概述
近年来,大规模语言模型因其能够根据人类指令自动生成大量高质量文本而备受关注。特别是 2022 年底发布的 ChatGPT 3.5,因其聊天界面的易用性而迅速走红。目前,学术交流领域正在积极讨论如何使用它。而最初的期望也逐渐让人们对其能力和局限性有了更深入的理解和认识。
根据 2023 年底进行的一项调查,30% 的研究人员使用大规模语言模型准备稿件,许多出版商也开始提供使用指南;Wiley 等出版商允许使用这些工具,只要作者完全负责并明确披露其使用情况。然而,要全面了解大规模语言建模文本生成对学术文献质量的影响并不容易。一些研究已经确定论文是由大规模语言模型生成的,因为其中包含的短语明显不同于人类使用的短语,但这种情况只占总数的一小部分。
人工智能检测工具的进步在一定程度上使得使用大规模语言模型来识别生成的文本成为可能,但在某些领域,如物理和数学,还没有得到广泛应用。不过,最近的研究表明,大规模语言模型可用于会议论文的同行评审,尤其是在人工智能领域。这些例子表明,大规模语言模型的使用正开始在学术交流中发挥重要作用,未来的发展将令人关注。
大规模语言模型首选术语的识别
Liang 等人的研究提出了一种新方法,通过识别与模型生成的文本相关的术语来查找利用大规模语言模型的论文。这种方法不需要分析整个文本,只需检测这些特征术语即可进行评估。
为此,Liang 等人选择了 12 个特征形容词(形容词)和副词(副词),并对这些词进行了检测。此外,还有 12 个中性词(Controls)可供比较,这些词在许多文章中都很常用。
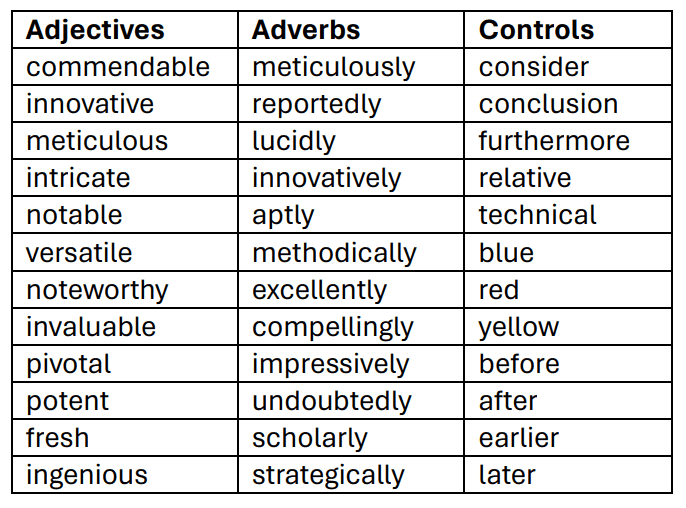
全文检索中与每个关键词匹配的文件数量数据来自 Dimensions。数据收集时间为 2024 年 3 月 18 日至 22 日。使用空白搜索对所有 "文章 "进行的计数被用作基线,结果被计算为每年出现该关键词的文件百分比。该基线从 2015 年的约 340 万上升至 2023 年的 530 多万;2024 年的数据已收集,但由于不完整而未进行分析。与每个词匹配的文档比例从 "lucidly "的 0.02%(约 1000 篇/年)到 "after "的 50%以上(约 280 万篇/年)不等。中性词(控制词)比副词(副词)出现的频率高得多,而且比副词更常见。这一分析证实了大规模语言模型生成的文本中使用的独特词汇数量明显增加,表明大规模语言模型在学术文献中的普遍性:在 2023 年发表的文章中,即使考虑到 ChatGPT 发布后出版过程的延迟、预计这一效应将开始显现。
大规模语言模型所青睐的术语变化
下面三幅图显示了 36 个选定词语每年的相对频率变化。仅显示 2019 年至 2023 年的数据。正如预期的那样,中性词(Controls)的年度变化很小。随着时间的推移,一些词语逐渐增多。例如,从 2015 年到 2023 年,蓝色、红色和黄色都略有增加。与此同时,其他词语则保持稳定或略有下降。这些变化表明,随着时间的推移,学术文献中的用词偏好正在逐渐发生变化。
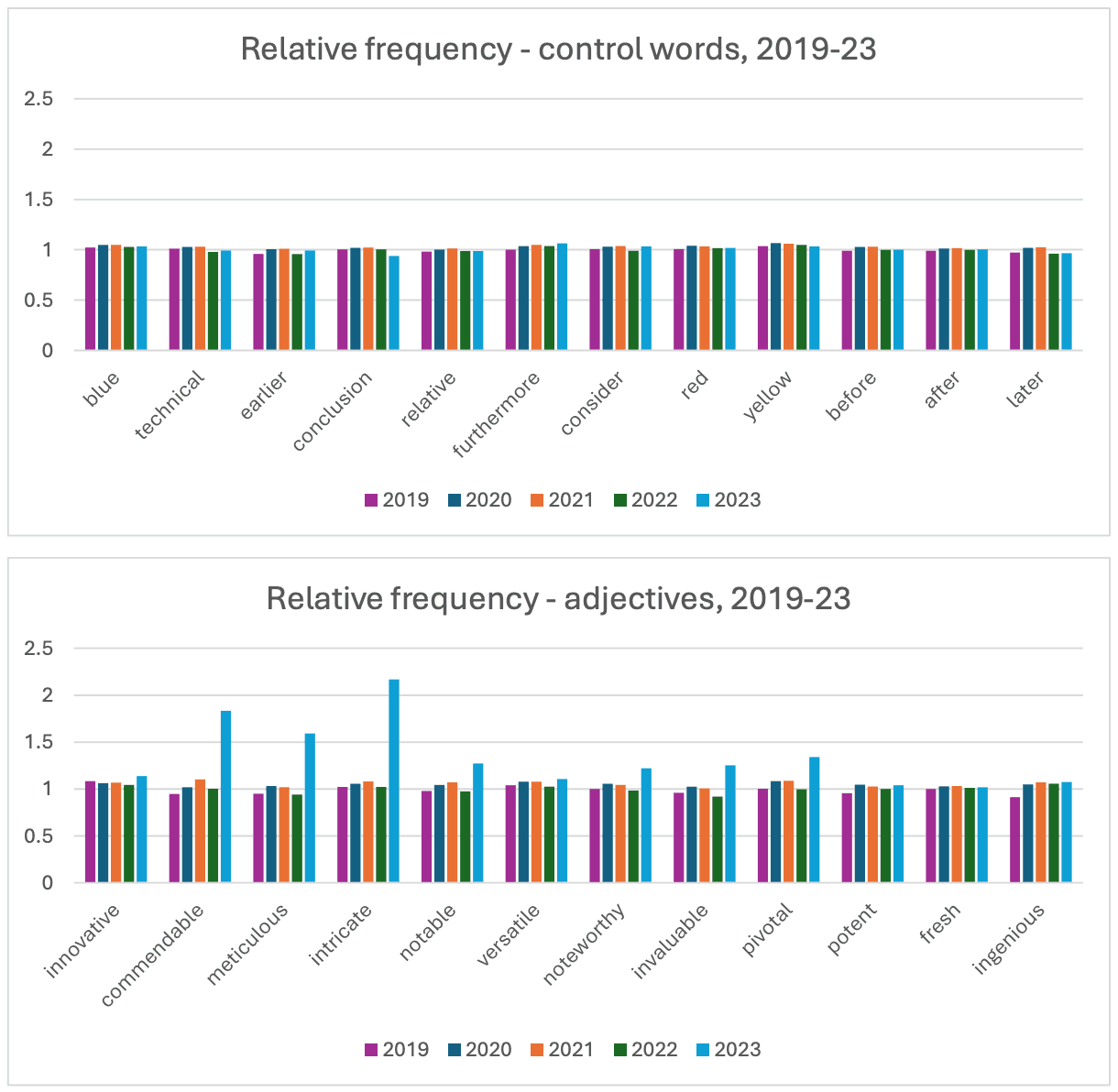
形容词的变化则稍显复杂,一些形容词在 2015 年至 2022 年间稳步增长,而另一些则缓慢下降。然而,在 2023 年,也就是大规模语言模型发布后的第二年,变化尤为明显:12 个形容词(形容词)在 2022 年至 2023 年期间平均增加了 33.7%,其中 "错综复杂"、"值得称赞 "和 "一丝不苟 "等词语显著增加。等词语的数量显著增加。
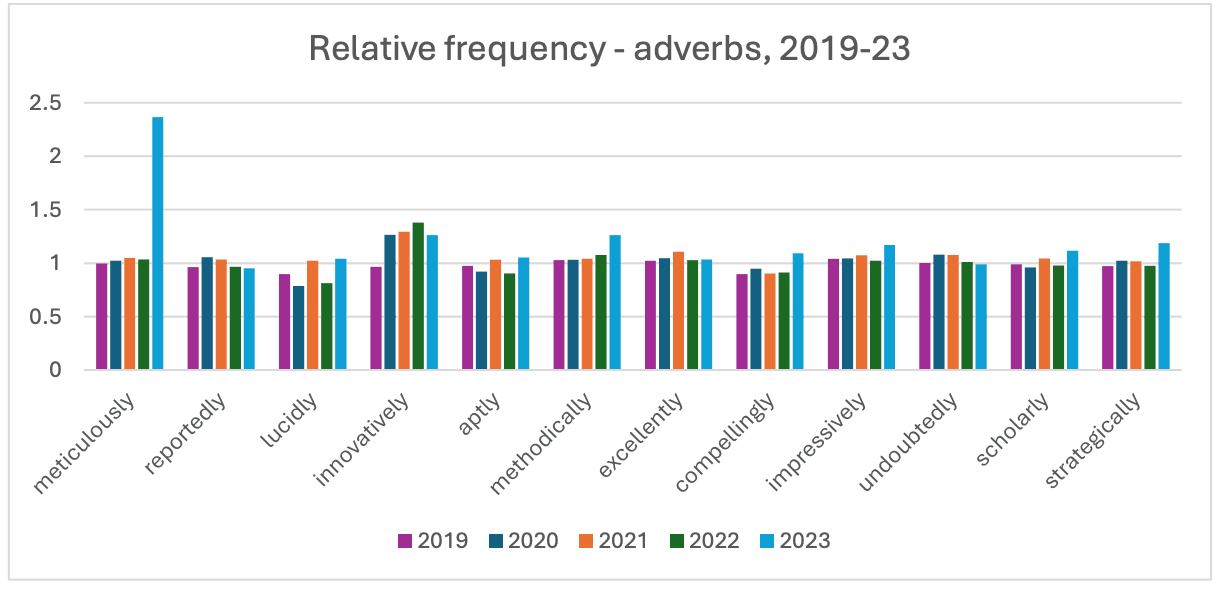
同样,一些副词(Adverbs)在 2015 年至 2022 年间有所减少,而另一些则有所增加:在 2023 年,"一丝不苟 "增加了 137%,而 "有条不紊 "和 "创新 "也分别增加了 26%。2023年,"一丝不苟 "增加了137%,"有条不紊 "和 "勇于创新 "也分别增加了26%。尤其是,"competently "在 2023 年前再次上升。这些结果表明,大规模语言模型正在对学术文献中的语言使用产生显著影响。
与使用单一术语相比,组合术语的效果也更为明显。例如,在 2023 年,包含前四个 "强 "指标中的一个或多个指标的文章增加了 83.5%。第二组包含 "中等强度 "指标的文章增加了16.3%。第三组 "弱 "指标增加了 9.3%。最后,由 12 个术语组成的第五组 "强、中、弱 "指标组每年发表的文章超过 100 万篇,占所有研究文章的五分之一。
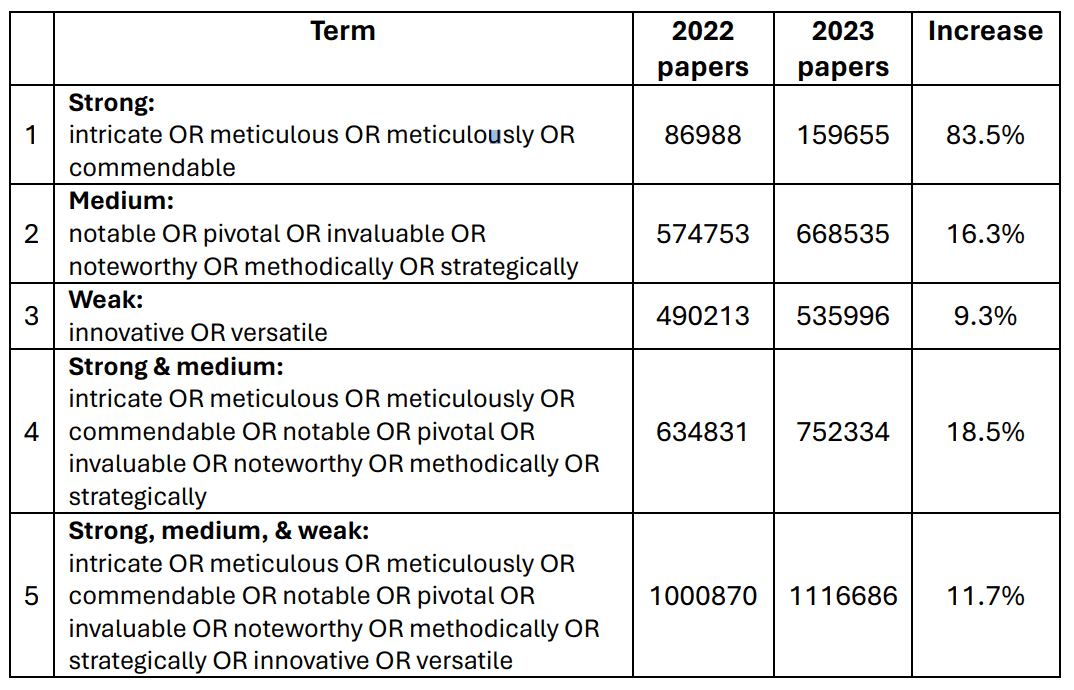
如果大规模语言模型生成的文本倾向于某些术语,那么这些术语有可能被多次使用;通过使用维度数据库查找使用多个指标术语的论文,发现某些词对的结果大幅增加结果表明,某些词对的结果急剧增加。例如,同时包含 "错综复杂 "和 "一丝不苟 "的文章增加了七倍,而 "错综复杂 "和 "引人注目 "的组合增加了四倍。

结合两个或更多术语的论文频率也呈现出类似的趋势,尤其是在第八组中,包括两个 "弱 "术语,与前一年相比增加了 35%。通过这种方式分析术语组合,还可以更准确地了解大规模语言模型的影响范围。
通过利用综合术语数据,我们可以估算出可能包含由大规模语言模型生成的文本的文章总数:从 2014 年到 2022 年,即大规模语言模型开始普及之前,"强+中等术语 "中的文章数量每年平均增长 1.1%,而包括 "所有术语 "在内的第五组文章数量每年平均增长 2.1%。第四组文章的年均增长率为 1.1%,而包括 "所有术语 "在内的第五组文章的年均增长率为 2.1%。这些组别的最大年变化率约为 5%。因此,如果没有外部因素的影响,这些组别的文章数量预计会增加约 5%。根据这一估计,预计第 4组和第 5组的文章数量分别为666,573 篇和1,050,914 篇,而实际数量分别超过 85,761 篇和 65,772 篇,占 2023 年发表文章总数的 1.63% 和 1.25%。
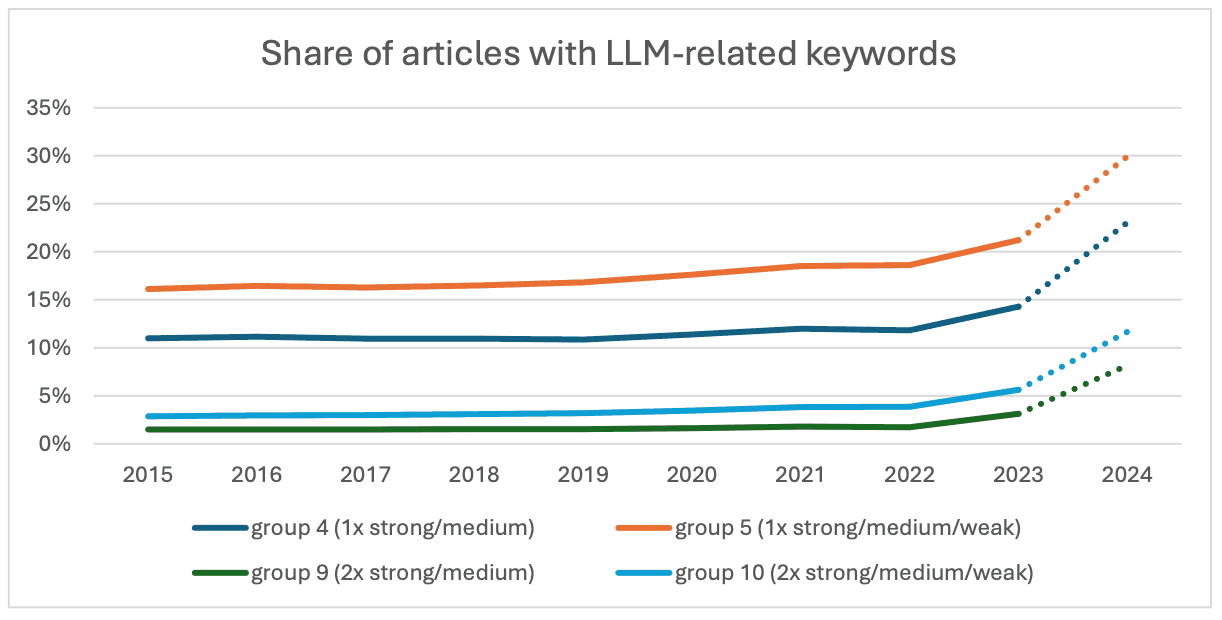
就包含两个以上术语的论文而言,第 9组(两个强/中术语)和第 10组(两个强/中/弱术语)在 2014 年至 2022 年期间的年增长率最大,约为 10-11%,而第 9组(两个强/中/弱术语)和第 10组(两个强/中/弱术语)在 2014 年至 2022 年期间的年增长率分别为 79.8%和 45.7%。显著增长 45.7%。假设这两组的增幅为 11%,预计第 9组和第 10组的论文数量分别为103 232 和230 338 份,而实际数量分别超过 60 514 和 65 735 份,占总数的 1.15%和 1.25%。
然而,这些术语并不是用来识别 ChatGPT 生成文本的唯一指标。例如,"groundbreaking"(开创性的)等词在 2023 年的增长率为 52%,高于其他测试词。此外,"outwith "这个通常只在苏格兰英语中使用的词汇也意外地被 ChatGPT 首选:2023 年几乎增长了两倍,增幅达 185%;"outwith "被发现是 ChatGPT 在 2023 年最常用的词汇,增幅达 18%;"outwith "被发现是 ChatGPT 在 2023 年最常用的词汇,增幅达 18%;"outwith "被发现是英国最常用的词汇,增幅达 18%。此处未测试的其他词语也显示出类似的 "ChatGPT 风格",而且很有可能出现在文章中,这可能会进一步增加数字。
总结
对 2023 年发表的论文进行的分析表明,估计有 60,000 多篇论文可能包含由大规模语言模型生成的文本。虽然这并不一定直接表明个别论文是由大规模语言模型生成的,但它确实表明大规模语言模型的使用非常普遍。
论文指出,这一事实有两个主要影响:首先,它提出了大规模语言模型是否纯粹用于外观目的的问题。虽然还需要更详细的分析,但论文指出,大规模语言模型可能不仅仅用于简单的文体调整。
其次是对大规模语言模型本身的影响。学术文献是大规模语言模型的重要学习资源,使用大规模语言模型生成的文本越多,"模型崩溃 "的风险就越大。作者认为,这意味着大规模语言模型未来生成文本的质量可能会下降。
报告指出,这种情况需要出版商和审稿人积极应对。特别是,如果没有适当披露使用大规模语言模型生成文本的情况,则有必要制定规则加以澄清。使用大规模语言模型生成文本的作者应适当披露其使用情况,或重新考虑其使用是否恰当。
今后,需要进一步开展研究,以准确确定问题的严重程度,同时还必须为大规模语言模型的使用制定道德准则,并监测其使用对学术界的影响。希望本研究能为深入了解大规模语言模型的使用对学术交流的影响以及应采取的适当措施迈出第一步。
注: