一:Python软件的安装
1 Python软件安装及入门
1)Anaconda软件安装
2)Python库的安装与基本语法
3)Python的字符操作与正则表达式
4)Python的数据清洗与存储
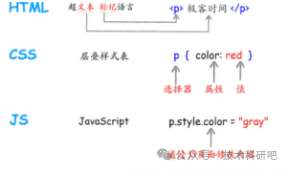
5)HTML和XML基础

二:Python爬虫基础
2 Python爬虫基础
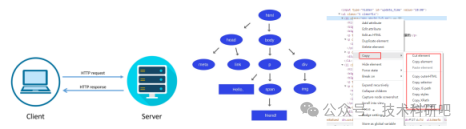
1)爬虫的工作流程
2)发送请求及获得页面
Requests库的使用
获取代理、设置代理ip池及反爬虫
3)解析页面技术:
正则表达式使用
BeautifulSoup库的使用
CSS选择器使用
Xpath、lxml、entree语法
PyQuery库使用
三:Python爬虫全流程
3 Python爬虫全流程
1)抓取的数据形式:文本、图片、链接
2)保存和清洗获取的数据
3)如何使用多线程提高爬虫的效率
4)使用五种不同解析技术爬取经济、天气、土壤、品种大数据

四:Python爬虫模拟器
4 模拟浏览器Selenium使用
1)Selenium库
2)Selenium定位元素(id/name/class/tag/text/xpath/css定位)
3)Selenium操作网页(点击、保存、刷新等)
4)Selenium显式等待和隐式等待
5)使用Selenium爬取农业大数据
五:Python 爬取异步加载网页及数据集网站
5 Python 爬取异步加载网页及数据集网站
1)Ajax请求和JS渲染
2)json解析、XHR
3)使用Ajax爬取和下载动态图片库
4)案使用json解析爬取数据类网站
5)使用一些特定库爬取大型数据集网
6)如何爬取pdf中的表格数据