在神经辐射场(NeRF)技术 revolutionize novel-view synthesis(新视角合成)领域后,如何在保证渲染质量的同时实现实时交互,是学术界和工业界共同的核心诉求之一。传统 NeRF 方法虽能生成高质量渲染结果,但训练和渲染耗时极高;而后续的快速方法(如 InstantNGP、Plenoxels)又往往在质量上做出妥协。2023 年发表于 ACM Trans. Graph. 的论文《3D Gaussian Splatting for Real-Time Radiance Field Rendering》提出了一种颠覆性方案,通过创新性的 3D 高斯场景表示与高效渲染管线,首次实现了 "顶尖质量 + 实时渲染 + 快速训练" 的三重突破。
原文链接:https://arxiv.org/pdf/2308.04079
代码链接:https://github.com/graphdeco-inria/gaussian-splatting
沐小含持续分享前沿算法论文,欢迎关注...
一、论文核心贡献与定位
1.1 研究背景与痛点
辐射场(Radiance Field)方法通过连续的场景表示,能够从多张输入图像中合成逼真的新视角,但长期面临三大矛盾:
- 质量与速度的权衡:顶尖质量方法(如 Mip-NeRF360)需 48 小时训练,渲染帧率仅 0.071 fps,无法满足实时需求;
- 场景适应性局限:快速方法(如 InstantNGP、Plenoxels)在无界场景、1080p 高分辨率下难以兼顾速度与质量;
- 表示效率不足:基于体素网格或哈希编码的方法,在空区域存在冗余计算,且难以精准表示复杂几何结构。
1.2 核心贡献
论文提出三大关键创新,构建了端到端的高效辐射场渲染系统:
- 各向异性 3D 高斯表示:将场景建模为无结构的 3D 高斯集合,兼具连续体素表示的优化灵活性与点云表示的渲染高效性;
- 自适应密度控制的优化策略:通过高斯的克隆、分裂与剪枝,动态调整场景表示的密度,在保证精度的同时控制模型规模;
- 实时可微光栅化器:基于瓦片排序的 GPU 加速渲染管线,支持各向异性高斯的可见性感知混合,实现 1080p 分辨率下 ≥30 fps 的实时渲染与高效反向传播。
1.3 性能亮点
如图 1 所示,该方法在核心指标上全面超越现有方案:
- 渲染速度:最高 135 fps(1080p),远超 Mip-NeRF360(0.071 fps)和 InstantNGP(9.2 fps);
- 训练时间:51 分钟即可达到 SOTA 质量,与 InstantNGP(7 分钟)相当,远快于 Mip-NeRF360(48 小时);
- 渲染质量:PSNR 达 25.2,略优于 Mip-NeRF360(24.3),在细节还原上表现更优。

二、相关工作综述
论文从三个核心方向梳理了相关工作,明确了自身的技术定位:
2.1 传统场景重建与渲染
- 光场与 SfM/MVS:早期光场方法(如 Lumigraph)依赖密集采样,SfM(运动恢复结构)生成稀疏点云,MVS(多视图立体匹配)实现稠密重建,但这些方法难以处理未重建区域或过重建伪影,且需存储大量输入图像;
- 神经渲染的优势:近年神经渲染方法通过隐式表示减少伪影,避免了输入图像的冗余存储,在多数场景下性能超越传统方法。
2.2 神经渲染与辐射场
- NeRF 及其变体:NeRF 引入位置编码与重要性采样,通过 MLP 建模连续辐射场,但训练和渲染速度极慢;Mip-NeRF360 优化了抗锯齿与无界场景适应性,成为质量标杆,但耗时依旧高昂;
- 快速辐射场方法:InstantNGP 采用哈希网格编码,Plenoxels 基于稀疏体素网格,均通过空间离散化减少 MLP 依赖,提升训练速度,但结构化网格难以高效表示空区域,且渲染速度仍未达到实时。
2.3 基于点的渲染与辐射场
2.3.1 传统点云渲染
基于点的渲染方法以非结构化的点云为核心,高效处理离散几何样本的可视化问题 Gross and Pfister 2011。其最基础的形式是点采样渲染 Grossman and Dally 1998,直接将无结构点集以固定尺寸光栅化,可借助图形 API 原生支持的点类型 Sainz and Pajarola 2004 或 GPU 并行软件光栅化技术 Laine and Karras 2011; Schütz et al. 2022 提升效率。但这种基础方法存在明显缺陷,易产生孔洞、锯齿等 artifacts,且本质上是不连续的表示形式。
为解决这些问题,基于点的高质量渲染研究通过 "喷洒(splatting)" 技术进行改进 ------ 将点基元扩展为大于像素的形状,如圆形 / 椭圆形圆盘、椭球体或表面元(surfels)Botsch et al. 2005; Pfister et al. 2000; Ren et al. 2002; Zwicker et al. 2001b,从而提升渲染连续性与视觉质量。
2.3.2 可微点渲染
近年来,可微点基渲染技术受到广泛关注 Wiles et al. 2020; Yifan et al. 2019。这类方法为点添加神经特征,并通过 CNN 完成渲染 Aliev et al. 2020; Rückert et al. 2022,实现了快速甚至实时的新视角合成。但它们普遍依赖多视图立体匹配(MVS)获取初始几何结构,因此继承了 MVS 的固有缺陷 ------ 在无特征区域、反光表面或细薄结构等复杂场景中,易出现过重建或欠重建问题。
值得注意的是,基于点的 α 混合与 NeRF 风格的体积渲染,本质上采用相同的图像生成模型。具体而言,NeRF 的体积渲染颜色 C 通过沿光线积分计算:
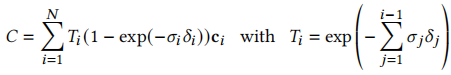
其中为密度、T为透射率、c为颜色,
为采样间隔。该公式可改写为:
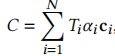
其中
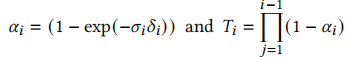
而典型的神经点基方法(如 Kopanas et al. 2022, 2021)通过混合像素重叠的有序点集计算颜色:

其中为点的颜色,
由 2D 高斯协方差 Σ 的评估结果与学习到的逐点不透明度相乘得到。
从公式推导可见,两者的图像生成模型完全一致,但渲染算法存在本质区别:
- NeRF 采用连续表示,隐式建模空区域与占用区域,需通过昂贵的随机采样获取积分样本,易产生噪声且计算成本高;
- 点基表示为非结构化离散形式,可灵活创建、销毁和移动几何元素,兼具 NeRF 的优化灵活性,同时避免了完整体积表示的冗余计算。
2.3.3 与本文的区别
现有方法或依赖结构化表示,或受限于初始化方式,而本文的 3D 高斯表示无需 MVS 数据,且通过各向异性优化与高效光栅化,兼顾了质量、速度与灵活性。
三、方法总览
本文方法的核心思路是:用无结构的 3D 高斯集合建模辐射场,通过自适应优化调整高斯分布,再利用 GPU 加速的瓦片化光栅化实现实时渲染。整体流程如图 2 所示,分为三个关键阶段:
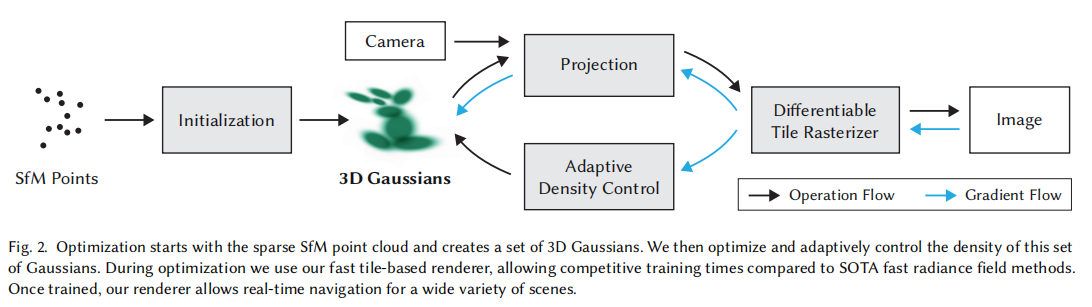
- 输入与初始化:输入多张静态场景图像及 SfM 校准后的相机参数,从 SfM 输出的稀疏点云初始化 3D 高斯集合;
- 优化与密度控制:交替优化高斯的位置、不透明度、各向异性协方差和球谐系数(SH),同时通过克隆、分裂、剪枝动态调整高斯密度;
- 实时渲染:将 3D 高斯投影为 2D 椭圆,通过瓦片排序、可见性感知混合,实现高效光栅化与新视角合成。
四、可微 3D 高斯表示
这是模型的 "数据结构核心",场景被表示为 100 万 - 500 万个独立的 3D 高斯基元,每个高斯仅包含自身的可学习参数(无参数共享)。
4.1 高斯的数学定义
3D 高斯是本文的核心渲染基元,每个高斯由以下参数定义:
- 均值(μ):3D 空间中的位置;
- 协方差矩阵(Σ):描述高斯的形状与方向,支持各向异性;
- 不透明度(α):控制高斯对最终像素颜色的贡献权重;
- 球谐系数(SH):建模视角相关的颜色外观。
3D 高斯的概率密度函数为:
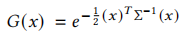
其中, 为 3D 空间中的任意点。该表示的核心优势在于:
- 可微性:所有参数均可通过梯度下降优化;
- 灵活性:协方差矩阵支持各向异性,能紧凑表示复杂几何(如细长结构、曲面);
- 高效投影:可直接投影为 2D 椭圆,适配光栅化渲染。
4.2 协方差矩阵的优化表示
协方差矩阵需满足正定半定约束,直接优化易导致数值不稳定。论文采用 "缩放 + 旋转" 的分解表示,规避约束问题:
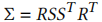
其中:
- S 是对角缩放矩阵,由 3D 向量 s 控制(s₁, s₂, s₃ 分别对应三个轴的缩放系数);
- R 是旋转矩阵,由四元数 q 表示(保证旋转的有效性)。
这种分解将协方差优化转化为对 s(缩放)和 q(旋转)的无约束优化,既保留了各向异性的表达能力,又确保了数值稳定性。
4.3 3D 到 2D 的投影
渲染时需将 3D 高斯投影到图像平面,转化为 2D 椭圆。投影过程如下:
-
通过相机外参 W 将 3D 高斯转换到相机坐标系;
-
利用投影变换的仿射近似雅可比矩阵 J,计算相机坐标系下的协方差矩阵 Σ':
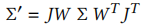
-
忽略 Σ' 的第三行第三列(深度维度),得到 2D 协方差矩阵,用于定义图像平面上的椭圆形状。
该投影过程完全可微,确保渲染结果能反向传播梯度,优化 3D 高斯参数。
五、带自适应密度控制的优化
5.1 优化目标与损失函数
优化的核心目标是最小化渲染图像与输入图像的差异,采用 损失与 D-SSIM 损失的加权组合:
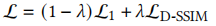
其中 λ=0.2,D-SSIM 用于增强结构相似性约束,提升渲染质量。
5.1.1  损失()
损失()
- 定义:衡量渲染图像与真实图像的像素级绝对差异,对异常值(如噪声、局部 artifacts)的鲁棒性优于
- 计算过程:
- 设渲染图像为
- 对每个像素的每个通道,计算渲染值与真实值的绝对差;
- 对所有像素、所有通道的绝对差取平均值,得到最终的
- 设渲染图像为
5.1.2 D-SSIM 损失()
- 定义:基于 SSIM(结构相似性指数)的损失形式,SSIM 原本用于衡量两幅图像的结构相似度(取值范围 0,1,越接近 1 结构越一致),D-SSIM 通过
- 核心作用:弥补
- 计算过程(遵循标准 SSIM 推导,论文未修改核心逻辑):
- 对图像进行局部窗口滑动(通常使用 11×11 高斯窗口),计算每个窗口内的三项指标:
- 亮度对比(Luminance):窗口内像素的均值差异;
- 对比度对比(Contrast):窗口内像素的标准差差异;
- 结构对比(Structure):窗口内像素的协方差与标准差乘积的比值;
- 结合三项指标计算单个窗口的 SSIM 值:
- 对所有窗口的 SSIM 值取平均值,再通过
- 对图像进行局部窗口滑动(通常使用 11×11 高斯窗口),计算每个窗口内的三项指标:
5.2 优化参数与激活函数
优化的参数包括:
- 位置(μ):初始化为 SfM 稀疏点位置,采用指数衰减学习率调度;
- 不透明度(α):通过 sigmoid 激活约束在 [0,1) 区间,确保平滑梯度;
- 缩放(s):通过指数激活确保非负性;
- 球谐系数(SH):建模视角相关颜色,支持多阶展开(最高 4 阶)。
5.3 自适应密度控制策略
为解决初始稀疏点云难以覆盖复杂场景的问题,论文设计了 "克隆 - 分裂 - 剪枝" 的动态密度调整机制,在优化过程中交替进行(每 100 次迭代执行一次):
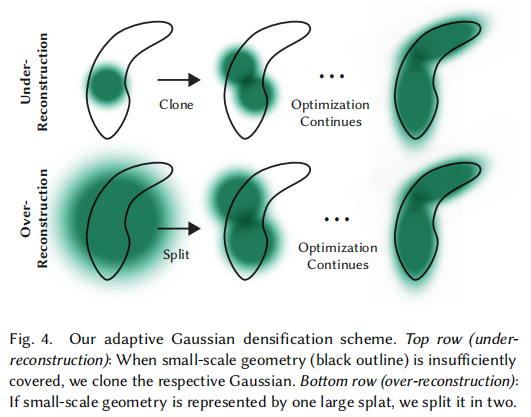
5.3.1 剪枝(Pruning)
移除无效高斯:
- 不透明度阈值:
- 尺寸阈值:世界空间中过大或图像空间中覆盖范围过大的高斯,避免冗余。
5.3.2 克隆(Cloning)
针对 "欠重建" 区域(小高斯、位置梯度大):
- 检测条件:高斯尺寸较小(
- 操作:复制该高斯,沿位置梯度方向轻微偏移,增加局部高斯密度,覆盖细小组件。
5.3.3 分裂(Splitting)
针对 "过重建" 区域(大高斯、位置梯度大):
- 检测条件:高斯尺寸较大(
- 操作:将该高斯分裂为两个新高斯,缩放系数除以 1.6(实验确定),位置基于原高斯的概率密度采样,细化场景表示。

该机制最终使场景表示保持在 100 万 - 500 万个高斯,在精度与紧凑性之间取得平衡。
六、高斯的快速可微光栅化器
光栅化器是论文实现 "实时渲染 + 高效优化" 的核心引擎,其设计目标是解决传统辐射场渲染中 "质量、速度、可微性" 难以兼顾的问题。该模块基于 GPU 硬件加速,通过 "瓦片划分、全局排序、可见性感知混合" 的创新流程,实现了各向异性 3D 高斯的快速光栅化,同时支持无限制的梯度反向传播,为端到端优化提供了关键支撑。
6.1 核心设计目标
论文明确了光栅化器的四大核心诉求,直接针对现有方法的短板:
- 实时渲染能力:在 1080p 分辨率下实现 ≥30 fps 的渲染帧率,满足交互式新视角合成需求;
- 可见性感知的 α-blending:正确处理高斯间的遮挡关系(前层遮挡后层),同时支持各向异性高斯的灵活混合,保证渲染质量;
- 无限制可微性:避免传统方法中 "限制梯度传播的高斯数量" 的设计,支持任意数量高斯的梯度反向传播,适配复杂场景的深度复杂度;
- 低内存开销:通过工程优化减少内存占用,避免动态内存管理带来的性能损耗,确保大规模场景下的可行性。
这些目标直接决定了光栅化器的整体架构 ------ 放弃逐像素排序和体素射线行进,采用 "全局排序 + 瓦片并行" 的设计,平衡速度与精度。
6.2 核心流程:从 3D 高斯到 2D 图像的光栅化链路
光栅化器的核心逻辑是将无结构的 3D 高斯集合,通过 "剔除→投影→排序→混合" 四步,转化为 2D RGB 图像,全程依托 GPU 并行计算加速。流程严格遵循论文 Algorithm 2(GPU 软件光栅化算法),具体步骤如下:

步骤 1:视锥体剔除与极端位置过滤
首先过滤对当前视角无贡献的高斯,减少无效计算,这是提升渲染效率的基础:
- 视锥体剔除:仅保留 99% 置信区间与相机视锥体相交的高斯。高斯的 99% 置信区间由其 3D 协方差矩阵定义(对应椭球体范围),通过几何判断该椭球体是否与视锥体(相机可见区域)重叠,重叠则保留;
- 极端位置过滤:引入 "保护带(guard band)" 机制,直接剔除均值靠近近平面或远超出视锥体的高斯。这类高斯的 2D 投影协方差计算易出现数值不稳定,过滤后可提升渲染鲁棒性;
- 核心作用:将参与后续计算的高斯数量减少 30%-50%(依场景而定),大幅降低计算开销。
步骤 2:3D 高斯到屏幕空间的变换
将保留的高斯从世界空间转换到屏幕空间,为后续排序和混合提供几何基础,该过程完全可微:
- 几何变换 :通过相机外参矩阵 W 将高斯的 3D 位置(
- 协方差投影 :计算屏幕空间的协方差矩阵
- 输出结果:每个高斯对应屏幕空间的 "2D 椭圆参数(
步骤 3:瓦片划分与高斯实例化
为最大化 GPU 并行效率,引入 "瓦片(tile)" 概念,将屏幕空间分割为 16×16 像素的独立单元,适配 GPU 线程块的并行粒度:
- 瓦片划分:例如 1920×1080 分辨率的图像,可划分为 120×68=8160 个瓦片,每个瓦片独立处理,避免线程间数据依赖;
- 高斯实例化:每个高斯可能覆盖多个瓦片(如一个大尺寸高斯横跨 3 个瓦片),因此为每个高斯覆盖的瓦片生成对应的 "高斯实例"。每个实例包含原高斯的所有参数(颜色、不透明度、椭圆参数),并绑定对应的瓦片 ID;
- 核心作用:将全局高斯集合分解为多个瓦片的局部集合,使每个线程块仅处理一个瓦片的高斯实例,提升并行效率,减少内存访问延迟。
步骤 4:全局排序:按 "深度 + 瓦片 ID" 排序
排序是实现可见性感知混合的关键,论文采用 GPU 快速基数排序(Radix Sort),一次性解决所有高斯实例的顺序问题,避免逐像素排序的高开销:
- 排序键设计:为每个高斯实例分配 64 位排序键,格式为 "高 32 位:瓦片 ID + 低 32 位:投影深度";
- 高 32 位:编码高斯实例所属的瓦片 ID,确保排序后同一瓦片的高斯实例连续存放;
- 低 32 位:编码高斯在相机空间的投影深度(
- 全局基数排序:调用 NVIDIA CUB 库的快速基数排序接口(Merrill and Grimshaw 2010),对所有高斯实例按排序键全局排序。基数排序的时间复杂度为 O (N log N)(N 为高斯实例总数),且完全并行化,GPU 上处理百万级实例仅需毫秒级时间;
- 排序后效果:同一瓦片内的高斯实例按深度从前到后连续排列,后续混合时直接按此顺序遍历,无需逐像素排序,彻底解决了传统点基渲染中 "逐像素排序开销大" 的痛点。
步骤 5:瓦片范围识别与线程分配
排序后需快速定位每个瓦片对应的高斯实例范围,为并行混合做准备:
- 瓦片范围识别:遍历排序后的高斯实例数组,通过比较相邻实例的 "瓦片 ID"(排序键高 32 位),确定每个瓦片对应的实例起始索引和结束索引。例如,瓦片 T0 对应的实例范围为 [start0, end0),瓦片 T1 对应的范围为 [start1, end1),以此类推;
- 线程分配:为每个瓦片分配一个 GPU 线程块(thread block),线程块内的线程协作处理该瓦片内的所有像素(16×16=256 像素,对应 256 个线程,1 线程处理 1 像素);
- 核心优化:范围识别过程通过 GPU 并行实现(1 线程处理 64 位排序键),避免 CPU 参与,确保流程端到端 GPU 加速。
步骤 6:瓦片内逐像素 α-blending 颜色混合
这是生成 2D 图像的核心步骤,线程块内按排序后的高斯顺序,逐像素累积颜色和不透明度,完全遵循辐射场的体积渲染模型:
- 共享内存加载:线程块首先将该瓦片对应的高斯实例批量加载到 GPU 共享内存(shared memory)。共享内存的访问速度是全局内存的 10-100 倍,可大幅减少内存访问延迟;
- 逐像素遍历与椭圆覆盖判断:每个线程(对应一个像素)按 "从前到后" 的顺序遍历瓦片内的高斯实例,首先判断当前高斯的 2D 椭圆是否覆盖该像素。判断逻辑基于像素坐标与椭圆参数的几何关系(通过二次型计算实现快速判断),未覆盖则跳过该高斯;
- 颜色解码与混合计算:对覆盖当前像素的高斯,执行两步计算:
- 颜色解码:根据当前相机视角,将高斯的球谐系数(SH)解码为 RGB 颜色
- α-blending 累积:按辐射场体积渲染公式累积像素颜色,核心公式为:
- 颜色解码:根据当前相机视角,将高斯的球谐系数(SH)解码为 RGB 颜色
- 早停机制 :当像素的累积不透明度(
- 瓦片整合:所有像素混合完成后,该瓦片的 16×16 像素颜色被写入全局内存的画布(canvas),所有瓦片处理完毕后,画布即构成完整的 2D RGB 图像。
6.3 关键技术:可微性实现与梯度反向传播
光栅化器的可微性是端到端优化的核心 ------ 损失函数的梯度需通过光栅化过程反向传播到 3D 高斯的所有参数(位置、协方差、不透明度、SH 系数)。论文设计了 "反向遍历 + 中间透射率恢复" 的策略,既保证可微性,又避免额外内存开销,具体实现如下:
6.3.1 正向传播的关键存储
为支持反向传播,正向传播时仅额外存储一项关键信息:每个像素的最终累积不透明度(final accumulated opacity)。无需存储逐像素的高斯混合列表,大幅降低内存占用,这是该方法的核心优化之一。
6.3.2 反向传播的核心逻辑
反向传播的目标是计算损失函数对每个高斯参数的梯度(、
等),核心步骤如下:
- 反向遍历瓦片内高斯:线程块按 "从后到前" 的顺序遍历瓦片内的高斯实例(与正向传播的 "从前到后" 相反);
- 像素参与判断:每个像素仅处理深度 ≤ 正向传播中最后一个贡献高斯深度的实例。这是因为深度大于该值的高斯未对像素颜色产生贡献,梯度为 0,可直接跳过;
- 中间透射率恢复 :梯度计算需要正向传播中每个高斯的中间透射率
- 设正向传播中像素的最终累积不透明度为
- 设正向传播中像素的最终累积不透明度为
- 梯度计算与传播 :基于恢复的
6.3.3 无限制可微性的优势
与 Pulsar 等方法限制 "仅前 N 个高斯参与梯度传播" 不同,本文方法支持任意数量高斯的梯度传播,无需场景特异性超参数调优。这使得方法能适配深度复杂度高的场景(如茂密植被、室内多物体遮挡),避免因梯度截断导致的质量损失。
6.4 工程优化:并行效率与数值稳定性保障
光栅化器的实时性能不仅依赖算法设计,还得益于多项关键工程优化,论文详细披露了以下核心实现细节:
6.4.1 并行效率优化
- 基数排序的高效应用:采用 NVIDIA CUB 库的 Radix Sort 接口,支持百万级高斯实例的毫秒级排序。排序键的 "瓦片 ID + 深度" 设计,确保排序后同一瓦片的高斯连续存放,减少后续范围识别的开销;
- 线程块与瓦片的精准匹配:每个线程块处理一个 16×16 瓦片,与 GPU 线程块的 warp 调度(通常 32 线程)高度适配。线程块内通过协作加载共享内存,避免线程间竞争,提升内存访问效率;
- 范围识别的并行实现:通过 1 线程处理 1 个排序键的方式,并行比较相邻排序键的瓦片 ID,快速定位每个瓦片的高斯实例起始和结束索引,避免串行遍历的低效。
6.4.2 数值稳定性保障
反向传播中的除法操作易出现数值不稳定(如除以 0),论文通过三项设计规避:
- 低不透明度跳过 :正向和反向传播中,均跳过
- 不透明度上界限制 :α clamping 到 0.99,防止
- 混合早停阈值:正向传播中,当累积不透明度达到 0.9999 时停止混合,避免过度饱和导致的数值精度损失。
七、实现细节与实验结果
7.1 实现细节
- 框架:基于 PyTorch 实现,核心光栅化逻辑采用自定义 CUDA 内核;
- 初始化:SfM 稀疏点云初始化,协方差矩阵初始化为各向同性(轴长为最近三个点的平均距离);
- SH 优化策略:先优化 0 阶 SH(漫反射颜色),每 1000 次迭代增加一阶,直到 4 阶,避免角度信息缺失导致的颜色失真;
- 分辨率调度:优化初期使用 1/4 分辨率热身,250 次和 500 次迭代后两次上采样至原始分辨率,提升稳定性。
7.2 实验设置
- 硬件:NVIDIA A6000 GPU(除 Mip-NeRF360 采用 4 卡 A100 外);
- 数据集:
- 真实场景:Mip-NeRF360(10 个场景)、Tanks&Temples(2 个场景)、Deep Blending(2 个场景);
- 合成场景:Blender NeRF(8 个场景);
- 对比方法:Mip-NeRF360(质量标杆)、InstantNGP(快速方法标杆)、Plenoxels(无神经网络方法标杆);
- 评价指标:PSNR(峰值信噪比)、SSIM(结构相似性)、LPIPS(感知相似度)、渲染帧率(fps)、训练时间、内存占用。
7.3 定量结果
7.3.1 真实场景性能对比(表 1)

关键结论:
- 质量:Ours-30K 的 PSNR/SSIM 与 Mip-NeRF360 相当(甚至略优),远超 InstantNGP 和 Plenoxels;
- 速度:训练时间仅 36-41 分钟,渲染帧率达 134-154 fps,实现实时交互;
- 内存:模型占用 411-734 MB,虽高于 NeRF 类方法,但远低于稠密点云方法。
7.3.2 合成场景性能对比(表 2)
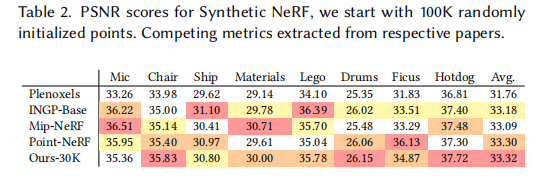
即使在随机初始化(无 SfM 点云)的合成场景中,本文方法仍达到 SOTA 水平,验证了表示的灵活性。
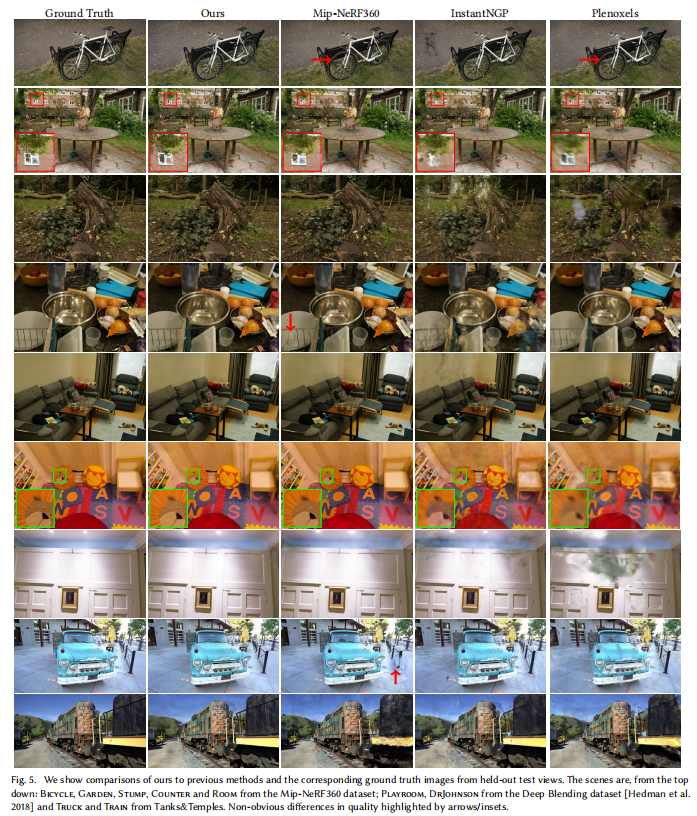
7.4 定性结果
7.5 消融实验(对应原文 Table 3)
为验证各核心组件的必要性,论文进行了消融实验:
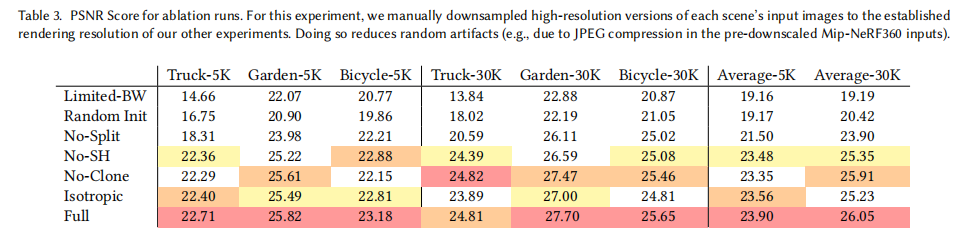
关键结论:
-
梯度传播无限制:限制最大混合数(Limited-BW)导致 PSNR 下降 7dB,验证了无梯度限制的重要性;
-
自适应密度控制:分裂(Split)和克隆(Clone)分别提升 2.4dB 和 0.14dB,共同确保场景覆盖,可视化如图;

-
各向异性高斯:Isotropic 配置比 Full 低 0.82dB,验证了各向异性对复杂几何表示的必要性;
-
SfM 初始化:Random Init 比 Full 低 3.73dB,说明 SfM 点云能提供有效先验,加速收敛,可视化如下图。

八、局限性与未来工作
8.1 局限性
- 未充分观测区域的伪影:在输入图像覆盖不足的区域,仍会出现浮点数或低细节问题(图 11);
- 闪烁与弹出伪影:优化过程中生成的大高斯可能导致视角切换时的弹出效应,源于光栅化中的简单可见性判断;
- 内存占用:训练时峰值内存可达 20GB(未优化原型),虽渲染时仅需数百 MB,但仍有优化空间;
- 超大型场景适配:对城市级等超大型场景,需调整位置学习率才能收敛。

8.2 未来工作
- 正则化优化:引入空间正则化,减少未观测区域的 artifacts;
- 抗锯齿与可见性优化:改进光栅化的可见性判断,加入抗锯齿,减少闪烁;
- 内存优化:采用点云压缩技术,进一步降低模型存储;
- 网格重建:基于 3D 高斯表示推导网格,桥接体素表示与表面表示;
- 动态场景扩展:将静态场景的高斯表示扩展到动态场景,支持实时动态新视角合成。
九、总结
《3D Gaussian Splatting for Real-Time Radiance Field Rendering》通过三大核心创新,首次实现了 "顶尖质量 + 实时渲染 + 快速训练" 的辐射场渲染方案:
- 3D 高斯表示:兼具连续表示的优化灵活性与离散表示的渲染高效性,各向异性协方差精准建模复杂几何;
- 自适应密度控制:克隆 - 分裂 - 剪枝机制动态调整高斯分布,平衡精度与紧凑性;
- 瓦片化可微光栅化器:GPU 加速的排序与混合,实现 1080p 实时渲染与无限制梯度传播。
该方法不仅在技术上突破了传统 NeRF 的速度瓶颈,更在实际应用中具备极高价值,为虚拟现实(VR)、增强现实(AR)、数字孪生等领域的实时 3D 重建与渲染提供了新的解决方案。其核心思想 ------"用无结构的灵活基元替代结构化网格,用高效光栅化替代体素射线行进"------ 也为后续辐射场研究提供了重要启示。