检索增强生成(RAG)已被证明可以提高大型语言模型(LLMs)的事实准确性,但现有方法在有效使用检索到的证据方面往往存在有限的推理能力,特别是当使用开源LLMs时。
引入了一个新颖的框架OPEN-RAG,增强基于开源大型语言模型的检索增强推理的能力,特别是处理复杂推理任务时的有限推理能力。
方法
1.LLMs转MOE
模型转换:OPEN-RAG将任意密集的LLM转换为参数高效的稀疏专家混合(MoE)模型。该模型不仅能够自我反思,还能处理复杂的推理任务,包括单跳和多跳查询。
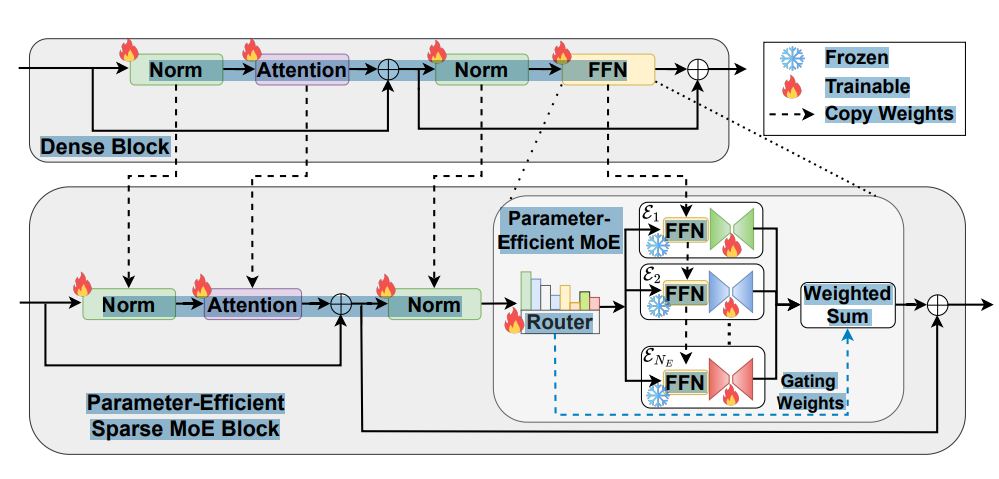
路由模块 :路由模块 R R R负责根据输入 x i n x_{in} xin的归一化输出选择Top-k专家。使用Softmax函数来计算每个专家的激活概率。
R(x_{in}) = \\text{Softmax}(\\text{Top-k}(W_R \\cdot x_{in}))
适配器模块 :每个专家的适配器模块 A e A_e Ae负责调整专家的输出,以更好地适应当前的查询。适配器模块的参数是在训练过程中更新的,而原始的FFN层参数保持不变。
A_e(x) = \\sigma(xW_{\\text{down}}^e)W_{\\text{up}}^e + x
输出 :MoE模型的输出 y y y是激活的专家输出的加权和 。
y = ∑ e = 1 N E R ( x ) e A e ( E e ( x ) ) y = \sum_{e=1}^{N_E} R(x)_e A_e(E_e(x)) y=e=1∑NER(x)eAe(Ee(x))
训练策略:在微调过程中使用QLora适配器 ,它具有负载平衡目标和标准条件语言建模目标。在训练和推理期间,只有部分专家(例如2个专家)是活跃的。
通过上述步骤,OPEN-RAG成功地将一个密集型的大型语言模型转换为一个参数高效的稀疏混合专家模型,使其能够更有效地处理复杂的推理任务。这种转换不仅提高了模型的性能,还保持了模型的规模和参数效率。
2.混合自适应检索
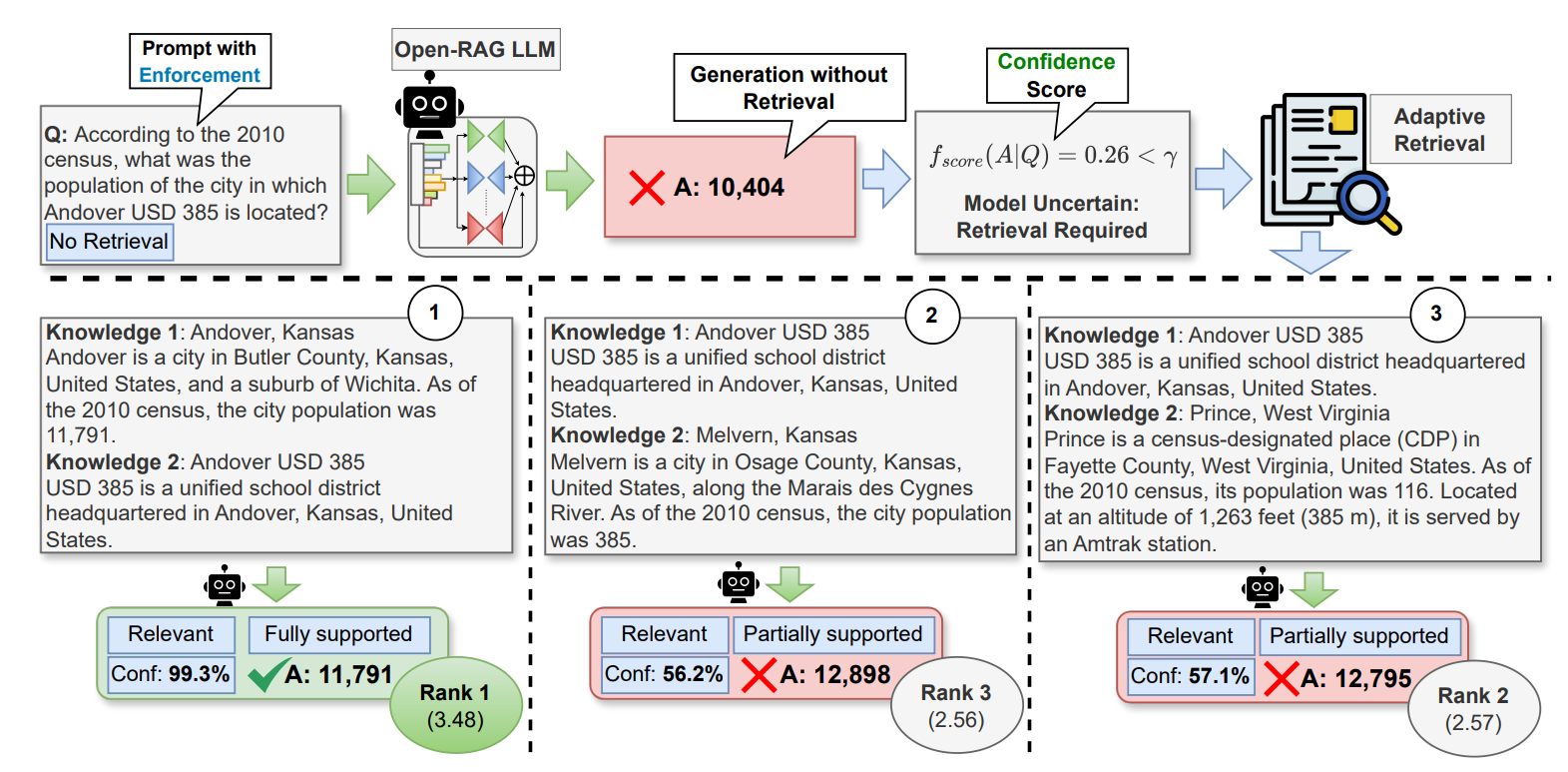
大型语言模型(LLMs)在处理复杂问题时,需要从外部知识源检索信息以提高回答的准确性。然而,频繁的检索会降低模型的推理速度,因此需要一种方法来动态决定是否需要进行检索。
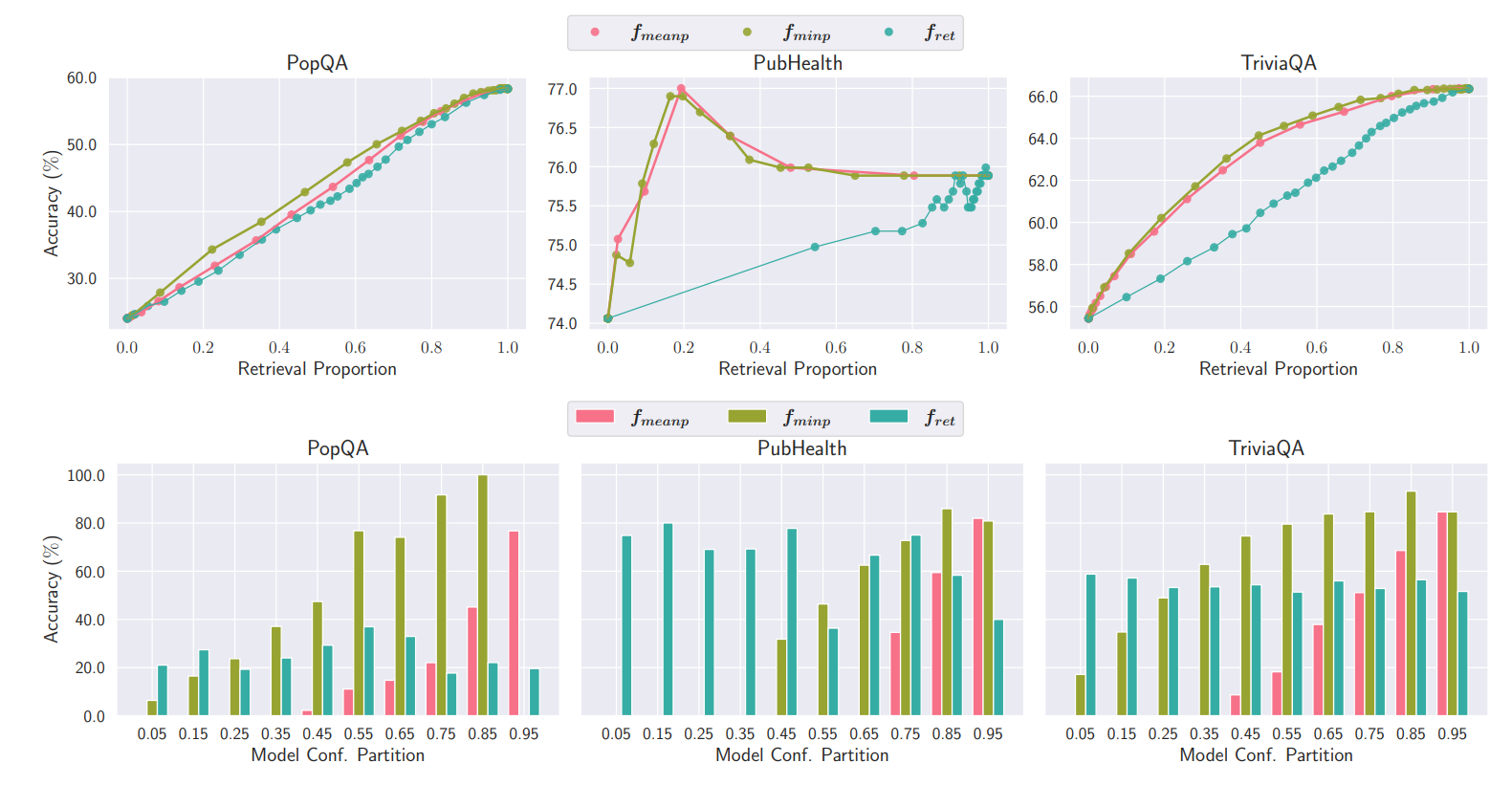
提出了一种混合自适应检索方法,根据模型置信度确定检索的必要性,并在性能和速度之间取得平衡。该方法通过生成检索/无检索反射令牌来测量在强制无检索设置下输出的置信度,并根据这些置信度决定是否进行检索。
OPEN-RAG模型在训练时学习生成**检索(RT)和不检索(NoRT)**反射令牌。在推理时评估模型生成的输出序列的置信度。
设计了两种不同的置信度评分函数:
-
fminp:输出序列中各个标记概率的最小值。
-
fmeanp:输出序列中各个标记概率的几何平均值。
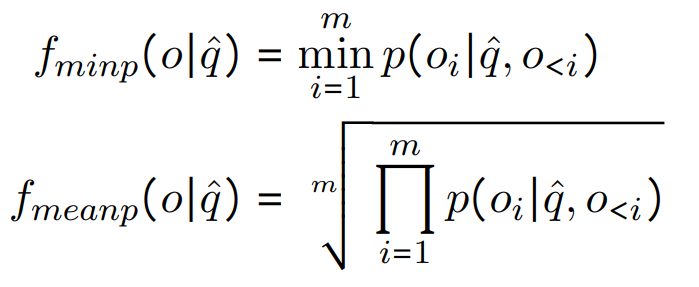
并且,使用一个可调的阈值γ来控制检索频率。如果置信度评分低于阈值γ,则触发检索。
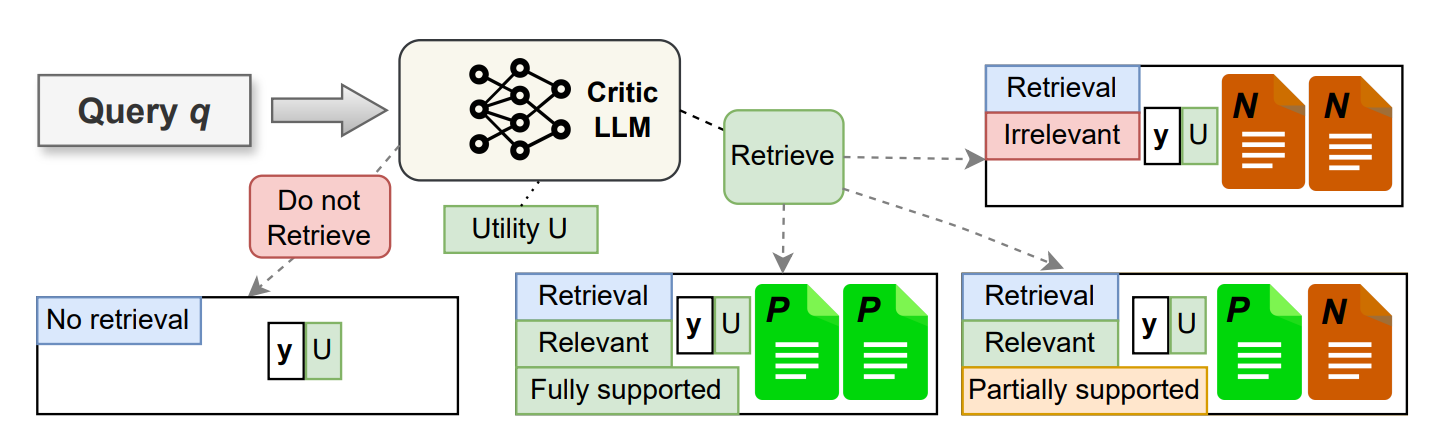
3.推理过程
-
接收输入查询:模型接收一个用户输入的查询(q)。
-
生成检索令牌:模型首先判断是否需要进行检索来更好地回答这个查询,并生成相应的检索令牌(RT/NoRT)。
-
无检索生成答案:如果模型决定不需要检索(NoRT),它将使用其内部知识(参数知识)来生成答案。
-
执行自适应检索 :如果模型决定需要检索(RT),则执行以下步骤:使用一个预定义的检索器 R R R从外部知识源 D D D检索最相关的文档。根据需要,可以执行单次检索或多跳检索。
-
处理检索到的文档:对于每个检索到的文档(s_t),模型执行以下操作:
- 生成相关性令牌(Relevant/Irrelevant),以判断文档是否与查询相关。
- 如果文档相关,生成基础令牌(Fully Supported/Partially Supported),以指示答案的准确性。
- 生成效用令牌(U:1-U:5),以评估文档对回答查询的有用性。
-
生成答案:模型并行处理所有检索到的文档,并根据相关性、基础和效用令牌的加权置信度分数对所有可能的答案进行排序。选择排名最高的答案作为最终输出。
-
输出最终答案 :模型输出最终的答案 y p r e d y_{pred} ypred。
实验
实验数据收集:为了使OPEN-RAG能够处理无需检索的查询以及需要检索的单跳和多跳查询,研究者构建了包含各种类型任务和数据集的训练数据。对于每个原始数据对(q,y),研究者使用真实标注或批评LLM生成带有反射令牌的新实例。
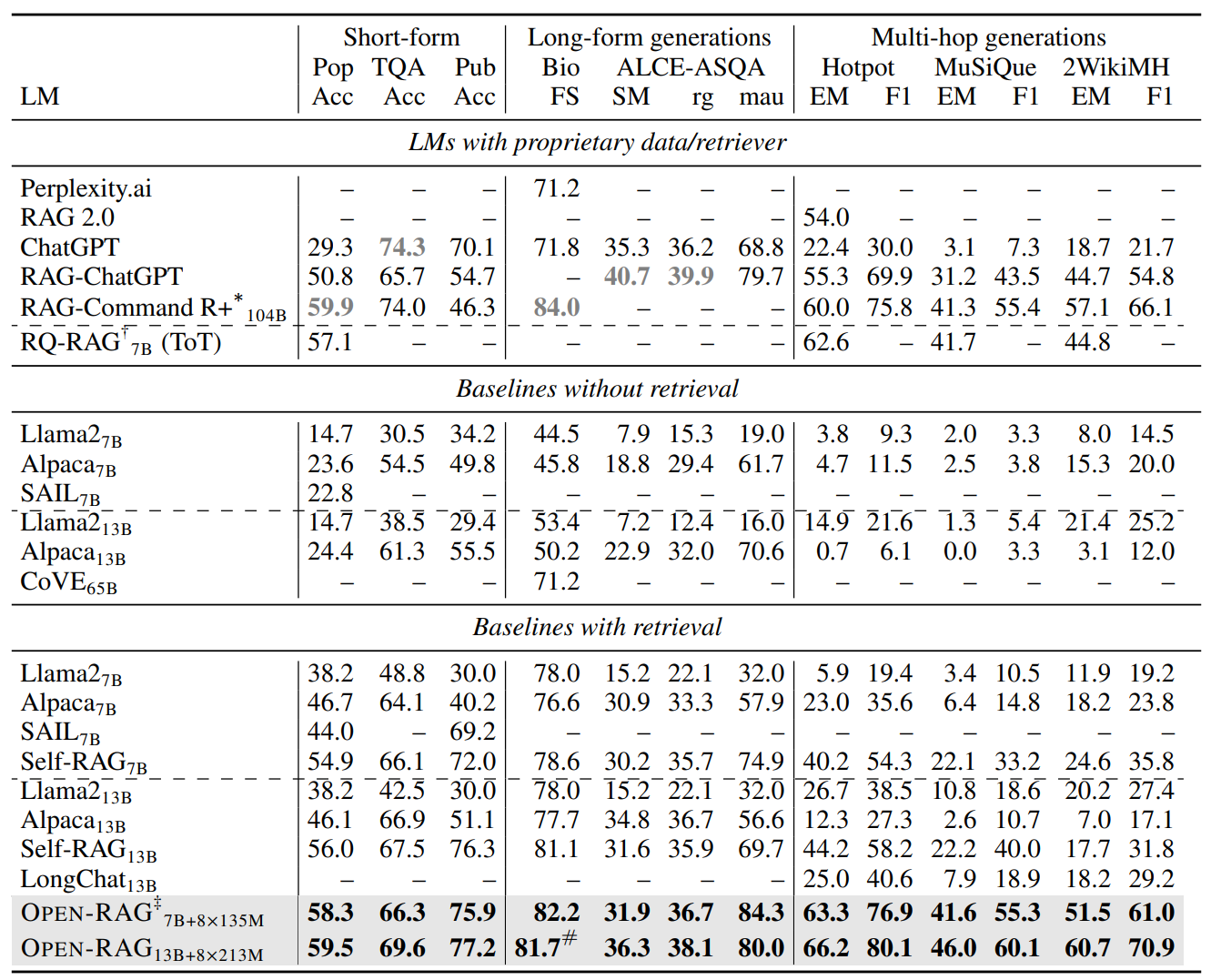
OPEN-RAG在所有监督微调的LLMs中展示了显著的性能提升,甚至在许多较大的模型(如65B CoVE)上也表现出色。特别是在多跳推理任务中,如HotpotQA
OPEN-RAG在有检索的开源RAG模型中也表现出色,始终优于现有的开源RAG模型,并且在大多数任务中达到了与专有模型相当的水平。

参考文献
- OPEN-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models,https://arxiv.org/pdf/2410.01782v1