240930_CycleGAN循环生成对抗网络

CycleGAN,也算是笔者记录GAN生成对抗网络的第四篇,前三篇可以跳转
在第三篇中,我们采用了pix2pix进行图像风格的转移,但在pix2pix上,训练往往需要在像素级上一一对应的数据,就造成了很多方面任务无法完成,有一定局限性。比如在绘画领域,我们无法得到画家当时所画的那个场景的照片,同样,我们此刻拍的照片也不能请那些画家来给咱们对照着画一幅画。这就造成了数据集无法一一对应,无法进行训练的问题。CycleGAN就是为了解决这样的问题,上面的图片就是CycleGAN所实现的效果。简单来说就是网络上前段时间爆火的图像风格转移,比如把你女朋友的照片传进去后变成一个公主。
传统GAN
在传统GAN中,我们有一组生成对抗网络,也就是两个网络,生成器根据随机噪声生成图像传给判别器进行判断。
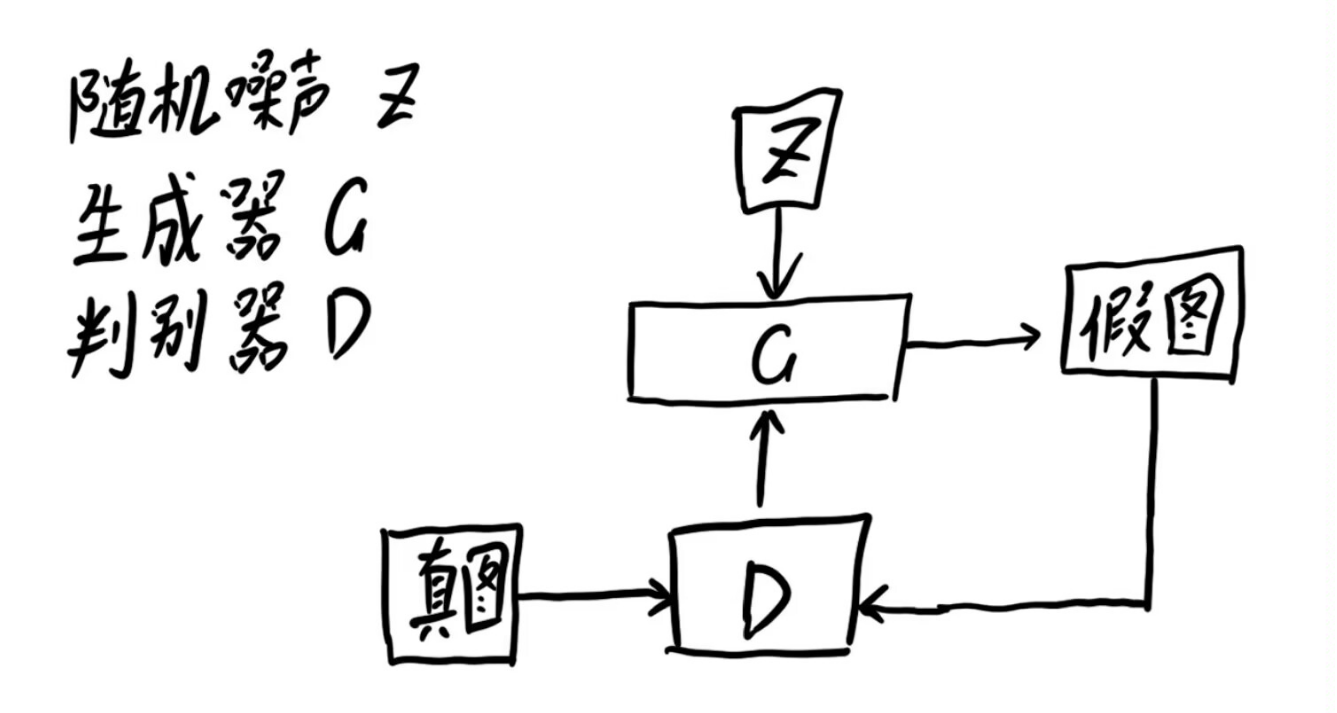
CycleGAN
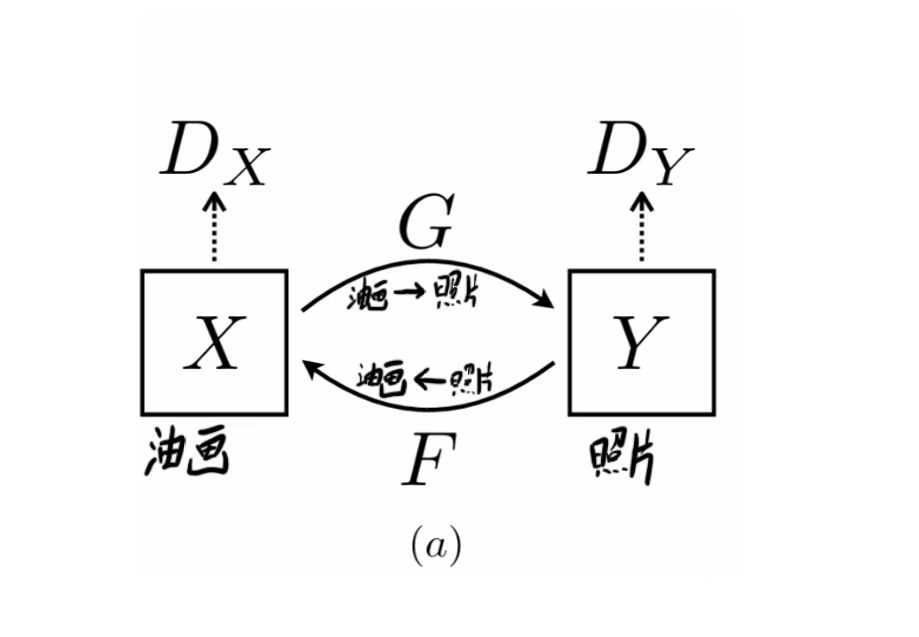
而在CycleGAN中,我们有两组生成对抗网络,如下图所示。
加入X和Y是两个文件夹,X中放了莫奈(一个有名的画家)所画的所有作品,Y中放了你手机相册里的一些风景照。此时我们需要把X域中一张图通过G生成器生成一张符合Y域的图(就是用一张油画生成一张照片,风格转移),Dy努力判别到底是真实的Y还是G生成器生成的假Y。G和Dy构成一组生成对抗网络,其结果就是Dy再也判别不出到底是真Y还是假Y。
而第二组生成对抗网络,就是把Y域中的一张图,通过F生成器,生成一张符合X域的图像(照片转油画),Dx努力判别是真的X还是F生成的假X,这就构成了第二组生成对抗网络,其结果是Dx再也分辨不出真的X和生成的X。
通过两组生成对抗网络,就实现了莫奈风格画作和照片的互相转移,也就构成了Cycle循环。
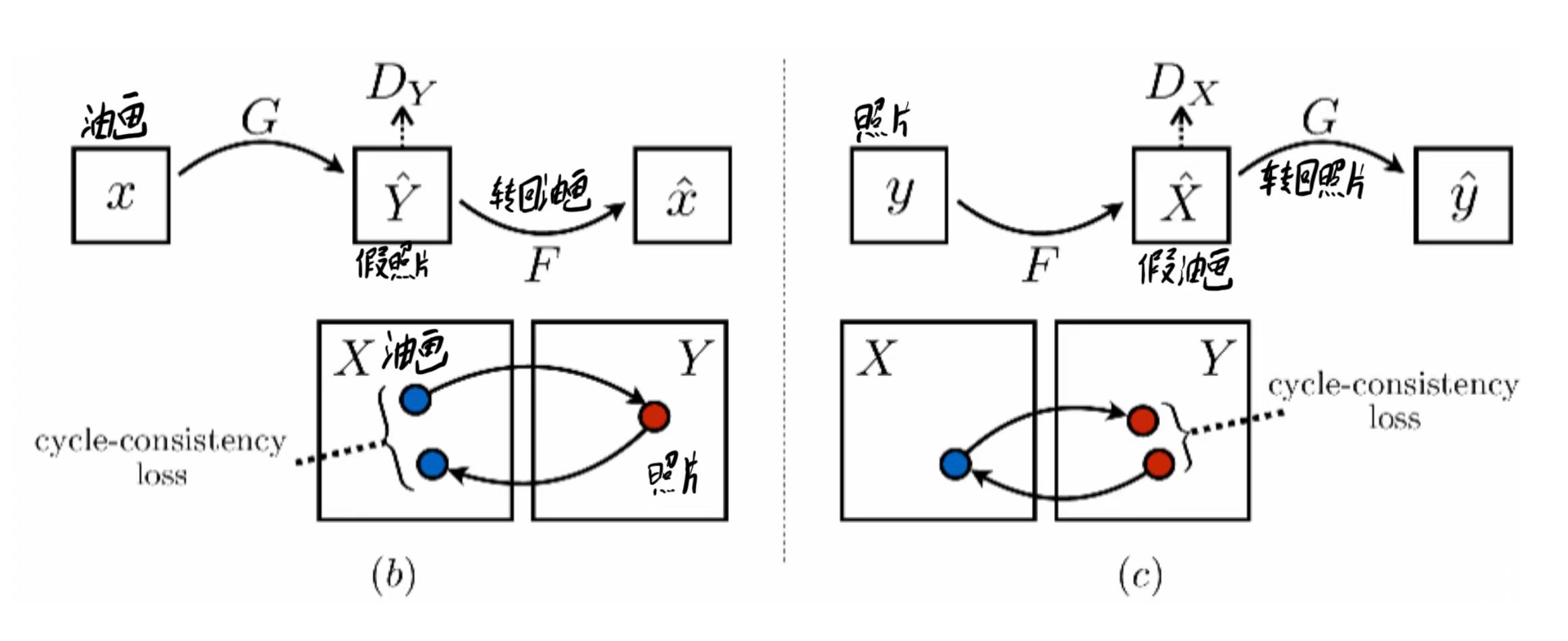
但这样仍然存在于一个问题,像我们在CGAN中说的那样,在CGAN中,我们除了判断其是真图像还是假图像之外,还要判断其是否符合我们提供的标签。
在这里,我们就要判断其到底是不是和原图所描述的场景一致。即要做到"风格转变,内容不变"。比如我们提供的油画是一幅森林的画作,通过G生成器生成后,确实生成了照片,但是生成的照片却变成了城市,这不是我们想要的,我们想要的是转变为照片的森林。
也有一种可能是不管你输入森林还是城市的油画,生成器总是给你生成一份草原的照片,这也确实符合照片的风格,但是也不是我们想要得到的,这是一种模式崩溃现象。
循环一致性损失(cycle-consistency loss)
为了解决这个问题,我们需要加入一个循环一致性损失(cycle-consistency loss)。具体该如何实现呢。我们就需要构建一个循环一致性损失,在森林的油画转成照片之后,我们再把这张照片通过F生成器转回油画,然后与原图做L1范式(逐元素做差取绝对值再求和)。用来确定和原图尽可能相似。
以下是该损失的公式:
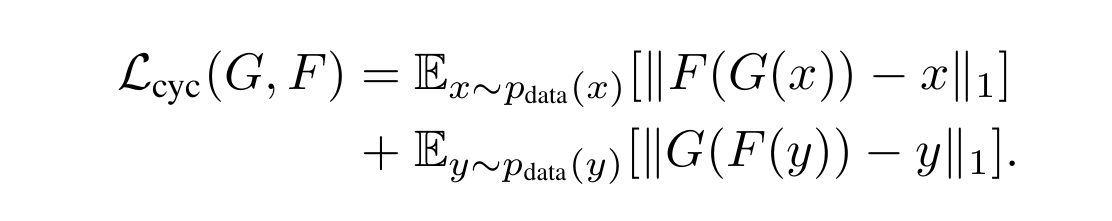
简单作以公式剖析, F ( G ( x ) ) F(G(x)) F(G(x))就是"x通过G生成的图像再传给F生成得到的图像",然后减去x,就是逐元素做差,然后外面套了两个看着像绝对值的东西,内层的两个竖线确实是取绝对值,外层的两个竖线就不是了,右下角还跟着一个1,这就是取L1范式,简单说就是上面说的,逐元素做差取绝对值再求和。这个损失是越小越好。
Identity Loss(可选)
在CycleGAN中,生成图不在意颜色的差别,只要能骗过判别器就行,生成出来的画作可能颜色就不太对,少了点灵魂,论文中提到可以加入Identity Loss来解决这个问题。

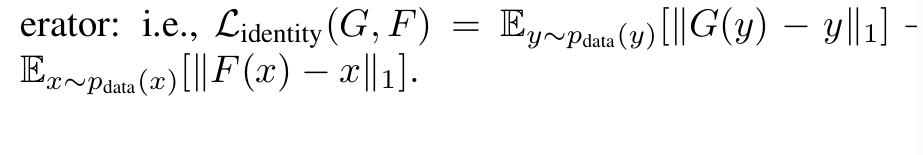
整体损失
整个CycleGAN的损失就是两个GAN的损失加上这个循环一致性损失
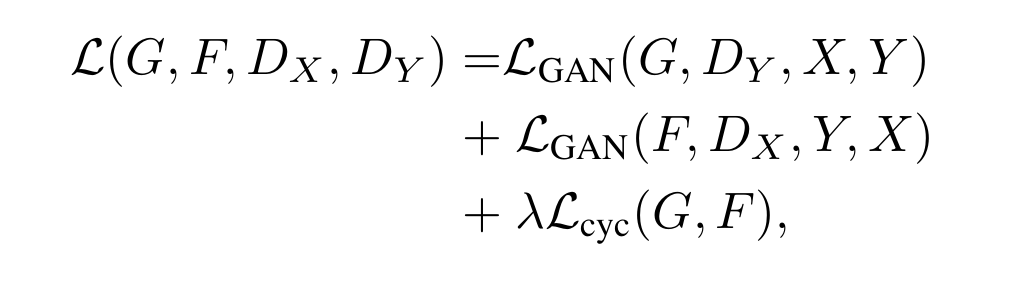
其中单独的GAN损失在之前讲GAN时就已经讲清楚了,复习请跳转博客开头那个GAN的链接。
项目实战
接下来我们通过一个实战项目进行讲解,具体参考代码在最后引出了,代码部分就简单过一下,注释都写得比较清楚。
数据集预处理
使用的数据集里面的图片来源于ImageNet,该数据集共有17个数据包,本文只使用了其中的苹果橘子部分。图像被统一缩放为256×256像素大小,其中用于训练的苹果图片996张、橘子图片1020张,用于测试的苹果图片266张、橘子图片248张。
这里对数据进行了随机裁剪、水平随机翻转和归一化的预处理,为了将重点聚焦到模型,此处将数据预处理后的结果转换为 MindRecord 格式的数据,以省略大部分数据预处理的代码。
python
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/CycleGAN_apple2orange.zip"
download(url, ".", kind="zip", replace=True)此处我们用MindDataset接口读取和处理数据集
python
from mindspore.dataset import MindDataset
# 读取MindRecord格式数据
name_mr = "./CycleGAN_apple2orange/apple2orange_train.mindrecord"
data = MindDataset(dataset_files=name_mr)
print("Datasize: ", data.get_dataset_size())
batch_size = 1
dataset = data.batch(batch_size)
datasize = dataset.get_dataset_size()可视化
通过 create_dict_iterator 函数将数据转换成字典迭代器,然后使用 matplotlib 模块可视化部分训练数据。
这部分都是常用的绘图代码,所以注释没有写太多。
python
import numpy as np
import matplotlib.pyplot as plt
mean = 0.5 * 255
std = 0.5 * 255
plt.figure(figsize=(12, 5), dpi=60)
for i, data in enumerate(dataset.create_dict_iterator()):
if i < 5:
show_images_a = data["image_A"].asnumpy()
show_images_b = data["image_B"].asnumpy()
plt.subplot(2, 5, i+1)
show_images_a = (show_images_a[0] * std + mean).astype(np.uint8).transpose((1, 2, 0))
plt.imshow(show_images_a)
plt.axis("off")
plt.subplot(2, 5, i+6)
show_images_b = (show_images_b[0] * std + mean).astype(np.uint8).transpose((1, 2, 0))
plt.imshow(show_images_b)
plt.axis("off")
else:
break
plt.show()
构建生成器
本案例生成器的模型结构参考的 ResNet 模型的结构,参考原论文,对于128×128大小的输入图片采用6个残差块相连,图片大小为256×256以上的需要采用9个残差块相连,所以本文网络有9个残差块相连,超参数 n_layers 参数控制残差块数。
生成器的结构如下所示:

python
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Normal
# 初始化权重的标准差为0.02的正态分布
weight_init = Normal(sigma=0.02)
class ConvNormReLU(nn.Cell):
"""
包含卷积、归一化及ReLU激活的模块。
参数:
input_channel (int): 输入通道数。
out_planes (int): 输出通道数。
kernel_size (int, 可选): 卷积核大小,默认为4。
stride (int, 可选): 步长,默认为2。
alpha (float, 可选): LeakyReLU的负斜率,默认为0.2。
norm_mode (str, 可选): 归一化模式,可选'instance'或'batch',默认为'instance'。
pad_mode (str, 可选): 填充模式,可选'CONSTANT'或其他模式,默认为'CONSTANT'。
use_relu (bool, 可选): 是否使用ReLU,默认为True。
padding (int, 可选): 填充大小,默认根据kernel_size计算。
transpose (bool, 可选): 是否使用转置卷积,默认为False。
返回:
Tensor: 经过卷积、归一化及ReLU后的输出张量。
"""
def __init__(self, input_channel, out_planes, kernel_size=4, stride=2, alpha=0.2, norm_mode='instance',
pad_mode='CONSTANT', use_relu=True, padding=None, transpose=False):
super(ConvNormReLU, self).__init__()
# 根据norm_mode选择不同的归一化层
norm = nn.BatchNorm2d(out_planes, affine=(norm_mode != 'instance'))
# 根据是否使用实例归一化来设置是否有偏置项
has_bias = (norm_mode == 'instance')
# 设置填充大小
if padding is None:
padding = (kernel_size - 1) // 2
# 根据pad_mode和transpose标志构建卷积层
if pad_mode == 'CONSTANT':
conv = nn.Conv2dTranspose if transpose else nn.Conv2d
conv = conv(input_channel, out_planes, kernel_size, stride, pad_mode='same' if transpose else 'pad',
has_bias=has_bias, weight_init=weight_init)
layers = [conv, norm]
else:
paddings = ((0, 0), (0, 0), (padding, padding), (padding, padding))
pad = nn.Pad(paddings=paddings, mode=pad_mode)
conv = nn.Conv2dTranspose if transpose else nn.Conv2d
conv = conv(input_channel, out_planes, kernel_size, stride, pad_mode='pad',
has_bias=has_bias, weight_init=weight_init)
layers = [pad, conv, norm]
# 添加ReLU层
if use_relu:
relu = nn.ReLU() if alpha <= 0 else nn.LeakyReLU(alpha)
layers.append(relu)
self.features = nn.SequentialCell(layers)
def construct(self, x):
"""
构建并返回经过卷积、归一化及ReLU处理后的输出。
参数:
x (Tensor): 输入张量。
返回:
Tensor: 处理后的输出张量。
"""
output = self.features(x)
return output
class ResidualBlock(nn.Cell):
"""
残差块,包含两个ConvNormReLU模块和一个残差连接。
参数:
dim (int): 输入和输出的通道数。
norm_mode (str, 可选): 归一化模式,可选'instance'或'batch',默认为'instance'。
dropout (bool, 可选): 是否使用Dropout,默认为False。
pad_mode (str, 可选): 填充模式,可选'CONSTANT'或其他模式,默认为'CONSTANT'。
返回:
Tensor: 经过残差连接后的输出张量。
"""
def __init__(self, dim, norm_mode='instance', dropout=False, pad_mode="CONSTANT"):
super(ResidualBlock, self).__init__()
self.conv1 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode)
self.conv2 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode, use_relu=False)
self.dropout = nn.Dropout(p=0.5) if dropout else None
def construct(self, x):
"""
构建并返回经过残差块处理后的输出。
参数:
x (Tensor): 输入张量。
返回:
Tensor: 处理后的输出张量。
"""
out = self.conv1(x)
if self.dropout:
out = self.dropout(out)
out = self.conv2(out)
return x + out
class ResNetGenerator(nn.Cell):
"""
基于ResNet架构的生成器网络。
参数:
input_channel (int, 可选): 输入通道数,默认为3。
output_channel (int, 可选): 初始输出通道数,默认为64。
n_layers (int, 可选): 残差块的数量,默认为9。
alpha (float, 可选): LeakyReLU的负斜率,默认为0.2。
norm_mode (str, 可选): 归一化模式,可选'instance'或'batch',默认为'instance'。
dropout (bool, 可选): 是否使用Dropout,默认为False。
pad_mode (str, 可选): 填充模式,可选'CONSTANT'或其他模式,默认为'CONSTANT'。
返回:
Tensor: 经过生成器处理后的输出张量。
"""
def __init__(self, input_channel=3, output_channel=64, n_layers=9, alpha=0.2, norm_mode='instance', dropout=False,
pad_mode="CONSTANT"):
super(ResNetGenerator, self).__init__()
self.conv_in = ConvNormReLU(input_channel, output_channel, 7, 1, alpha, norm_mode, pad_mode=pad_mode)
self.down_1 = ConvNormReLU(output_channel, output_channel * 2, 3, 2, alpha, norm_mode)
self.down_2 = ConvNormReLU(output_channel * 2, output_channel * 4, 3, 2, alpha, norm_mode)
layers = [ResidualBlock(output_channel * 4, norm_mode, dropout=dropout, pad_mode=pad_mode) for _ in range(n_layers)]
self.residuals = nn.SequentialCell(layers)
self.up_2 = ConvNormReLU(output_channel * 4, output_channel * 2, 3, 2, alpha, norm_mode, transpose=True)
self.up_1 = ConvNormReLU(output_channel * 2, output_channel, 3, 2, alpha, norm_mode, transpose=True)
if pad_mode == "CONSTANT":
self.conv_out = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad',
padding=3, weight_init=weight_init)
else:
pad = nn.Pad(paddings=((0, 0), (0, 0), (3, 3), (3, 3)), mode=pad_mode)
conv = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad', weight_init=weight_init)
self.conv_out = nn.SequentialCell([pad, conv])
def construct(self, x):
"""
构建并返回经过生成器处理后的输出。
参数:
x (Tensor): 输入张量。
返回:
Tensor: 处理后的输出张量。
"""
x = self.conv_in(x)
x = self.down_1(x)
x = self.down_2(x)
x = self.residuals(x)
x = self.up_2(x)
x = self.up_1(x)
output = self.conv_out(x)
return ops.tanh(output)
# 实例化生成器
net_rg_a = ResNetGenerator()
net_rg_a.update_parameters_name('net_rg_a.')
net_rg_b = ResNetGenerator()
net_rg_b.update_parameters_name('net_rg_b.')这个结构搭建的还是比较清晰的,没有昨天看CGAN痛苦。这段执行完了之后我们可以直接把网络结构打印出来对照查看。
python
print(net_rg_a)打出来网络结构可能会很多,其中ResidualBlock有好几层,注意看ResNetGenerator方法
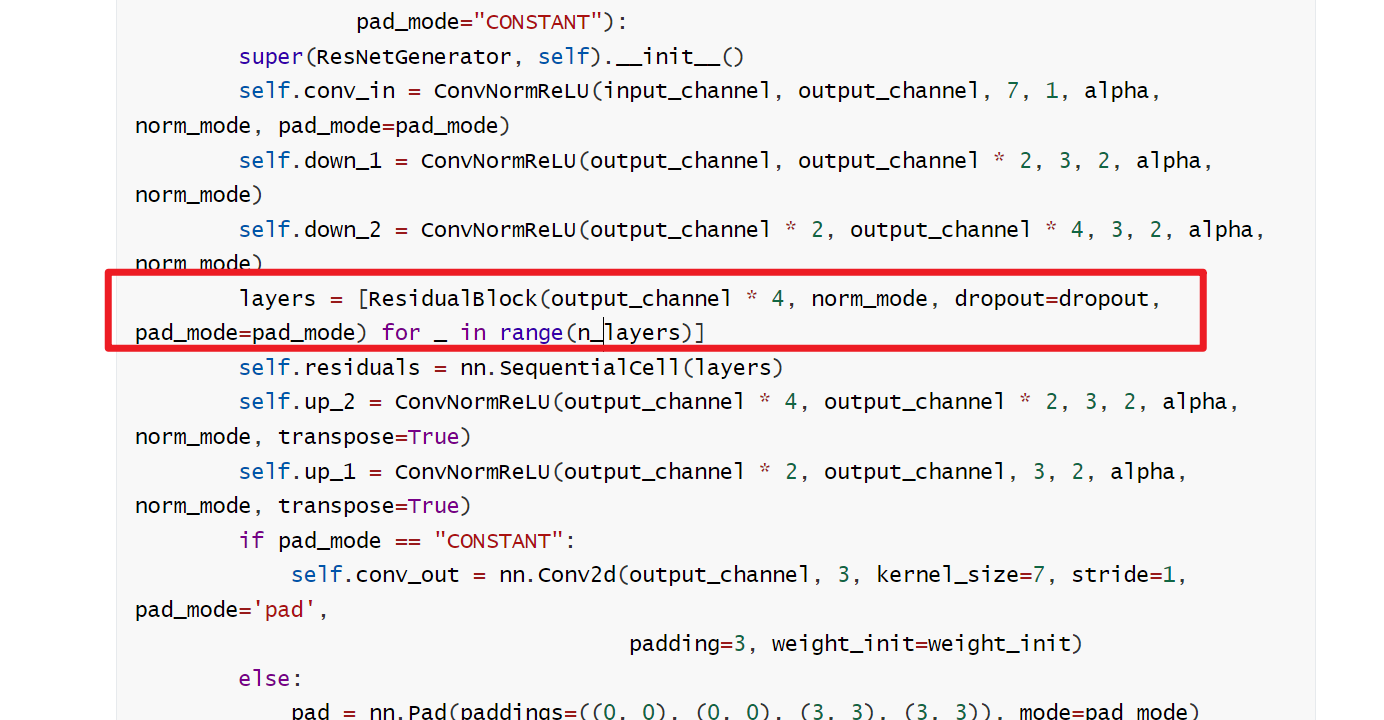
构建判别器
判别器其实是一个二分类网络模型,输出判定该图像为真实图的概率。网络模型使用的是 Patch 大小为 70x70 的 PatchGANs 模型。通过一系列的 Conv2d 、 BatchNorm2d 和 LeakyReLU 层对其进行处理,最后通过 Sigmoid 激活函数得到最终概率。
python
# 定义判别器类,用于判断输入的图像是否真实
class Discriminator(nn.Cell):
def __init__(self, input_channel=3, output_channel=64, n_layers=3, alpha=0.2, norm_mode='instance'):
"""
初始化判别器。
参数:
input_channel (int): 输入图像的通道数,默认为3。
output_channel (int): 第一个卷积层的输出通道数,默认为64。
n_layers (int): 卷积层的数量,默认为3。
alpha (float): LeakyReLU激活函数的负斜率,默认为0.2。
norm_mode (str): 归一化模式,默认为'instance'。
判别器由多个卷积层、归一化层和LeakyReLU激活层组成。
"""
super(Discriminator, self).__init__()
kernel_size = 4
# 第一层卷积和激活
layers = [nn.Conv2d(input_channel, output_channel, kernel_size, 2, pad_mode='pad', padding=1, weight_init=weight_init),
nn.LeakyReLU(alpha)]
nf_mult = output_channel
# 中间层卷积、归一化和激活
for i in range(1, n_layers):
nf_mult_prev = nf_mult
nf_mult = min(2 ** i, 8) * output_channel
layers.append(ConvNormReLU(nf_mult_prev, nf_mult, kernel_size, 2, alpha, norm_mode, padding=1))
# 最后一层卷积、归一化和激活,注意步长为1
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8) * output_channel
layers.append(ConvNormReLU(nf_mult_prev, nf_mult, kernel_size, 1, alpha, norm_mode, padding=1))
# 输出层卷积,输出通道数为1,步长为1
layers.append(nn.Conv2d(nf_mult, 1, kernel_size, 1, pad_mode='pad', padding=1, weight_init=weight_init))
# 将所有层连接成一个序列模型
self.features = nn.SequentialCell(layers)
def construct(self, x):
"""
前向传播函数。
参数:
x (Tensor): 输入的图像数据。
返回:
Tensor: 判别器的输出,表示输入图像的真实性。
"""
output = self.features(x)
return output
# 初始化两个判别器实例,分别用于判别A域和B域的图像
net_d_a = Discriminator()
net_d_a.update_parameters_name('net_d_a.')
net_d_b = Discriminator()
net_d_b.update_parameters_name('net_d_b.')优化器和损失函数
这里刚才也进行了讲解,要注意的是,每个网络的优化器都得单独定义。

python
# 构建生成器,判别器优化器
optimizer_rg_a = nn.Adam(net_rg_a.trainable_params(), learning_rate=0.0002, beta1=0.5)
optimizer_rg_b = nn.Adam(net_rg_b.trainable_params(), learning_rate=0.0002, beta1=0.5)
optimizer_d_a = nn.Adam(net_d_a.trainable_params(), learning_rate=0.0002, beta1=0.5)
optimizer_d_b = nn.Adam(net_d_b.trainable_params(), learning_rate=0.0002, beta1=0.5)
# GAN网络损失函数,这里最后一层不使用sigmoid函数
loss_fn = nn.MSELoss(reduction='mean')
l1_loss = nn.L1Loss("mean")
def gan_loss(predict, target):
target = ops.ones_like(predict) * target
loss = loss_fn(predict, target)
return loss前向计算
为了减少模型振荡1,这里遵循 Shrivastava 等人的策略2,使用生成器生成图像的历史数据而不是生成器生成的最新图像数据来更新鉴别器。这里创建 image_pool 函数,保留了一个图像缓冲区,用于存储生成器生成前的50个图像。
python
import mindspore as ms
# 前向计算
def generator(img_a, img_b):
"""
生成器函数,用于生成假图像并对图像进行重建和身份转换测试。
参数:
img_a: Tensor, 输入图像A。
img_b: Tensor, 输入图像B。
返回:
fake_a: Tensor, 生成的假图像A。
fake_b: Tensor, 生成的假图像B。
rec_a: Tensor, 重建后的图像A。
rec_b: Tensor, 重建后的图像B。
identity_a: Tensor, 图像A的身份转换结果。
identity_b: Tensor, 图像B的身份转换结果。
"""
fake_a = net_rg_b(img_b)
fake_b = net_rg_a(img_a)
rec_a = net_rg_b(fake_b)
rec_b = net_rg_a(fake_a)
identity_a = net_rg_b(img_a)
identity_b = net_rg_a(img_b)
return fake_a, fake_b, rec_a, rec_b, identity_a, identity_b
lambda_a = 10.0
lambda_b = 10.0
lambda_idt = 0.5
def generator_forward(img_a, img_b):
"""
生成器的前向传播函数,计算生成器的损失。
参数:
img_a: Tensor, 输入图像A。
img_b: Tensor, 输入图像B。
返回:
fake_a: Tensor, 生成的假图像A。
fake_b: Tensor, 生成的假图像B。
loss_g: Tensor, 总生成器损失。
loss_g_a: Tensor, 生成器A的对抗损失。
loss_g_b: Tensor, 生成器B的对抗损失。
loss_c_a: Tensor, 生成器A的循环一致性损失。
loss_c_b: Tensor, 生成器B的循环一致性损失。
loss_idt_a: Tensor, 生成器A的身份损失。
loss_idt_b: Tensor, 生成器B的身份损失。
"""
true = Tensor(True, dtype.bool_)
fake_a, fake_b, rec_a, rec_b, identity_a, identity_b = generator(img_a, img_b)
loss_g_a = gan_loss(net_d_b(fake_b), true)
loss_g_b = gan_loss(net_d_a(fake_a), true)
loss_c_a = l1_loss(rec_a, img_a) * lambda_a
loss_c_b = l1_loss(rec_b, img_b) * lambda_b
loss_idt_a = l1_loss(identity_a, img_a) * lambda_a * lambda_idt
loss_idt_b = l1_loss(identity_b, img_b) * lambda_b * lambda_idt
loss_g = loss_g_a + loss_g_b + loss_c_a + loss_c_b + loss_idt_a + loss_idt_b
return fake_a, fake_b, loss_g, loss_g_a, loss_g_b, loss_c_a, loss_c_b, loss_idt_a, loss_idt_b
def generator_forward_grad(img_a, img_b):
"""
生成器前向传播的梯度计算函数。
参数:
img_a: Tensor, 输入图像A。
img_b: Tensor, 输入图像B。
返回:
loss_g: Tensor, 总生成器损失的梯度。
"""
_, _, loss_g, _, _, _, _, _, _ = generator_forward(img_a, img_b)
return loss_g
def discriminator_forward(img_a, img_b, fake_a, fake_b):
"""
判别器的前向传播函数,计算判别器的损失。
参数:
img_a: Tensor, 真实图像A。
img_b: Tensor, 真实图像B。
fake_a: Tensor, 生成的假图像A。
fake_b: Tensor, 生成的假图像B。
返回:
loss_d: Tensor, 总判别器损失。
"""
false = Tensor(False, dtype.bool_)
true = Tensor(True, dtype.bool_)
d_fake_a = net_d_a(fake_a)
d_img_a = net_d_a(img_a)
d_fake_b = net_d_b(fake_b)
d_img_b = net_d_b(img_b)
loss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true)
loss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true)
loss_d = (loss_d_a + loss_d_b) * 0.5
return loss_d
def discriminator_forward_a(img_a, fake_a):
"""
判别器A的前向传播函数,计算判别器A的损失。
参数:
img_a: Tensor, 真实图像A。
fake_a: Tensor, 生成的假图像A。
返回:
loss_d_a: Tensor, 判别器A的损失。
"""
false = Tensor(False, dtype.bool_)
true = Tensor(True, dtype.bool_)
d_fake_a = net_d_a(fake_a)
d_img_a = net_d_a(img_a)
loss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true)
return loss_d_a
def discriminator_forward_b(img_b, fake_b):
"""
判别器B的前向传播函数,计算判别器B的损失。
参数:
img_b: Tensor, 真实图像B。
fake_b: Tensor, 生成的假图像B。
返回:
loss_d_b: Tensor, 判别器B的损失。
"""
false = Tensor(False, dtype.bool_)
true = Tensor(True, dtype.bool_)
d_fake_b = net_d_b(fake_b)
d_img_b = net_d_b(img_b)
loss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true)
return loss_d_b
# 保留了一个图像缓冲区,用来存储之前创建的50个图像
pool_size = 50
def image_pool(images):
"""
图像缓冲池函数,用于保存和随机返回假图像。
参数:
images: list of Tensor, 新生成的图像列表。
返回:
output: Tensor, 从缓冲池中选出的图像集合。
"""
num_imgs = 0
image1 = []
if isinstance(images, Tensor):
images = images.asnumpy()
return_images = []
for image in images:
if num_imgs < pool_size:
num_imgs = num_imgs + 1
image1.append(image)
return_images.append(image)
else:
if random.uniform(0, 1) > 0.5:
random_id = random.randint(0, pool_size - 1)
tmp = image1[random_id].copy()
image1[random_id] = image
return_images.append(tmp)
else:
return_images.append(image)
output = Tensor(return_images, ms.float32)
if output.ndim != 4:
raise ValueError("img should be 4d, but get shape {}".format(output.shape))
return output计算梯度和反向传播
python
from mindspore import value_and_grad
# 实例化求梯度的方法
grad_g_a = value_and_grad(generator_forward_grad, None, net_rg_a.trainable_params())
grad_g_b = value_and_grad(generator_forward_grad, None, net_rg_b.trainable_params())
grad_d_a = value_and_grad(discriminator_forward_a, None, net_d_a.trainable_params())
grad_d_b = value_and_grad(discriminator_forward_b, None, net_d_b.trainable_params())
# 计算生成器的梯度,反向传播更新参数
def train_step_g(img_a, img_b):
# 在生成器训练步骤中,冻结判别器的梯度计算
net_d_a.set_grad(False)
net_d_b.set_grad(False)
# 生成器前向计算并获取损失
fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib = generator_forward(img_a, img_b)
# 计算生成器A和B的梯度
_, grads_g_a = grad_g_a(img_a, img_b)
_, grads_g_b = grad_g_b(img_a, img_b)
# 使用优化器更新生成器A和B的参数
optimizer_rg_a(grads_g_a)
optimizer_rg_b(grads_g_b)
return fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib
# 计算判别器的梯度,反向传播更新参数
def train_step_d(img_a, img_b, fake_a, fake_b):
# 在判别器训练步骤中,开启判别器的梯度计算
net_d_a.set_grad(True)
net_d_b.set_grad(True)
# 计算判别器A和B的损失和梯度
loss_d_a, grads_d_a = grad_d_a(img_a, fake_a)
loss_d_b, grads_d_b = grad_d_b(img_b, fake_b)
# 计算判别器的平均损失
loss_d = (loss_d_a + loss_d_b) * 0.5
# 使用优化器更新判别器A和B的参数
optimizer_d_a(grads_d_a)
optimizer_d_b(grads_d_b)
return loss_d模型训练
训练分为两个主要部分:训练判别器和训练生成器,在前文的判别器损失函数中,论文采用了最小二乘损失代替负对数似然目标。
- 训练判别器:训练判别器的目的是最大程度地提高判别图像真伪的概率。按照论文的方法需要训练判别器来最小化 𝐸𝑦−𝑝𝑑𝑎𝑡𝑎(𝑦)(𝐷(𝑦)−1)2Ey−pdata(y)(D(y)−1)2 ;
- 训练生成器:如 CycleGAN 论文所述,我们希望通过最小化 𝐸𝑥−𝑝𝑑𝑎𝑡𝑎(𝑥)(𝐷(𝐺(𝑥)−1)2Ex−pdata(x)(D(G(x)−1)2 来训练生成器,以产生更好的虚假图像。
python
%%time
import os
import time
import random
import numpy as np
from PIL import Image
from mindspore import Tensor, save_checkpoint
from mindspore import dtype
# 由于时间原因,epochs设置为1,可根据需求进行调整
epochs = 1
save_step_num = 80
save_checkpoint_epochs = 1
save_ckpt_dir = './train_ckpt_outputs/'
print('Start training!')
# 开始训练过程
for epoch in range(epochs):
g_loss = []
d_loss = []
start_time_e = time.time()
# 遍历数据集中的每个样本
for step, data in enumerate(dataset.create_dict_iterator()):
start_time_s = time.time()
# 从数据中提取图像A和B
img_a = data["image_A"]
img_b = data["image_B"]
# 训练生成器,并得到生成的图像及损失
res_g = train_step_g(img_a, img_b)
fake_a = res_g[0]
fake_b = res_g[1]
# 训练判别器,并得到损失
res_d = train_step_d(img_a, img_b, image_pool(fake_a), image_pool(fake_b))
loss_d = float(res_d.asnumpy())
step_time = time.time() - start_time_s
# 将生成器和判别器的损失分别记录
res = []
for item in res_g[2:]:
res.append(float(item.asnumpy()))
g_loss.append(res[0])
d_loss.append(loss_d)
# 每隔一定步数,打印训练信息
if step % save_step_num == 0:
print(f"Epoch:[{int(epoch + 1):>3d}/{int(epochs):>3d}], "
f"step:[{int(step):>4d}/{int(datasize):>4d}], "
f"time:{step_time:>3f}s,\n"
f"loss_g:{res[0]:.2f}, loss_d:{loss_d:.2f}, "
f"loss_g_a: {res[1]:.2f}, loss_g_b: {res[2]:.2f}, "
f"loss_c_a: {res[3]:.2f}, loss_c_b: {res[4]:.2f}, "
f"loss_idt_a: {res[5]:.2f}, loss_idt_b: {res[6]:.2f}")
# 计算并打印每个epoch的平均损失和时间信息
epoch_cost = time.time() - start_time_e
per_step_time = epoch_cost / datasize
mean_loss_d, mean_loss_g = sum(d_loss) / datasize, sum(g_loss) / datasize
print(f"Epoch:[{int(epoch + 1):>3d}/{int(epochs):>3d}], "
f"epoch time:{epoch_cost:.2f}s, per step time:{per_step_time:.2f}, "
f"mean_g_loss:{mean_loss_g:.2f}, mean_d_loss:{mean_loss_d :.2f}")
# 每隔一定epoch数,保存检查点
if epoch % save_checkpoint_epochs == 0:
os.makedirs(save_ckpt_dir, exist_ok=True)
save_checkpoint(net_rg_a, os.path.join(save_ckpt_dir, f"g_a_{epoch}.ckpt"))
save_checkpoint(net_rg_b, os.path.join(save_ckpt_dir, f"g_b_{epoch}.ckpt"))
save_checkpoint(net_d_a, os.path.join(save_ckpt_dir, f"d_a_{epoch}.ckpt"))
save_checkpoint(net_d_b, os.path.join(save_ckpt_dir, f"d_b_{epoch}.ckpt"))
print('End of training!')模型推理
下面我们通过加载生成器网络模型参数文件来对原图进行风格迁移,结果中第一行为原图,第二行为对应生成的结果图。
python
import os
from PIL import Image
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
from mindspore import load_checkpoint, load_param_into_net
import matplotlib.pyplot as plt
import numpy as np
# 加载权重文件
# 参数 net:网络模型
# 参数 ckpt_dir:权重文件目录
# 无返回值
def load_ckpt(net, ckpt_dir):
param_GA = load_checkpoint(ckpt_dir)
load_param_into_net(net, param_GA)
g_a_ckpt = './CycleGAN_apple2orange/ckpt/g_a.ckpt'
g_b_ckpt = './CycleGAN_apple2orange/ckpt/g_b.ckpt'
load_ckpt(net_rg_a, g_a_ckpt)
load_ckpt(net_rg_b, g_b_ckpt)
# 图片推理
fig = plt.figure(figsize=(11, 2.5), dpi=100)
# 推理函数
# 参数 dir_path:图片目录路径
# 参数 net:网络模型
# 参数 a: subplot起始位置偏移量
# 无返回值
def eval_data(dir_path, net, a):
# 读取图片生成器
def read_img():
for dir in os.listdir(dir_path):
path = os.path.join(dir_path, dir)
img = Image.open(path).convert('RGB')
yield img, dir
dataset = ds.GeneratorDataset(read_img, column_names=["image", "image_name"])
trans = [vision.Resize((256, 256)), vision.Normalize(mean=[0.5 * 255] * 3, std=[0.5 * 255] * 3), vision.HWC2CHW()]
dataset = dataset.map(operations=trans, input_columns=["image"])
dataset = dataset.batch(1)
for i, data in enumerate(dataset.create_dict_iterator()):
img = data["image"]
fake = net(img)
fake = (fake[0] * 0.5 * 255 + 0.5 * 255).astype(np.uint8).transpose((1, 2, 0))
img = (img[0] * 0.5 * 255 + 0.5 * 255).astype(np.uint8).transpose((1, 2, 0))
fig.add_subplot(2, 8, i+1+a)
plt.axis("off")
plt.imshow(img.asnumpy())
fig.add_subplot(2, 8, i+9+a)
plt.axis("off")
plt.imshow(fake.asnumpy())
eval_data('./CycleGAN_apple2orange/predict/apple', net_rg_a, 0)
eval_data('./CycleGAN_apple2orange/predict/orange', net_rg_b, 4)
plt.show()
参考代码:lab - JupyterLab (mindspore.cn)
参考资料: