随着大语言模型在自然语言处理领域的迅速发展,大语言模型技术被广泛地应用于文本类推荐任务中。在本文中,我们筛选并总结了EMNLP 2024和NeurIPS 2024中部分大语言模型与推荐系统融合的相关论文。这些论文展示了大语言模型相关领域工作(如可解释性、预训练/微调和偏好对齐等)与推荐任务场景的对齐,从而提升文本类推荐任务的性能。
1.XRec: Large Language Models for Explainable Recommendation
论文链接:https://arxiv.org/pdf/2406.02377
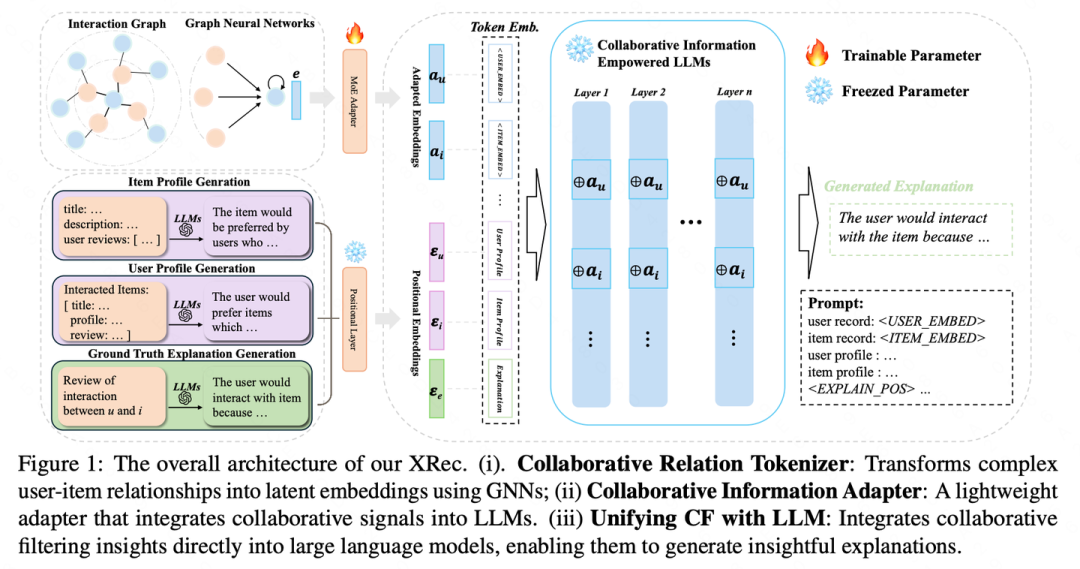
推荐系统主要提供与用户偏好相匹配的个性化推荐信息,而协同过滤(CF)是当前推荐领域广泛采用的一种方法。尽管图神经网络(GNNs)和自监督学习(SSL)等先进技术使CF模型可以生成更好的用户表示,但是这些技术往往缺乏为所推荐的物品生成文本解释的能力。可解释推荐技术旨在填补这一空白,通过提供推荐决策过程的解释,增强用户对所推荐物品合理性的理解程度。本文提出了一种与模型无关的可解释推荐框架XRec,利用LLMs强大的语言能力,为推荐系统中的用户行为提供更加全面的解释。通过整合协同信号并设计轻量级的协同适配器,该框架使LLMs能够理解用户-项目交互中的复杂模式,并深入理解用户偏好。本文通过大量的实验展示了XRec的有效性,证明其生成全面且有意义的解释的能力,超越了传统的可解释推荐系统。
2.Decoding Matters: Addressing Amplification Bias and Homogeneity Issue for LLM-based Recommendation
论文链接:https://arxiv.org/pdf/2406.14900
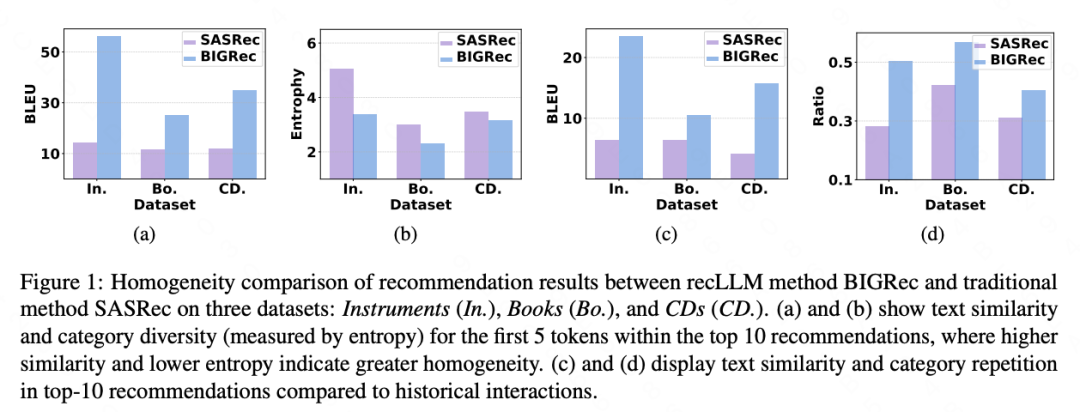
将大型语言模型(LLMs)与推荐系统结合的过程中,需要对模型解码过程的深入研究,因为推荐物品生成任务和传统自然语言处理任务之间存在一定的差异。现有的方法通常直接应用LLMs的原始解码方法。然而,本文发现这些方法面临显著挑战:(1)偏差放大问题:标准长度归一化使得包含生成概率接近1的标记(称为幽灵标记)的推荐物品得分会显著提升;(2)同质性问题------微调后的模型倾向于为用户生成多个相似或重复的项目。为了应对这些挑战,我们提出了一种新的解码方法,称为去偏多样性解码(D3)。D3在长度归一化的过程中禁用幽灵标记,以减轻偏差放大问题;同时,该方法引入一个无文本辅助模型,以鼓励生成那些不常由LLMs生成的标记,从而对抗推荐同质性问题。
3.Large Language Models Enhanced Sequential Recommendation for Long-tail User and Item
论文链接:https://arxiv.org/pdf/2405.20646
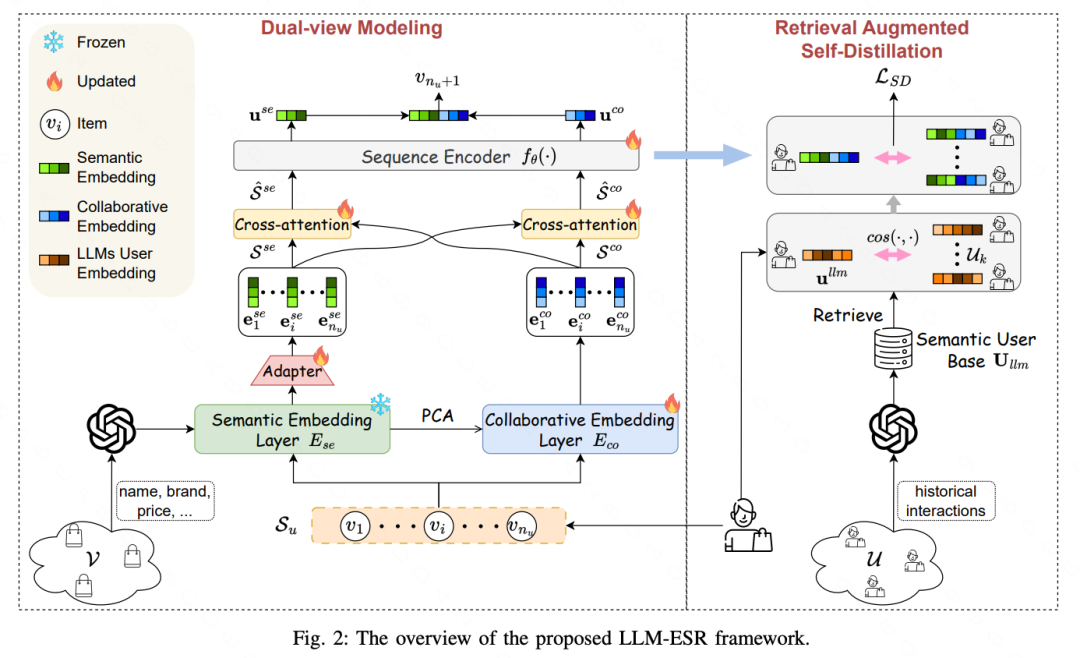
序列推荐系统(SRS)可以根据用户的过去交互物品序列预测其后续的偏好,然而传统SRS面临很多挑战,比如长尾用户和长尾物品困境,大多数用户只与有限数量的物品交互,而大多数物品则很少被交互。虽然一些研究工作缓解了这些问题,但仍然面临着交互信息稀缺而导致的摇摆或噪音等问题。本文利用大语言模型的强大语言能力,引入了顺序推荐的大型语言模型增强框架(LLM-ESR),该框架利用LLMs的语义嵌入来提升SRS性能,而无需增加计算开销。为了应对长尾物品的挑战,本文提出了一种双视图建模方法,将来自LLMs的语义信息与传统SRS的协同信号融合在一起。为了解决长尾用户的挑战,本文引入了一种检索增强自蒸馏技术,通过结合类似用户的更丰富的交互数据来细化用户偏好表示。
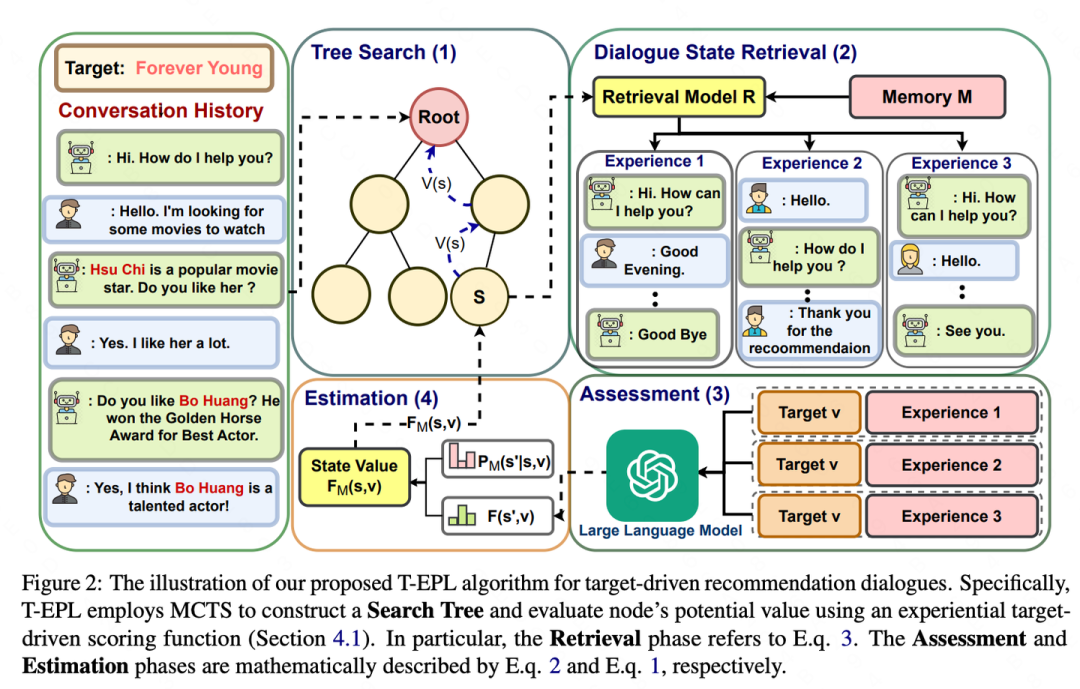
4.Experience as Source for Anticipation and Planning: Experiential Policy Learning for Target-driven Recommendation Dialogues
论文链接:https://www.researchgate.net/profile/ExperienceasSourceforanticipationandplanning
目标驱动的对话式推荐系统在对话管理过程中面临一定的挑战,因为成功的对话管理过程需要预测用户的交互对话行为。目前的方法存在许多局限性:(1)对话预测能力不足;(2)计算效率较低;(3)较少利用历史对话经验。为了解决这些问题,本问提出了一种称为经验政策学习(EPL)的新框架。具体而言,EPL体现了"从经验中学习"的原则,通过一个经验评分函数来促进预期,该函数利用存储在长期记忆中的相似历史对话来估计当前对话的状态。此外,为了展示其灵活性,本文引入了树结构EPL(T-EPL),并实现了基于大型语言模型(LLMs)和蒙特卡罗树搜索(MCTS)的无训练方法。T-EPL使用LLMs评估过去的对话状态,同时利用MCTS实现分层和多级推理。
5.Customizing Language Models with Instance-wise LoRA for Sequential Recommendation
论文链接:https://arxiv.org/pdf/2408.10159
序列推荐系统通过分析过去的交互来预测用户下一个感兴趣的物品,从而使推荐与个人偏好相一致。当前有许多方法利用大型语言模型(LLMs)在知识理解和推理方面的优势,通过语言生成范式将LLMs应用于序列推荐任务。这些方法将用户行为序列转换为微调LLM的指令,并利用低秩适应(LoRA)模块来优化推荐。然而,在不同用户行为中统一应用一个LoRA,有时无法捕捉到个体间的差异,导致性能不佳以及不同序列之间的负迁移。为了解决这些挑战,本文提出了实例级LoRA(iLoRA),将LoRA与专家混合(MoE)框架相结合。iLoRA创建了一系列多样化的专家,每个专家捕捉用户偏好的特定方面,并引入了一个由序列表示指导的门控函数。该门控函数处理历史交互序列,以生成丰富的表示,指导门控网络输出定制的专家参与权重。这种量身定制的方法减轻了负迁移的影响,并动态调整以适应多样化的行为模式。

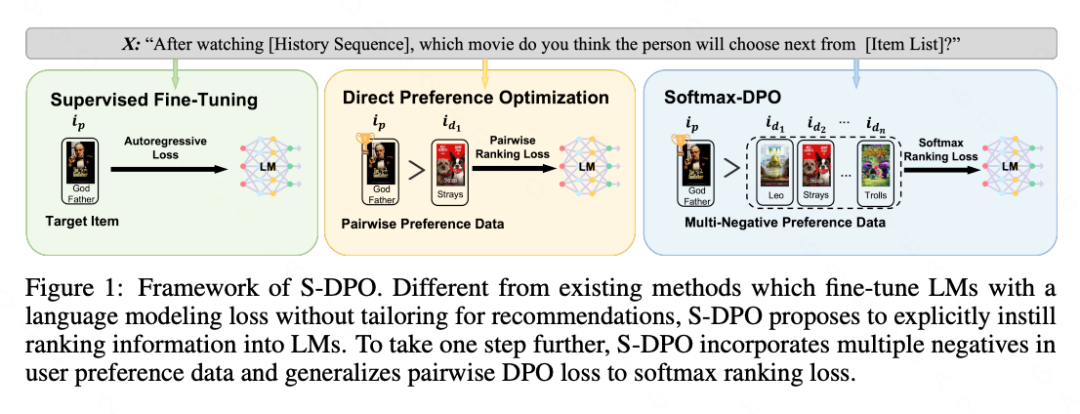
6.On Softmax Direct Preference Optimization for Recommendation
论文链接:https://arxiv.org/pdf/2406.09215
推荐系统旨在根据用户偏好数据预测个性化的物品排名列表。随着语言模型(LM)的兴起,基于语言模型的推荐系统因其广泛的世界知识和强大的推理能力而被广泛研究。大多数基于语言模型的推荐系统将历史交互转换为文本指令,并将一个正样本物品作为预测目标,用于微调语言模型。然而,这些方法未能充分利用偏好数据,也未针对个性化排名任务进行优化,这限制了基于语言模型的推荐系统的性能。本文提出了Softmax-DPO(S-DPO),以将排名信息注入语言模型,帮助基于语言模型的推荐系统区分偏好的物品与负样本项目,而不仅仅只关注正样本物品。具体而言,本文在用户偏好数据中引入多个负面样本,并设计了一种专门为基于语言模型的推荐系统设计的DPO损失的替代方式,该方式与softmax采样策略相联系。