作者:来自 Elastic Craig Taverner

如何使用 Kibana 和 csv 采集处理器将地理空间数据采集到 Elasticsearch 中,以便在 Elasticsearch 查询语言 (ES|QL) 中进行搜索。Elasticsearch 具有强大的地理空间搜索功能,现在 ES|QL 也具备这些功能,大大提高了易用性和 OGC 熟悉度。但要使用这些功能,我们需要地理空间数据。
我们最近发布了一篇博文,介绍了如何使用 ES|QL(Elasticsearch 新的、功能强大的管道查询语言)中的新地理空间搜索功能。要使用这些功能,你需要在 Elasticsearch 中拥有地理空间数据。因此,在这篇博文中,我们将向你展示如何提取地理空间数据,以及如何在 ES|QL 查询中使用它。
使用 Kibana 导入 CSV 数据
我们在上一篇博客中用于示例的数据基于我们内部用于集成测试的数据。为了方便起见,我们将其以几个 CSV 文件的形式包含在此处,可以使用 Kibana 轻松导入。数据包括机场、城市和城市边界。你可以从以下位置下载数据:
- airports.csv
- 这包含三个数据集的合并:
- 来自 Natural Earth 的机场(名称、位置和相关数据)
- 来自 SimpleMaps 的城市位置
- 来自全球机场数据库的机场海拔
- 这包含三个数据集的合并:
- airport_city_boundaries.csv
- 这包含来自上述机场和城市名称与一个新来源的合并:
- 来自 OpenStreetMap 的城市边界
- 这包含来自上述机场和城市名称与一个新来源的合并:
正如你所猜到的,我们花了一些时间将这些数据源合并到上面的两个文件中,目的是能够测试 ES|QL 的地理空间功能。这可能与你的特定数据需求不完全相同,但希望这能让你了解什么是可能的。具体来说,我们想演示一些有趣的事情:
- 将带有地理空间字段的数据与其他可索引数据一起导入
- 导入 geo_point 和 geo_shape 数据并在查询中一起使用它们
- 将数据导入可以使用空间关系连接的两个索引
- 创建摄取管道以方便将来的导入(超越 Kibana)
- 摄取处理器的一些示例,如 csv、convert 和 split
虽然我们将在本博客中讨论如何使用 CSV 数据,但重要的是要了解有几种使用 Kibana 添加地理数据的方法。在地图应用程序中,你可以上传分隔数据,如 CSV、GeoJSON 和 ESRI ShapeFiles,也可以直接在地图中绘制形状。对于本博客,我们将重点介绍从 Kibana 主页导入 CSV 文件。
导入机场数据
第一个文件 airports.csv 有一些需要处理的特殊情况。首先,列之间有多余的空白符,这在典型的 CSV 文件中并不常见。其次,type 字段是一个多值字段,需要将其拆分为单独的字段。最后,一些字段不是字符串类型,需要转换为正确的类型。所有这些都可以使用 Kibana 的 CSV 导入功能来完成。
从 Kibana 主页开始。有一个名为 "Get started by adding integrations" 的部分,其中有一个名为 "Upload a file" 的链接:
单击此链接,你将进入 "Upload file" 页面。在这里,你可以拖放 airports.csv 文件,Kibana 将分析该文件并向你显示数据预览。它应该自动将分隔符检测为逗号,并将第一行检测为标题行。但是,它可能没有修剪列之间的多余空格,也没有确定字段的类型,假设所有字段都是 text 或 keyword。我们需要解决这个问题。

单击 "Override settings" 并选中 "Should trim fields" 复选框,然后单击 "Apply" 关闭设置。现在我们需要修复字段的类型。这在下一页上可用,因此继续并单击 "Import"。
首先选择一个索引名称,然后选择 "Advanced" 以进入字段映射和提取处理器页面。

在这里,我们需要更改索引的字段映射以及用于导入数据的提取管道。首先,虽然 Kibana 很可能会自动检测 scalerank 字段做为 long 类型,但它错误地将 location 和 city_location 字段视为 keyword。将它们编辑为 geo_point,最终得到如下所示的映射:
{
"properties": {
"abbrev": { "type": "keyword" },
"city": { "type": "keyword" },
"city_location": { "type": "geo_point" },
"country": { "type": "keyword" },
"elevation": { "type": "double" },
"location": { "type": "geo_point" },
"name": { "type": "text" },
"scalerank": { "type": "long" },
"type": { "type": "keyword" }
}
}这里你可以灵活处理,但请注意, 你选择的类型会影响字段的索引方式以及可能的查询类型。例如,如果你将 location 保留为 keyword,则无法对其执行任何地理空间搜索查询。同样,如果你将 elevation 保留为 text,则无法对其执行数值范围查询。
现在是时候修复摄取管道了。如果 Kibana 自动检测到 scalerank 为上面的 long,它还会添加一个处理器来将字段转换为 long。我们需要为 elevation 字段添加一个类似的处理器,这次将其转换为 double。编辑管道以确保你已完成此转换。在保存之前,我们还需要进行一次转换,将 type 字段拆分为多个字段。使用以下配置向管道添加 split 处理器:
{
"split": {
"field": "type",
"separator": ":",
"ignore_missing": true
}
}最终的摄取管道应如下所示:
{
"description": "Ingest pipeline created by text structure finder",
"processors": [
{
"csv": {
"field": "message",
"target_fields": [
"abbrev",
"name",
"scalerank",
"type",
"location",
"country",
"city",
"city_location",
"elevation"
],
"ignore_missing": false,
"trim": true
}
},
{
"convert": {
"field": "scalerank",
"type": "long",
"ignore_missing": true
}
},
{
"convert": {
"field": "elevation",
"type": "double",
"ignore_missing": true
}
},
{
"split": {
"field": "type",
"separator": ":",
"ignore_missing": true
}
},
{
"remove": {
"field": "message"
}
}
]
}请注意,我们没有为 location 和 city_location 字段添加转换处理器。这是因为字段映射中的 geo_point 类型已经理解这些字段中数据的 WKT 格式。geo_point 类型可以理解多种格式,包括 WKT、GeoJSON 等。例如,如果我们在 CSV 文件中有两列用于 latitude 和 longitude,我们就需要添加 script 或 set 处理器以将它们组合成单个 geo_point 字段(例如“set”:{“field”:“location”,“value”:“{{lat}},{{lon}}”})。
我们现在可以导入文件了。单击 Import,数据将使用我们刚刚定义的映射和摄取管道导入索引。如果摄取数据时出现任何错误,Kibana 会在此处报告这些错误,因此你可以编辑源数据或摄取管道并重试。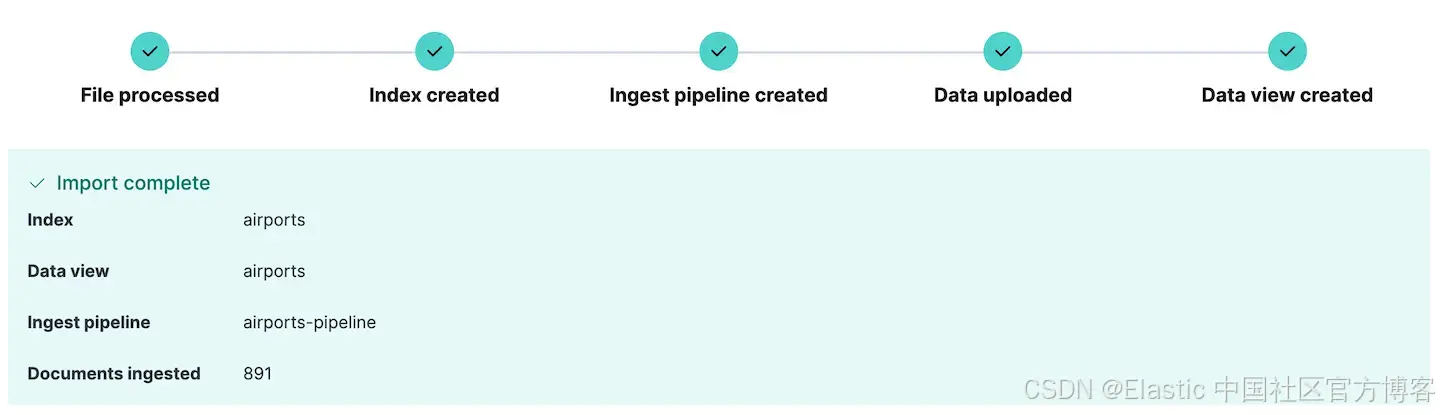
请注意,已创建了新的采集管道。你可以通过转到 Kibana 的 Stack Management 部分并选择 Ingest Pipelines 来查看。在这里,你可以看到我们刚刚创建的管道,并在必要时对其进行编辑。事实上,Ingest Pipelines 部分可用于创建和测试采集管道,如果你计划进行更复杂的采集,这是一个非常有用的功能。
如果你想立即探索这些数据,请跳到后面的部分,但如果你还想导入城市边界,请继续阅读。
导入城市边界
airport_city_boundaries.csv 中提供的城市边界文件比上一个示例导入起来简单一些。它包含一个 city_boundary 字段,该字段是城市边界的 WKT 表示形式,为 POLYGON,以及一个 city_location 字段,该字段是城市位置的 geo_point 表示形式。我们可以以与机场数据类似的方式导入这些数据,但有一些不同:
- 我们需要选择覆盖设置 "Has header row",因为该设置无法自动检测到
- 我们不需要修剪字段,因为数据中已经没有多余的空格
- 我们不需要编辑提取管道,因为所有类型都是字符串或空间类型
- 但是,我们必须编辑字段映射以将 city_boundary 字段设置为 geo_shape,将 city_location 字段设置为 geo_point
我们最终的字段映射如下所示:
{
"properties": {
"abbrev": { "type": "keyword" },
"airport": { "type": "keyword" },
"city": { "type": "keyword" },
"city_boundary": { "type": "geo_shape" },
"city_location": { "type": "geo_point" },
"region": { "type": "text" }
}
}与之前的 airports.csv 导入一样,只需单击 "Import" 即可将数据导入索引。数据将与我们编辑的映射和 Kibana 定义的提取管道一起导入。
使用开发工具探索数据
在 Kibana 中,通常使用 "Discover" 探索索引数据。但是,如果你打算使用 ES|QL 查询编写自己的应用程序,尝试访问原始 Elasticsearch API 可能会更有趣。Kibana 有一个方便的控制台,可用于尝试编写查询。这称为 "Dev Tools" 控制台,可以在 Kibana 侧边栏中找到。此控制台直接与 Elasticsearch 集群对话,可用于运行查询、创建索引等。
尝试以下操作:
POST /_query?error_trace=true&format=txt
{
"query": """
FROM airports
| EVAL distance = ST_DISTANCE(city_location, TO_GEOPOINT("POINT(12.565 55.673)"))
| WHERE distance < 1000000 AND scalerank < 6 AND distance > 10000
| SORT distance ASC
| KEEP distance, abbrev, name, location, country, city, elevation
| LIMIT 10
"""
}这应该提供以下结果:
| distance | abbrev | name | location | country | city | elevation |
|---|---|---|---|---|---|---|
| 273418.05776847183 | HAM | Hamburg | POINT (10.005647830925 53.6320011640866) | Germany | Norderstedt | 17.0 |
| 337534.653466062 | TXL | Berlin-Tegel Int'l | POINT (13.2903090925074 52.5544287044101) | Germany | Hohen Neuendorf | 38.0 |
| 483713.15032266214 | OSL | Oslo Gardermoen | POINT (11.0991032762581 60.1935783171386) | Norway | Oslo | 208.0 |
| 522538.03148094116 | BMA | Bromma | POINT (17.9456175406145 59.3555902065112) | Sweden | Stockholm | 15.0 |
| 522538.03148094116 | ARN | Arlanda | POINT (17.9307299016916 59.6511203397372) | Sweden | Stockholm | 38.0 |
| 624274.8274399083 | DUS | Düsseldorf Int'l | POINT (6.76494446612174 51.2781820420774) | Germany | Düsseldorf | 45.0 |
| 633388.6966435644 | PRG | Ruzyn | POINT (14.2674849854076 50.1076511703671) | Czechia | Prague | 381.0 |
| 635911.1873311149 | AMS | Schiphol | POINT (4.76437693232812 52.3089323889822) | Netherlands | Hoofddorp | -3.0 |
| 670864.137958866 | FRA | Frankfurt Int'l | POINT (8.57182286907608 50.0506770895207) | Germany | Frankfurt | 111.0 |
| 683239.2529970079 | WAW | Okecie Int'l | POINT (20.9727263383587 52.171026749259) | Poland | Piaseczno | 111.0 |
使用地图可视化数据
Kibana Maps 是一款强大的地理空间数据可视化工具。它可用于创建具有多个图层的地图,每个图层代表不同的数据集。数据可以以各种方式进行过滤、聚合和样式化。在本节中,我们将向你展示如何使用我们在上一节中导入的数据在 Kibana Maps 中创建地图。
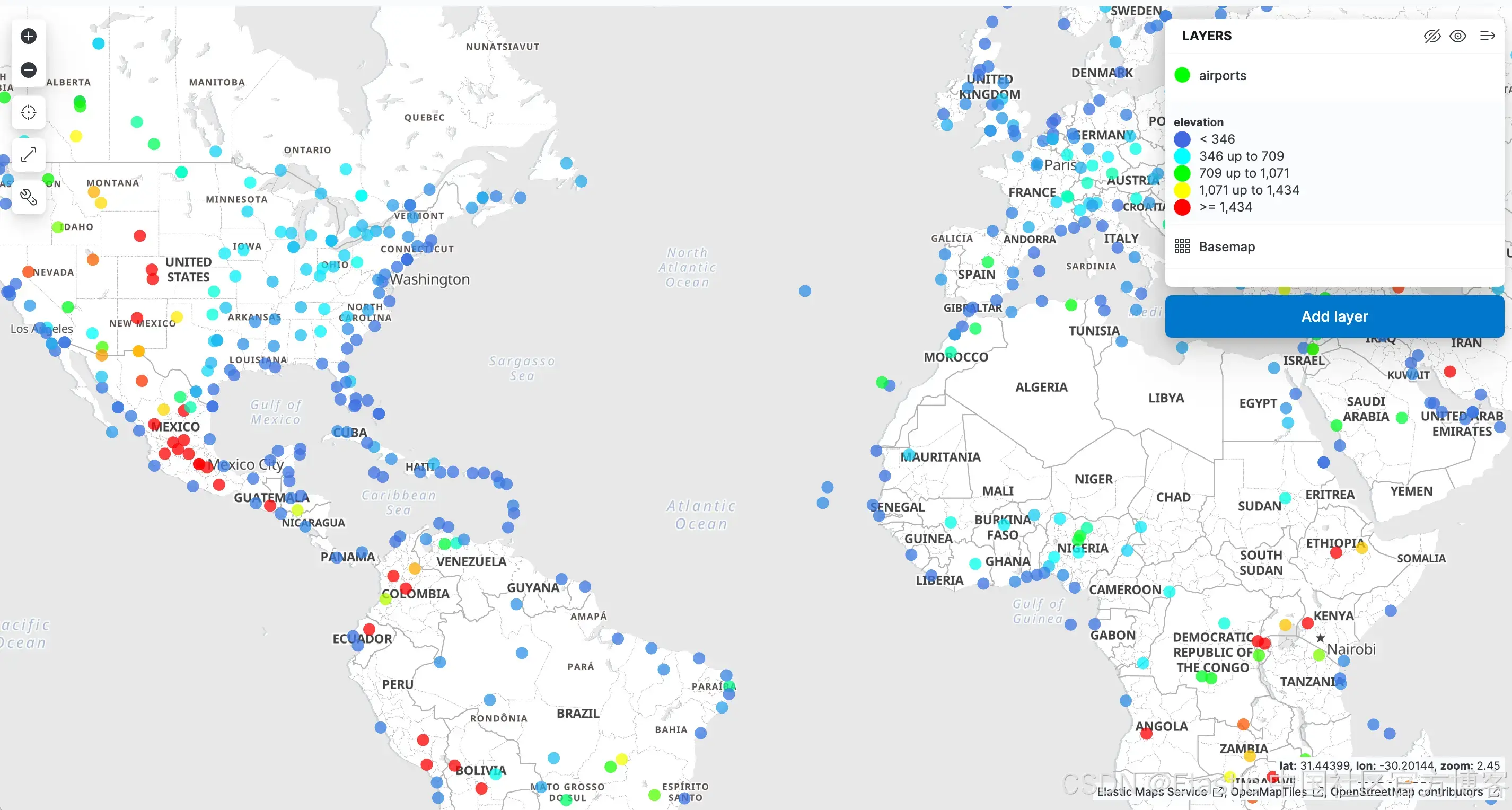
在 Kibana 菜单中,导航至 Analytics->Maps 以打开新的地图视图。单击 "Add Layer" 并选择 "Documents",选择数据视图 airports,然后编辑图层样式以使用海拔字段为标记着色,这样我们就可以轻松看到每个机场的高度。
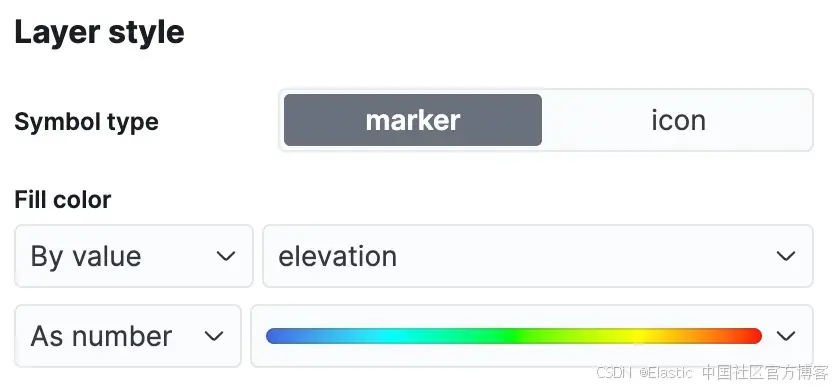
单击 "Keep changes" 保存地图:
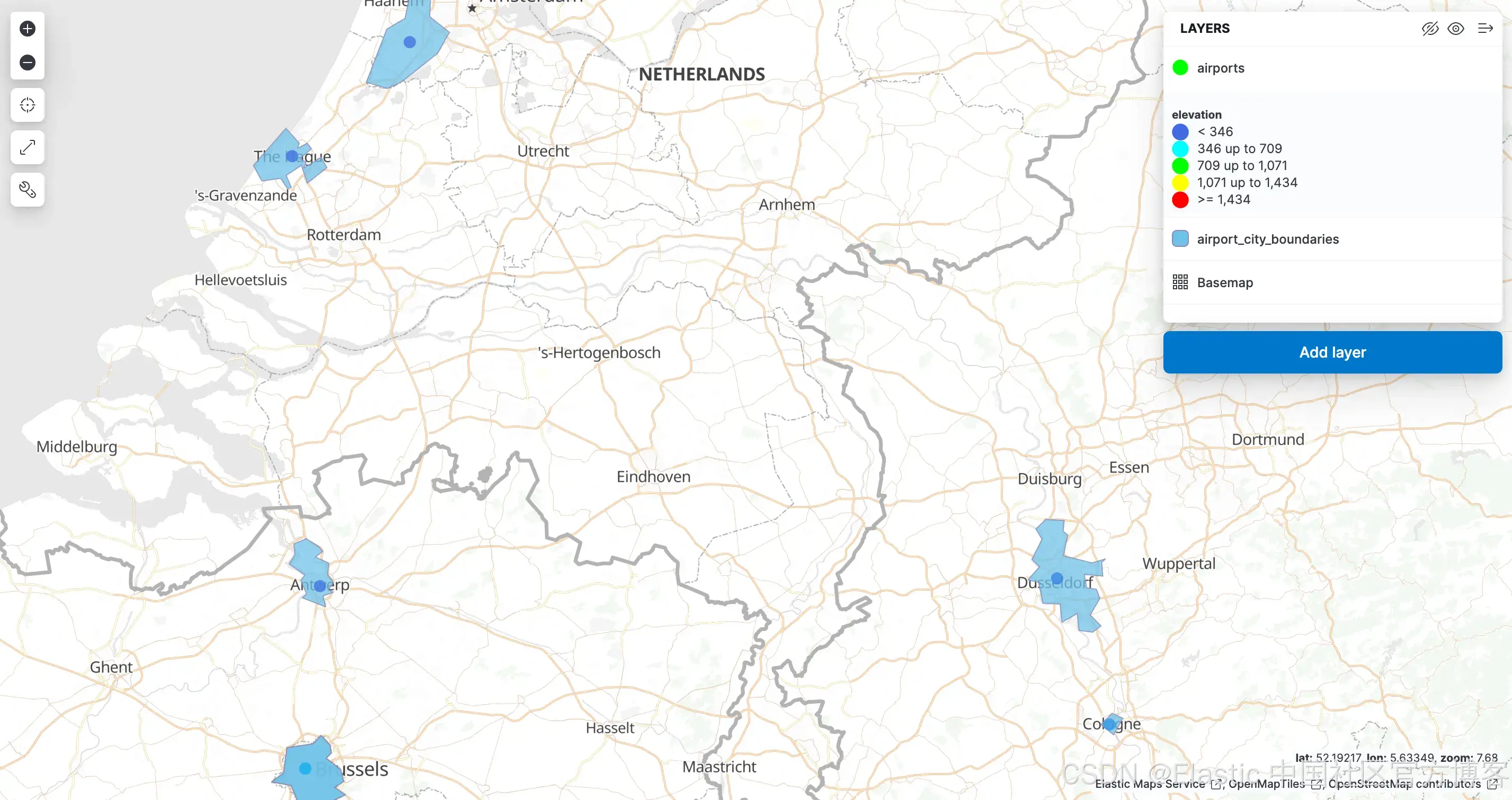
现在添加第二个图层,这次选择 airport_city_boundaries 数据视图。这次,我们将使用 city_boundary 字段来设置图层样式,并将填充颜色设置为浅蓝色。这将在地图上显示城市边界。确保重新排序图层以确保机场标记位于顶部。
空间连接
ES|QL 不支持 JOIN 命令,但你可以使用 ENRICH 命令实现特殊连接。此命令的操作类似于 SQL 中的 "左连接 - left join",允许你根据两个数据集之间的空间关系使用来自另一个索引的数据来丰富来自一个索引的结果。
例如,让我们通过查找包含机场位置的城市边界来丰富机场表的结果,其中包含有关机场所服务城市的其他信息,然后对结果进行一些统计:
FROM airports
| ENRICH city_boundaries ON city_location WITH airport, region, city_boundary
| STATS
centroid = ST_CENTROID_AGG(location),
count = COUNT(city_location)
BY region
| SORT count DESC
| LIMIT 10如果你在没有先准备丰富索引的情况下运行此查询,你将收到类似以下的错误消息:
cannot find enrich policy [city_boundaries]这是因为,正如我们之前提到的,ES|QL 不支持真正的 JOIN 命令。其中一个重要原因是 Elasticsearch 是一个分布式系统,而连接是昂贵的操作,很难扩展。然而,ENRICH 命令可以非常高效,因为它利用了专门准备的丰富索引,这些索引在集群中重复,从而可以在每个节点上执行本地连接。
为了更好地理解这一点,让我们关注上面查询中的 ENRICH 命令:
FROM airports
| ENRICH city_boundaries ON city_location WITH airport, region, city_boundary此命令指示 Elasticsearch 丰富从 airports 索引检索到的结果,并在原始索引的 city_location 字段和 airport_city_boundaries 索引的 city_boundary 字段之间执行相交(intersects)连接,我们在之前的几个示例中使用过该字段。但其中一些信息在此查询中并不清晰可见。我们看到的是丰富策略 city_boundaries 的名称,缺失的信息封装在该策略定义中。
{
"geo_match": {
"indices": "airport_city_boundaries",
"match_field": "city_boundary",
"enrich_fields": ["city", "airport", "region", "city_boundary"]
}
}在这里我们可以看到它将执行 geo_match 查询(默认为 intersects),要匹配的字段是 city_boundary,而 enrich_fields 是我们要添加到原始文档的字段。其中一个字段,即 region,实际上被用作 STATS 命令的分组键,如果没有这个"左连接"功能,我们就无法做到这一点。有关丰富策略的更多信息,请参阅 enrich 文档。
Elasticsearch 中的丰富索引和策略最初设计用于在索引时丰富数据,使用来自另一个准备好的丰富索引的数据。然而,在 ES|QL 中,ENRICH 命令在查询时工作,并且不需要使用摄取管道。这实际上使它非常类似于 SQL LEFT JOIN,只是你不能连接任何两个索引,只能连接左侧的普通索引和右侧专门准备的丰富索引。
无论哪种情况,无论是用于摄取管道还是在 ES|QL 中使用,都需要执行一些准备步骤来设置丰富索引和策略。我们已经导入了上述 airport_city_boundaries 索引,但这不能直接用作 ENRICH 命令中的丰富索引。我们首先需要执行两个步骤:
- 创建上述丰富策略以定义源索引、源索引中要匹配的字段以及匹配后要返回的字段。
- 执行此策略以创建丰富索引。这将构建一个特殊的内部索引,通过将原始源索引读入更高效的数据结构并在集群中复制。
可以使用以下命令创建丰富策略:
PUT /_enrich/policy/city_boundaries
{
"match": {
"indices": "airport_city_boundaries",
"match_field": "city_boundary",
"enrich_fields": ["city", "airport", "region", "city_boundary"]
}
}可以使用以下命令执行该策略:
POST /_enrich/policy/city_boundaries/_execute请注意,如果你更改 airport_city_boundaries 索引的内容,则需要重新执行此策略才能看到 enrich 索引中反映的更改。现在让我们再次运行原始 ES|QL 查询:
FROM airports
| ENRICH city_boundaries ON city_location WITH airport, region, city_boundary
| STATS
centroid = ST_CENTROID_AGG(location),
count = COUNT(city_location)
BY region
| SORT count DESC
| LIMIT 10这将返回拥有最多机场的前 5 个地区,以及所有具有匹配区域的机场的质心,以及这些区域内城市边界的 WKT 表示的长度范围:
| centroid | count | region |
|---|---|---|
| POINT (-12.139086859300733 31.024386116624648) | 126 | null |
| POINT (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| POINT (39.74537850357592 47.21613017376512) | 3 | городской округ Батайск |
| POINT (-156.80986787192523 20.476673701778054) | 3 | Hawaii |
| POINT (-73.94515332765877 40.70366442203522) | 3 | City of New York |
| POINT (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| POINT (-76.66873019188643 24.306286952923983) | 2 | New Providence |
| POINT (-3.0252167768776417 51.39245774131268) | 2 | Cardiff |
| POINT (-115.40993484668434 32.73126147687435) | 2 | Municipio de Mexicali |
| POINT (41.790108773857355 50.302146775648) | 2 | Центральный район |
| POINT (-73.88902732171118 45.57078813901171) | 2 | Montréal |
你可能还会注意到,最常见的区域为 null。这意味着什么?回想一下,我将此命令比作 SQL 中的 "左连接 - left join",这意味着如果未找到机场的匹配城市边界,则仍会返回机场,但 airport_city_boundaries 索引中的字段值为 null。结果发现有 125 个机场未找到匹配的 city_boundary,而一个机场的匹配项的 region 字段为空。这导致结果中有 126 个机场没有区域。如果你的用例要求所有机场都可以与城市边界匹配,则需要获取其他数据来填补空白。需要确定两件事:
- airport_city_boundaries 索引中的哪些记录没有 city_boundary 字段
- airports 索引中的哪些记录与 ENRICH 命令不匹配(即不相交)
Kibana Maps 中的 ES|QL
Kibana 在 Maps 应用程序中添加了对 Spatial ES|QL 的支持。这意味着你现在可以使用 ES|QL 在 Elasticsearch 中搜索地理空间数据,并在地图上将结果可视化。
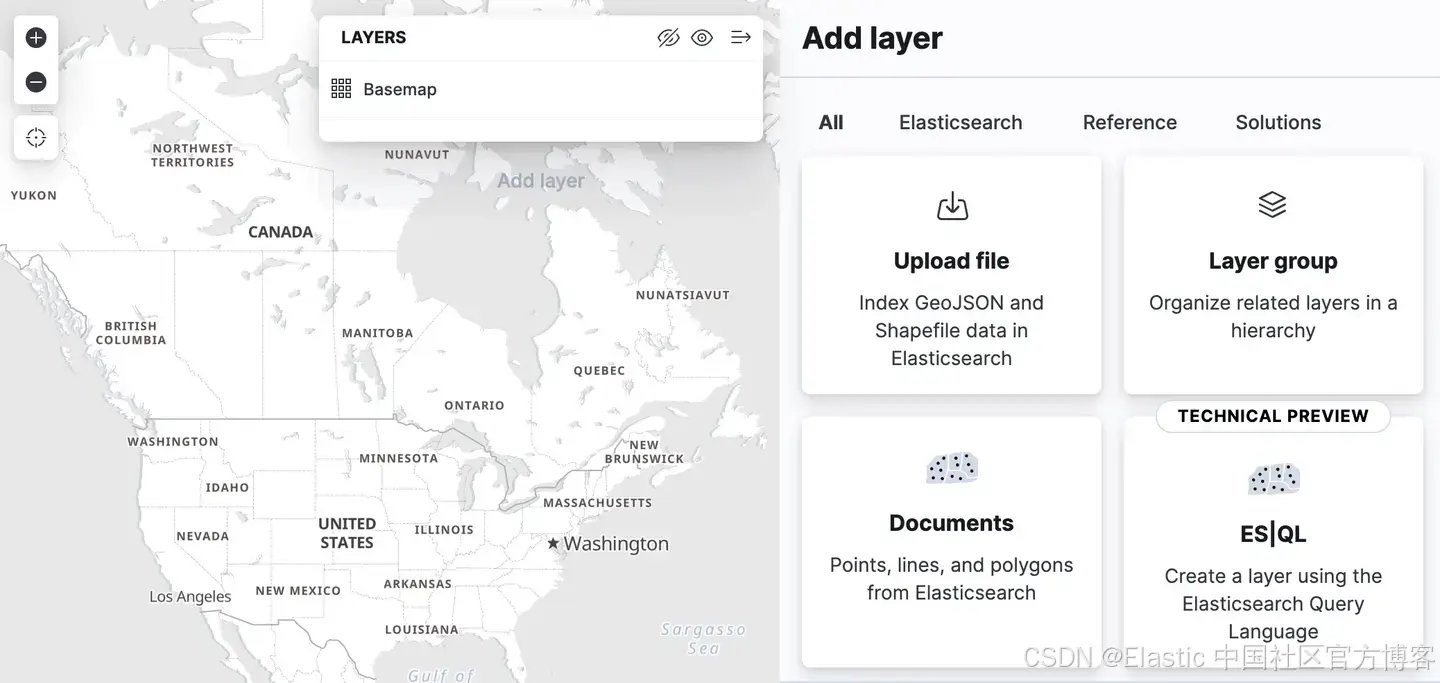
添加图层菜单中有一个新的图层选项,称为 "ES|QL"。与迄今为止描述的所有地理空间功能一样,该选项处于 "技术预览" 状态。选择此选项可让您根据 ES|QL 查询的结果向地图添加图层。例如,你可以向地图添加一个显示世界上所有机场的图层。
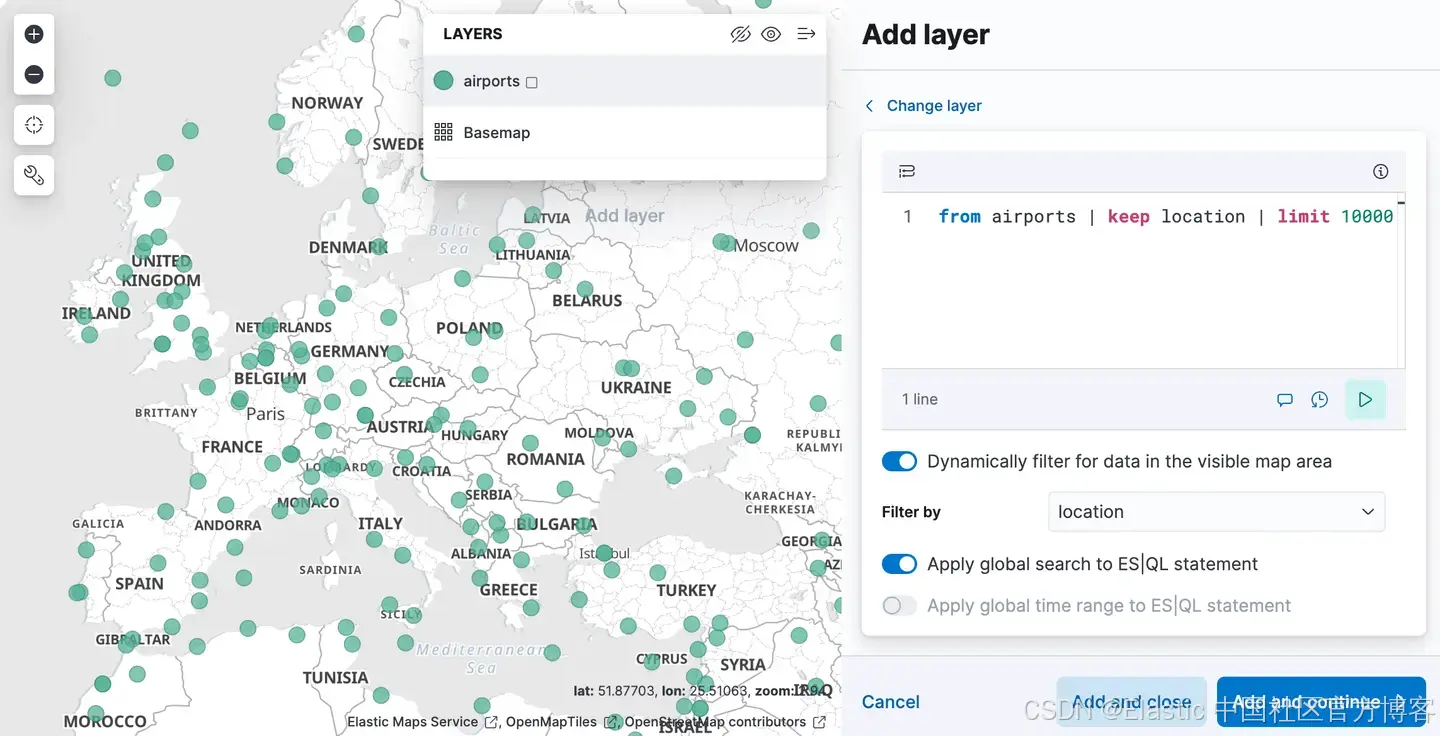
或者你可以添加一个显示 airport_city_boundaries 索引中的多边形的图层,或者更好的是,上面的复杂 ENRICH 查询如何生成每个地区有多少个机场的统计数据?
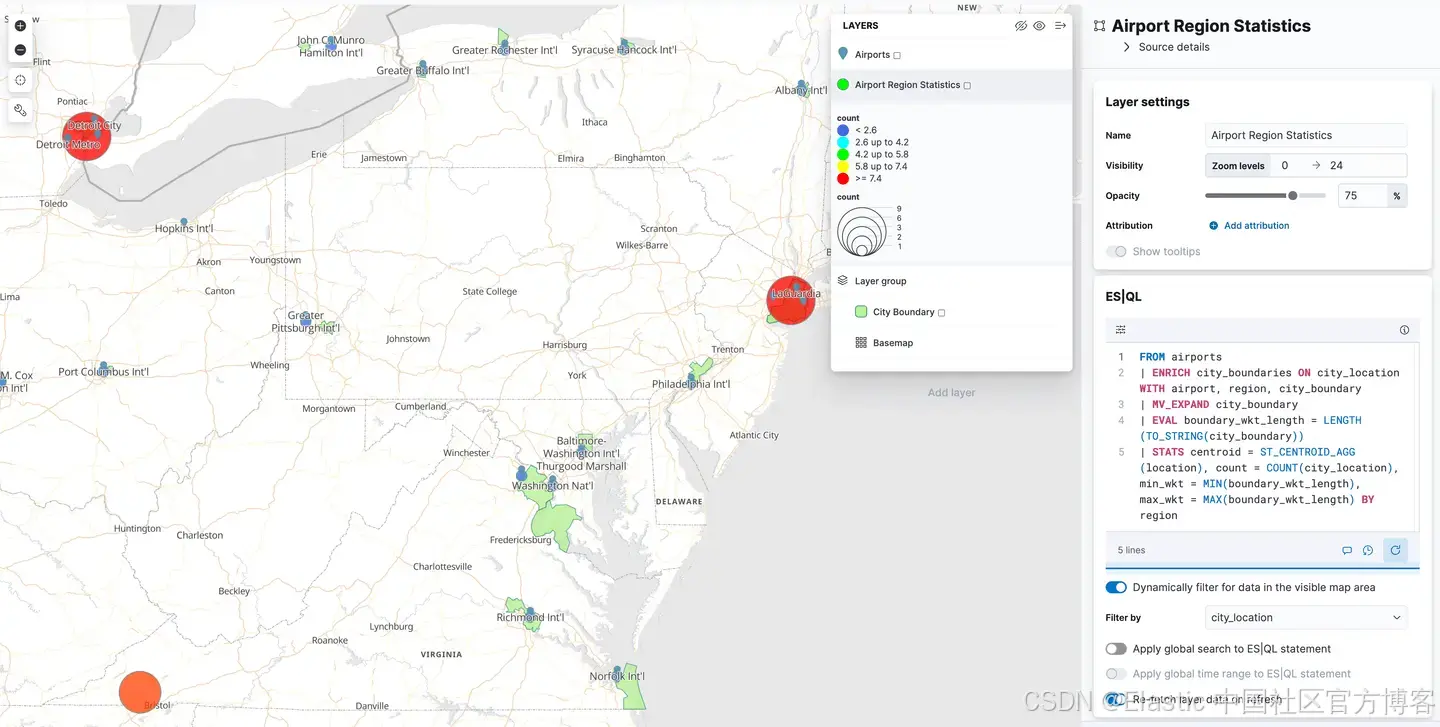
下一步是什么?
上一篇地理空间搜索博客重点介绍了如何使用 ST_INTERSECTS 等函数执行搜索,这些函数自 Elasticsearch 8.14 起可用。这篇博客向你展示了如何导入我们用于这些搜索的数据。但是,Elasticsearch 8.15 附带了一个特别有趣的函数:ST_DISTANCE,可用于执行有效的空间距离搜索,这将是下一篇博客的主题!
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时举行!
原文:Using Kibana to ingest geospatial data into Elasticsearch for use in ES|QL - Search Labs