关的 top-k 上下文,这些上下文然后作为 Llama3-Instruct-8B/70B 和 Llama3-ChatQA-1.5-8B/70B 的输入。我们报告了使用 top-15、top-20 和 top-25 上下文获得的最佳结果。在表 9 中,我们显示了尽管模型尺寸显著较小,Llama3-ChatQA-1.5-8B 的表现仍优于当前最先进的 RA-DIT模型。Llama3-ChatQA-1.5-70B 显著超越了现有的前沿 RAG 模型。
6.7 案例研究

在表 10 中,我们展示了 ChatQA-1.0-70B 和 GPT-4-0613 输出的四个示例。第一个示例(关于董事会听证会)是一个简单的信息检索问题,ChatQA-1.0-70B 和 GPT-4 都回答正确。在第二个示例(关于 Arya)中,模型需要找到隐含信息(用蓝色标出)来给出答案。GPT-4 倾向于谨慎地提供答案,并回应说上下文中没有确切的信息,这也是正确的。第三和第四个示例要求模型具有良好的表格理解和推理能力。在第三个示例(关于 Massif)中,ChatQA-1.0-70B 通过比较保护区的大小与 3100 公顷得出正确答案,而 GPT-4 未能做到这一点。在第四个示例(关于 John B. England)中,ChatQA-1.0-70B 正确列出了三个日期但漏掉了一个,而 GPT-4 正确回答了问题。
7. 结论
在本文中,作者构建了一系列模型,在对话式 QA 和 RAG 任务中超越了 GPT-4。我们引入了 CHATRAG BENCH,这是一个涵盖了 RAG、表格推理、算术计算和无法回答场景的 10 个对话式 QA 数据集的集合。
A ChatQA指令微调模板
A.1 Stage-1: 监督微调
System: This is a chat between a user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions
based on the context. The assistant should also indicate when the answer cannot be
found in the context.
User: {Question 1}
Assistant: {Answer 1}
...
User: {Latest Question}
Assistant:使用助手的 {Latest Answer}作为模型输出的监督信号。
A.2 Stage-2: 上下文增强指令微调
基于State-1的格式模板,State-2中LLM的输入增加了{Context for Latest Question}和{Instruction}:
System: This is a chat between a user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions
based on the context. The assistant should also indicate when the answer cannot be
found in the context.
{Context for Latest Question}
User: {Instruction} + {Question 1}
Assistant: {Answer 1}
...
User: {Latest Question}
Assistant:和State-1一样,使用{Latest Answer}作为模型输出的监督。
对于{Instruction},基于答案类型为不同的数据集使用不同的指令:
Please give a full and complete answer for the question.这是针对长答案数据集,用于HumanAnnotatedConvQA和SyntheticConvQA,
Answer the following question with a short span. The answer needs to be just in a few words.这是短文本答案的数据集,用于SQuAD1.1、SQuAD2.0、 NarrativeQA、DROP、ROPES、NewsQ和 Quoref。
Answer the following question with a number from context or the math arithmetic using +, -, *, or /.这是针对使用数学计算或从上下文抽取数字的数据集,用于TAT-QA数据集。
Answer the following question with a short span, or a full and complete answer.可同时用于短和长文本答案。用于TAT-QA数据集。
对于用于sate-2指令微调的stage-1的 SFT 数据,我们保持与stage-1相同的格式模板。换句话说,{Context for Latest Question} 和{Instruction} 是空的。
B 合成数据生成
使用 GPT-3.5-Turbo 进行两步提示,以获得高质量的多轮 QA 对话。在第一步中,我们提示 GPT-3.5-Turbo 基于给定的文档生成多轮 QA 对话。然而,我们发现生成的对话缺少代词或常见名词来指代对话历史中的单词或短语。因此,在第二步中,我们提示 GPT-3.5-Turbo 通过添加代词或常见名词来修订生成的对话。对于两个阶段,我们都向 GPT-3.5-Turbo 提供少量示例,以确保生成的高质量。
第一步中的上下文少量示例提示如下(旨在生成多轮 QA 对话):
You are a helpful, pattern-following assistant.
role-user:
PersonA has access to information in the following passage:
###There are certain important aspects of college preparation. The student preparing
for college should define their goals and interests. The student should also plan
financially and academically. We have a checklist that helps students get ready
financially and academically.###
Generate a conversation of around four turns between PersonA and PersonU where
PersonU needs information from PersonA that is in the passage. Use only information
found in the passage.
PersonU starts the conversation and only asks questions. Most of PersonU's questions
are follow-up or continuations of previous questions.
Conversation:
role-assistant:
PersonU: I need to know how to prepare for college.
PersonA: You should first define your goals and interest and be sure to know the
costs and how to plan financially and academically for college.
PersonU: Is there something I can use as a guide to get ready for it?
PersonA: you can use our checklist to get ready financially and academically.
PersonU: Any other tip?
PersonA: Be sure to check out the reasons to attend a College or Career schools.
PersonU: Ok, that sounds good. Can you give me more tips?
PersonA: Another thing to take into consideration is to explore your career options.
role-user:
PersonA has access to information in the following passage:
###There are several disability compensation benefits. One of the benefits is the
annual clothing allowance. This allowance covers the cost of purchasing new clothes
up to a limit of 200 dollars annually.###
Generate a conversation of around two turns between PersonA and PersonU where
PersonU needs information from PersonA that is in the passage. Use only information
found in the passage.
PersonU starts the conversation and only asks questions. Most of PersonU's questions
are follow-up or continuations of previous questions.
Conversation:
role-assistant:
PersonU: I heard about a disability benefit for clothing. What is it about?
PersonA: This is a disability compensation benefit known as an annual clothing
allowance.
PersonU: I am quite interested about such benefits.
PersonA: Would you like to find out if you are eligible?
role-user:
PersonA has access to information in the following passage:
###Vascepa (icosapent ethyl) is a prescription fish oil medication approved for
treating adults with extremely high triglycerides, defined as a triglyceride level
of 500 mg/dL or higher. While using this medicine, you may need frequent blood tests
at your doctor's office. Vascepa is only part of a treatment program that may also
include diet, exercise, and weight control. Follow your doctor's instructions very
closely. You should not use Vascepa if you are allergic to icosapent. To make sure
Vascepa is safe for you, tell your doctor if you have: 1 liver disease; 2 diabetes;
3 a thyroid disorder; 4 problems with your pancreas; 5 a bleeding or blood-clotting
disorder; 6 if you are allergic to fish or shellfish; or. 7 if you drink large
amounts of alcohol, Vascepa (icosapent) works in the liver and bloodstream to reduce
very low-density triglycerides.###
Generate a conversation of around three turns between PersonA and PersonU where
PersonU needs information from PersonA that is in the passage. Use only information
found in the passage.
PersonU starts the conversation and only asks questions. Most of PersonU's questions
are follow-up or continuations of previous questions.
Conversation:
role-assistant:
PersonU: I heard about a medication called Vascepa. What is it used for?
PersonA: Vascepa is a prescription fish oil medication used for treating adults with
extremely high triglyceride levels.
PersonU: Are there any side effects or precautions I should be aware of?
PersonA: While using Vascepa, you may need frequent blood tests, and it's important
to follow your doctor's instructions closely. It's important to talk to your doctor
about any allergies or existing conditions you have.
PersonU: Is it effective in lowering cholesterol levels?
PersonA: Vascepa is used together with a low-fat diet and other treatments to lower
total cholesterol in people with severe high cholesterol.
role-user:
PersonA has access to information in the following passage:
{Document}
Generate a conversation of around three turns between PersonA and PersonU where
PersonU needs information from PersonA that is in the passage. Use only information
found in the passage.
PersonU starts the conversation and only asks questions. Most of PersonU's questions
are follow-up or continuations of previous questions.
Conversation:
role-assistant:
The in-context few-shot prompt in step-2 is as follows (aims to revise the multi-turn QA conversation
by adding pronouns and common nouns):
You are a helpful, pattern-following assistant.
role-user:
Given the following conversation between PersonU and PersonA:
###PersonU: I've heard about adobo sauce in Mexican cuisine. Can you tell me more
about it?
PersonA: Adobo sauce is a dark red sauce made from ground chiles, herbs, and
vinegar. It's used as a marinade and cooking sauce in Mexican and Southwestern
cuisines.
PersonU: What are the main ingredients in adobo sauce?
PersonA: The main ingredients are typically chile peppers, garlic, and vinegar.
However, there can be variations in the recipe.
PersonU: How can I make adobo sauce at home?
PersonA: One way to make adobo sauce at home is by using smoked jalapeno peppers
called chipotles. You can stew the chipotles in a sauce with tomatoes, garlic,
vinegar, salt, and spices. It's also possible to find canned adobo sauce in the
Hispanic foods section of many grocery stores.
PersonU: Are there any other uses for adobo sauce?
PersonA: Adobo sauce can be used as a condiment or as a marinade for various dishes.
It enhances the flavor of meats and can be used as a cooking and serving sauce.
Additionally, adobo is also used in a stew-like presentation of meat prepared in
this sauce.
PersonU: Is adobo sauce easy to preserve?
PersonA: Yes, you can preserve adobo sauce by freezing or canning it when you're
done making it. This allows you to store it for up to a year and enjoy its flavors
whenever you want.###
Modify PersonU's questions to use pronouns or common nouns to refer back to words
or phrases in PersonU's previous questions or PersonA's previous responses.
role-assistant:
PersonU: I've heard about adobo sauce in Mexican cuisine. Can you provide more
information about it?
PersonA: Adobo sauce is a dark red sauce made from ground chiles, herbs, and vinegar.
It's used as a marinade and cooking sauce in Mexican and Southwestern cuisines.
PersonU: What are the main ingredients in the sauce?
PersonA: The main ingredients are typically chile peppers, garlic, and vinegar.
However, there can be variations in the recipe.
PersonU: How can I make the sauce at home?
PersonA: One way to make it at home is by using smoked jalapeno peppers called
chipotles. You can stew them in a sauce with tomatoes, garlic, vinegar, salt, and
spices. It's also possible to find canned adobo sauce in the Hispanic foods section
of many grocery stores.
PersonU: Are there any other uses for it?
PersonA: It can be used as a condiment or as a marinade for various dishes. It
enhances the flavor of meats and can be used as a cooking and serving sauce.
Additionally, it is also used in a stew-like presentation of meat prepared in
this sauce.
PersonU: Is it easy to preserve?
PersonA: Yes, you can preserve it by freezing or canning it when you're done
making it. This allows you to store it for up to a year and enjoy its flavors
whenever you want.
role-user:
Given the following conversation between PersonU and PersonA:
###PersonU: I've heard about a test called urinalysis. What is it used for?
PersonA: Urinalysis is a test that evaluates a sample of your urine. It is used to
detect and assess a wide range of disorders, such as urinary tract infection,
kidney disease, and diabetes. It examines the appearance, concentration, and content
of urine.
PersonU: Can it help diagnose bladder cancer?
PersonA: Yes, urinalysis can be used as a screening and diagnostic tool for
bladder cancer. One way to test for bladder cancer is to check for blood in the
urine, which is called hematuria. This can be done during a urinalysis by examining
the urine cells under a special microscope.
PersonU: What other conditions or diseases can be detected through urinalysis?
PersonA: Urinalysis is commonly used to diagnose urinary tract or kidney infections,
evaluate causes of kidney failure, screen for the progression of chronic conditions
like diabetes mellitus and high blood pressure, and it can be used in combination
with other tests to diagnose certain diseases. It is a versatile test that helps
detect abnormalities in the urinary tract.
PersonU: Where can I get a urinalysis done?
PersonA: Urinalysis can be performed in various healthcare settings, including
doctors' offices, urgent care facilities, laboratories, and hospitals. You can
provide a urine sample in a specimen cup, and the sample can be analyzed on-site
or sent to a laboratory for testing.
PersonU: How much urine is typically needed for a urinalysis?
PersonA: Usually, only small amounts of urine, ranging from 30 to 60 ml, are required
for urinalysis testing. It's a non-invasive and relatively simple test that provides
valuable information about your health.###
Modify PersonU's questions to use pronouns or common nouns to refer back to words
or phrases in PersonU's previous questions or PersonA's previous responses.
role-assistant:
PersonU: I've heard about a test called urinalysis. What is it used for?
PersonA: Urinalysis is a test that evaluates a sample of your urine. It's used to
detect and assess a wide range of disorders, such as urinary tract infection,
kidney disease, and diabetes. It examines the appearance, concentration, and
content of urine.
PersonU: Can it help diagnose bladder cancer?
PersonA: Yes, urinalysis can be used as a screening and diagnostic tool for bladder
cancer. One way to test for bladder cancer is to check for blood in the urine, which
is called hematuria. This can be done during a urinalysis by examining the urine
cells under a special microscope.
PersonU: What other conditions or diseases can be detected through this test?
PersonA: Urinalysis is commonly used to diagnose urinary tract or kidney infections,
evaluate causes of kidney failure, screen for the progression of chronic conditions
like diabetes mellitus and high blood pressure, and it can be used in combination
with other tests to diagnose certain diseases. It is a versatile test that helps
detect abnormalities in the urinary tract.
PersonU: Where can I go to get this test done?
PersonA: Urinalysis can be performed in various healthcare settings, including
doctors' offices, urgent care facilities, laboratories, and hospitals. You can
provide a urine sample in a specimen cup, and the sample can be analyzed on-site
or sent to a laboratory for testing.
PersonU: How much urine is typically needed for the test?
PersonA: Usually, only small amounts of urine, ranging from 30 to 60 ml, are
required for urinalysis testing. It's a non-invasive and relatively simple test
that provides valuable information about your health.
role-user:
Given the following conversation between PersonU and PersonA:
{multi-turn QA conversation}
Modify PersonU's questions to use pronouns or common nouns to refer back to words
or phrases in PersonU's previous questions or PersonA's previous responses.
role-assistant:C 关于对话 QA 中检索的更多细节和结果
C.1 GPT-3.5-Turbo 的查询重写提示
我们为 GPT-3.5-Turbo 使用的上下文少样本查询重写提示如下:
You are a helpful, pattern-following assistant.
role-user:
Given the following conversation between PersonU and PersonA:
PersonU: Hello, I would like to know what to do if I do not agree with any decision.
PersonA: disagree with our decision about your monthly income adjustment amounts?
PersonU: no. Where can I find my SHIP contact information?
PersonA: You can find your local SHIP contact information in the back of your
Medicare & You 2020 Handbook online.
PersonU: and how do they calculate the adjustments?
Instead of having this entire conversation, how can PersonU get what he or she is
looking for using a single question? Respond with that question.
role-assistant:
How is the calculation for adjustments made by SHIP determined?
role-user:
Given the following conversation between PersonU and PersonA:
PersonU: I need to know how to prepare for college.
PersonA: You should first define your goals and interest and be sure to know the
costs and how to plan financially and academically for college.
PersonU: Is there something I can use as a guide to get ready for it?
Instead of having this entire conversation, how can PersonU get what he or she is
looking for using a single question? Respond with that question.
role-assistant:
What resources or guides can I use to help me prepare for college?
role-user:
Given the following conversation between PersonU and PersonA:
{Dialogue History + Latest Question}
Instead of having this entire conversation, how can PersonU get what he or she is
looking for using a single question? Respond with that question.
role-assistant:C.2 对话 QA 中检索的更多结果
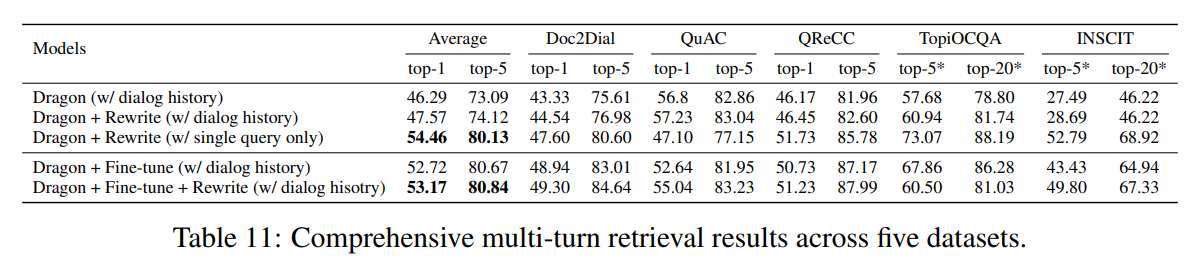
在表 11 中,我们展示了微调和重写方法之间的全面比较。
有趣的是,我们发现与仅使用重写查询作为输入(Dragon + Rewrite(仅单查询))相比,提供额外的对话历史(Dragon + Rewrite(有对话历史))会使平均得分显著下降。这是因为 Dragon 最初是在单轮查询上进行预训练的,当提供单轮重写查询而非多轮对话时,它自然会有更好的泛化能力。而且重写查询已经包含了来自对话历史的足够信息。
此外,我们观察到 "Dragon + Fine-tune" 与 "Dragon + Fine-tune + Rewrite" 表现相当。换句话说,对于多轮微调方法,将原始查询替换为重写查询作为输入会产生相似的结果。这是因为重写查询不会为模型提供太多额外的信息,因为对话历史已经被提供,而且它可能会产生负面效果(例如,TopiOCQA 数据集上的结果),因为它使整个对话输入显得不自然。这再次证明了微调方法在使模型具备理解多轮上下文的能力方面是多么有效。
D f CHATRAG BENCH的细节
D.1 数据统计
略
D.2 表格作为上下文的细节
我们使用 Markdown 格式来处理文档中的表格(即使用|分隔表格中的每个单元格)。然而,随着表格行数的增加,模型更难将最后几行的单元格值与表格中对应的标题关联起来。为了解决这个问题,我们将标题附加到每一行的相应单元格值中,以便于模型更容易捕捉单元格与其各自标题之间的联系。例如,一个原始的 Markdown 表格
| Boat | Crew | Nation | Date | Meet | Location |
| M1x | Mahe | FR | 2009 | | Poznan |
| M2- | Hamish | US | 2012 | Olympics | Lucerne |
| M2+ | Igor | DE | 1994 | | Indianapolis |会转换成:
| M1x (Boat) | Crew: Mahe | Nation: FR | Date: 2009 | Meet: | Location: Poznan |
| M2- (Boat) | Crew: Hamish | Nation: US | Date: 2012 | Meet: Olympics | Location: Paris |
| M2+ (Boat) | Crew: Igor | Nation: DE | Date: 1994 | Meet: | Location: Indianapolis |其他略了,太长了。
H 人工标注的对话QA数据
H.1 用户-代理对话回合的统计
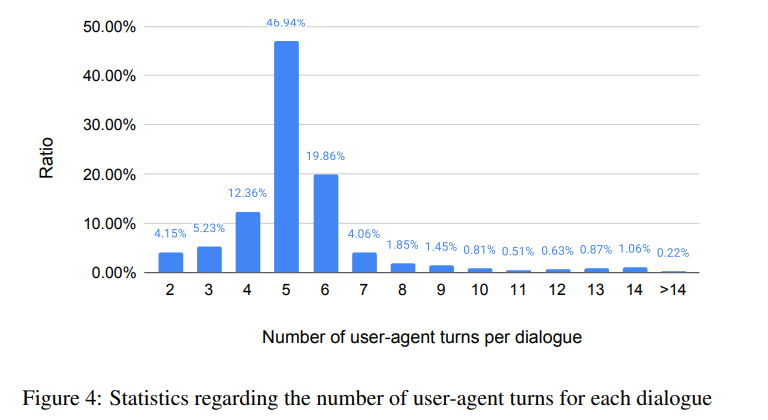
图4展示了在7000条人工标注的对话QA数据中,每个对话的用户-代理对话回合数的统计情况。
H.2 对话QA数据收集的指南
在这一部分,我们展示了用于对话QA数据收集的指南。我们要求标注员同时扮演用户和代理的角色,以基于提供的文档构建对话QA样本,从而提高标注效率。指南包括三个部分:1)对话QA样本的样子;2)我们需要什么样的对话QA样本;3)我们需要标注什么内容。
H.2.1 对话QA样本的样子
一个对话QA样本是基于我们提供的文档的。用户和代理的行为如下:
-
用户行为:
- 根据提供的文档向代理提问;
- 当代理需要澄清某些内容时,回答代理的问题。
-
代理行为:
- 根据文档回答用户的问题;
- 当用户的问题不清楚或过于笼统时,向用户提问。
H.2.2 我们需要的多轮QA样本类型
我们列出了用户提问和代理响应的要求。
用户的提问
- 用户的问题可以参考他/她之前的问题(或几轮之前的问题)。
- 用户的问题也可以参考代理之前的回答(或几轮之前的回答)。
- 尽量使用代词或常用名词替代之前提到的实体。
- 尽量使用户的问题多样化。对于相同类型的问题,尝试在不同的对话标注中使用不同的表达方式。
- 其他用户问题类型:
- 基于代理的回答,要求额外信息(例如,"还有什么......?"、"其他的......?"、"是否有更多......?")。
- 切换话题,开始新的对话主题。
- 同时提出两个问题。
代理的回答
- 尽量将代理的回答控制在1-2句话内。如果回答必须较长,尽量使其简洁。
- 尽量不要直接复制文档中相关上下文的全部内容作为答案。相反,尝试通过改述选择的上下文来构建答案。
- 尽量构建一小部分情况,其中代理向用户提问以澄清某些内容。具体来说,当用户的问题过于广泛或不清楚时,代理需要通过提问来缩小范围,以了解用户更关心哪些具体方面。
H.2.3 我们需要标注的内容
我们列出了每个对话需要标注的内容:
- 对于每个文档,我们需要标注用户的问题及其对应的代理回答。每个对话的用户-代理对话回合的平均数需要保持在五回合左右。
- 对于每个用户的问题,我们需要标注文档中的所有相关上下文。
总结
⭐ 作者介绍了 ChatQA,一种两阶段指令微调方法,提高了 RAG 的表现。还引入了一种针对多轮对话 QA 优化的密集检索器。