
摘要
本文研究了基于孤立森林算法的异常数据检测方法,并在MATLAB中实现了该算法的可视化。孤立森林是一种无监督的异常检测算法,主要通过构建决策树来区分正常数据和异常数据。本文使用真实数据集,通过二维可视化展示了检测结果。实验结果表明,孤立森林算法能够有效识别出数据集中的离群点,为异常检测问题提供了一种高效、可靠的解决方案。
理论
孤立森林算法
孤立森林(Isolation Forest)是一种用于异常检测的无监督学习算法。其基本思想是通过构建多棵决策树来"隔离"样本,异常数据通常在较少的划分次数下就能被隔离。孤立森林通过以下步骤进行异常检测:
-
随机采样:从数据集中随机抽取子样本。
-
构建决策树:为每个子样本构建一棵随机决策树,在每个节点随机选择一个特征和划分值。
-
隔离数据点:数据点在决策树中的路径长度越短,该点越容易被隔离,因此被认为是异常点。
孤立森林的核心优点在于,它不需要假设数据的分布,并且计算复杂度低,适合大规模数据集。
异常检测
异常检测是数据挖掘中的一个重要任务,通常用于识别与大部分数据显著不同的样本。异常数据可能是由于噪声、错误记录或真实的罕见事件造成的。在金融、网络安全等领域,检测异常数据有助于防范潜在的风险。
实验结果
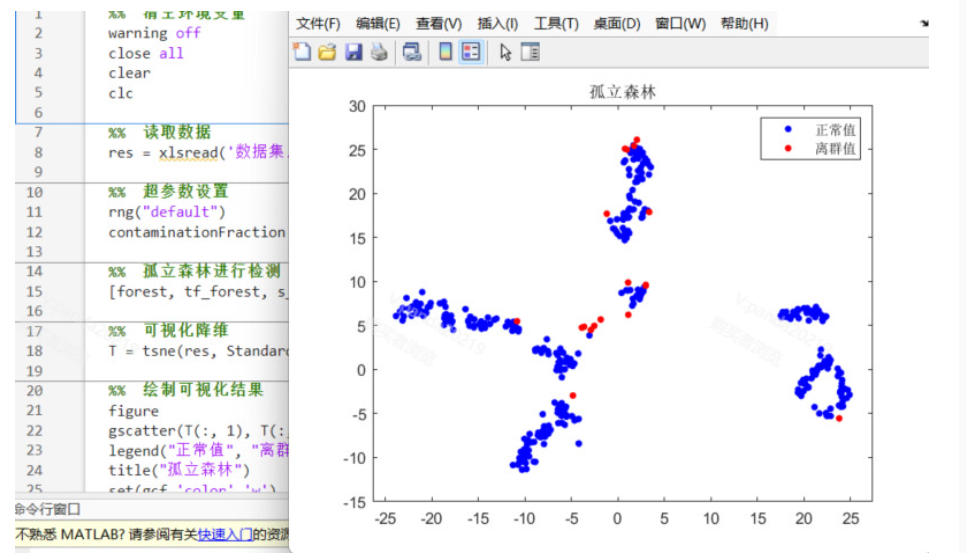
实验使用了包含多个特征的数据集,数据经过预处理后应用孤立森林算法进行异常检测。实验结果显示了正常点和异常点在二维空间中的分布情况,如图所示,蓝色点表示正常值,红色点表示异常值。孤立森林算法能够有效地识别出异常数据,验证了该算法在异常检测中的实用性。
通过设置不同的污染率(contamination factor),可以调整异常检测的敏感度。实验表明,适当的污染率设置可以更好地平衡异常点和正常点的检测准确率。
部分代码
以下是基于MATLAB实现的孤立森林算法的部分代码:
% 读取数据
data = xlsread('dataset.xlsx');
% 设置随机数种子
rng('default');
% 设置污染率 (contamination rate)
contaminationFraction = 0.05;
% 执行孤立森林算法
[forest, tf_forest, scores] = iforest(data, 'NumLearners', 100, 'ContaminationFraction', contaminationFraction);
% 降维可视化
T = tsne(data, 'Standardize', true);
% 绘制可视化结果
figure;
gscatter(T(:,1), T(:,2), tf_forest, 'br', 'ox');
legend('正常值', '离群值');
title('孤立森林');
% 输出异常分数
disp(scores);参考文献
❝
Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation Forest . Proceedings of the 2008 IEEE International Conference on Data Mining (ICDM).
Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000). LOF: Identifying Density-Based Local Outliers . Proceedings of the ACM SIGMOD International Conference on Management of Data.
Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly Detection: A Survey . ACM Computing Surveys (CSUR), 41(3), 1-58.
