文章目录
- 一、跨境电商数据的作用
-
- [1.1 市场趋势预测与洞察](#1.1 市场趋势预测与洞察)
- [1.2 消费者行为分析](#1.2 消费者行为分析)
- [1.3 库存管理优化](#1.3 库存管理优化)
- [1.4 定价策略制定](#1.4 定价策略制定)
- 二、爬取目标
- 三、环境准备
- 四、代理IP获取
-
- [4.1 为什么爬虫要用代理IP?](#4.1 为什么爬虫要用代理IP?)
- [4.2 为什么选择青果代理IP?](#4.2 为什么选择青果代理IP?)
- [4.3 青果代理IP领取](#4.3 青果代理IP领取)
- [4.4 利用代码获取IP](#4.4 利用代码获取IP)
- 五、爬虫代码实战
-
- [5.1 分析网页](#5.1 分析网页)
- [5.2 导入模块](#5.2 导入模块)
- [5.3 传入关键词设置翻页](#5.3 传入关键词设置翻页)
- [5.4 携带代理IP发送请求](#5.4 携带代理IP发送请求)
- [5.5 提取数据](#5.5 提取数据)
- [5.6 保存数据](#5.6 保存数据)
- [5.7 效果展示](#5.7 效果展示)
- [5.8 完整源码](#5.8 完整源码)
- 五、总结
一、跨境电商数据的作用
在全球化经济日益紧密的今天,跨境电商已成为推动国际贸易发展的重要引擎。随着技术的不断进步,数据已成为跨境电商领域中最宝贵的资源之一。跨境电商数据不仅反映了市场趋势、消费者行为,还为企业提供了宝贵的洞察,助力企业精准定位、优化运营、提升竞争力。以下是跨境电商数据在多个维度上的重要作用:
1.1 市场趋势预测与洞察
跨境电商数据能够帮助企业捕捉全球市场的最新动态,包括热门商品类别、消费者偏好变化、新兴市场需求等。通过分析历史销售数据、社交媒体趋势、搜索引擎热度等信息,企业可以预测未来市场走向,及时调整产品线和市场策略,抓住市场机遇。
1.2 消费者行为分析
深入了解目标市场的消费者行为是跨境电商成功的关键。数据可以帮助企业分析消费者的购买习惯、偏好、支付意愿以及购物路径等,从而定制化营销策略,提高转化率。例如,通过分析用户浏览记录、购买历史及反馈,企业可以实施个性化推荐,增强用户体验和忠诚度。
1.3 库存管理优化
跨境电商涉及跨国物流,库存管理尤为复杂。利用大数据分析,企业可以预测不同市场的销售峰值与低谷,实现库存的动态调整,减少库存积压和缺货风险,提高资金周转率。同时,数据还能帮助优化供应链布局,缩短配送时间,提升客户满意度。
1.4 定价策略制定
跨境电商平台上的价格竞争异常激烈。通过监测竞争对手价格、分析成本结构、评估市场需求弹性,企业可以制定更具竞争力的定价策略。数据驱动的定价不仅能最大化利润,还能在保持市场份额的同时,避免价格战带来的负面影响。
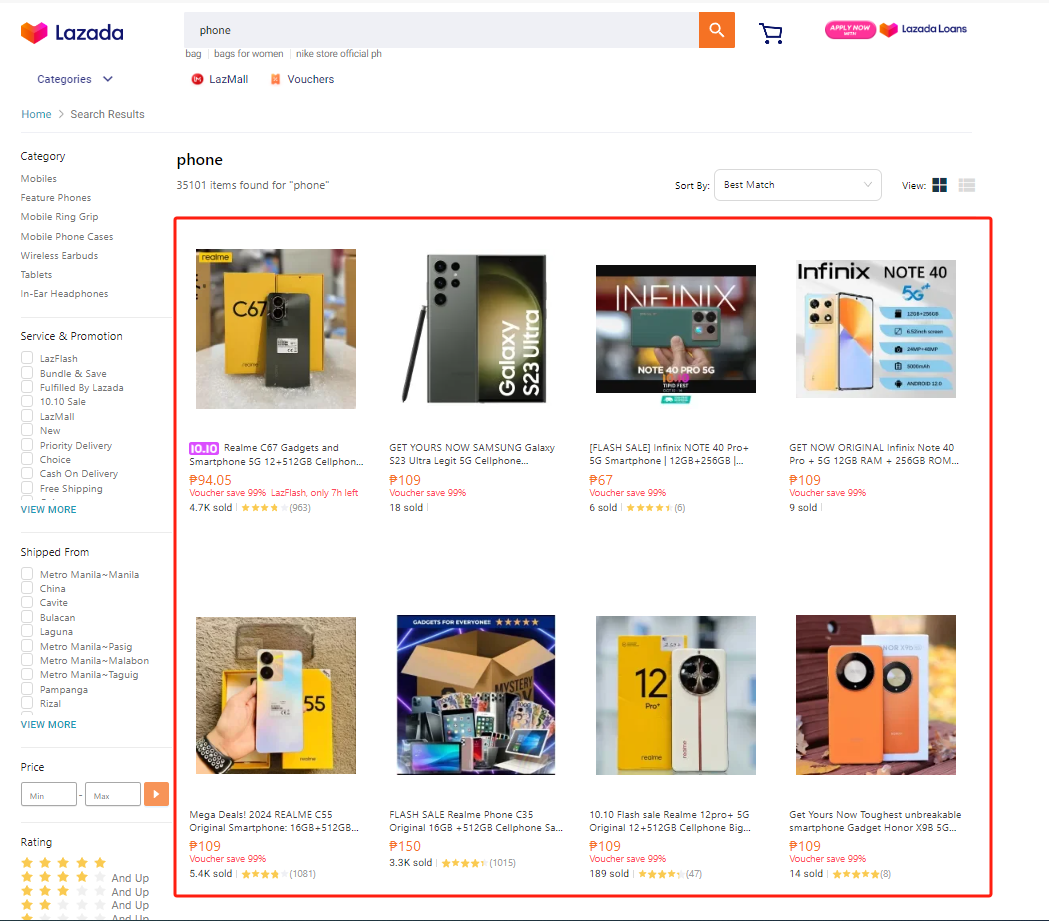
二、爬取目标
本次的爬取目标是Lazada电商平台输入关键词后的全部商品信息列表,并且进行翻页:
三、环境准备
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
python
pip install requests # 网页数据爬取
pip install pandas # 数据处理四、代理IP获取
4.1 为什么爬虫要用代理IP?
1、爬虫使用代理IP主要是为了避免因频繁访问同一网站而被识别并封禁真实IP,同时代理IP还能帮助绕过地域限制,提高数据采集的效率和成功率。
2、由于跨境电商数据量大,想要成功获取到数据就比必须要使用到代理IP。
4.2 为什么选择青果代理IP?
经常有写爬虫的粉丝跑来问我有没有比较靠谱的代理IP可以推荐一下?
我个人的话,长期写爬虫代码都是使用的是青果代理IP(青果代理IP免费体验),体验下来的感受有几点:
1、响应速度快,代理IP质量高
2、价格便宜,单个IP才0.0014元
3、套餐丰富,可以选择按天或者按量计费,选择灵活并且性价比高
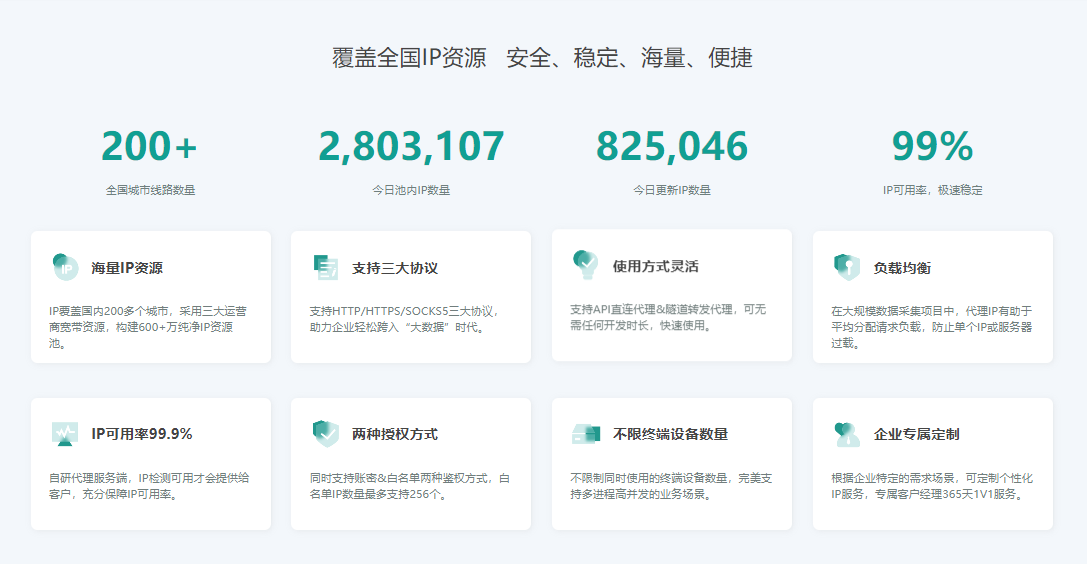
当然最重要的他们家短效代理、独享代理、隧道代理、静态代理都可以免费体验6小时,真的太香了!!!

感兴趣的小伙伴可以看下文跟着博主免费领取使用哟!
4.3 青果代理IP领取
1、打开官网地址注册一个账号:青果代理官网
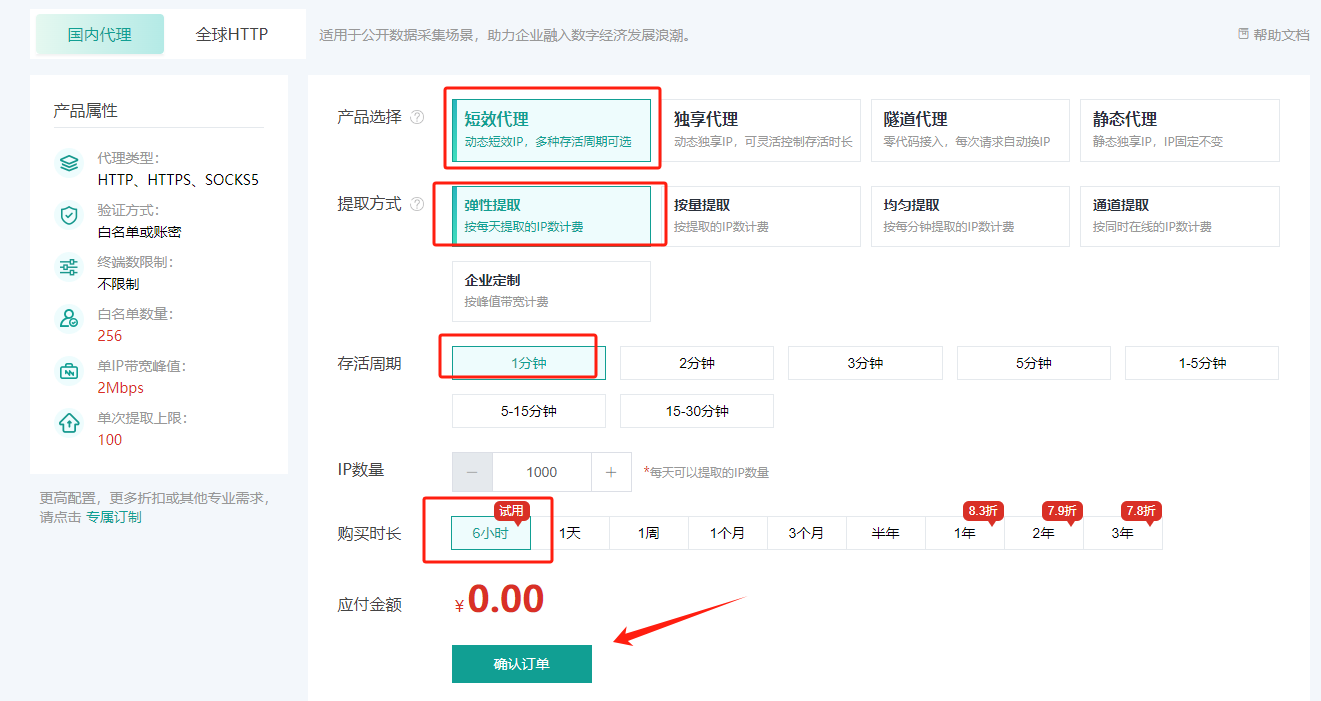
2、选择6小时的免费套餐:
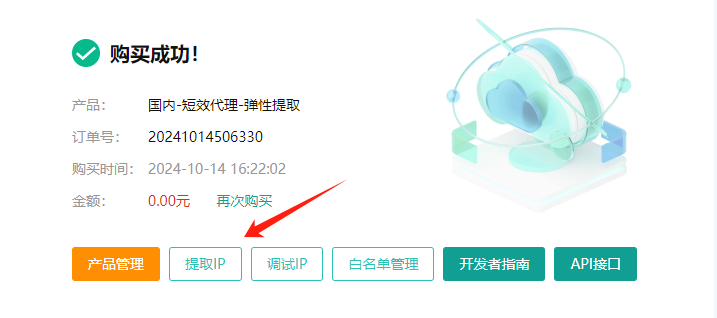
3、免费购买成功,点击提取IP:
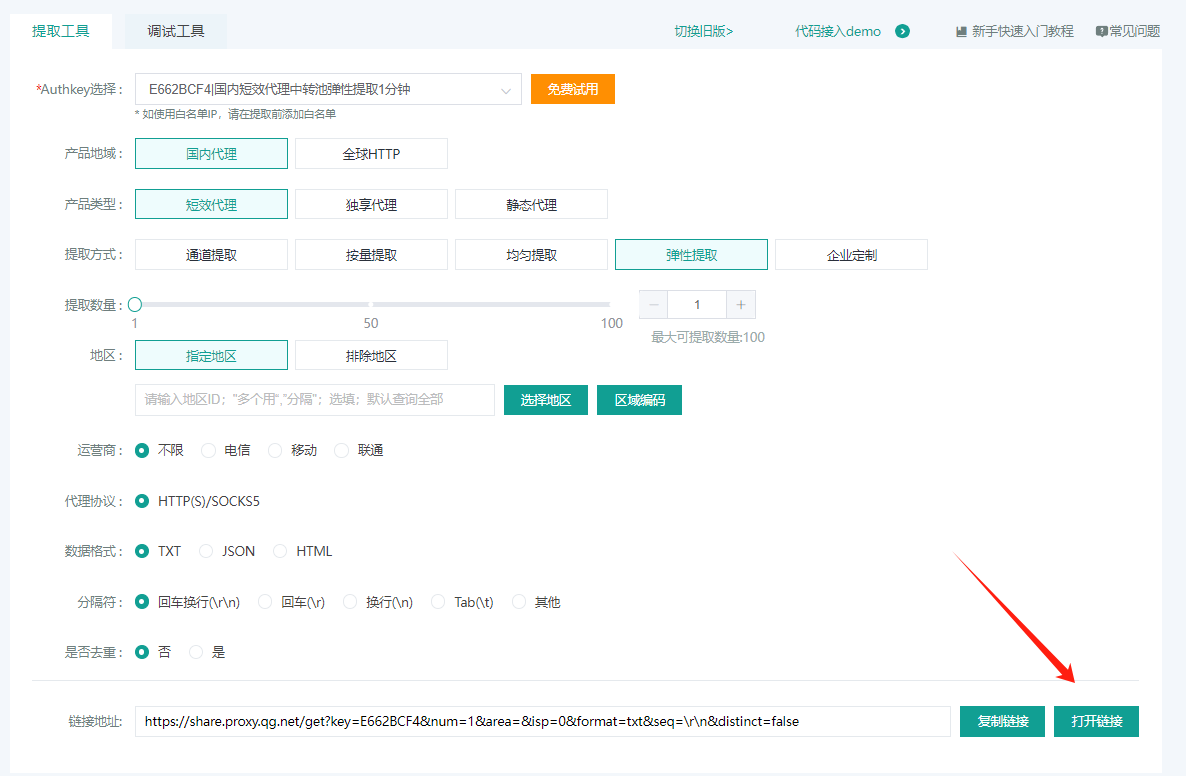
4、设置提取规则,这里默认即可,点击打开链接:
5、网页上成功返回IP,提取没问题:
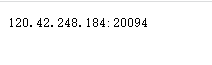
4.4 利用代码获取IP
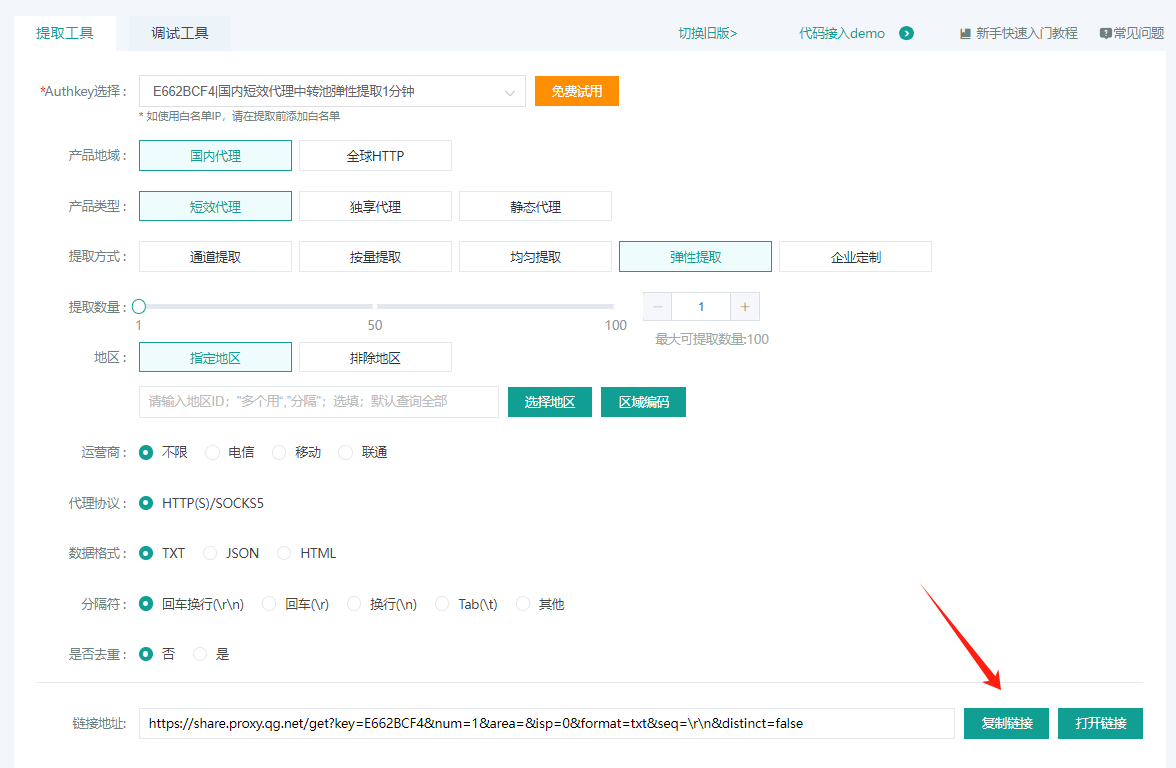
1、复制API链接:
2、在博主的提取代码中修改url为自己的API链接:
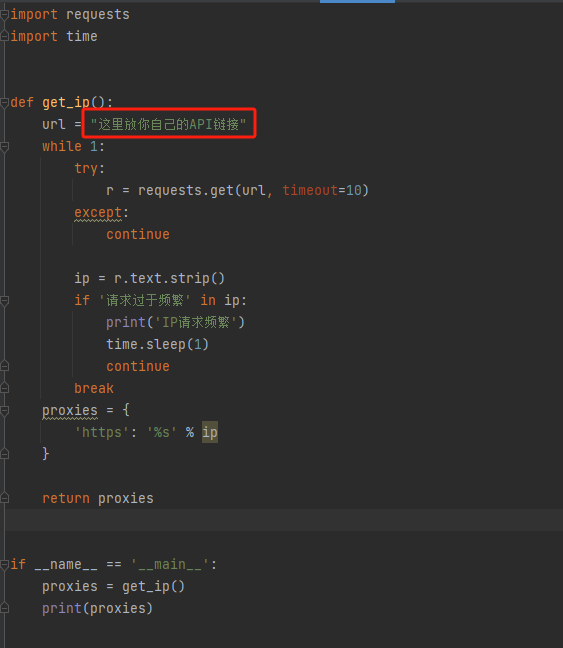
代码如下:
python
import requests
import time
def get_ip():
url = "这里放你自己的API链接"
while 1:
try:
r = requests.get(url, timeout=10)
except:
continue
ip = r.text.strip()
if '请求过于频繁' in ip:
print('IP请求频繁')
time.sleep(1)
continue
break
proxies = {
'https': '%s' % ip
}
return proxies
if __name__ == '__main__':
proxies = get_ip()
print(proxies)3、代码返回IP,运行成功:

五、爬虫代码实战
我们爬取一个网站时,首先要查看是否有接口数据(有接口就用接口)、其次是能否用requests模块发送请求正常获取数据,如果requests模块不行就考虑使用selenium模块去获取数据了。
5.1 分析网页
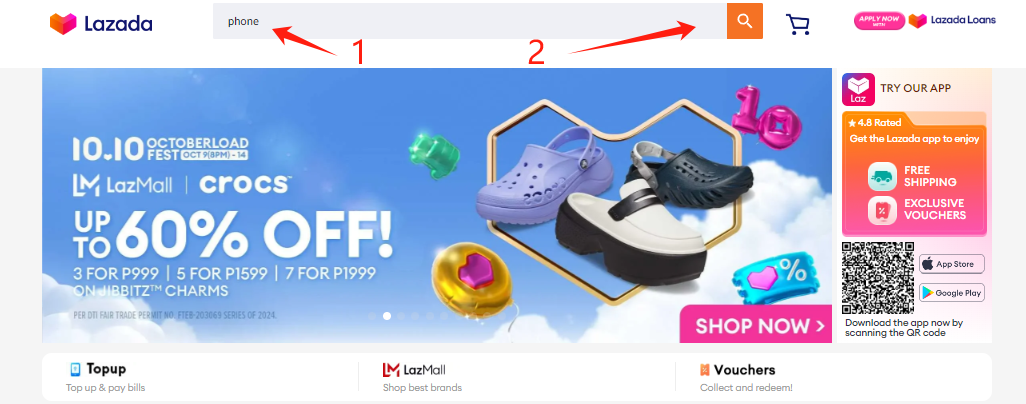
1、我们首先打开电商平台官网,并在输入框输入我们想要爬取的商品列表:https://www.lazada.com.ph/#?
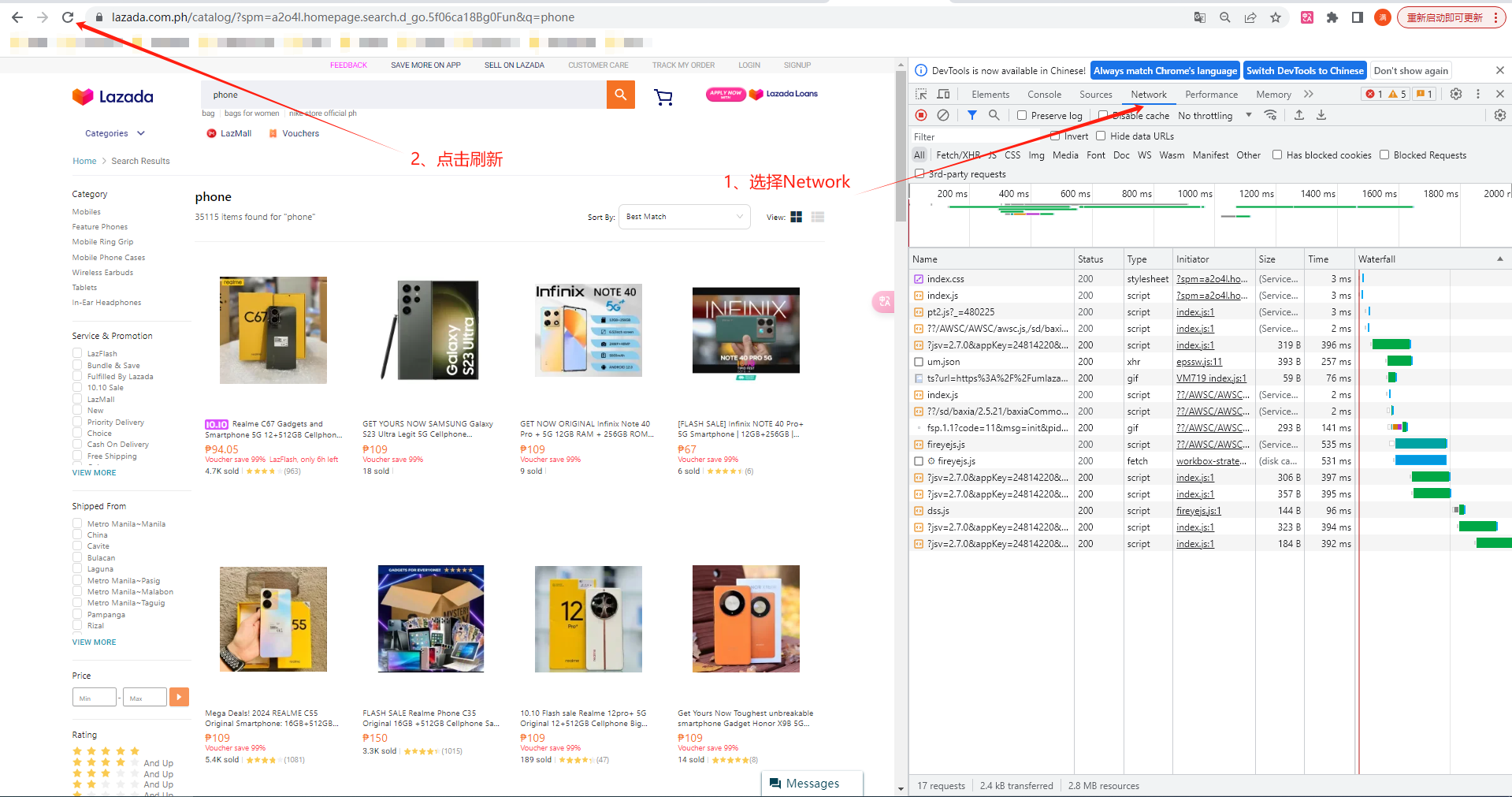
2、按下f12 或者 右击选择检查,选择Network,然后点击刷新:
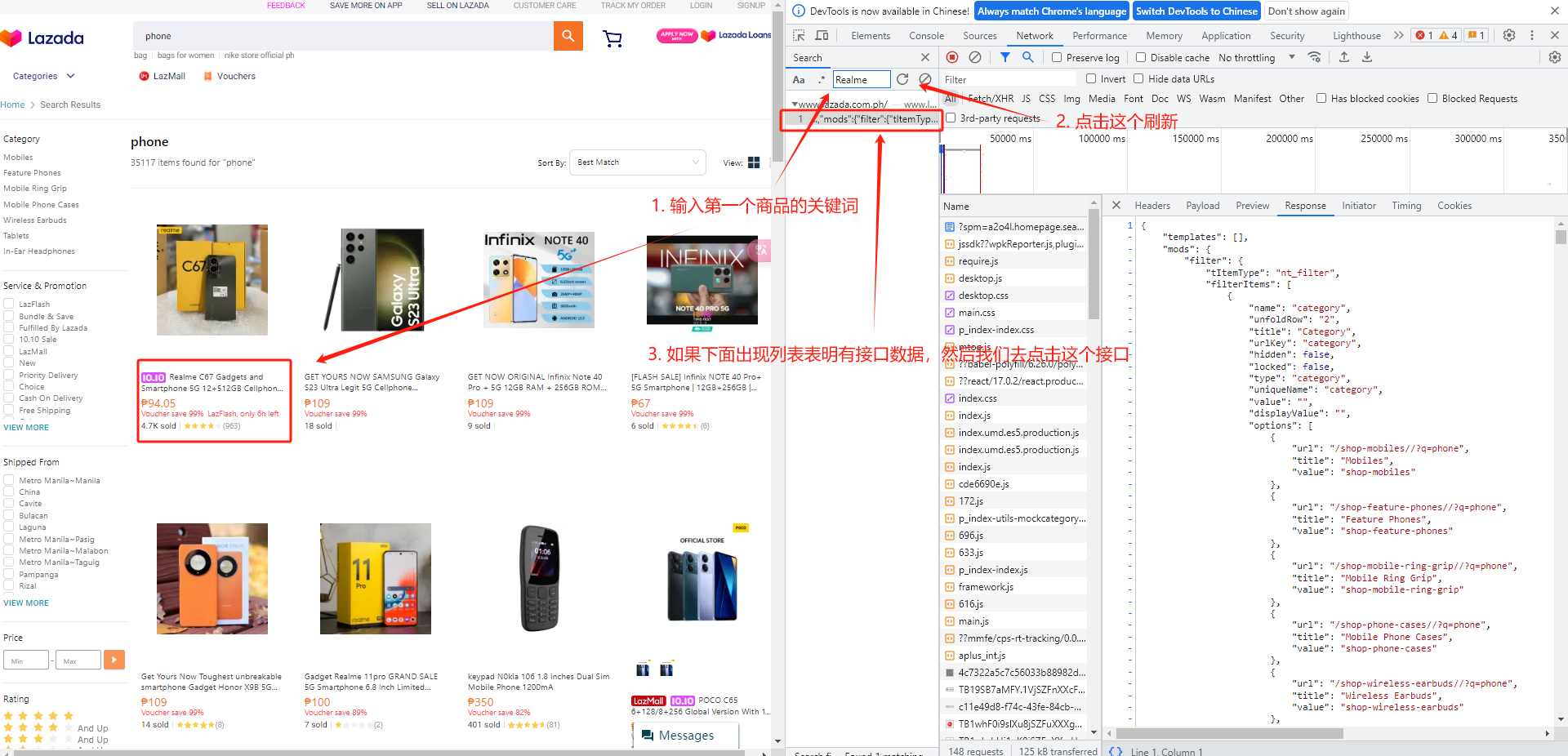
3、我们随便选择一个Network下面的列表,接着按ctrl+f 打开搜索框,搜索商品信息找到接口:
4、接着点击接口,找到接口链接复制去新界面打开:
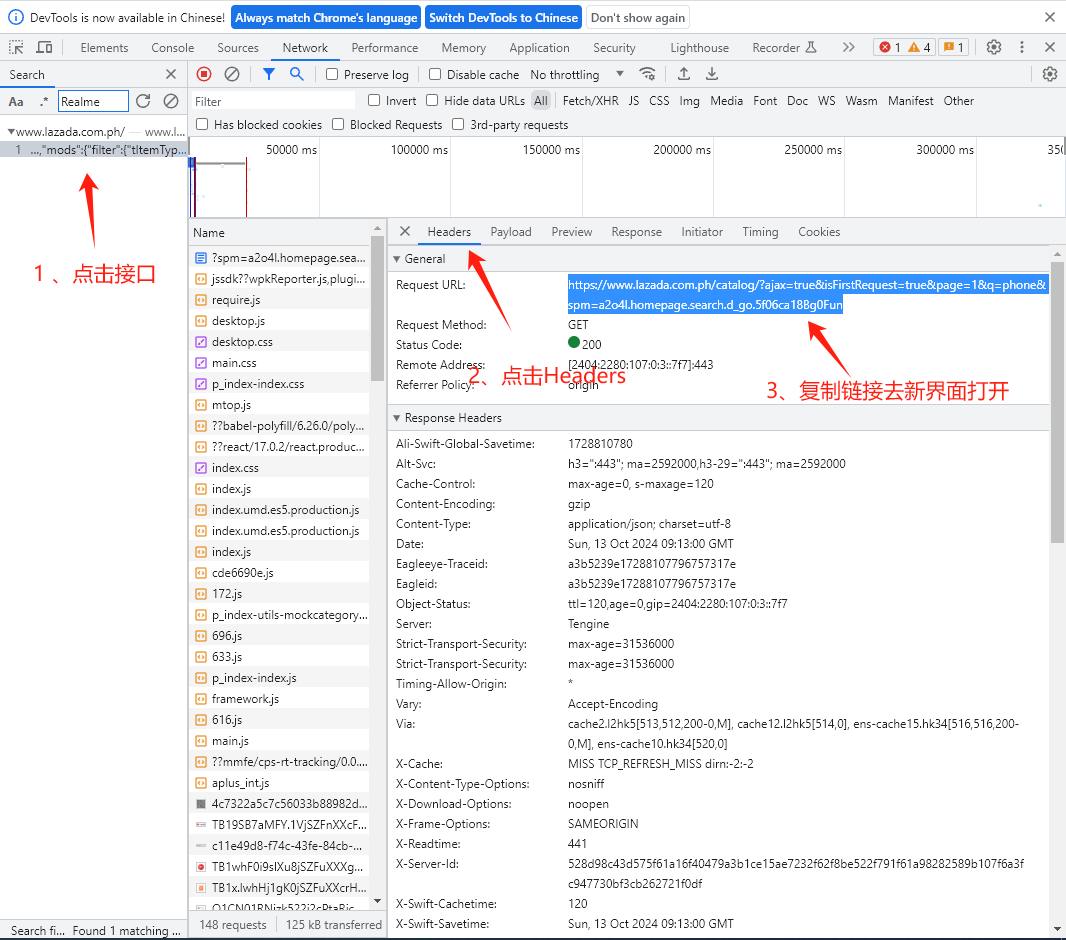
5、我们在新界面打开接口连接后可以看到有翻页关键词page 和 检索关键词q:
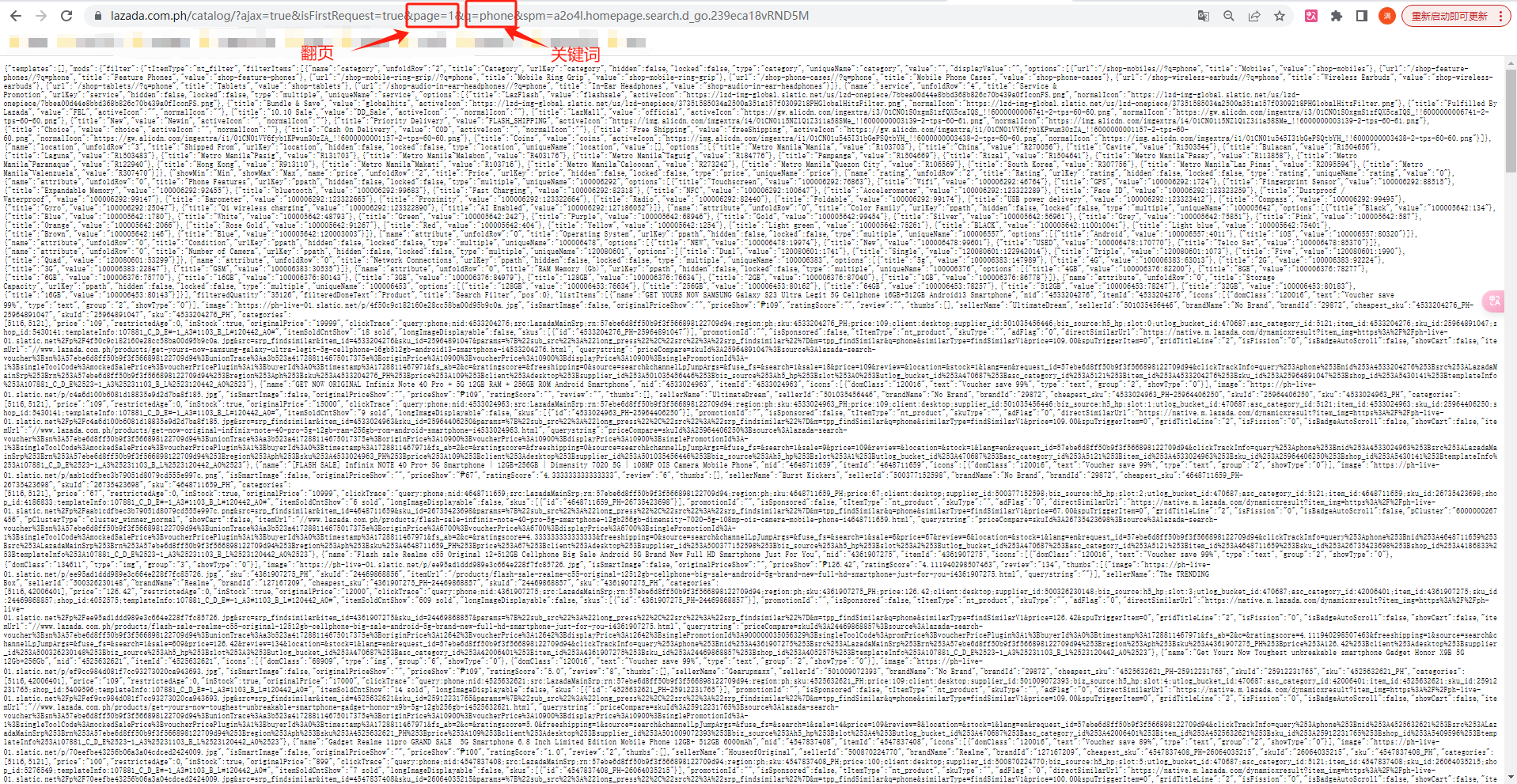
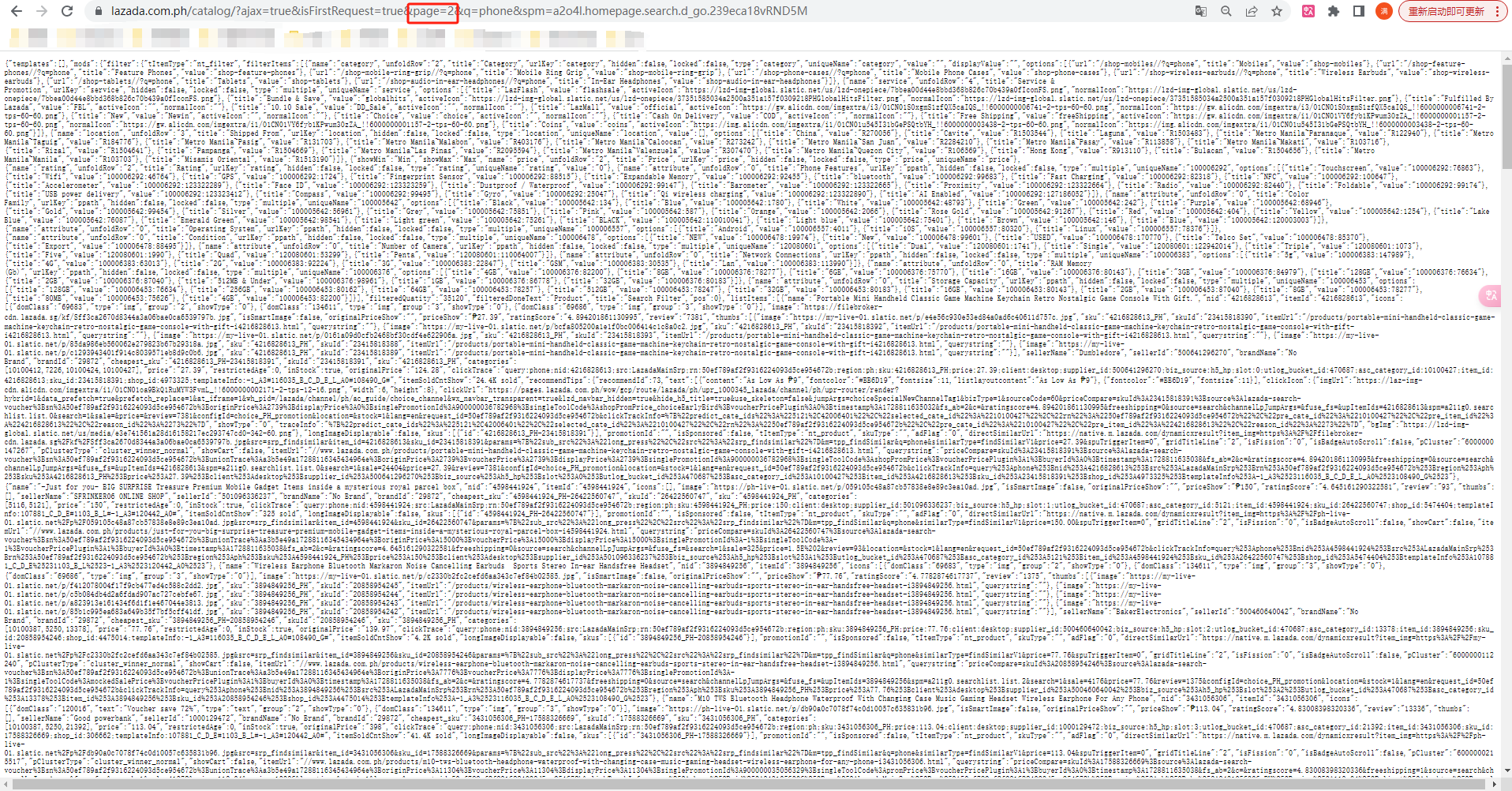
6、尝试改变翻页关键词page的值,网页正常打开并且数据刷新了,到这里就可以确定我们使用这个接口获取手机数据是没问题:
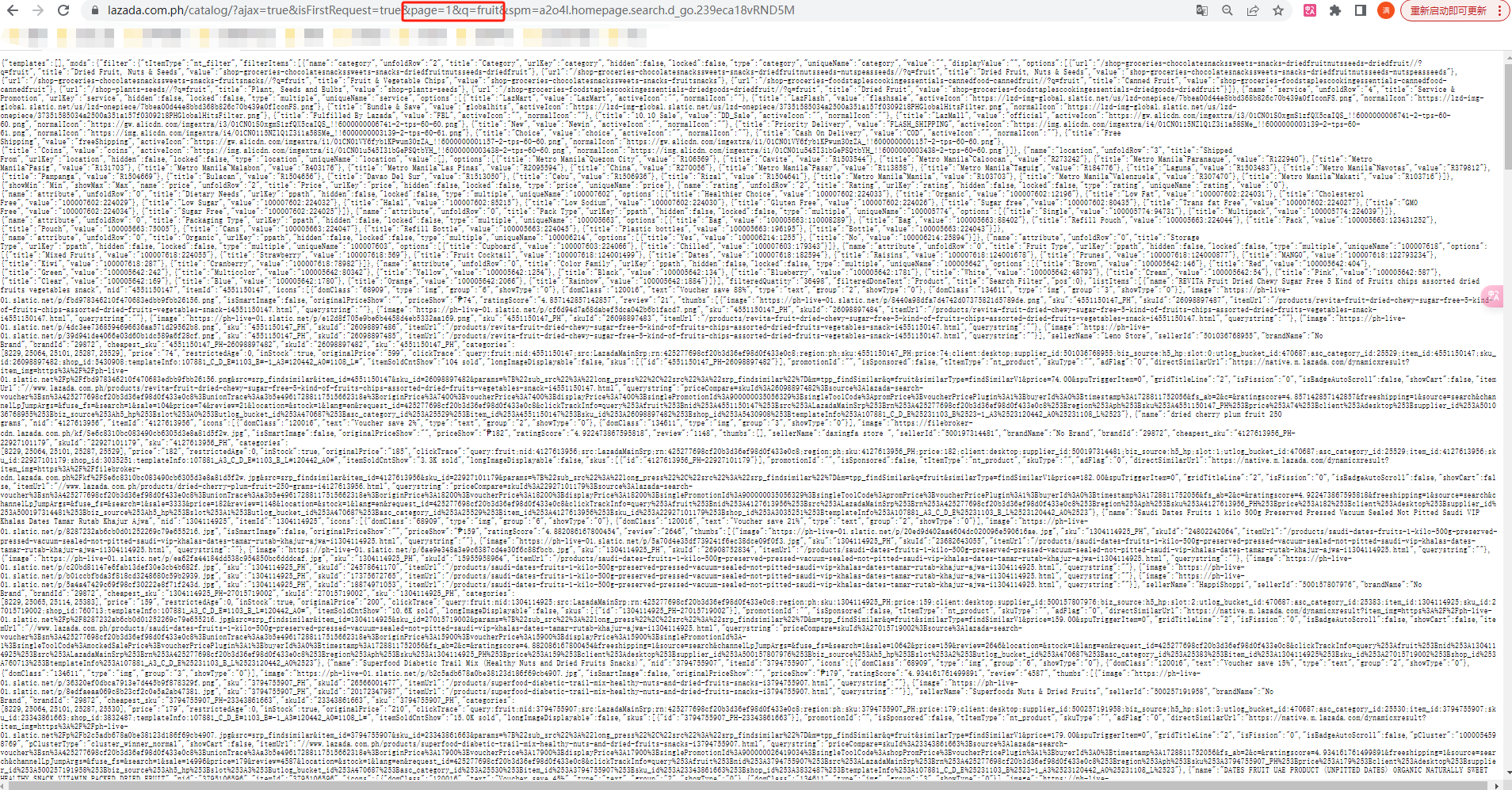
7、尝试将检索关键词q 的值改为fruit(水果),网页正常打开并且数据刷新了,到这里就可以确定我们使用这个接口可以传入任何关键词都是没问题的:
8、回到Network界面,点击Response,随便点击下面的内容,接着按ctrl+f 打开搜索框,搜索商品信息,成功找到我们需要的数据都在listItems列表下面的一个个字典中,那么等会我们只需要定位到这个列表,遍历并解析字典中的数据即可:
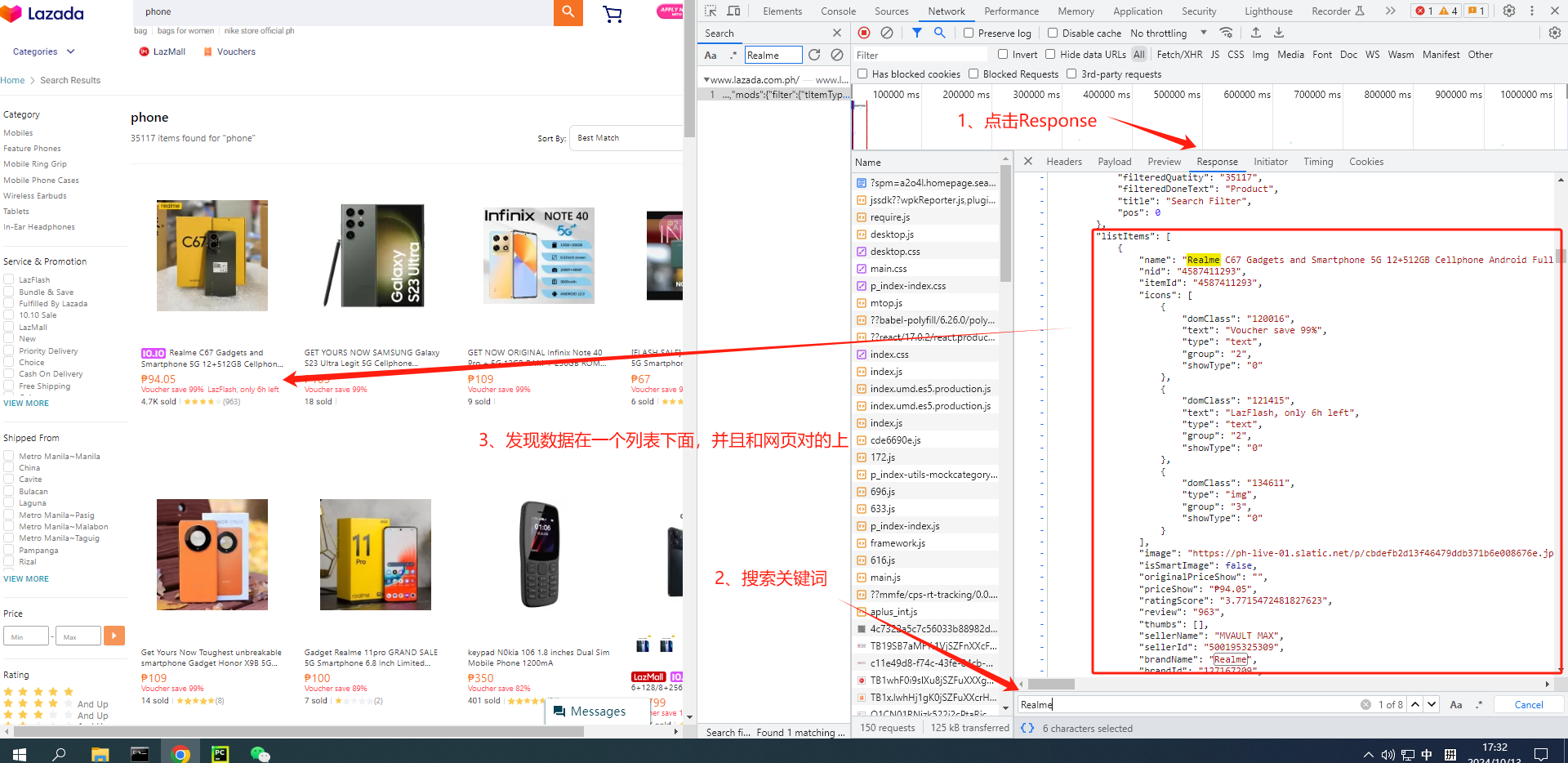
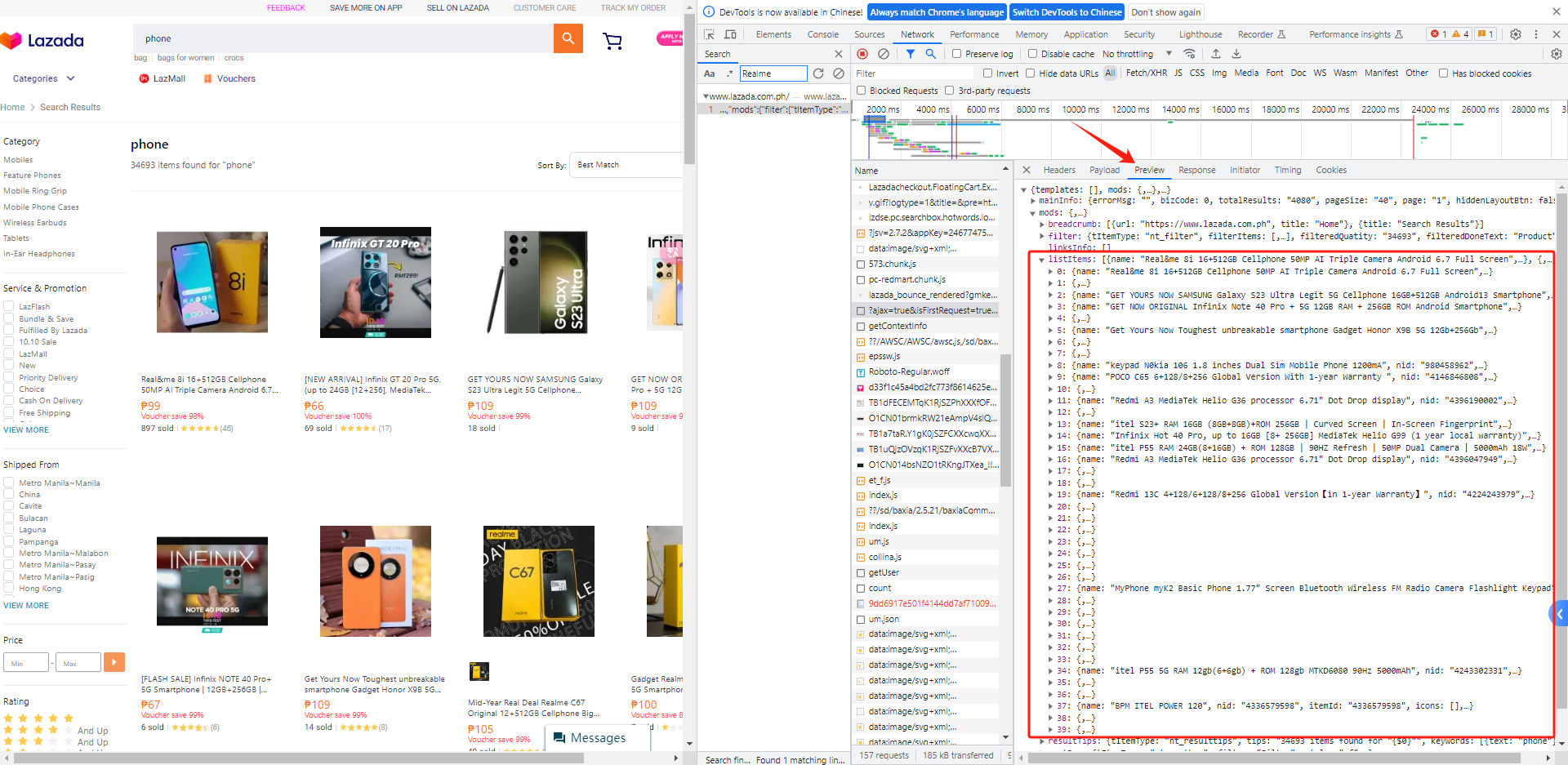
9、点击Preview可以看到listItems列表下面有40个商品信息,并且我们能轻松查看字段的层级:
5.2 导入模块
python
import requests # python基础爬虫库
import pandas as pd # pandas,用于写入Excel文件
import time # 防止爬取过快可以睡眠一秒5.3 传入关键词设置翻页
根据5.1的网页分析我们了解了,只要在接口链接传入关键词和页数就可以成功获取数据:
python
def main():
# 一、传入关键词和需要爬取的页数,拼接数据接口链接
keyword = 'phone' # 设置需要爬取的商品关键词
page_num = 1 # 设置需要爬取的页数
data_list = []
for page in range(1, page_num+1):
url = f'https://www.lazada.com.ph/catalog/?ajax=true&isFirstRequest=true&page={page}&q={keyword}'5.4 携带代理IP发送请求
下面代码利用4.4案例中的get_ip() 函数去获取代理IP,利用python携带代理IP去请求电商平台,以此达到隐秘IP的目的:
python
def get_data_json(url):
"""发送请求,获取响应"""
# 请求头模拟浏览器
headers = {
'Authority':'www.lazada.com.ph',
'Refere':'https://www.lazada.com.ph/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# 获取代理IP
proxies = get_ip()
# 添加请求头和代理IP发送请求
response = requests.get(url,headers=headers,proxies=proxies)
# 将数据转为json字典格式
data_json = response.json()
return data_json5.5 提取数据
提取我们需要的商品标题、商品价格、商品销量、五星好评数、商品链接、商品图片链接,如果需要更多的其他字段可以自己添加解析代码:
python
def get_data(data_list,data_json):
listItems = data_json['mods']['listItems']
print(len(listItems)) # 打印listItems列表长度,返回40,说明数据正确
for i in listItems:
try:
name = i['name']
except:
name = None
try:
priceShow = i['priceShow']
except:
priceShow = None
try:
itemSoldCntShow = i['itemSoldCntShow'].replace(' sold','')
except:
itemSoldCntShow = None
try:
review = i['review']
except:
review = None
try:
itemUrl = i['itemUrl']
url = 'https:' + itemUrl
except:
url = None
try:
image = i['image']
except:
image = None
print({'商品标题':name,'商品价格':priceShow,'商品销量':itemSoldCntShow,'五星好评数':review,'商品链接':url,'商品图片链接':image})
print('*'*50)
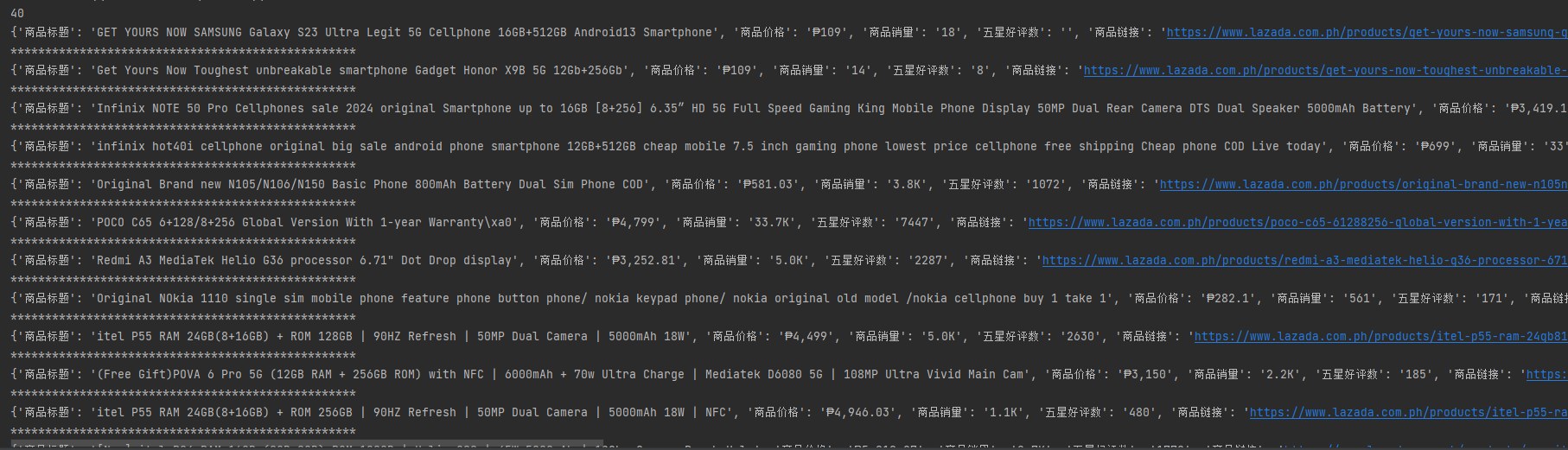
data_list.append({'商品标题':name,'商品价格':priceShow,'商品销量':itemSoldCntShow,'五星好评数':review,'商品链接':url,'商品图片链接':image})运行成功返回数据:
5.6 保存数据
将数据全部写入excel文件中去:
python
def save(data_list,keyword):
df = pd.DataFrame(data_list)
df.to_excel(f'{keyword}.xlsx',index=False) # 根据关键词创建excel文件5.7 效果展示
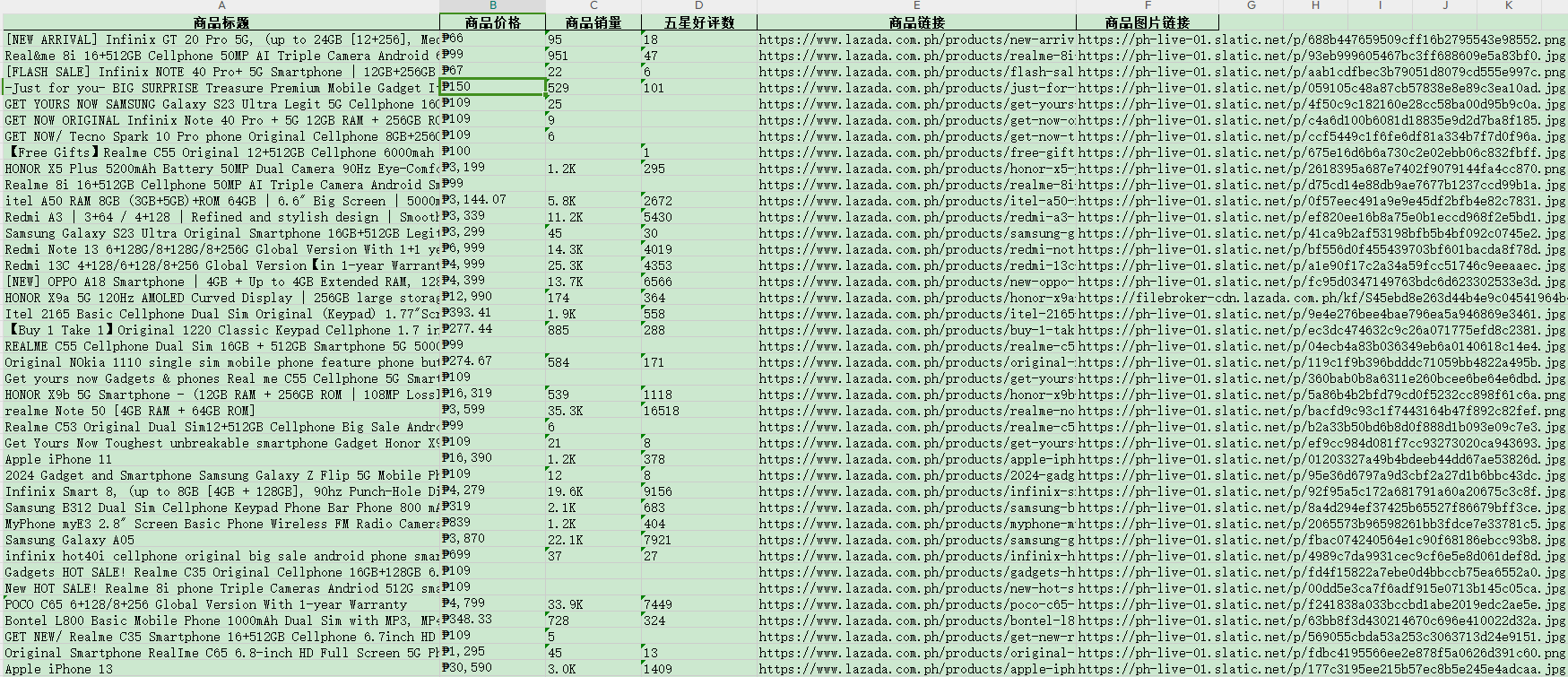
使用青果代理IP成功爬取电商数据,效果非常Nice,最终生成一个excel表格,有商品标题、价格、销量等等:
5.8 完整源码
注意下面的完整源码,需要看4.3和4.4修改为自己的代理API才能运行成功,还可以修改爬取的关键词和页数:
python
import requests # python基础爬虫库
import pandas as pd # pandas,用于写入Excel文件
import time # 防止爬取过快可以睡眠一秒
def get_ip():
url = "https://share.proxy.qg.net/get?key=E662BCF4&num=1&area=&isp=0&format=txt&seq=\r\n&distinct=false"
while 1:
try:
r = requests.get(url, timeout=10)
except:
continue
ip = r.text.strip()
if '请求过于频繁' in ip:
print('IP请求频繁')
time.sleep(1)
continue
break
proxies = {
'https': '%s' % ip
}
return proxies
def get_data_json(url):
"""发送请求,获取响应"""
# 请求头模拟浏览器
headers = {
'Authority':'www.lazada.com.ph',
'Refere':'https://www.lazada.com.ph/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# 获取代理IP
proxies = get_ip()
# 添加请求头和代理IP发送请求
response = requests.get(url,headers=headers,proxies=proxies)
# 将数据转为json字典格式
data_json = response.json()
return data_json
def get_data(data_list,data_json):
listItems = data_json['mods']['listItems']
print(len(listItems)) # 打印listItems列表长度,返回40,说明数据正确
for i in listItems:
try:
name = i['name']
except:
name = None
try:
priceShow = i['priceShow']
except:
priceShow = None
try:
itemSoldCntShow = i['itemSoldCntShow'].replace(' sold','')
except:
itemSoldCntShow = None
try:
review = i['review']
except:
review = None
try:
itemUrl = i['itemUrl']
url = 'https:' + itemUrl
except:
url = None
try:
image = i['image']
except:
image = None
print({'商品标题':name,'商品价格':priceShow,'商品销量':itemSoldCntShow,'五星好评数':review,'商品链接':url,'商品图片链接':image})
print('*'*50)
data_list.append({'商品标题':name,'商品价格':priceShow,'商品销量':itemSoldCntShow,'五星好评数':review,'商品链接':url,'商品图片链接':image})
def save(data_list,keyword):
df = pd.DataFrame(data_list)
df.to_excel(f'{keyword}.xlsx',index=False) # 根据关键词创建excel文件
def main():
# 一、传入关键词和需要爬取的页数,拼接数据接口链接
keyword = 'phone' # 设置需要爬取的商品关键词
page_num = 10 # 设置需要爬取的页数
data_list = []
for page in range(1, page_num+1):
# url = f'https://www.lazada.com.ph/catalog/?ajax=true&isFirstRequest=true&page={page}&q={keyword}'
url = 'https://www.lazada.com.ph/catalog/?ajax=true&isFirstRequest=true&page=1&q=phone&spm=a2o4l.homepage.search.d_go.5f06ca18Bg0Fun'
print(url)
# 二、发送请求获取数据
data_json = get_data_json(url)
# 三、解析数据
get_data(data_list,data_json)
time.sleep(1) # 降低爬取速度
# 四、写入excel
save(data_list, keyword)
if __name__ == '__main__':
main()五、总结
在跨境电商领域的广阔舞台上,面对复杂多变的业务需求,众多出海企业正不断探索高效、稳定的解决方案以应对重重挑战。青果代理IP作为数据采集领域的利器,凭借其卓越的访问稳定性、增强的网站信任度以及强大的防封禁能力,极大地促进了跨境电商的数据采集,有兴趣的小伙伴都可以试试:青果代理IP免费体验