- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标:
具体实现 :
(一)环境 :
语言环境 :Python 3.10
编 译 器: PyCharm
框架: TensorFlow
**(二)具体步骤:
-
安装TensorFlow
第一次使用这个框架,先安装,打开官网:TensorFlow:

先把PIP升级到最新版本
$ pip install --upgrade pip
安装稳定版,支持CPU和GPU
$ pip install tensorflow
演示一下官方的代码看看能不能跑(我也看不懂是什么意思,就当是hello world,看看TF正常不):


跑成功了(下图),那说明我们安装也成功了。

下面就通过具体代码来熟悉熟悉TF的使用。
- 使用TensorFlow实现MNIST手写数字识别
2.1 设置GPU
一上来就整高阶的GPU运算,大家如果没有显卡 ,可以使用CPU(应该默认就是使用CPU),那么本步骤可以直接忽略.
import tensorflow as tf
print("可用的GPU数量: ", len(tf.config.list_physical_devices('GPU')))
我的机器明明有显卡,但是显示0,不管了,后面再研究。
选择GPU的代码:
import tensorflow as tf
print("可用的GPU数量: ", len(tf.config.list_physical_devices('GPU')))
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,则使用第0个GPU
tf.config.experiment.set_memory_growth(gpu0, True)
tf.config.set_variable_device([gpu0], "GPU")2.2 导入MINST数据
from tensorflow.keras import datasets, layers, models
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()2.3 归一化
# 归一化
train_images, test_images = train_images / 255.0, test_images / 255.0
#查看数据形状
print('train_images.shape:', train_images.shape)
print('test_images.shape: ', test_images.shape)
print('train_labels: ', train_labels.shape)
print('test_labels: ', test_labels.shape)
2.4 把数据可视化看看
# 显示数据集前50个图片数据看看
plt.figure(figsize=(20, 10)) # 将图片显示大小设置为 20宽,10长的大小 ,单位英寸(inch)
# 遍历MNIST数据集,下标0-49
for i in range(50):
# 将整个figure分成5行10列,绘制第i+1个子图
plt.subplot(5, 10, i+1)
plt.xticks([]) # 不显示X轴刻度
plt.yticks([]) # 不显示Y轴刻度
plt.grid(False) # 不显示网格线
plt.imshow(train_images[i], cmap=plt.cm.binary) # 显示图片
plt.xlabel(train_labels[i]) # 显示图片对应的数字(标签)
plt.show()
2.5 调整图片格式 (数据形状)
为啥要调整图片格式呢,导入数据的时候,图片的形状是这样的(60000, 28,28)意思是有6000张28X28像素的图片,现在要调整成(60000, 28, 28, 1)的形状,为啥要调整形状?因为神经网络使用的数量(图像表)它的形状应该是(样本数、宽、高、通道数),对应到(60000, 28, 28)就是样本数60000张图片,宽28,高28都有了,差一个通道数。按我的理解,MNIST数据集图片是单通道图片,因此后面应该通道数是1。可以先学习一下什么叫张量表示(张量简介 | TensorFlow Core):



再理解一张图片,通常是由RGB三通道构成的,如下:


# 调整数据格式,使用reshape来调整
test_images = test_images.reshape((60000, 28, 28, 1))
train_images = train_images.reshape((60000, 28, 28, 1))
# 查看数据形状
print('train_images.shape:', train_images.shape)
print('test_images.shape: ', test_images.shape)
print('train_labels: ', train_labels.shape)
print('test_labels: ', test_labels.shape)
格式已经调整过来了。有人可能问train_labels和test_labels怎么不调整格式,记住这两个不是图片,是标签值,不用调整。
2.6 构建CNN网络模型(重头戏)
CNN的概念 :Convolutional Neural Network,卷积神经网络)是一种前馈神经网络,特别适用于处理具有网格结构的数据,如图像或时间序列数据。CNN最初是为图像识别任务而设计的,但后来也被广泛应用于其他领域。
CNN的工作原理:CNN通过一系列方法成功将数据量庞大的图像识别问题不断降维,最终使其能够被训练。其工作原理主要包括以下几个部分:
-
卷积层:用于提取输入数据的局部特征。
-
池化层:用于降低特征的空间维度,减少计算量。
-
全连接层:用于分类或回归任务。
CNN的特点包括局部连接、权重共享和空间层次结构,这些特点使得CNN在处理图像等数据时非常高效。
CNN的应用领域 :由于CNN在图像识别方面的出色表现,它已经被广泛应用于各种图像处理任务中。此外,CNN也被应用于自然语言处理和语音识别等领域。近年来,随着深度学习的发展,CNN已经成为图像分类的黄金标准。
CNN的构建 :话说把一头大像装冰箱总共需要几步,也是三步:第一步打开冰箱门,第二步放进冰箱(怎么装时冰箱的你别管),第三步关上冰箱门。CNN的构建简单来讲就是三步,第一步准备数据集(输入层),第二步做卷积运算(怎么运算的,目前还是一个黑盒子),第三步是输出结果(输出层,我们期望它输出的内容)。输入和输出大家都已经清楚了,就是这个第二步一直没闹明白,这个黑盒子内部是怎么搞的,就这么神奇的实现了各种分类,归类。今天就是来实现第二步,看看怎么搞出来的。
CNN的模型 :其实第二步的黑盒子就是神经网络模型,而模型有千千万(你自己也可以搞,只是效果怎么样就不知道了),知名的有:

TF框架给了我们搭建模型的方法,我们就找一个模型来试试:

从左到右,一步一步通过TF的方法来实现这个神经网络模型,代码中解释:搭建模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),layers.Flatten(), layers.Dense(64, activation='relu'), layers.Dense(10)])
打印网络结构
print(model.summary())

解释 :
Conv2D:二维卷积层,基本都用这个。
activation='relu':激活函数使用ReLu函数。
MaxPooling2D: 池化层
Flatten:连接卷积层和全连接层。把张量展平。
Dense: 全连接层和输出层

2.6 编译模型
# 编译模型
model.compile(
optimizer="adam", # 设置优化器为Adam优化器
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy']2.7 训练模型
# 训练模型
history = model.fit(
# 输入训练集数据
train_images,
# 输入训练集标签
train_labels,
# 设置epoch为10,第一个epoch将会把所有数据输入模型完成一次训练
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels)
)
2.8 用这个网络模型来进行预测吧
找一张test_images里的照片先预测一下,看实际图片是什么:
plt.imshow(test_images[1]) # 上面的代码中test_images已经归一化了,可能显示不出来,可以使用归一化前的test_images看图片
拿这张照片预测一下:
pre = model.predict(test_images)
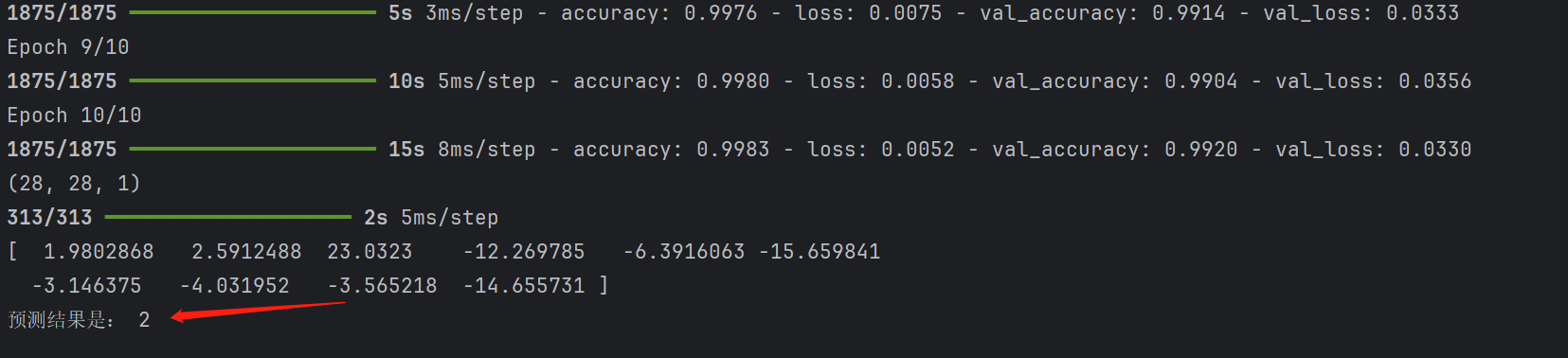
print(pre[1])
数值最大的是第3个数,按照对应,第3个数就是2(0,1,2...这个顺序)。所以预测是对的。
改进一下,直观一点:
# 预测
print(test_images[1].shape)
plt.imshow(test_images[1].reshape(28, 28))
pre = model.predict(test_images)
print(pre[1])
print("预测结果是:", np.argmax(pre[1]))