文章汇总
存在的问题
原文:具有图像特定知识的图像条件提示符号在提升类嵌入分布方面的能力较差。
个人理解:单纯把"a photo of {class}"这种提示模版作为输入是不利于text encoder学习的
动机
在可学习的提示和每一类的文本知识之间建立一种动态关系,以增强其辨别能力。
解决办法
之前方法的回顾
CoOp
CoCoOp
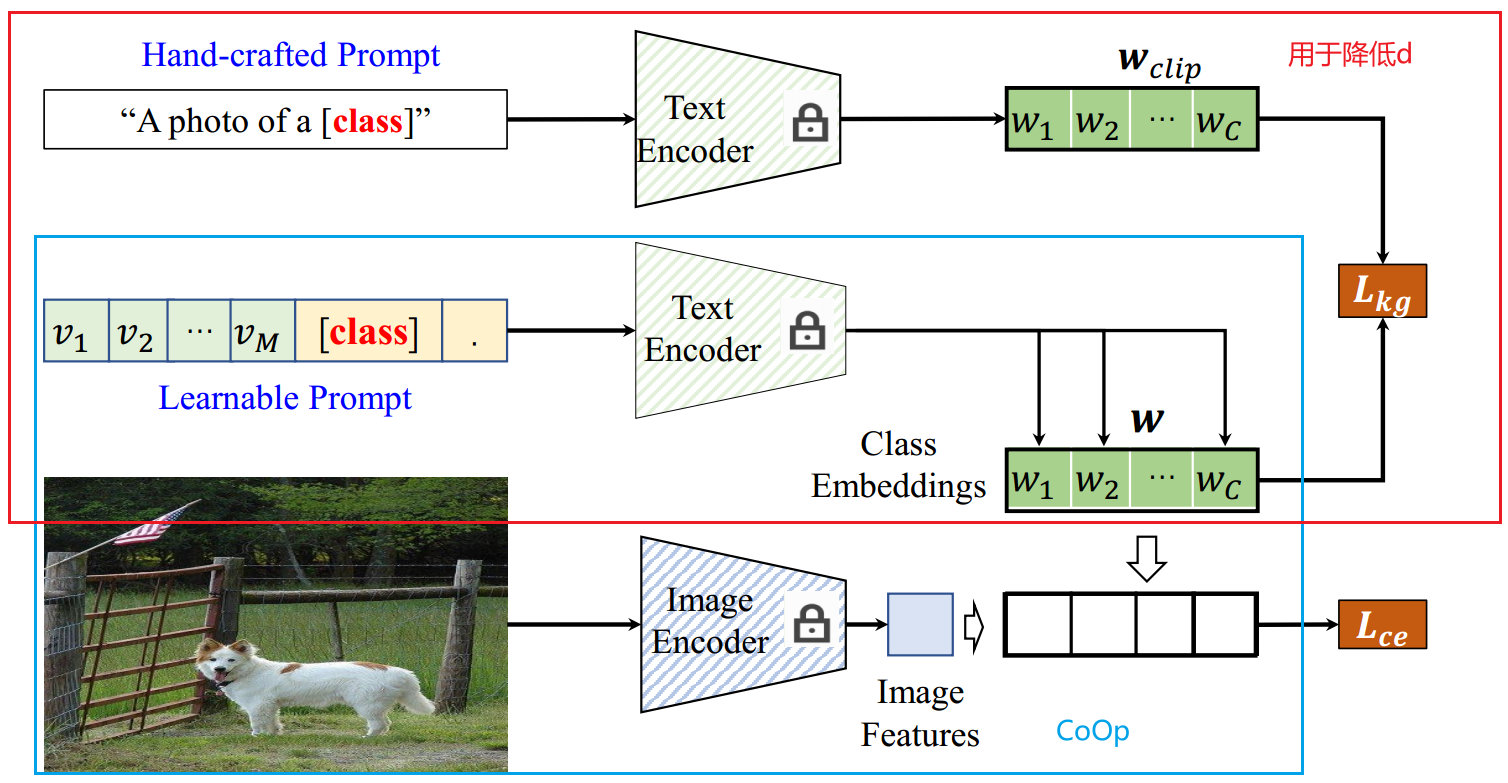
KgCoOp(本人觉得这是这篇文章的baseline)
方法框架图(对比KgCoOp)
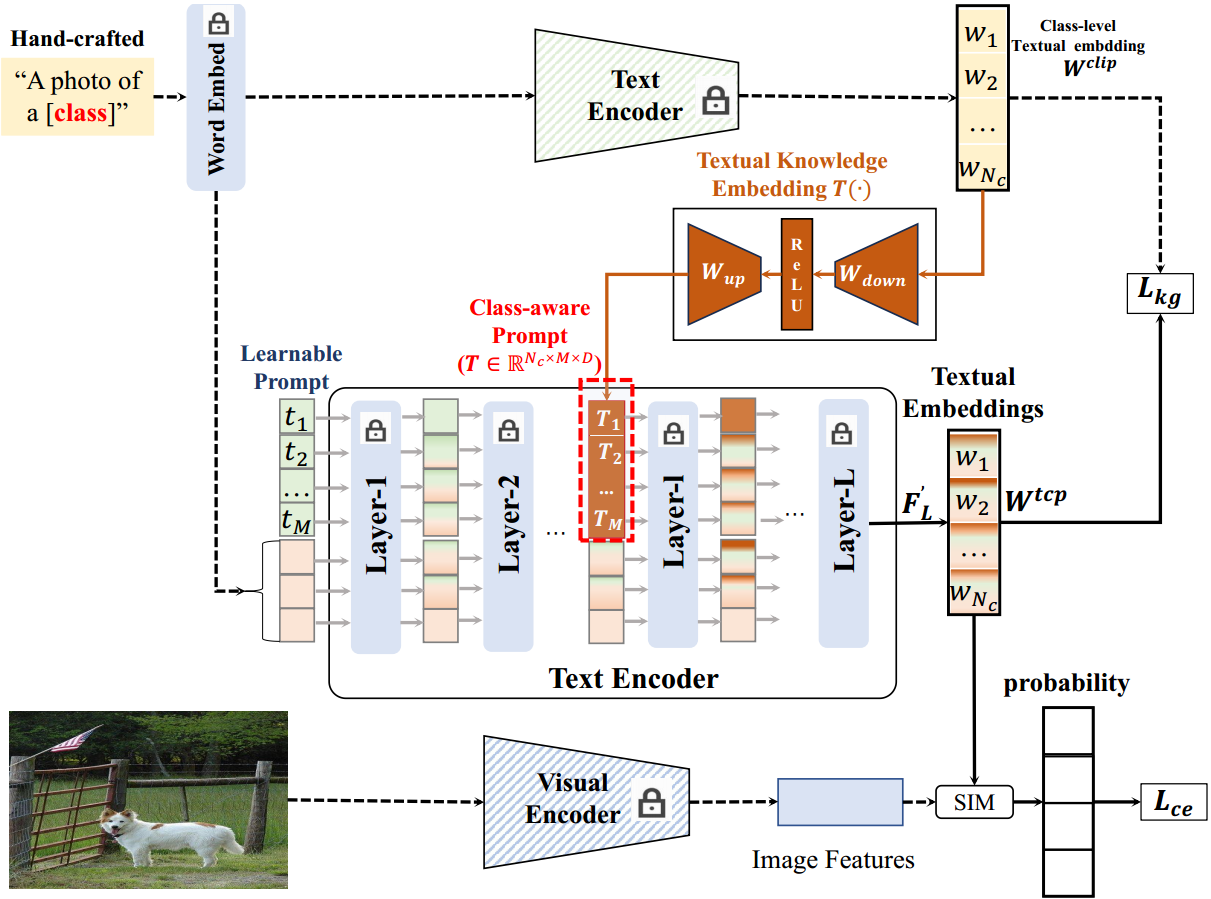
对比KgCoOp,其实你会发现就中间的text encoder进行了改造。
流程解读
中间的Text Encoder的改进
输入端
可学习文本标记 T = t 1 , t 2 , . . . , t M T=t_1,t_2,...,t_M T=t1,t2,...,tM和hand-crafted转化而来的类token C C C
Text Encoder的输入文本令牌: F 0 = { T , C } F_0=\{T,C\} F0={T,C}
其中 C = { c i } i N c C=\{c_i\}^{N_c}_i C={ci}iNc为第 i i i类的向量化文本令牌, N c N_c Nc为类的个数
特征转换
对于前 l l l层:
第 i i i层的文本令牌 F i ( i ≤ l ) F_i(i\le l) Fi(i≤l)定义为:
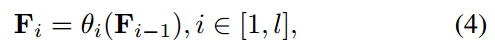
对于从第 l l l层开始就不同了
将之前放 t 1 , t 2 , . . . , t M t_1,t_2,...,t_M t1,t2,...,tM的位置换成了由 T ( ⋅ ) T(\cdot) T(⋅)生成的 T 1 , T 2 , . . . , T M T_1,T_2,...,T_M T1,T2,...,TM
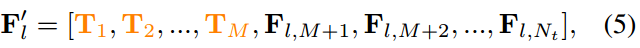
之后还是
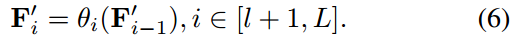
对于效果更好的思考
个人认为,直接随机初始化的Learnable Prompt很难跟hand-crafted的prompt建立起很好的联系。但是hand-crafted的prompt经过Text Encoder和 T ( ⋅ ) T(\cdot) T(⋅)之后更容易被Text Encoder接收。
那为什么我们还要在前 l l l层加入随机初始化的Learnable Prompt呢?这就有点像maple那样,前 l l l层像一个"适应期",使得模型知道要与 t 1 , t 2 , . . . , t M t_1,t_2,...,t_M t1,t2,...,tM**的位置建立起联系。**得模型"适应"好了之后,我们丢到 t 1 , t 2 , . . . , t M t_1,t_2,...,t_M t1,t2,...,tM的位置上的Prompt,换成我们特意提取的特征由 T ( ⋅ ) T(\cdot) T(⋅)生成的 T 1 , T 2 , . . . , T M T_1,T_2,...,T_M T1,T2,...,TM。
摘要
提示调优是使预训练的视觉语言模型(VLM)适应各种下游任务的一种有价值的技术。基于CoOp的最新进展提出了一组可学习的域共享或图像条件文本令牌,以促进特定任务文本分类器的生成。然而,这些文本标记对于不可见的域具有有限的泛化能力,因为它们不能动态地调整以适应测试类的分布。为了解决这个问题,我们提出了一种新的基于文本的类感知提示调优(TCP),它显式地结合了关于类的先验知识,以增强它们的可辨别性。TCP的关键概念包括利用文本知识嵌入(TKE)将类级别文本知识的高泛化性映射到类感知的文本令牌。通过无缝地将这些类感知提示集成到Text Encoder中,可以生成一个动态的类感知分类器,以增强对不可见域的可辨别性。在推理期间,TKE动态地生成与不可见类相关的类感知提示。综合评价表明,TKE可作为即插即用模块与现有方法轻松结合。此外,TCP在需要更少的训练时间的情况下始终实现卓越的性能。
1. 介绍
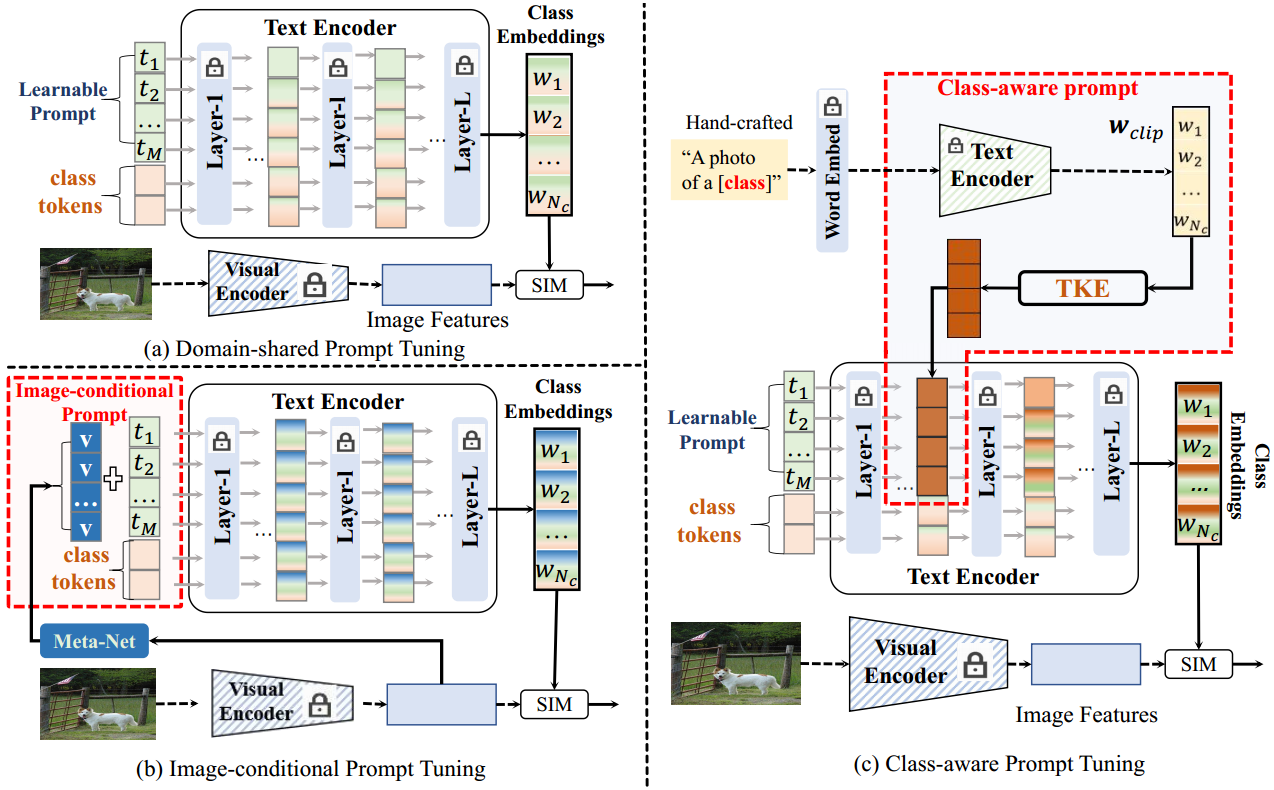
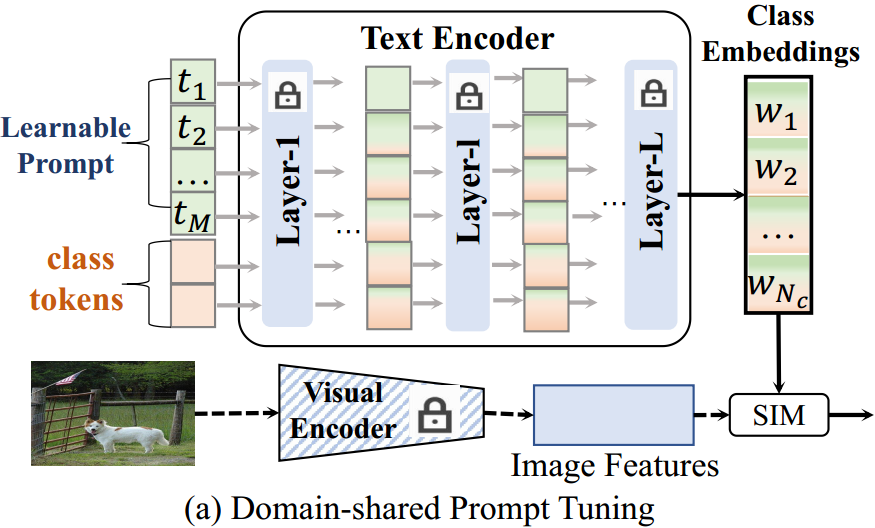
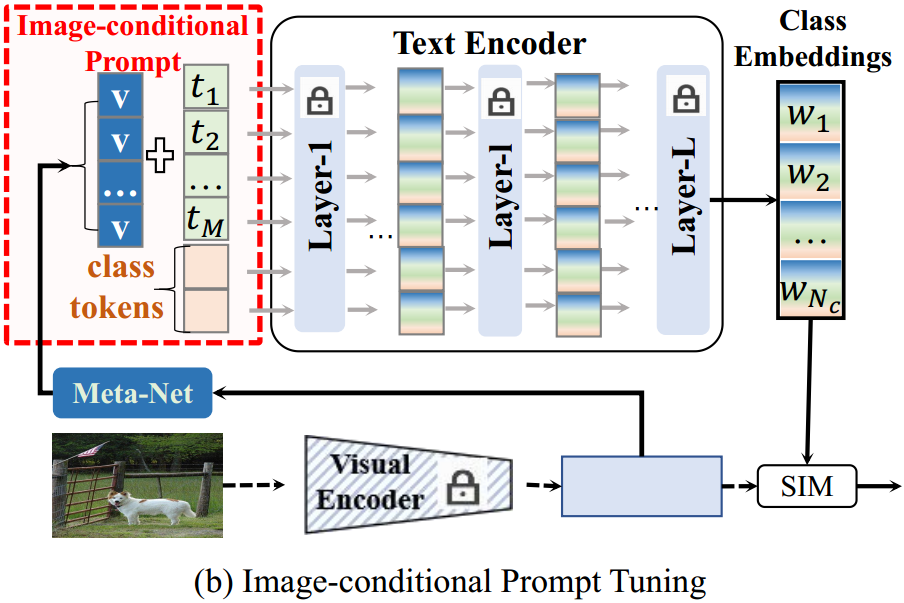
图1所示。与现有框架的比较。(a)域共享提示调优在训练域和测试域之间应用相同的可学习提示。(b)图像条件提示调整将图像嵌入与可学习提示相结合;类感知提示调优通过类感知提示将类级别的文本嵌入注入到文本编码器中。
大规模图像-文本对能够训练出具有强大泛化能力的视觉语言模型(VLM),用于各种下游任务2,33。然而,从头开始训练这些模型需要一个带有标记图像的庞大数据集,这使得很难将它们直接应用于具有较少图像的下游任务。为了解决这个问题,我们推荐了三种常用的技术:全微调30、提示调优50、适配器12和LoRA15。其中,提示调优是一个简单而有效的框架,它将VLM的基本通用知识传递给下游任务。
提示调优(Prompt tuning)是一种将可学习的文本标记与类标记结合起来生成判别文本分类器的技术,称为上下文优化(Context Optimization, CoOp)50。最近,各种基于合作的方法4,5,17,18,22,31,40,43,50,52推断出训练域和测试域之间的域共享提示令牌(图1(a))。然而,由于领域共享的提示令牌来自标记的训练图像,当面对未见过的测试类时,它们的性能不是最优的。为了增强可学习提示符号的泛化能力,45,49提出了融合图像特征和可学习标记符号的图像条件提示(图1(b))。值得注意的是,**图像条件文本标记封装了每个图像的特定知识,特别是对于测试图像,从而使其更容易泛化到看不见的测试图像。**然而,具有图像特定知识的图像条件提示符号在提升类嵌入分布方面的能力较差。总而言之,由域共享和图像条件文本令牌生成的分类器对未见过的类表现出次优性能,这主要是因为它们无法显式地对类分布建模。因此,必须在可学习的提示和每一类的文本知识之间建立一种动态关系,以增强其辨别能力。
冻结的CLIP与手工制作的提示符相结合,展示了对新类的强大泛化能力,使其成为每个类的先验文本知识的有价值的来源。通过将类级文本知识与可学习提示相关联,可以形成类感知提示,从而提高文本分类器的判别能力。为了实现这一点,我们使用一个嵌入模块将类感知的文本知识投影到类感知的提示令牌中,如图1©所示。由此产生的类感知提示包含特定于每个类的先前文本知识,赋予生成的文本分类器更高的判别能力。此外,类感知提示通过利用来自两个类别的文本知识,促进为可见类和不可见类生成分类器。综上所述,经过训练的嵌入模块可以根据每个类的描述("类名")为每个类生成一个类感知提示,从而增强了类级文本嵌入的泛化和判别能力。
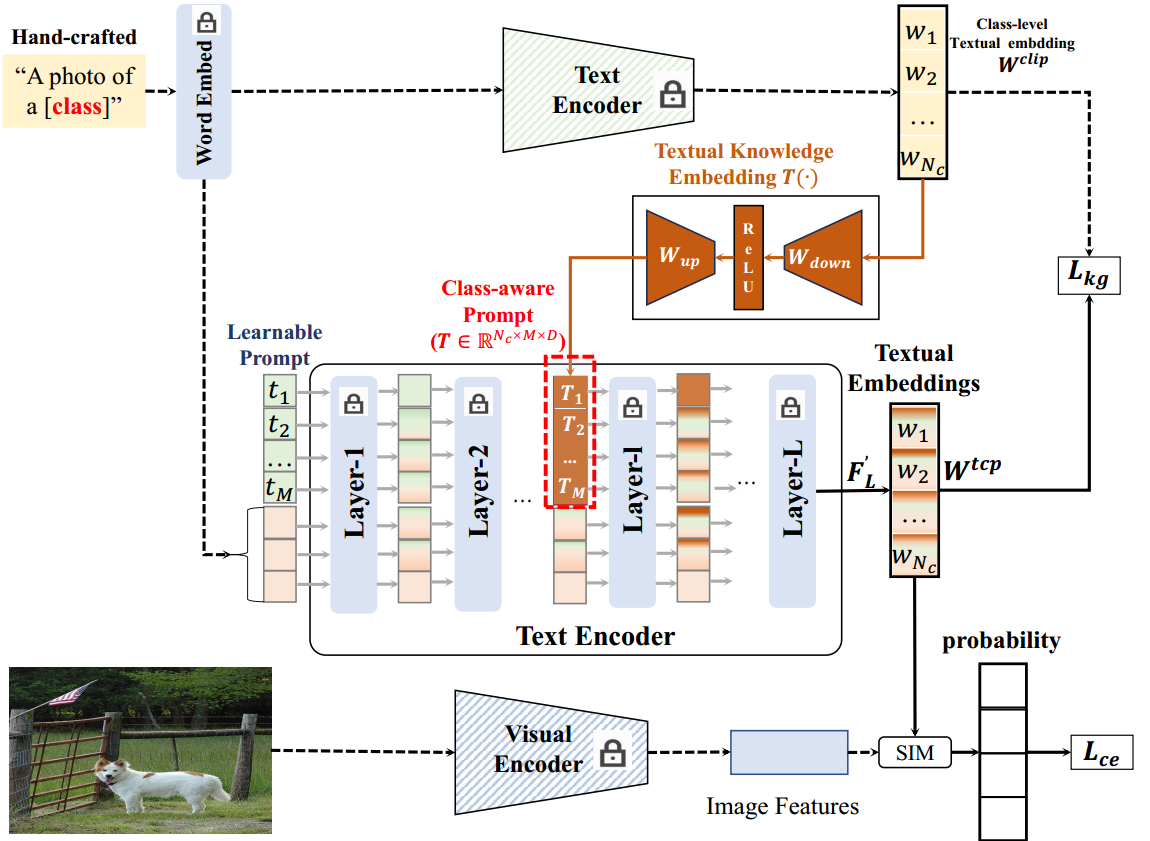
图2。TCP提出的框架。
因此,我们提出了一种基于CoOp框架的基于文本的类感知提示调优(TCP),如图2所示。除了CoOp中引入的域共享文本令牌之外,TCP还提供了一种新的文本知识嵌入(TKE),将类级别的文本知识映射到类感知的提示令牌。此外,通过将类感知的提示标记插入到Text Encoder的中间层中,生成了一个类感知的文本分类器。我们使用标准对比损失和知识引导一致性43来优化TKE和可学习提示令牌。在推理过程中,TCP通过将域共享的提示令牌和TKE生成的类感知提示令牌提供给冻结的Text Encoder,从而为不可见的类生成一个类感知的分类器。
总的来说,所提出的TCP明确地引导提示学习类感知知识,从而最大限度地提高下游任务的泛化和区别性。通过对11个图像分类数据集的基到新泛化、跨数据集泛化和小样本学习验证,TCP是一种以更少的训练时间获得更高性能的有效方法。总之,提出的基于文本的类感知提示调优(TCP)有以下主要贡献:
1.将文本知识嵌入(TKE)生成的文本类感知提示注入到文本编码器中,提出了一种有效的基于文本的类感知提示调优方法。
2.我们证明了将每个类别的先验知识显式地纳入可学习提示令牌可以增强类别分布的判别性。
3.文本知识嵌入(TKE)是一种即插即用模块,可以快速插入现有的提示调优方法,进一步提高其性能。
2. 相关的工作
2.1. 视觉语言模型
近年来,研究人员已经证明,视觉语言模型(VLM)2,33在图像-文本对的大规模训练上,由视觉和文本模态组成,具有强大的泛化和判别能力。为了进一步提高VLM的描述能力,从以下几个方面对VLM模型进行了提升:1)使用更强的文本编码器或视觉编码器25,41,46;2)深度融合视觉和文本知识23,38;3)使用更多的图像16,33,35,36。为了提高文本描述的多样性,掩码语言建模(mask Language Modeling, MLM)2026随机擦除用于表示学习的文本描述中的单词。与传销不同,提出了基于掩码自编码器的方法13,通过随机掩码图像补丁来提高描述能力。在现有的VLM模型中,CLIP是利用基于4亿个图像-文本关联对的对比损失来推断独立的视觉和文本编码器的具有代表性和直接性的框架。由于CLIP具有良好的泛化性,现有的大多数基于协作的方法都是基于CLIP将预训练好的VLM适应下游任务。与现有方法类似,我们在CLIP的TextEncoder上执行提示调优策略,以获得用于预测的特定任务的文本嵌入。
2.2. 提示优化
为了使预训练的VLM适应下游任务,提示调优10,22,24,31,33,45总是使用任务相关的文本标记来推断任务特定的文本知识。在CLIP33中,使用手工制作的模板"a photo of a CLASS"来嵌入文本嵌入,用于零样本预测。然而,手工制作的提示描述下游任务的能力很差。文本提示调优通过推断一组可学习的文本标记与类标记相结合来增强文本嵌入。例如,上下文优化(CoOp)50取代了手工制作的提示符用可学习的软提示。为了提高CoOp中可学习文本提示的泛化性,条件上下文优化(Conditional Context Optimization, CoCoOp)49和VPT45生成了一个融合了图像特征和可学习文本提示的图像条件提示。此外,知识导向上下文优化(knowledge - guided Context Optimization, KgCoOp)43、ProGrad51和提示正则化(Prompt Regularization, ProReg)52约束了建议的可学习提示包含基本的一般知识。与上述方法考虑文本提示不同,集成上下文优化(Ensembling Context Optimization, ECO)1采用提示集成来组合多个提示。为了获得高质量的任务相关令牌,ProDA27考虑提示符的先验分布学习,而分布感知提示调优(distributed - aware prompt Tuning, DAPT)5通过最大化互分散来优化可学习提示符。除了来自"classname"的文本知识外,知识感知提示调谐(knowledge-aware Prompt Tuning, KAPT)17还利用外部知识生成针对新类别的判别性知识感知提示。
PLOT4应用最佳传输来匹配视觉和文本模式,以生成判别性和视觉对齐的本地文本提示令牌。除了文本提示调音外,Multi-modal prompt Learning (MaPLe)18和PromptSRC19还通过在视觉和文本编码器上共同进行提示调音来进行视觉文本提示调音。多任务视觉语言提示调优(MVLPT)37将跨任务知识整合到视觉语言模型的提示调优中。DenseCLIP34使用上下文感知提示策略来生成密集预测任务,CLIPAdapter11使用适配器来调整视觉或文本嵌入。
现有方法通常推断两种类型的提示令牌:域共享和图像条件。然而,用这些标记生成的文本分类器往往在未见过的类上表现不佳。为了缓解这一限制,我们提出了一种新的基于文本的类感知提示调优(TCP),它使用动态类感知令牌来增强可学习文本提示的泛化和区分能力。此外,我们引入了文本知识嵌入,将类级文本知识投影到类感知提示中,然后将这些提示插入到文本编码器中以生成判别类感知分类器。评价结果表明,将类级先验知识集成到提示标记中,显著提高了提示调整过程的判别能力。
3.方法
由于基于上下文优化(CoOp)提出了基于文本的类感知提示调优(TCP),我们首先简要回顾了CoOp,然后介绍了所提出的TCP。
3.1. 准备知识
现有的基于CoOp的方法是基于强大的对比语言图像预训练(CLIP)提出的。给定图像及其相应的文本描述,CLIP使用视觉和文本编码器来提取视觉和文本嵌入。然后,计算视觉嵌入和文本嵌入之间的压缩损失以对齐这两个嵌入。为了使CLIP有效地适应下游任务,CLIP应用手工制作的模板"a photo of a{}"提取一般的类级文本嵌入,定义为 W c l i p = { w i c l i p } i = 1 N c W^{clip}=\{w_i^{clip}\}^{N_c}_{i=1} Wclip={wiclip}i=1Nc,其中 w i c l i p w_i^{clip} wiclip为第 i i i个类的文本嵌入, N c N_c Nc为类的个数。给定第 i i i类的"class-name",Word Embedded e ( ⋅ ) e(\cdot) e(⋅)首先将手工制作的描述嵌入到一个矢量化的文本标记中: t i c l i p = e t_i^{clip}=e ticlip=e("a photo of a {class-name}")。之后,Text Encoder θ \theta θ将矢量化的文本标记 t i c l i p t_i^{clip} ticlip 映射到类级嵌入中: w i c l i p = θ ( t i c l i p ) w^{clip}_i=\theta(t^{clip}_i) wiclip=θ(ticlip).
为了提高类级嵌入的判别性,上下文优化(CoOp)的提示调优方法将手工制作的文本标记替换为一组可学习的文本标记 T = { t 1 , t 2 , . . . , t M } T=\{t_1,t_2,...,t_M\} T={t1,t2,...,tM},其中 M M M为令牌的长度。与CLIP类似,将相应的类令牌 c i c_i ci与可学习的令牌 T T T连接起来,以生成文本令牌 t i c o o p = { t 1 , t 2 , . . . , t M , c i } t_i^{coop}=\{t_1,t_2,...,t_M,c_i\} ticoop={t1,t2,...,tM,ci}。然后,将文本标记 t i c o o p t_i^{coop} ticoop 输入到Text Encoder θ \theta θ中,即 w i c o o p = θ ( t i c o o p ) w^{coop}_i=\theta(t_i^{coop}) wicoop=θ(ticoop),得到文本嵌入 w i c o o p w^{coop}i wicoop 。最后,将所有类的文本嵌入定义为 W c o o p = { w i c o o p } i = 1 N c W^{coop}=\{w_i^{coop}\}^{N_c}{i=1} Wcoop={wicoop}i=1Nc。
CoOp通过最小化图像嵌入 x x x与其类嵌入 W y c o o p W^{coop}_y Wycoop之间的对比损失来推断可学习的文本标记 T T T:
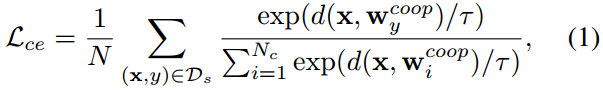
其中, D s D_s Ds是看到的数据集, d ( ⋅ ) d(\cdot) d(⋅)是余弦距离。 τ \tau τ是CLIP中定义的温度因子, N N N是训练图像的个数。
由于生成的文本嵌入对新类具有良好的泛化能力,KgCoOp进一步在生成的嵌入 W c o o p W^{coop} Wcoop与通用嵌入 W c l i p W^{clip} Wclip之间增加了一个高效的一致性 L k g L_{kg} Lkg。
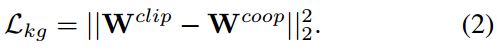
因此,提示调优的健壮目标是:
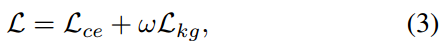
其中 ω \omega ω设为8.0,与KgCoOp43相同。
3.2. 基于文本的类感知提示调优
图2。TCP提出的框架。
基于CLIP中预训练的Text Encoder,文本提示调优旨在推断一组域共享或图像条件文本标记与一般类标记相结合,以生成特定的类嵌入。然而,由这些文本标记生成的文本分类器对未见过的类执行较差的泛化,因为它们不能对测试类的分布进行建模。研究表明,利用冷冻CLIP提取的一般文本知识可以创建新类的判别先验知识,增强可学提示的判别性和泛化性。利用已见和未见类的一般文本知识,我们提出了一种基于文本的类感知提示调优(TCP),以使预训练的CLIP适应下游任务。如图2所示,TCP使用文本知识嵌入(TKE)将一般的类级文本嵌入转移到类感知提示符中,然后将其与可学习的文本令牌结合起来,生成类感知分类器。TKE对于不可见的类是有利的,因为它生成特定于类的提示,以获得具有更好判别能力的不可见的类感知文本分类器。此外,明确地结合可视类感知提示可以增强可视类的辨别能力。
给定具有 N c N_c Nc 训练类的通用类级文本嵌入 W c l i p = R N c × D t W^{clip}=R^{N_c\times D_t} Wclip=RNc×Dt,提出文本知识嵌入(textual Knowledge embedding, TKE) T ( ⋅ ) T(\cdot) T(⋅),将类级嵌入 W c l i p W^{clip} Wclip投影到类感知提示符 T = τ ( W c l i p ) \Tau=\tau(W^{clip}) T=τ(Wclip)中。如图2所示,TKE由下项目层和上项目层两层组成。down-project层使用权值 W d o w n ∈ R D t × D m i d W_{down}\in R^{D_t\times D_{mid}} Wdown∈RDt×Dmid将文本嵌入投影到维度为 D m i d D_{mid} Dmid 的低维特征中。接下来,上项目层的权值 W u p ∈ R m i d × D ′ W_{up}\in R^{{mid}\times D'} Wup∈Rmid×D′将低维特征映射为维数为 D ′ D' D′ 的高维特征。注意, D ′ D' D′是由提示符的长度 M M M 和维数 D D D 决定的: D ′ = M × D D'=M\times D D′=M×D。综上所述,一般的文本嵌入 W c l i p ∈ R N c × D t W^{clip}\in R^{N_c\times D_t} Wclip∈RNc×Dt 可以投影到类感知的文本标记 T ∈ R N c × D ′ T\in R^{N_c\times D'} T∈RNc×D′ 中,再将其重塑成 T ∈ R N c × M × D ′ T\in R^{N_c\times M \times D'} T∈RNc×M×D′ 的形状,插入到Text Encoder θ \theta θ 的中间层中。
假设我们将类感知提示符 T T T插入到Text Encoder θ \theta θ的第1层。下面我们将对超参数 l l l 进行详细的分析。与CoOp类似,通过组合领域共享的可学习文本标记 T = t 1 , t 2 , . . . , t M T=t_1,t_2,...,t_M T=t1,t2,...,tM和所有类的预训练类token C C C,我们可以得到Text Encoder的输入文本令牌 F 0 = { T , C } F_0=\{T,C\} F0={T,C},其中 C = { c i } i N c C=\{c_i\}^{N_c}_i C={ci}iNc 为第 i i i 类的向量化文本令牌。将文本标记 F 0 F_0 F0 输入到文本编码器的前1层,以获得中间层文本嵌入 F l F_l Fl。形式上,第 i i i 层的文本令牌 F i ( i ≤ l ) F_i(i\le l) Fi(i≤l) 定义为:
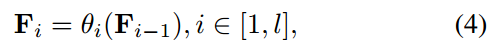
其中 θ i \theta_i θi是文本编码器的第 i i i层。
对于文本标记 F l ∈ R N c × N t × D F_l\in R^{N_c\times N_t \times D} Fl∈RNc×Nt×D和类感知提示标记 T ∈ R N c × M × D T\in R^{N_c\times M \times D} T∈RNc×M×D,第一个维度与类的数量有关。因此,与CoOp一样,可学习的提示符号总是插入到 F l F_l Fl的第二维中。形式上,将类感知的提示符 T T T 插入到 F l F_l Fl 中,以生成类感知的增强令牌 F l ′ F'_l Fl′;
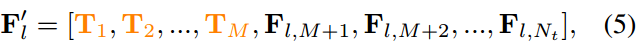
式中, T i T_i Ti表示 T T T在第二维中的第 i i i个指标, F l , j F_{l,j} Fl,j表示对应的 F l F_l Fl在第二维中的第 j j j个指标,即 T i = T : , i , : , F l , j = F l : , j , : T_i=T:,i,:,F_{l,j}=F_l:,j,: Ti=T:,i,:,Fl,j=Fl:,j,:。
之后,将类增强的文本标记符 F i ′ F'_i Fi′填充到其他层中,以生成类感知的文本嵌入。
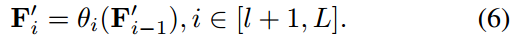
将最后一层 F L ′ F'_L FL′的输出作为类嵌入 W t c p W^{tcp} Wtcp,用于Eq.(3)中具有对比损失和知识引导一致性损失的优化。
4. 实验
与CoOp50类似,我们从三种任务类型来评估TCP的有效性:1)数据集中从基类到新类的泛化;2)用K-shot标记图像进行小样本学习;3)从imagenet到其他数据集的跨数据集泛化。更详细的结果将在补充材料中提供。
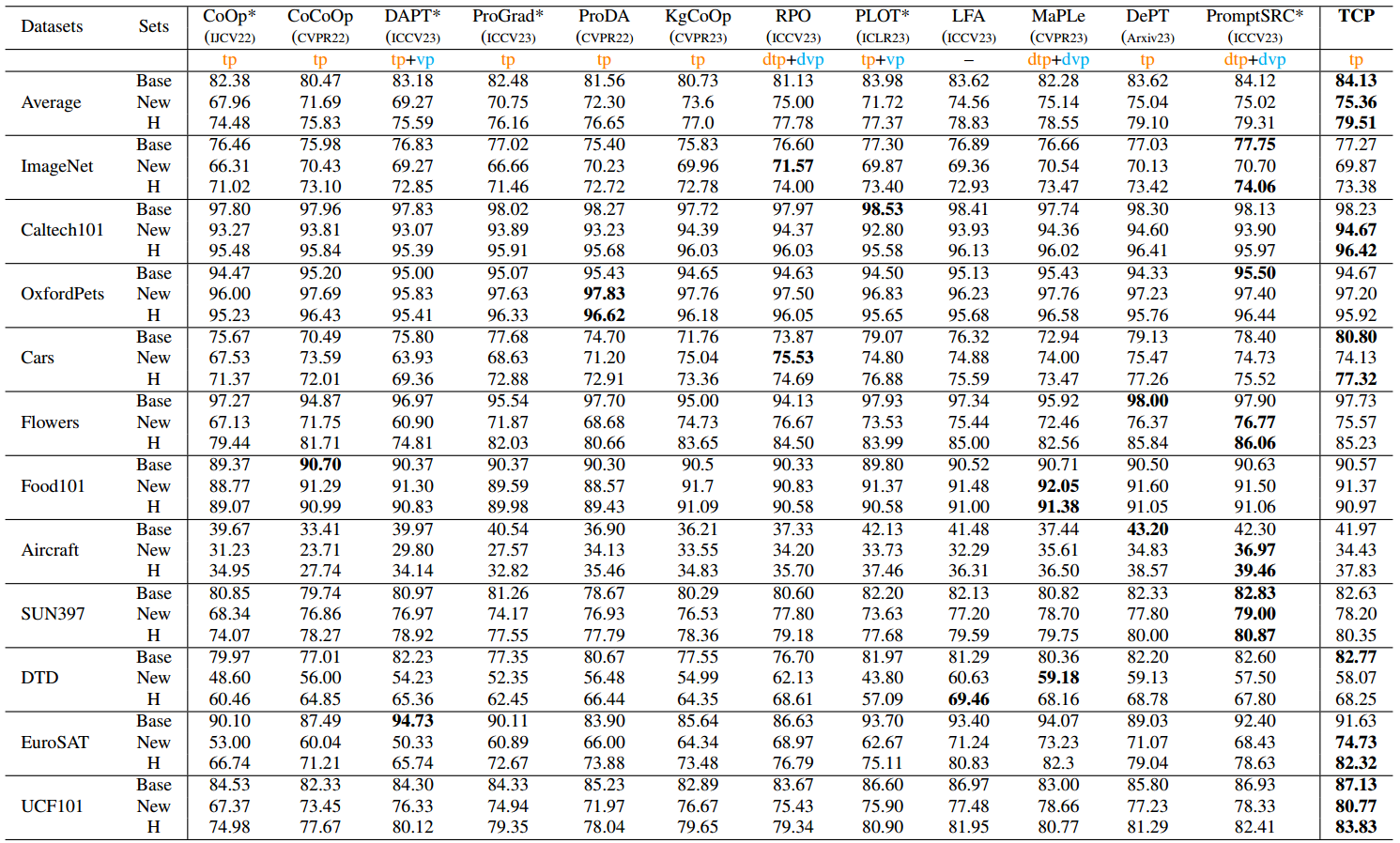
表1。基数到新泛化设置与16-shot的比较。"tp"、"dtp"、"vp"和"dvp"分别表示"文本提示"、"深度文本提示"、"视觉提示"和"深度视觉提示"。PromptSRC基于深度视觉文本提示调优(' dvp+dtp ')。' * '表示我们重新实现后获得的性能。
在Base-to-New泛化设置中,New类始终具有与基类相似的数据分布。为了进一步验证所提出TCP的泛化性,在跨数据集泛化中,TCP从ImageNet中进行训练,并直接在不相关的数据集上进行评估,例如其余10个数据集。提出的TCP与现有方法的比较总结如表2所示。从表2中我们可以看到,本文提出的TCP在所有文本提示调优方法中获得了最高的平均性能(66.29% vs . DePT的65.55%47),并且与视觉文本提示调优方法(66.29% vs . DAPT的66.31%5)获得了相当的性能,证明了TCP在学习泛化知识方面的有效性。
表2。跨数据集评价的比较。"tp"、"dtp"、"vp"和"dvp"分别表示"文本提示"、"深度文本提示"、"视觉提示"和"深度视觉提示"。请注意,DAPT和MaPLe基于可视文本提示调优(' vp+tp ')。
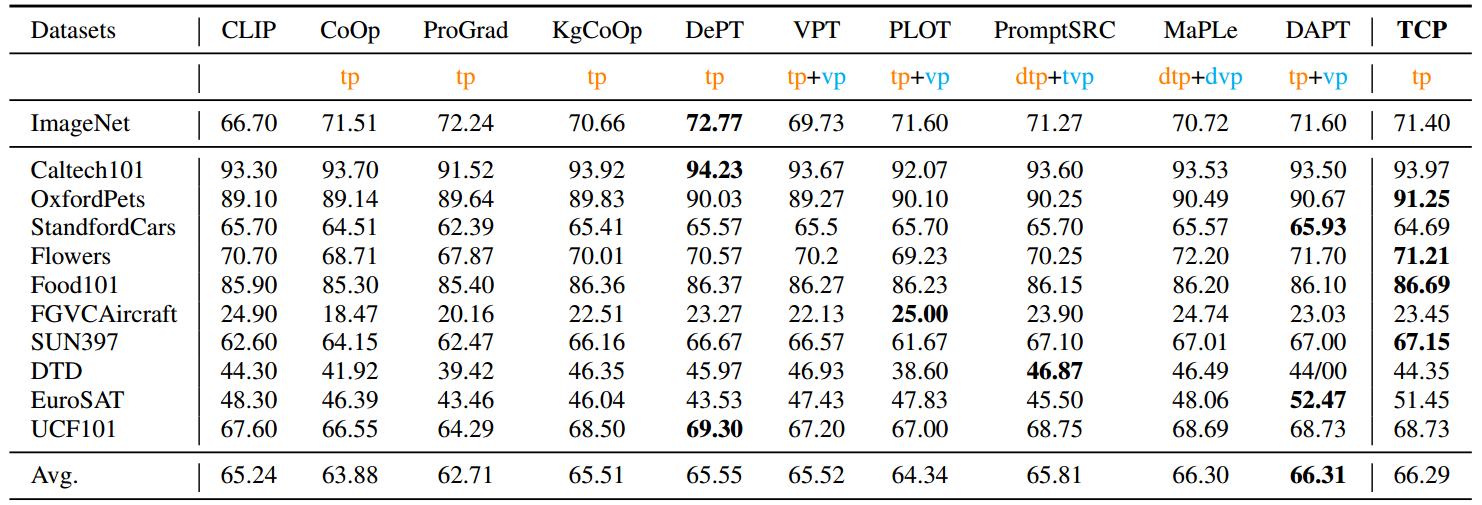
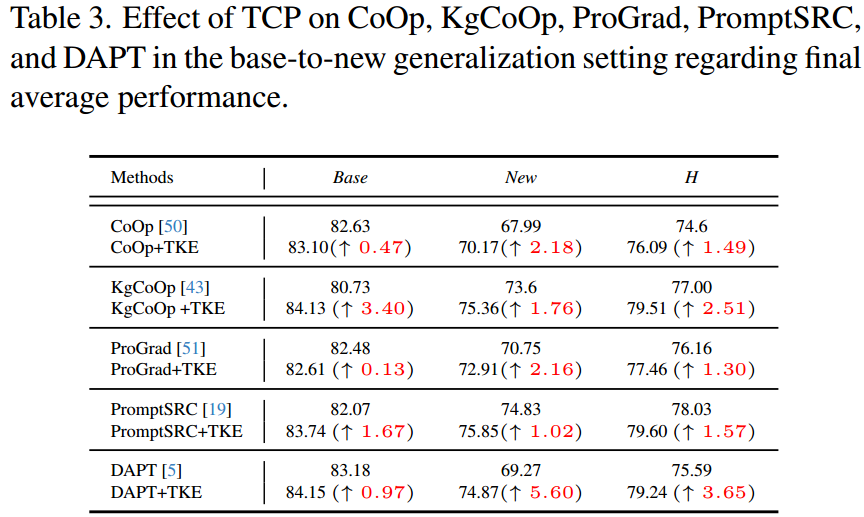
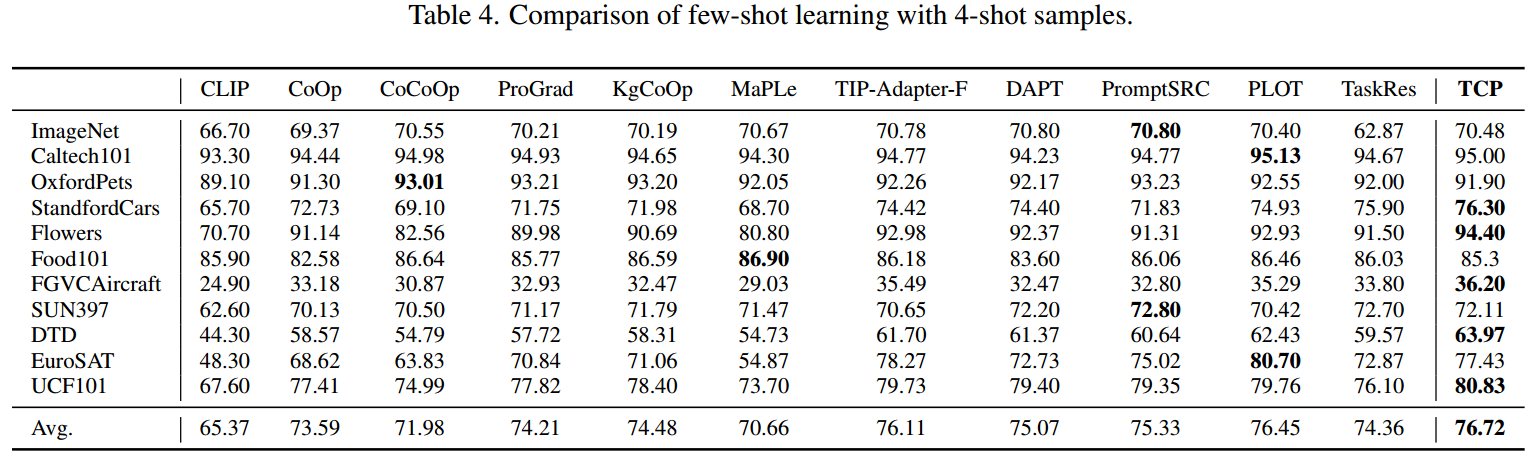

图7。CoOp和TCP概率的可视化。
5. 结论
为了提高可学习提示的泛化和判别能力,我们引入了一种基于文本的类感知提示调优方法,该方法利用了一般类级文本知识的优势。为了实现这一点,我们提出了一种文本知识嵌入(TKE),它将类级别的文本嵌入转换为类感知提示。这与预先训练的类标记相结合,生成特定于任务的文本知识。几个基准测试和任务表明,类感知提示对于提示调优是有效的。
然而,TCP中的类感知提示在很大程度上依赖于通用文本嵌入的识别能力。另一方面,较弱的文本嵌入将产生较弱的文本分类器。例如,TCP在fgvc - aircraft数据集上表现不佳。因此,在未来,我们计划探索如何使用较弱的文本知识来获得判别文本分类器。
参考资料
论文下载(2024 CVPR)

代码地址
https://github.com/htyao89/Textual-based_Class-aware_prompt_tuning