介绍
论文地址:https://arxiv.org/pdf/2405.04655v1
近年来,大型语言模型(LLM)不仅被广泛应用于各个领域,而且通过大量的基准评估,证明它们能够理解人类所拥有的常识(=Commonsense)。这里的常识指的是世界上大多数人所共有的关于世界的广泛而基本的常识,包括关于日常事件、现象和关系的一般知识。LLM群体在过去投入了大量精力,除了公共常识外,还建立了更为专业的知识库,如物理常识和社会常识。
另一方面,常识,如 "红色是婚纱的常见颜色",在中国、印度和越南是共同的文化规范 ,但在意大利或法国却不是。常识在中国、印度和越南是共同的文化规范,但在意大利和法国却不是。
然而,也存在一些问题:以往的研究很少考察LLM对这种文化常识(=Cultural Commonsense)的理解。在此背景下,本文介绍了一篇 论文,该论文通过使用 多种文化常识****基准进行比较实验,研究了不同文化背景下LLM表现的差异和局限性,并指出了LLM对文化理解的固有偏差
概述
常识往往是隐性的、不成文的,因此与事实知识的不同之处在于,它具有通过文化学习长期习得的特性。部分由于这种性质的分析困难,现有的文化常识研究非常有限,而且这些研究也主要集中在建立包含相对较少的文化事实和信息的数据集上。而本文则侧重于语言文本作为文化背景的功能 ,即一个文化群体的先学语料库中的文本是用该文化群体所使用的语言写成的。
如下图所示。

例如,**"人们在道路的哪一边行走?**如果用日语或斯瓦希里语(肯尼亚的官方语言)来回答,用户很可能是会说这两种语言的日本人或肯尼亚人,因此更有可能回答 "左边"。鉴于这些特点,本文研究了LLM在文化常识方面的能力和局限性,这是以前从未做过的。
实验装置
本文根据以下两个标准对 LLM 进行评估
- 了解特定文化和一般常识
- 了解特定文化背景下的一般常识
根据这些评估标准,本文使用中国、****印度、伊朗、肯尼亚和美国 五个国家的文化和五种官方语言(中文、印地语、波斯语、苏马瓦里语和英语)进行了多任务实验。
创建多语言提示
在本实验中,我们制作了多语言提示,以研究语言在本地语言学习者的表现中所起的作用,以及不同语言在多大程度上可以提高(或降低)本地语言学习者识别文化常识的能力。
具体来说,对于以中文、印地语、波斯语、苏马瓦里语和英语书写的提示,Azure 的翻译 API 可用于将其翻译为目标语言。
此外,还通过使用不同的翻译工具重新翻译部分翻译结果来验证翻译质量。
测试LLM
为了全面测试 LLMs 在与文化常识相关的任务中的能力,本文在不同尺度上对 LLMs 进行了实验,包括
使用的开源模型有:LLAMA2 (用于各种任务);Vicuna (由 ShareGPT 对 LLAMA2 进行微调);Falcon(具有开放的商业用途和干净的语料库 RefinedWeb)。
此外,闭源模型还有GPT-3.5-turbo 和****GPT-4,它们是托管在 Azure 上的 OpenAI 模型。
通过对这些模型执行下述任务,对每个模型进行了比较验证。
实验结果
本实验进行了两项任务的对比实验:问题解答(QUESTION ANSWERING)和国家预测(COUNTRY PREDICTION)。
下图显示了这些任务中使用的提示和正确答案示例,每种提示都指示 LLM 填入句子的屏蔽部分。

让我们逐一看看。
回答问题
这项任务涉及的问题在不同的文化中会有不同的答案,对于特定文化背景的人来说,这些问题被认为是常识性的,它向LLM们展示了每种相关文化的常识性论据,这些论据显示了他们的民族背景和可供选择的选项,并要求他们填写遮盖的区域。
问题和答案选项被翻译成多种语言,每个模型被指示用与输入相同的语言作答。
实验结果如下表所示。
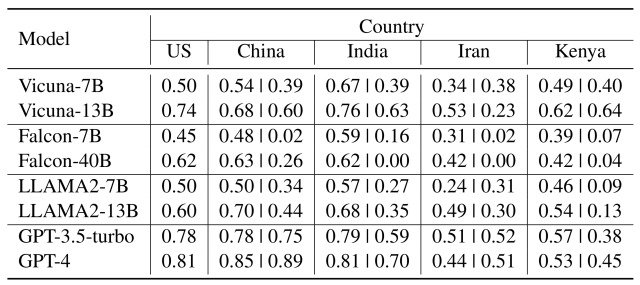
值得注意的是**,在伊朗(Iran)和肯尼亚(Kenya)的问题上,所有模型的性能都有所下降,尤其是在伊朗,平均准确率下降了 20%**。
从这一结果可以推断出,LLM 无法应对来自先前学习语料库中代表性不强的国家的文化常识。
国家预测
为了进一步了解情况,本文随后利用国家预测进行了比较验证。
这项任务是为了测试 "在给定一个包含特定文化常识的句子时,语言学LLM能否识别出句子中提到的是哪个国家",在句子中屏蔽了国家名称,然后让语言学LLM做出回答。
实验结果如下表所示。

与问答任务一样,在比较不同文化背景下的表现时,该模型在伊朗或肯尼亚的表现始终最差�
此外,在印度、伊朗和肯尼亚,我们发现当使用开放源码模型以该国语言进行查询时,性能比英语低(但在封闭源码模型中则没有)。
这一现象可能表明 ,在开放源码模式中,用于输入 LLM 的语言可能会影响性能,而且对 LLM 文化的理解存在固有偏差。
总结
结果如何?在这篇文章中,我们介绍了一篇论文,该论文通过使用多种文化规范的基准进行比较实验,研究了不同文化背景下LLM成绩的差异和局限性,并指出了LLM对文化理解的固有偏差。
虽然本文在实验中提出了各种建议,但也存在一些挑战**,例如****本文使用的数据集只有英文版**,而且研究中使用的 LLM 模型也不是最新的。